
Как сделать реплику postgresql
Добавил пользователь Cypher Обновлено: 04.10.2024
Мы не будем напоминать о важности резервного копирования данных, об этом немало сказано, а поговорим о практической реализации одного из сценариев. Сегодня в фокусе нашего внимания будет популярная бесплатная СУБД PostgreSQL. Актуальности данному вопросу добавляет тот факт, что PostgreSQL активно используется для хранения информационных баз системы 1С:Предприятие.
В данном материале мы рассмотрим реализацию резервного копирования на примере сервера баз данных для 1С:Предприятия, который мы описывали в данной статье. Также заметим, что всё, о чем пойдет речь ниже одинаково применимо как к платформе Linux, так и к платформе Windows, за незначительными уточнениями.
PostgreSQL, как и любая другая СУБД, имеет богатые возможности по резервному копированию как кластера БД, так и отдельных баз, но основным механизмом управления при этом является командная строка, что может вызвать определенные затруднения. Несмотря на то, что утилита PgAdmin позволяет выполнять основные задачи через графический интерфейс, мы все равно рекомендуем освоить работу с PostgreSQL через командную строку, что позволит вам уверенно чувствовать себя в любой ситуации и открывает широкие возможности по автоматизации.
Итак, в нашем распоряжении имеется сервер СУБД на базе Ubuntu Server, где расположены базы 1С:Предприятия, наша задача обеспечить автоматическое резервное копирование в соответствии с заданными условиями.
Прежде всего настроим авторизацию для СУБД. Так как основные операции должны будут производится из скрипта, то имеет смысл разрешить локальный доступ к СУБД без авторизации. Учитывая, что доступ к серверу БД имеет ограниченный круг лиц и расположен он в периметре сети, безопасность пострадает слабо.
Откроем файл pg_hba.conf, он находится в /var/lib/pgsql/data и приведем к следующему виду строку:
На платформе Windows данный файл находится в C:\Program Files\PostgreSQL\Версия_СУБД\data и строка будет иметь несколько иное содержание:
Для создания резервной копии воспользуемся утилитой pg_dump, которая позволяет создать дамп для указанной БД. Создание дампа происходит без блокирования таблиц и представляет снимок БД на момент выполнения команды. Т.е. вы можете создавать дампы во время работы пользователей, в то время как для создания резервной копии средствами 1С вам нужен монопольный доступ к базе.
Синтаксис pg_dump предельно прост, нам нужно указать имя базы и расположение и название файла дампа. Просмотреть список баз можно командой:
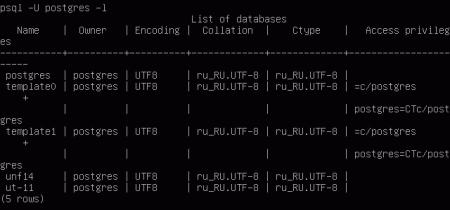
Кроме списка баз вывод содержит ряд полезной информации, например о кодировке базы, данная информация пригодится нам при восстановлении БД на другом сервере.
Теперь, уточнив наименование баз на сервере создадим резервную копию базы unf14:
результатом выполнения команды будет файл дампа в домашней директории. Расширение файла мы рекомендуем указывать таким образом, чтобы по нему было понятно назначение данного файла и оно может быть любым. В нашем случае мы используем pgsql.backup, глянув на такой файл сразу станет понятно о его назначении, это может быть важно, если поиском дампов будут заниматься ваши коллеги. Также мы не рекомендуем использовать расширение .bak, потому что многие утилиты "для оптимизации" удаляют такие файлы.
При необходимости можем создать сжатый дамп:
Сжатие позволяет уменьшить размер дампов примерно вдвое, поэтому следует его использовать при передаче резервных копий по сети интернет или при ограниченном размере хранилища.
Теперь рассмотрим процедуру восстановления. Для примера будем использовать сервер под управлением Windows. Никаких существенных особенностей по работе с PostgreSQL на разных платформах нет. Однако под Windows следует вместо psql использовать psql.bat и указывать полный путь к утилитам C:\Program Files\PostgreSQL\Версия_СУБД\bin, либо добавить этот путь в системную переменную PATH.
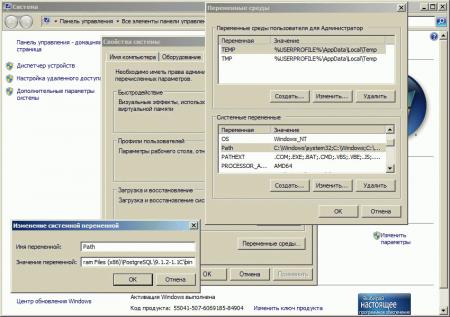
Еще одно важное замечание. Кодировка исходного и целевого серверов должна совпадать, иначе вы после восстановления получите нерабочую базу. На платформе Linux СУБД обычно работает в кодировке UTF8, в то время как сборка PostgreSQL от 1С на Windows по умолчанию устанавливается в кодировке WIN1251.
Для 1С:Предприятия типичным симптомом того, что вы залили UTF8 базу на сервер с WIN1251 является невозможность авторизоваться в ИБ.
Перед восстановлением дампа следует создать целевую БД (при ее отсутствии), хотя мы рекомендуем делать это всегда. Еще одна БД есть не просит, зато избавляет от распространенной ситуации, когда залили не тот дамп или не в ту базу. Для создания базы выполним:
Теперь зальем полученный дамп в только что созданную базу unf14:
На платформе Линукс эта команда будет выглядеть так:
В нашем примере файл дампа находится в C:\backup и домашней директории соответственно.
Все что теперь остается, это через оснастку Администрирование сервера 1С:Предприятия создать новую ИБ или изменить настройки существующей, указав на новый сервер СУБД и новую базу.
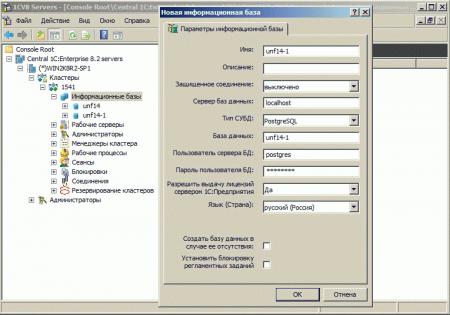
С основными командами мы разобрались и убедились, что ничего сложного в процессе резервного копирования и восстановления баз PostgreSQL нет. Но не будем же мы создавать бекапы вручную. Поэтому перейдем к автоматизации. Создадим скрипт, который будет создавать резервные копии указанных баз и размещать их на FTP-сервере. В силу определенных различий между платформами, создать универсальный скрипт для Windows и Linux не получится, поэтому рассмотрим каждую платформу отдельно.
Начнем с Linux, в нашем случае это Ubuntu Server. Создадим файл скрипта:
и поместим в него следующее содержимое:
Скрипт довольно прост и мы не будем разбирать его подробно. Сохраним его и дадим права на выполнение:
Также не забудем создать каталог /root/backup
Проверив работоспособность скрипта, зададим его регулярное выполнение через cron.
Для платформы Windows все несколько сложнее, так как встроенный архиватор отсутствует, то следует воспользоваться сторонним решением, в нашем случае будет использоваться 7zip, также нужно указывать полные пути к бинарным файлам или добавить их в переменную PATH, мы будем задавать эту переменную динамически в скрипте. Еще одна сложность связана с использованием встроенного ftp-клиента, набор команд для него необходимо подготовить в виде отдельного файла.
Создадим в Блокноте новый файл и разместим там нижеприведенный текст:
Скрипт также довольно прост для понимания и повторяет по структуре и логике скрипт для Ubuntu. Задаем переменные, устанавливаем рабочую директорию и выгружаем туда дамп, затем создаем архив. Следующим шагом формируем файл с командами для FTP-соединения, загружаем архив на FTP и делаем уборку.
Файл следует сохранить как pgsql-backup.bat и разместить в удобном месте. Затем настроить его выполнение по расписанию через Планировщик задач Windows. Также не забудьте создать директорию C:\backup (или любую другою, которую вы хотите использовать в качестве рабочей).
Конечно, наши примеры не затрагиваю все возможные сценарии резервного копирования, но мы уверены что приведенные примеры помогут вам создавать собственные скрипты для автоматизации данного процесса.
Как правильно скопировать всю базу данных (ее структуру и данные) в новую в pgAdmin?
Postgres позволяет использовать любую существующую базу данных на сервере в качестве шаблона при создании новой базы данных. Я не уверен, что pgAdmin дает вам опцию в диалоговом окне создания базы данных, но вы должны иметь возможность выполнить следующее В окне запроса, если это не так:
тем не менее, вы можете получить:
версия командной строки Белла:
Это должно выполняться с привилегиями мастера базы данных, обычно postgres.
чтобы клонировать существующую базу данных с помощью postgres, вы можете сделать это
это убьет все соединение с исходной БД, избегая ошибки
в рабочей среде, где исходная база данных находится под трафиком, я просто использую:
не знаю о pgAdmin, но pgdump дает вам дамп базы данных в SQL. Вам нужно только создать базу данных с тем же именем и сделать
для восстановления всех таблиц и их данных и всех прав доступа.
я собрал этот подход вместе с примерами выше. Я работаю над сервером "под нагрузкой" и получил ошибку, когда я попытался подойти от @zbyszek. Я также был после решения "только для командной строки".
createdb: database creation failed: ERROR: source database "exampledb" is being accessed by other users .
вот что сработало для меня (команды начинаются с nohup для перемещения вывода в файл и защиты от сервера отключить):
- nohup pg_dump exampledb > example-01.sql
- createdb -O postgres exampledbclone_01
во-первых, sudo как пользователь базы данных:
перейдите в командную строку PostgreSQL:
создайте новую базу данных, дайте права и выйдите:
скопировать структуру и данные из старой базы данных в новую:
в pgAdmin вы можете сделать резервную копию из исходной базы данных, а затем просто создать новую базу данных и восстановить из только что созданной резервной копии:
- щелкните правой кнопкой мыши исходную базу данных, резервное копирование. и дамп в файл.
- щелкните правой кнопкой мыши, новый объект, новая база данных. и назовите пункт назначения.
- щелкните правой кнопкой мыши новую базу данных, восстановить. и выберите файл.
Как правильно скопировать всю базу данных (ее структуру и данные) в новую в pgAdmin?
для тех, кто все еще заинтересован, я придумал сценарий bash, который делает (более или менее) то, что хотел автор. Мне пришлось сделать ежедневную копию бизнес-базы данных в производственной системе, этот скрипт, похоже, делает трюк. Не забудьте изменить имя базы данных/user/PW значения.
для создания дампа базы данных
в resote дамп базы данных
если база данных имеет открытые соединения, этот скрипт может помочь. Я использую это для создания тестовой базы данных из резервной копии базы данных в реальном времени каждую ночь. Это предполагает, что у вас есть .Файл резервной копии SQL из рабочей БД (я делаю это в webmin).
через pgAdmin, отсоединить базу данных, которую вы хотите использовать в качестве шаблона. Затем вы выбираете его в качестве шаблона для создания новой базы данных, это позволяет избежать получения уже используемой ошибки.
С документация, используя createdb или CREATE DATABASE с шаблонами не рекомендуется:
хотя можно скопировать базу данных, отличную от template1 указывая свое имя в качестве шаблона, это не (пока) предназначено как универсальное средство "копировать базу данных". Основным ограничением является что никакие другие сеансы не могут быть подключены к базе данных шаблонов его копируют. Создать базу данных не удастся, если любой другой соединение существует при запуске; в противном случае новые подключения к шаблону база данных блокируется до завершения создания базы данных.
pg_dump или pg_dumpall это хороший способ для копирования базы данных и всех данных. Если вы используете GUI как pgAdmin, эти команды вызываются за кулисами при выполнении команды резервного копирования. Копирование в новую базу данных выполняется в два этапа: резервное копирование и восстановление
pg_dumpall сохраняет все базы данных в кластере PostgreSQL. Недостатком этого подхода является то, что вы получаете потенциально очень большой текстовый файл, полный SQL, необходимый для создания базы данных и заполнения данных. Преимущество этого подхода заключается в том, что вы получаете все роли (разрешения) для кластера бесплатно. Чтобы сбросить все базы данных, сделайте это из учетной записи суперпользователя
pg_dump имеет некоторые варианты сжатия, которые дают у вас гораздо меньше файлов. У меня есть производственная база данных, которую я резервирую два раза в день с помощью задания cron, используя
здесь compress уровень сжатия (от 0 до 9) и create сообщает pg_dump добавить команды для создания базы данных. Восстановление (или перемещение в новый кластер) с помощью
Всем привет! Сегодня мы рассмотрим процесс переноса базы данных PostgreSQL с одного сервера на другой, например, с компьютера разработчика на production-сервер, при этом мы будем использовать графический инструмент pgAdmin 4.

Исходные данные. Задача
Допустим, мы разрабатываем базу данных в PostgreSQL, при этом мы используем обычный клиентский компьютер под управлением операционной системы Windows 10, где собственно локально и установлен PostgreSQL.
В качестве инструмента разработки мы используем стандартное графическое приложение pgAdmin 4.
pgAdmin 4 – это стандартный и бесплатный графический инструмент для разработки баз данных в PostgreSQL, который можно использовать для написания SQL запросов, разработки процедур, функций, а также для выполнения базовых задач администрирования баз данных.
В итоге базу данных мы разработали, протестировали ее, внесли в нее необходимые данные, заполнили справочники, в общем, база данных готова.
Теперь у нас возникла необходимость перенести эту базу данных на реальный сервер, который и будет выступать в качестве сервера баз данных. И так как мы используем PostgreSQL, в качестве такого сервера баз данных обычно выступает сервер под управлением операционной системы Linux.
Таким образом, нам необходимо перенести базу данных PostgreSQL, разработанную в Windows, в базу данных PostgreSQL на Linux. В моем случае в качестве операционной системы Linux будет выступать дистрибутив Debian.
Создание дампа базы данных PostgreSQL в pgAdmin 4
Весь процесс переноса базы данных PostgreSQL достаточно простой, суть в следующем.
Нам необходимо создать копию нашей базы данных (дамп), затем создать пустую базу на нужном нам сервере и восстановить все данные, используя созданный ранее дамп.
Все это можно сделать с нашего клиентского компьютера, используя pgAdmin 4, если, конечно же, целевой сервер нам доступен, если недоступен, то придётся каким-то другим образом переносить дамп базы данных на нужный сервер и, используя стандартные консольные утилиты, восстановить базу данных из дампа.
Кстати, стоит отметить, что pgAdmin 4 для экспорта/импорта баз данных использует как раз эти стандартные консольные утилиты, в частности pg_dump, pg_dumpall и pg_restore, которые по умолчанию входят в состав PostgreSQL.
Таким образом, благодаря pgAdmin 4 нам не нужно писать и выполнять команды в командной строке, за нас все это делает pgAdmin 4, мы всего лишь будем пользоваться мышкой, настраивая все параметры в графическом интерфейсе.
Создать дамп базы данных PostgreSQL можно в нескольких форматах, в частности:
Специальный (Custom) – это пользовательский формат, который использует сжатие. Данный формат по умолчанию предлагается в pgAdmin 4 и рекомендован для средних и больших баз данных. Обычно архивные файлы в таком формате создают с расширением backup, однако можно использовать и другое расширение.
Tar (tar) – база данных выгружается в формат tar. Данный формат не поддерживает сжатие.
Простой (plain) – в данном случае база данных выгружается в обычный текстовый SQL-скрипт, в котором все объекты базы данных и непосредственно сами данные будут в виде соответствующих SQL инструкций. Данный скрипт можно легко отредактировать в любом текстовом редакторе и выполнить, используя Query Tool, как обычные SQL запросы. Данный формат рекомендован для небольших баз данных, а также для тех случаев, когда требуется внести изменения в дамп базы данных перед восстановлением.
Каталог (directory) – этот формат файла создает каталог, в котором для каждой таблицы и большого объекта будут созданы отдельные файлы, а также файл оглавления в машиночитаемом формате, понятном для утилиты pg_restore. Этот формат по умолчанию использует сжатие, а также поддерживает работу в несколько потоков.
В данном материале мы рассмотрим создание дампа в специальном формате, а также в формате обычного SQL скрипта, дело в том, что процесс восстановления базы данных из этих форматов в pgAdmin 4 немного отличается.
Создание дампа базы данных в сжатом формате
Затем всего лишь нужно указать имя архивного файла и путь к каталогу, где его сохранить, для этого можно использовать кнопку с тремя точками.
Как я уже отмечал, обычно архив в таком формате создают с расширением backup, я так и поступаю, т.е. архив назову shop.backup и сохраню его в каталоге D:\PostgreSQL_Backup\.
В нашем случае база данных небольшая, поэтому мы можем оставить все по умолчанию.
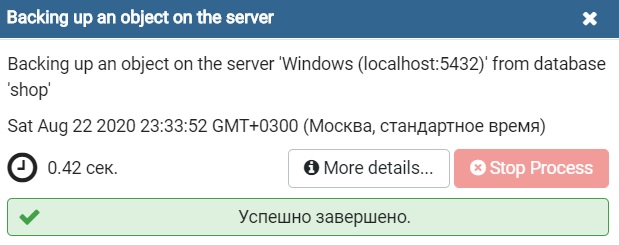
Создание дампа базы данных в простом формате SQL
Импорт дампа базы данных PostgreSQL в pgAdmin 4
Дамп готов, теперь можно переходить к восстановлению базы данных из этого дампа. Однако перед тем как приступать к импорту, необходимо создать пустую базу данных, в которую собственно и импортировать все данные, как это делается, я подробно рассказывал в отдельном материале.
Импорт сжатого дампа базы данных
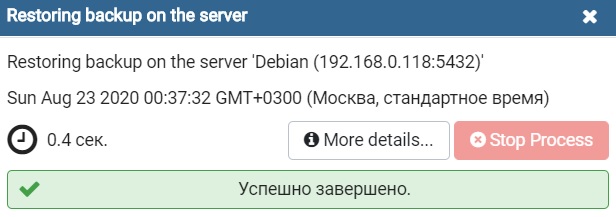
В результате все данные будут восстановлены из дампа, и таким образом мы перенесли базу данных PostgreSQL на новый сервер.
Импорт дампа базы данных в формате SQL
В случае с простым форматом, т.е. с обычными SQL инструкциями, использовать отдельный функционал для восстановления не получится, поэтому мы можем просто выполнить SQL скрипт, который содержится в этом файле.
Если инструкция выполнится без ошибок, значит, все хорошо.
Примечание! Если Вы уже восстановили базу данных предыдущим способом, то, чтобы использовать этот способ, необходимо пересоздать базу данных, иначе возникнет конфликт и, соответственно, ошибка, так как все объекты в базе уже будут существовать.
В итоге мы перенесли базу данных PostgreSQL с одного сервера, который управляется операционной системой Windows, на другой, который управляется Linux, хотя это, как Вы понимаете, в нашем случае было не так принципиально.
Стоит отметить, что если требуется перенести базу данных, размер которой достаточно большой, например, несколько десятков или сотен гигабайт, то лучше напрямую использовать консольные утилиты pg_dump или pg_dumpall, т.е. без графического интерфейса pgAdmin 4.
Видео – Перенос базы данных PostgreSQL на другой сервер с помощью pgAdmin 4

P ostgreSQL претендует на звание самой передовой базы данных с открытым исходным кодом в мире, и вполне заслуженно. Основные технические возможности, производительность и рабочие характеристики позволяют относить ее к числу ведущих баз данных для коммерческого использования, делая ее очень подходящей, экономически эффективной альтернативой как для стартапов, так и для крупных компаний, которым необходимо хранить данные и осуществлять управление ими.
Постараемся здесь дать исчерпывающее, разв е рнутое представление об этой замечательной системе управления базами данных — от установки, настройки, резервного копирования и восстановления с помощью barman 2.11 и до репликации и переключения с использованием repmgr 5.0.0 на Ubuntu 20.10. Акцент, впрочем, сделаем на достижении конкретных результатов, целей и задач. Поэтому особое внимание уделим соответствующим этапам и командам, оставив в стороне фоновые сведения и подробные объяснения.
Задействуем три физических компьютера или три виртуальные машины ( database-1 , database-2 и backup ). Каждый компьютер или машину запускаем на ubuntu 20.10 и подключаем к подсоединенному хранилищу, смонтированному в /backup :

Начальная настройка инфраструктуры
Убедитесь, что DNS правильно сконфигурирован на каждой из машин — наше руководство будет ссылаться не на IP-адреса, а только на имена хостов.
Установка Postgres
- Устанавливаем закадычных друзей: sudo apt -y install vim bash-completion wget joe .
- Теперь обновляем определения пакетов apt: apt-get update .
- Устанавливаем postgresql 12: apt install postgresql .
- Устанавливаем интерфейс командной строки barman: apt install barman-cli .
- Проверяем состояние запущенной службы: systemctl status postgresql.service .
- Проверяем подключение postgres: su - postgres .
- Даем пользователю postgres более надежный пароль: psql -c "alter user postgres with password 'MyStrongAdminP@ssw0rd'" .
- То же самое проделываем на уровне ОС (с тем же паролем). Выполняем с правами администратора passwd postgres .
- Затем перезагружаем машину.
- Повторяем эти пункты для машины database-2 .
- На обоих серверах баз данных от имени пользователя postgres создаем файл ~/.bash_rc и добавляем следующее содержимое:
- И добавляем эти строчки привилегированному пользователю root в ~/.bashrc на обоих серверах.
Конфигурация Postgres
- конфигурируем /etc/postgresql/12/main/postgresql.conf следующим образом:
- редактируем /etc/postgres/12/main/pg_hba.conf и добавляем следующие строки (здесь уже содержится конфигурация репликации, которая потом понадобится для repmgr ):
- создаем начальную структуру базы данных (на этом этапе она может быть любой).
- Запускаемся с нового сервера резервного копирования на ubuntu 20.10.
- В backup устанавливаем barman: apt-get install barman barman-cli .
- Создаем закрытый ключ для пользователя postgres и пользователя barman в
database-1 и backup соответственно. - В database-1 меняем на пользователя postgres su - postgres и генерируем пару ключей: ssh-keygen -b 2048 -t rsa -N "" -C "postgres@database-1" .
- В database-2 меняем на пользователя postgres su - postgres и генерируем пару ключей: ssh-keygen -b 2048 -t rsa -N "" -C "postgres@database-2" .
- В backup меняем на пользователя barman su - barman и создаем пару ключей: ssh-keygen -b 2048 -t rsa -N "" -C "barman@backup" .
- Добавляем открытый ключ postgres и barman соответственно к
~/.ssh/authorized_keys :
- С каждой из машин подключаем одну к другой, используя соответствующее имя пользователя и полное имя хоста:
- В backup перемещаем файл /etc/barman.conf в /etc/barman.conf.orig и воссоздаем его со следующим содержимым:
- Настраиваем входящие в WAL — в backup получаем этот каталог с barman show-server database-1 | grep incoming_wals_directory : should be incoming_wals_directory: /backup/barman/database-1/incoming .
- Убеждаемся, что этот путь такой же, как и на postgresql.conf в archive_command .
- Выводим список всех доступных серверов резервного копирования: barman list-server .
- Проверяем архивацию WAL-журнала и все остальные части нашего сервера: barman check database-1 .

- Тестируем архивацию WAL-журнала с
barman switch-wal --force --archive database-1 . - Если видите строку WAL archive: FAILED (please make sure WAL shipping is setup) , это означает одно из трех: 1) возможно, база данных еще не создала никаких файлов в WAL; 2) они уже были удалены; 3) rsync не работает. Загляните в логи PostgreSQL: там все ответы.
Но если rsync работает правильно и никаких данных в базу данных фактически не записывается, то сервер не будет выдавать никаких WAL-файлов. Стало быть, резервную копию создавать не из чего. WAL-файлы создаются после получения определенного объема данных. Рекомендую создать таблицу и добавить в нее данные. Для принудительного закрытия текущего WAL-файла используйте: barman switch-wal --force --archive database-1 .
- Создаем базовую резервную копию: barman backup database-1 .
- Выводим список всех имеющихся резервных копий для одного сервера barman list-backup database-1 :
- Более подробная информация из конкретной резервной копии получается с помощью: barman show-backup server-a 20210209T115342 .
- Планируем резервное копирование с помощью cron:
- barman cron выполняется каждую минуту (операции архивирования WAL-журнала проходят параллельно на серверной основе, при этом обеспечивается соблюдение политик хранения на этих серверах).
- Выполняем резервное копирование базы данных каждый день в полночь.
- Удаляем /etc/cron.d в backup .
barman check database-1 — проверка конфигурации barman для конкретного сервера.
barman status database-1 — показ состояния конкретного сервера.
barman backup database-1 — создание резервной копии для конкретного сервера.
barman backup --reuse=link main — принудительное добавочное резервное копирование.
barman list-backup database-1 — вывод списка всех доступных резервных копий на конкретном сервере.
barman show-backup database-1 п — показ содержимого резервной копии.
barman show-backup database-1 latest — показ последней доступной резервной копии.
- Подключаемся к схеме баз данных database-1 и удаляем часть данных, некоторые таблицы или базы данных, имитируя аварийную ситуацию.
- Выключаем целевой сервер postgres на database-1 :
systemctl stop postgresql.service . - В backup от имени пользователя barman просматриваем последнюю резервную копию barman barman show-backup database-1 latest :


- Перезагружаем блок со 2-й базой данных database-2 .
- Теперь сервер баз данных восстановлен из резервной копии.
В случае если резервная копия базы данных не подлежит восстановлению и повреждена, практически ничего другого не остается, кроме как прибегнуть к жесткой перезагрузке кластера pg без переустановки контейнера базы данных. Для этого используют следующую процедуру. ВНИМАНИЕ. Это приведет к удалению всех данных.
- А теперь выполните описанную выше процедуру настройки кластера PostgreSQL в /etc/postgres/. , ведь вся последняя конфигурация была удалена.
- Если сервер Postgres не появляется после восстановления, посмотрите подробные логи запуска с помощью следующей команды:
Для настройки репликации между узлами postgres database-1 и database-2 будем использовать repmgr:
- В обоих блоках баз данных устанавливаем repmgr apt-get install postgresql-12-repmgr .
- В database-1 (основной узел) создаем пользователя repmgr и базу данных и выполняем от имени пользователя postgres следующее: createuser --superuser repmgr createdb --owner=repmgr repmgr .
- Меняем путь поиска пользователя repmgr по умолчанию:
psql -c "ALTER USER repmgr SET search_path TO repmgr, public;" . - Редактируем /etc/postgresql/12/main/postgresql.conf и добавляем следующую строку shared_preload_libraries = 'repmgr' . При запуске PostgreSQL будет загружено расширение repmgr.
- В database-1 создаем стандартный конфигурационный файл repmgr touch /etc/repmgr.conf и добавляем следующее:
- В database-1 редактируем /etc/default/repmgrd и применяем следующее содержимое:
- В database-2 создаем стандартный конфигурационный файл repmgr touch /etc/repmgr.conf и добавляем следующее:
- В database-2 редактируем /etc/default/repmgrd и применяем следующее содержимое:
- Чтобы репликация работала, database-1 должна принять подключение репликации от database-2 . Реплика запрашивает информацию о репликации, а не наоборот. В database-1 удостоверяемся в наличии следующей конфигурации в /etc/postgresql/12/main/pg_hba.conf (она у вас уже должна быть):
- От имени пользователя postgres регистрируем в database-1 основной узел database-1 с repmgr /usr/bin/repmgr -f /etc/repmgr.conf primary register :
- Проверяем состояние кластера /usr/bin/repmgr -f /etc/repmgr.conf cluster show :

- Запускаем с правами администратора root repmgrd в database-1 : /etc/init.d/repmgrd start .
- Настраиваем 2-й узел, переключаемся на database-2 и останавливаем postgresql /etc/init.d/postgresql stop .
- Выполняем от имени пользователя postgres : /usr/bin/repmgr -h database-1 -U repmgr -d repmgr -p 5432 -F -f /etc/repmgr.conf standby clone --dry-run .
- По завершении выполняем операцию клонирования /usr/bin/repmgr -h database-1 -U repmgr -d repmgr -p 5432 -F -f /etc/repmgr.conf standby clone :
- На этом этапе PostgreSQL не работает в резервных узлах. Хотя у резервного узла есть скопированный из основного узла каталог данных Postgres, в том числе любые имеющиеся там конфигурационные файлы PostgreSQL.
- Теперь запускаем службу postgresql на вторичном узле /etc/init.d/postgresql start .
- Регистрируем от имени пользователя postgres вторичный узел с repmgr /usr/bin/repmgr -f /etc/repmgr.conf standby register :
- Теперь проверим настройку кластера repmgr:
/usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact

- Самое время протестировать репликацию: на основном сервере database-1 создаем базы данных, таблицы, записи и видим мгновенные изменения на database-2 → поддерживает идеальную синхронизацию со вспомогательным сервером. Отличная работа!
- Наша цель — с помощью repmgr переключиться с первичного узла/сервера на вторичный и обратно.
- Перед переключением обратимся к настройке кластера sudo -u postgres /usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact :

- Выполняем переключение в database-2 :
/usr/bin/repmgr standby switchover -f /etc/repmgr.conf :
- На ubuntu с командой /usr/lib/postgresql/12/bin/pg_ctl -w -D '/var/lib/postgresql/12/main' start , скорее всего, возникнут проблемы: PQping() returned "PQPING_NO_RESPONSE" будет появляться несколько раз, пока не истечет время ожидания. В этом случае запустите postgres вручную на database-1 в то время, когда будут повторные попытки подключиться к /etc/init.d/postgresql start .
- А теперь проверим настройку кластера repmgr: sudo -u postgres /usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact :

- Сейчас кластер repmgr работает с database-2 в качестве основного узла.
- Выполняем обратное переключение в database-1 от имени пользователя postgres : /usr/bin/repmgr standby switchover -f /etc/repmgr.conf .
- Опять же, в этом сценарии на ubuntu у postgres возможны проблемы с правильным возвращением на database-2 . Здесь тоже запускаем postgres с правами администратора root с помощью /etc/init.d/postgres start .
- Проверим настройку кластера repmgr: sudo -u postgres /usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact :

- Возможны ситуации, когда проще удалить текущую и, быть может, поломанную конфигурацию repmgr и начать все сначала. В этом случае в основном узле от имени пользователя postgres выполняем:
Поздравляю, мы настроили PostgreSQL с резервным копированием, полной репликацией и научились переключаться с основного узла базы данных на вторичный и обратно без риска для данных.
В добавок ко всему этому неплохо было бы выполнять полное текстовое резервное копирование с применением статической диспетчеризации (например, каждое воскресенье) с помощью pg_dumpall | gzip > backup.gz . Ведь когда-нибудь может понадобиться полный дамп всего содержимого кластера баз данных в текстовом формате для использования на разных ОС, версиях PostgreSQL или даже в разных системах управления базами данных.
А кроме того, мы еще не рассматривали то, как с переключением справляется прикладной уровень. Здесь возможны варианты: использовать средство балансировки нагрузки для принятия фактического решения о том, к какому серверу базы данных подключиться клиенту, или создать и настроить эту возможность на прикладном уровне.
Читайте также: