Склеить две строки в си
Добавил пользователь Cypher Обновлено: 04.10.2024
Строка -- это последовательность ASCII или UNICODE символов.
Строки в C, как и в большинстве языков программирования высокого уровня рассматриваются как отдельный тип, входящий в систему базовых типов языка. Так как язык C по своему происхождению является языком системного программирования, то строковый тип данных в C как таковой отсутствует, а в качестве строк в С используются обычные массивы символов.
Исторически сложилось два представления формата строк:
- формат ANSI;
- cтроки с завершающим нулем (используется в C).
Формат ANSI устанавливает, что значением первой позиции в строке является ее длина, а затем следуют сами символы строки. Например, представление строки "Моя строка!" будет следующим:
11 'М' 'о' 'я' ' ' 'с' 'т' 'р' 'о' 'к' 'а' '!'
В строках с завершающим нулем, значащие символы строки указываются с первой позиции, а признаком завершения строки является значение ноль. Представление рассмотренной ранее строки в этом формате имеет вид:
'М' 'о' 'я' ' ' 'с' 'т' 'р' 'о' 'к' 'а' '!' 0
Объявление строк в C
Строки реализуются посредством массивов символов. Поэтому объявление ASCII строки имеет следующий синтаксис:
char имя[длина];
Объявление строки в С имеет тот же синтаксис, что и объявление одномерного символьного массива. Длина строки должна представлять собой целочисленное значение (в стандарте C89 – константа, в стандарте C99 может быть выражением). Длина строки указывается с учетом одного символа на хранение завершающего нуля, поэтому максимальное количество значащих символов в строке на единицу меньше ее длины. Например, строка может содержать максимально двадцать символов, если объявлена следующим образом:
char str[21]; Инициализация строки в С осуществляется при ее объявлении, используя следующий синтаксис:
char str[длина] = строковый литерал;
Строковый литерал – строка ASCII символов заключенных в двойные кавычки. Примеры объявления строк с инициализацией:
char str1[20] = "Введите значение: ", str2[20] = "";
Работа со строками в С
Так как строки на языке С являются массивами символов, то к любому символу строки можно обратиться по его индексу. Для этого используется синтаксис обращения к элементу массива, поэтому первый символ в строке имеет индекс ноль. Например, в следующем фрагменте программы в строке str осуществляется замена всех символов 'a' на символы 'A' и наоборот.
for(int i = 0; str[i] != 0; i++)
if (str[i] == 'a') str[i] = 'A';
else if (str[i] == 'A') str[i] = 'a';
>
Массивы строк в С
Объявление массивов строк в языке С также возможно. Для этого используются двумерные массивы символов, что имеет следующий синтаксис:
char имя[количество][длина];
Первым размером матрицы указывается количество строк в массиве, а вторым – максимальная (с учетом завершающего нуля) длина каждой строки. Например, объявление массива из пяти строк максимальной длиной 30 значащих символов будет иметь вид:
При объявлении массивов строк можно производить инициализацию:
char имя[количество][длина] = ;
Число строковых литералов должно быть меньше или равно количеству строк в массиве. Если число строковых литералов меньше размера массива, то все остальные элементы инициализируются пустыми строками. Длина каждого строкового литерала должна быть строго меньше значения длины строки (для записи завершающего нуля).
char days[12][10] = <
"Январь", "Февраль", "Март", ”Апрель", "Май",
"Июнь", "Июль", "Август", "Сентябрь","Октябрь",
"Ноябрь", "Декабрь"
>;
При объявлении массивов строк с инициализацией допускается не указывать количество строк в квадратных скобках. В таком случае, количество строк в массиве будет определено автоматически по числу инициализирующих строковых литералов.
Например, массив из семи строк:
char days[][12] = <
"Понедельник", "Вторник", "Среда", "Четверг",
"Пятница", "Суббота", "Воскресенье"
>;
Функции для работы со строками в С
Все библиотечные функции, предназначенные для работы со строками, можно разделить на три группы:
- ввод и вывод строк;
- преобразование строк;
- обработка строк.
Ввод и вывод строк в С
Для ввода и вывода строковой информации можно использовать функции форматированного ввода и вывода (printf и scanf). Для этого в строке формата при вводе или выводе строковой переменной необходимо указать спецификатор типа %s. Например, ввод и последующий вывод строковой переменной будет иметь вид:
char str[31] = "";
printf("Введите строку: ");
scanf("%30s”,str);
printf("Вы ввели: %s”,str);
Недостатком функции scanf при вводе строковых данных является то, что символами разделителями данной функции являются:
- перевод строки,
- табуляция;
- пробел.
Функция gets предназначена для ввода строк и имеет следующий заголовок:
char * gets(char *buffer);
Между тем использовать функцию gets категорически не рекомендуется, ввиду того, что она не контролирует выход за границу строки, что может произвести к ошибкам. Вместо нее используется функция fgets с тремя параметрами:
char * fgets(char * buffer, int size, FILE * stream);
где buffer - строка для записи результата, size - максимальное количество байт, которое запишет функция fgets, stream - файловый объект для чтения данных, для чтения с клавиатуры нужно указать stdin. Эта функция читает символы со стандартного ввода, пока не считает n - 1 символ или символ конца строки, потом запишет считанные символы в строку и добавит нулевой символ. При этом функция fgets записывает в том символ конца строки в данную строку, что нужно учитывать.
Функция puts предназначена для вывода строк и имеет следующий заголовок:
int puts(const char *string);
Простейшая программа: ввод и вывод строки с использованием функций fgets и puts будет иметь вид:
char str[102] = "";
printf("Введите строку: ");
fgets(str, 102, stdin);
printf("Вы ввели: ");
puts(str);
Для считывания одного символа можно использовать функцию fgetc(FILE * stream) . Она считывает один символ и возвращает значение этого символа, преобразованное к типу int, если же считывание не удалось, то возвращается специальная константа EOF, равная -1. Функция возвращает значение -1 для того, чтобы можно было обрабатывать ситуацию конца файла, посимвольное чтение до конца файла можно реализовать следующим образом:
int c;
while ((c = fgetc(stdin)) != EOF) // Обработка символа
>
Для вывода одного символа можно использовать функцию int fputc(int c, FILE *stream); .
Помимо функций ввода и вывода в потоки в библиотеке stdio.h присутствуют функции форматированного ввода и вывода в строки. Функция форматированного ввода из строки имеет следующий заголовок:
int sscanf(const char * restrict buffer, const char * restrict string, [address] . );
Функции форматированного вывода в строку имеют следующие заголовки:
int sprintf(char * restrict buffer,
const char * restrict format, [argument] . );
int snprintf(char * restrict buffer, size_t maxsize,
const char * restrict format, [argument] . );
Преобразование строк
В С для преобразования строк, содержащих числа, в численные значения в библиотеке stdlib.h
предусмотрен следующий набор функций:
double atof(const char *string); // преобразование строки в число типа double
int atoi(const char *string); // преобразование строки в число типа int
long int atol(const char *string); // преобразование строки в число типа long int
long long int atoll(const char *string); // преобразование строки в число типа long long int
Корректное представление вещественного числа в текстовой строке должно удовлетворять формату:
После символов E, e указывается порядок числа. Корректное представление целого числа в текстовой строке должно удовлетворять формату:
Помимо приведенных выше функций в библиотеке stdlib.h доступны также следующие функции преобразования строк в вещественные числа:
float strtof(const char * restrict string, char ** restrict endptr);
double strtod(const char * restrict string, char ** restrict endptr);
long double strtold(const char * restrict string,char ** restrict endptr);
Аналогичные функции присутствуют и для преобразования строк в целочисленные значения:
long int strtol(const char * restrict string, char ** restrict endptr, int base);
unsigned long strtoul(const char * restrict string,
char ** restrict endptr, int base);
long long int strtoll(const char * restrict string,
char ** restrict endptr, int base);
unsigned long long strtoull(const char * restrict string,char ** restrict endptr, int base);
Функции обратного преобразования (численные значения в строки) в библиотеке stdlib.h присутствуют, но они не регламентированы стандартом, и рассматриваться не будут. Для преобразования численных значений в строковые наиболее удобно использовать функции sprintf и snprintf.
Обработка строк
В библиотеке string.h содержаться функции для различных действий над строками.
Функция вычисления длины строки:
size_t strlen(const char *string);
Функции копирования строк:
char * strcpy(char * restrict dst, const char * restrict src);
char * strncpy(char * restrict dst, const char * restrict src, size_t num);
Функции сравнения строк:
int strcmp(const char *string1, const char *string2);
int strncmp(const char *string1, const char *string2,size_t num);
Функции осуществляют сравнение строк по алфавиту и возвращают:
положительное значение – если string1 больше string2;
отрицательное значение – если string1 меньше string2;
нулевое значение – если string1 совпадает с string2;
Функции объединения (конкатенации) строк:
char * strcat(char * restrict dst, const char * restrict src);
char * strncat(char * restrict dst, const char * restrict src, size_t num);
Функции поиска символа в строке:
Функция поиска строки в строке:
char * strstr(const char *str, const char *substr);
Функция поиска первого символа в строке из заданного набора символов:
size_t strcspn(const char *str, const char *charset);
Функции поиска первого символа в строке не принадлежащему заданному набору символов:
size_t strspn(const char *str, const char *charset);
Функции поиска первого символа в строке из заданного набора символов:
char * strpbrk(const char *str, const char *charset);
Функция поиска следующего литерала в строке:
char * strtok(char * restrict string, const char * restrict charset);
Привет, друзья! Сегодня немного покодим. Попробуйте подумать без использования компилятора. Какой код правильно справится с данной задачей?
Что такое строки в языке C ?
В языке C, как и в компьютере в целом, строки представлены набором чисел, где на каждую букву приходится некоторый числовой код, по которому операционная система определяет какой символ нарисовать пользователю. Происходит это в соответствии с таблицами кодировок ( ASCII или UTF-8 , или другие). Хранить строки можно в массивах из переменных типа char. Каждый символ типа char хранит 1 байт ( 8 бит данных ). Вспоминаем формулу для мощности алфавита, получается, что если на один символ выделяется 8 бит, то мы можем закодировать 256 символов (еще в 1963 году в ASCII было 7 бит, но потом её расширили до 8 бит).
Как компилятор определяет конец строки?
Строка в C заканчивается терминальным символом '\0'. Да, здесь как бы два символа, но для компилятора это один символ, числовое значение которого 0, т.е. массив типа char заканчивается нулем.
Рассмотрим другой пример заполнения. В готовую переменную word присвоим строковый литерал. Строка "Math" заканчивается терминальным символом '\0'.
В итоге строки выводятся компилятором корректно.
А как считать строку с консоли в языке C ?
Для начала нужно создать переменную под нашу строку, т.е. создать переменную для массива типа char. При этом размер нужно выбрать такой, чтобы поместилась введенная нами строка.
Всегда есть опасность, что пользователь случайно или намеренно введет данные, которые не поместятся в массив. Тогда может возникнуть переполнение буфера, что повлечет затирание соседних данных. Специально такие уязвимости используются для проведения атак (инъекций), при которых нужные байты записываются в нужные места, для организации перехода на участок кода с вредоносной программой. Еще это может использоваться для логгирования данных программы (запись действий, совершенных программой).
Как самостоятельно определить длину строки?
Напишем небольшой код, который будет считывать введенную строку и находить её длину.
Это прекрасно работает в онлайн-компиляторах. Также этот код легко запустится, если написать его в любом текстовом редакторе, сохранить с расширением .c или .cpp , а потом запустить через терминал (или командную строку) с помощью компилятора GCC .
Но проблема может возникнуть в том случае, если вы попытаетесь запустить такой код в Microsoft Visual Studio ( MVS ), начиная с 2015 года выпуска. Дело в том, что там напихали своих безопасных версий этих функций, которые добавляют проблем начинающим. Вместо того, чтобы думать о логике кода, приходится бороться с ошибками IDE.
Самое интересное, что ни одно из представленных решений в поисковике (на первой странице) не сработало. То ли я дурак, то ли сани не едут. Поправьте, если знаете конкретное решение для 2015 MVS.
Прикрепляю код, единственный вариант, который удалось довести до работы без ошибок конкретно в 2015-й студии.
А можно ли сравнить два слова в языке C ?
Да, можно. Помните, что в начале статьи мы говорили о том, что каждая буква (каждый символ char) хранит числовое значение. Получается, что символы можно сравнить между собой также, как и числа. В большинстве случаев буквы в таблицах кодировок располагаются в алфавитном порядке. Это значит, что сортировка по числовым значениям соответствующих букв и состоящих из них строк будет являться сортировкой по алфавиту. Правда проблемы могут возникать с заглавными буквами и дополнительными символами, вроде апострофов. Но это пока опустим.
Как удалить элемент из массива символов или строки?
Есть такая полезная функция memcpy, полное определение которой будет следующим:
void * memcpy ( void * destptr, const void * srcptr, size_t num );
Эта функция копирует num первых байтов, на которые ссылается указатель srcptr (source pointer) в блок памяти, на который указывает destptr(destination pointer). Будьте аккуратны, данная функция не проверяет есть ли символ завершения в источнике srcptr. Поэтому возможно переполнение.
- destptr
Указатель на блок памяти назначения (куда будут копироваться байты данных), имеет тип данных void. - srcptr
Указатель на блок памяти источник (т. е., откуда будут копироваться байты данных), имеет тип данных void. - num
Количество копируемых байтов.
Вы спросите: "при чем здесь числа, если речь шла о строках?". Дело в том, что строки тоже представляются числами. А функции, работающей с памятью, не важно какие байты перемещать.
Поэтому аналогично можно удалить букву из слова:
Что еще можно сделать с помощью функции копирования участка памяти из одной области в другую? Можно написать функцию, которая меняет местами две переменные:
Нужно сделать замечание: выделение памяти является дорогостоящей операцией. Если мы хотим улучшить производительность функции, то в качестве буфера нужно передать временную переменную, которая будет создана только один раз, независимо от количества вызовов функции swap:
А что делать, если области памяти пересекаются?
Здесь тоже есть выход. Мы можем использовать следующую функцию:
void * memmove ( void * destination, const void * source, size_t num);
Данная функция копирует num байт из источника source в пункт назначения destination. При этом области могут пересекаться. При копировании используется промежуточный буфер, который справится с проблемой перекрытия областей.
Функция для копирования одной строки в другую
char * strcpy ( char * destination, const char * source );
Копирует одну строку в другую, вместе с нулевым символом. Также возвращает указатель на destination.
Есть еще функция, которая очень похожа на предыдущую:
char * strncpy ( char * destination, const char * source, size_t num);
Вызов данной функции скопирует только num первых букв строки. Терминальный символ \0 автоматически НЕ добавляется. При копировании из строки в эту же строку не должны пересекаться области. Если это происходит, то нужно использовать ранее рассмотренную функцию memmove().
Конкатенация строк: как склеить две строки в одну?
Существуют две функции из стандартной библиотеки
char * strcat ( char * destination, const char * source);
Добавляет в конец destination строку source, при этом затирая первым символом нулевой. Возвращает указатель на destination.
char * strncat ( char * destination, const char * source, size_t num);
Добавляет в конец строки destination num символов второй строки. В конец добавляется нулевой символ.
Сравнение строк через библиотечную функцию
Также для сравнения можно использовать стандартные функции:
int strcmp ( const char * str1, const char * str2);
Возвращает 0, если строки равны, больше нуля, если первая строка больше, меньше нуля, если первая строка меньше. Сравнение строк происходит посимвольно, сравниваются численные значения. Для сравнения строк на определённом языке используется strcoll
int strcoll ( const char * str1, const char * str2);
int strncmp ( const char * str1, const char * str2, size_t num);
сравнение строк по первым num символам.
Пример - сортировка массива строк по первым трём символам:
Работа с локалью или что такое locale.h ?
Существует заголовочный файл из стандартной библиотеки для решения задач, связанных с локализацией. В locale содержится информация о том, как нужно выполнять определенные операции ввода/вывода и преобразования с учетом географического расположения и особенностей языков.
Поиск в строке
Рассмотрим следующую функцию:
void * memchr ( void * memptr, int val, size_t num );
Функция memchr описана в заголовочном файле string.h (для C) или в cstring (для C++) и находит в блоке памяти, на который указывает memptr первое вхождение символа val , а после возвращает указатель на найденный символ. Ищет среди первых num байтов.
Если нужно работать только со строками, а не с произвольным наборов байт, то можно использовать функцию:
char * strchr ( char * str, int character); - выполняет поиск первого вхождения символа character в строку str. При этом учитывается нулевой терминальный символ. То есть он также может быть найден, чтобы получить указатель на конец строки.
Также можно использовать:
size_t strcspn ( const char * str1, const char * str2 );
Возвращает адрес первого вхождения любой буквы из строки str2 в строке str1. Если ни одно включение не найдено, то возвратит длину строки.
Поиск положение всех гласных в строке
Стоит обратить внимание на строку i++ после printf. Если бы её не было, то strcspn возвращал бы всегда 0, потому что в начале строки стояла бы гласная, и произошло зацикливание.
Для решения этой задачи гораздо лучше подошла функция, которая возвращает указатель на первую гласную:
char * strpbrk ( char * str1, const char * str2) - эта функция похожа на strcspn(), но возвращает указатель на первый символ из строки str1, который есть в строке str2. Аналогичная задача по поиску гласных реализовывалась бы так:
Получается, что для работы со строками в языке C могут понадобиться следующие заголовочные файлы:
string.h — заголовочный файл стандартной библиотеки языка Си, содержащий функции для работы со строками, оканчивающимися на 0, и различными функциями работы с памятью.
Понравилась заметка? Поставьте лайк, подпишитесь на канал, поделитесь заметкой в социальных сетях! Вам не сложно, а мне очень приятно :)
На этом шаге мы приведем примеры использования строковых функций.
Определение длины строк.
Длина строки определяется просто. Для этого нужно передать строковый указатель функции strlen() , которая возвратит длину строки, выраженную в символах. После объявления
Затем используйте функцию strlen() для установки целой переменной len , равной числу символов в литеральной строке, скопированной в буфер:
Копирование строк.
Оператор присваивания для строк не определен. Если с1 и с2 - символьные массивы, вы не сможете скопировать один в другой следующим образом:
Но если с1 и с2 объявить как указатели типа char * , компилятор согласится с этим оператором, но вряд ли вы получите ожидаемый результат. Вместо копирования символов из одной строки в другую оператор с1 = с2 скопирует указатель с2 в указатель с1 , перезаписав, таким образом, адрес в с1 , потенциально потеряв информацию, адресуемую указателем.
Чтобы скопировать одну строку в другую, вместо использования оператора присваивания вызовите функцию копирования строк strcpy() . Для двух указателей с1 и с2 типа char * оператор
копирует символы, адресуемые указателем с2 , в память, адресуемую указателем с1 , включая завершающие нули. И только на вас лежит ответственность за то, что принимающая строка будет иметь достаточно места для хранения копии.
Аналогичная функция strncpy() ограничивает количество копируемых символов. Если источник ( source ) и приемник ( destination ) являются указателями типа char * или символьными массивами, то оператор
скопирует до 10 символов из строки, адресуемой указателем source , в область памяти, адресуемую указателем destination . Если строка source имеет больше 10 символов, то результат усекается. Если же меньше - неиспользуемые байты результата устанавливаются равными нулю.
Замечание. Строковые функции, в имени которых содержится дополнительная буква n , объявляют числовой параметр, ограничивающий некоторым образом действие функции. Эти функции безопаснее, но медленнее, чем их аналоги, не содержащие букву n . Программные примеры содержат следующие пары функций: strcpy() и strncpy() , strcat() и strncat() , strcmp() и strncmp() .
Дублирование строк.
Использование механизма дублирования строк разберем на конкретном примере: создадим функцию, которая выводила бы приглашение и возвращала строку, введенную с клавиатуры. Желательно, чтобы эта строка запоминалась в куче и она занимала бы ровно столько байтов, сколько требуется.
Текст примера 2 образет один маленький модуль с единственной функцией GetStringAt() , которая удовлетворяет этим требованиям, используя другую строковую функцию strdup() для того, чтобы сделать копию выводимой строки. Другие примеры этого раздела используют модуль c64_2.cpp .
Файл c64_2.h - заголовочный: он содержит только объявления для включения в другие модули. Файл c64_2.cpp - это отдельный модуль, содержащий функцию (их может быть несколько), используемую в программе. Ни один из этих файлов не является законченной программой, поэтому не пытайтесь компилировать и запускать их. Ниже мы вспомним, как это можно сделать (см. пример 4 шага 53).
Пример 2а. Текст заголовочного файла c64_2.h .
Пример 2б. Текст модуля c64_2.cpp .
Указанный модуль включает свой собственный заголовочный файл, который определяет константу MAXLEN и объявляет прототип функции GetStringAt() . Внутри этой функции расположено объявление статической строки buffer . Использование ключевого слова static создает переменную, которая постоянно хранится в сегменте данных, но доступна только внутри функции GetStringAt() .
Статическая строка buffer служит для запоминания текста, введенного с помощью клавиатуры. Этот текст копируется в новую строку, возвращаемую функцией. Причиной использования именно статической переменной buffer является требование, чтобы функции хватило места для запоминания ввода. Но один недостаток этого метода состоит в том, что буфер перезаписывается при каждом вызове функции, которую, следовательно, нельзя вызывать рекурсивно. Применение статического буфера не является обязательным условием - вы могли бы написать функцию GetStringAt() с использованием локальной переменной или строки, запомненной в куче.
Оператор if проверяет параметр size . Если его значение находится вне заданного диапазона, то ему присваивается значение MAXLEN .
После позиционирования курсора с помощью вызова функции gotoxy() в цикле while вызывается функция getchar() , которая ожидает, пока вы введете символ. Программа присваивает этот символ переменной c и проверяет на совпадение с EOF ( end of file - конец файла, означающий, что источник ввода закрыт) или с управляющим символом \n ("новая строка", означающая, что вы нажали клавишу Enter ). Если одно из этих условий оказалось выполненным, программа устанавливает параметр size равным нулю, завершая тем самым цикл while . В противном случае программа присваивает значение переменной c элементу массива buffer с индексом i , инкрементированным оператором ++ для подготовки к вводу следующего символа.
Замечание. Выполните цикл while по шагам, используя клавишу F7 , наблюдая при этом за значениями переменных buffer , c и i .
Затем добавляется нулевой символ (литеральное выражение '\0') за последним символом, запомненным в строке buffer . После этого вызывается функция fflush() , с аргументом stdin , который является встроенным символом, представляющим стандартный файл ввода. Вызов функции fflush() очищает "повисший" символ новой строки, который может привести к тому, что функция getchar() (и другие функции ввода) не будет делать паузу для ожидания ввода.
И, наконец, в строке return strdup(buffer); возвращается результат функции GetStringAt() . Этот оператор передает строку buffer функции strdup() , которая создает копию символов и возвращает адрес дубликата строки.
Функция strdup() (ее название говорит само за себя) возвращает адрес дубликата строки, адресуемой ее аргументом. Строка создается с помощью вызова функции malloc() и занимает столько памяти, сколько необходимо. Если переменная c имеет тип char * , то оператор
выделит ровно 16 байт памяти кучи, скопирует в эту область памяти 15-символьную строку "Двойная тревога" плюс завершающий нуль и возвратит адрес этой области. По окончании работы с этой строкой следует освободить эту область памяти обычным способом:
Замечание. Можно модифицировать строки, создаваемые функцией strdup() , но при этом нельзя расширять их за пределы отведенных им объемов памяти. Если все-таки это сделать необходимо, то нужно скопировать строку в новый, больший по объему буфер, а затем освободить первоначальную строку.
Пример 3. Иллюстрация использования функции GetStringAt() .
Пример 3 демонстрирует применение функции GetStringAt() , объявленной в файле c64_2.h и описанной в файле c64_2.cpp . Чтобы создать законченную программу, вы должны скомпилировать c64_3.cpp и скомпоновать с модулем c64_2 . Произведем эти операции из командной строки, получив в результате DOS-приложение.
Первая команда компилирует модуль c64_2.cpp , создавая объектный файл с именем c64_2.obj который содержит скомпилированный код для функции GetStringAt() . Вторая команда компилирует модуль c64_3.cpp , создавая объектный файл с именем c64_3.obj , а также компонует эти два объектных файла и создает окончательный исполняемый файл c64_3.exe , который можное запустить в DOS .
осуществляется вызов функции GetStringAt() , с передачей ей трех аргументов: координаты х, координаты у и максимальной длины результата. Функция располагает курсор в заданном месте (полезная вещь при разработке экранов ввода данных) и ограничивает ввод требуемым числом символов.
программа проверяет результат функции GetStringAt() . Если она возвращает нуль, это значит, что функция strdup() не смогла создать копию ввода, возможно, из-за недостатка памяти в куче. Обратите внимание также на освобождение памяти после того, как она оказывается больше не нужной (конструкция free(s) ).
Сравнение строк.
Используя функцию GetStringAt() из предыдущего раздела, можно написать программу, которая предлагает ввести пароль. Чтобы определить правильность введенного пароля, воспользуемся функцией strcmp() , которая сравнивает две строки.
Пример 4. Иллюстрация использования функции strcmp() .
показано, как сравнивать две строки, в данном случае для того, чтобы определить правильность введенного пароля. Здесь переменная done получает значение "истина" (что соответствует любому ненулевому значению), если строка, адресуемая указателем s , и PASSWORD (макроопределение, которое расширяется в литеральную строку) равны. Если i - переменная типа int и если a и b - указатели на char или символьные массивы, то оператор
установит i равной -1 или другому отрицательному числу, если строка, адресуемая указателем a , в алфавитном порядке меньше строки, адресуемой указателем b . Если строки в точности совпадают, функция возвратит нуль. Она вернет +1 или другое положительное число, если строка a в алфавитном порядке больше строки b .
Функция strcmp() чувствительна к регистру букв - она считает строчные буквы больше их прописных эквивалентов (так как буквы нижнего регистра имеют большие значения кода ASCII, чем буквы верхнего регистра). Для сравнения двух строк без учета регистра вызовите функцию stricmp() . Буква i символизирует приказ ignore case ( игнорировать регистр ) . Эта функция действует аналогично функции strcmp() , но перед сравнением преобразует все буквы в прописные. Строка Apple алфавитно окажется меньше строки apple , если сравнение выполнялось с помощью функции strcmp() . Если же для сравнения использовать функцию stricmp() , то эти строки будут считаться идентичными.
Чтобы сравнить только часть двух строк, используйте функцию strncmp() . Например, оператор
установит целую переменную i равной нулю только в том случае, если первые два символа строк, адресуемых указателями s1 и s2 , в точности совпадают. Для безрегистрового сравнения вызывайте функцию strnicmp() .
Конкатенация строк.
Конкатенация двух строк означает их сцепление , при этом создается новая, более длинная строка. При объявлении строки
При вызове функции strcat() убедитесь, что первый аргумент типа char * инициализирован и имеет достаточно места, чтобы запомнить результат. Если c1 адресует строку, которая уже заполнена, а c2 адресует ненулевую строку, оператор strcat(c1, c2); перезапишет конец строки, вызвав серьезную ошибку.
Функция strcat() возвращает адрес результирующей строки (совпадающий с ее первым параметром) и может использоваться как каскад нескольких вызовов функций:
Этот оператор добавит строку, адресуемую c2 , и строку, адресуемую c3 , к строке, адресуемой c1 , что эквивалентно двум отдельным операторам:
Пример 5 показывает, как можно использовать функцию strcat() для получения в одной строке фамилии, имени и отчества, хранящихся отдельно, например, в виде полей базы данных. Введите фамилию, имя и отчество. Программа сцепит введенные вами строки и отобразит их как отдельную строку.
Пример 5. Иллюстрация использования функции strcat() .
Приведенная программа демонстрируют важный принцип конкатенации строк: всегда инициализируйте первый строковый аргумент . В данном случае символьный массив rez инициализируется вызовом функции strcpy() , которая вставляет fam в rez . После этого программа добавляет пробелы и две другие строки - im и otch . Никогда не вызывайте функцию strcat() с неинициализированным первым аргументом.
Если вы не уверены в том, что в строке достаточно места для присоединяемых подстрок, вызовите функцию strncat() , которая аналогична функции strcat() , но требует числового аргумента, определяющего число копируемых символов. Для строк s1 и s2 , которые могут быть либо указателями типа char * , либо символьными массивами, оператор
присоединяет и максимум четыре символа из s2 в конец строки s1 . Результат обязательно завершается нулевым символом.
Существует один способ использования функции strncat() , гарантирующий безопасную конкатенацию. Он состоит в передаче функции strncat() размера свободной памяти строки-приемника в качестве третьего аргумента. Рассмотрим следующие объявления:
Вы можете присоединить s2 к s1 , формируя строку "Кот в шляпе" , с помощью функции strcat() :
Если вы не уверены, что в s1 достаточно места, чтобы запомнить результат, используйте альтернативный оператор:
Этот способ гарантирует, что s1 не переполнится, даже если s2 нужно будет урезать до подходящего размера. Этот оператор прекрасно работает, если s1 - нулевая строка.

После того, как мы с вами познакомились со строками и символьными массивами в C++, рассмотрим самые распространённые функции для работы с ними. Урок будет полностью построен на практике. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring ( string.h – в старых версиях). Так вы примерно будете себе представлять, как они устроены. К стандартным функциям библиотеки cstring относятся:
- strlen() – подсчитывает длину строки (количество символов без учета \0);
- strcpy() – копирует символы одной строки в другую;
- strcmp() – сравнивает между собой две строки .
Это конечно не все функции, а только те, которые мы разберём в этой статье.
strlen() (от слова length – длина)
Наша программа, которая подсчитает количество символов в строке:
Для подсчёта символов в строке неопределённой длины (так как вводит её пользователь), мы применили цикл while – строки 13 – 17. Он перебирает все ячейки массива (все символы строки) поочередно, начиная с нулевой. Когда на каком-то шаге цикла встретится ячейка ourStr [amountOfSymbol] , которая хранит символ \0 , цикл приостановит перебор символов и увеличение счётчика amountOfSymbol .
Так будет выглядеть код, с заменой нашего участка кода на функцию strlen() :
Как видите, этот код короче. В нем не пришлось объявлять дополнительные переменные и использовать цикл. В выходном потоке cout мы передали в функцию строку – strlen(ourStr) . Она посчитала длину этой строки и вернула в программу число. Как и в предыдущем коде-аналоге, символ \0 не включен в общее количество символов.
Результат будет и в первой программе и во второй аналогичен:
![функция strlen () в C++]()
strcat() (от слова concatenation – соединение)
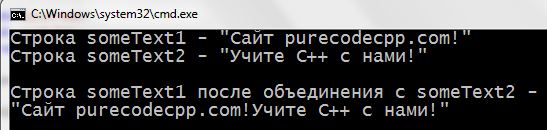
Программа, которая в конец одной строки, дописывает вторую строку. Другими словами – объединяет две строки.
По комментариям в коде должно быть всё понятно. Ниже напишем программу для выполнения таких же действий, но с использованием strcat() . В эту функцию мы передадим два аргумента (две строки) – strcat ( someText1 , someText2 ) ; . Функция добавит строку someText2 к строке someText1 . При этом символ '\0' в конце someText1 будет перезаписан первым символом someText2 . Так же она добавит завершающий '\0'
Реализация объединения двух строк, используя стандартную функцию, заняла одну строчку кода в программе – 14-я строка.
![strcat c++, strcat_s c++]()
На что следует обратить внимание и первом и во втором коде – размер первого символьного массива должен быть достаточным для помещения символов второго массива. Если размер окажется недостаточным – может произойти аварийное завершение программы, так как запись строки выйдет за пределы памяти, которую занимает первый массив. Например:
В этом случае, строковая константа “Учите С++ c нами!” не может быть записана в массив someText1 . В нём недостаточно места, для такой операции.
Если вы используете одну из последних версий среды разработки Microsoft Visual Studio, возможно возникновение следующей ошибки: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” Так происходит потому, что уже разработана новая более безопасная версия функции strcat – это strcat_s .
Она заботится о том, чтобы не произошло переполнение буфера (символьного массива, в который производится запись второй строки). Среда предлагает вам использовать новую функцию, вместо устаревшей. Почитать больше об этом можно на сайте msdn. Подобная ошибка может появиться, если вы будете применять функцию strcpy , о которой речь пойдет ниже.
Читайте также: