
Как сделать дипфейк на телефоне
Добавил пользователь Дмитрий К. Обновлено: 05.10.2024
Рассказываем о работе технологии face swap, создании известных сегодня deepfake-видео, как трансфер лиц поможет медиарынку и в каком направлении развивается эта область машинного обучения.
Нейросети оперируют и видеоконтентом: генерируют движущиеся пейзажи, убирают объекты или же заставляют танцевать людей на фото.
Сложнее обстоят дела с трансфером человеческих лиц или тел на изображениях. Эту сферу начинают осваивать стартапы, которые создают продукты для оптимизации процессов производства контента: Dowell (проект компании Everypixel Group, Россия), Synthesia (Великобритания), а также RefaceAI — создатели приложений Doublicat и Reflect (Украина).
Есть несколько сервисов вроде Reflect, Doublicat или Morhine, которые работают в реальном времени со статичным форматами или GIF. Недавно китайские разработчики зашли на поле видеоформата и выпустили приложение Zao, которое встраивает лица пользователей в известные фильмы.
В остальном широкая аудитория остаётся непричастной к созданию такого контента и потребляет deepfake-видео, которые выпускают известные продакшн-студии или свободные художники на YouTube.
Существуют разные архитектуры алгоритмов, которые переносят лица с видео на видео. Мы расскажем о нескольких самых распространённых.
Метод перемещения лица, в основе которого — кодировщик и декодировщик. Работает это так:
- Два видео: донорское (откуда берём лицо) и целевое (куда мы его помещаем, ресивер, реципиент). На них размечаются границы лица. Эти видео с помощью нарезки кадров превращаются в набор фотографий. По ним и будет обучаться модель.
- Кодировщик сжимает изображения (грубо говоря, упрощает до последовательности чисел). Мы получаем latent face (непроявленное лицо), потом оно восстанавливается до оригинального изображения инструментом декодирования. Две нейросети обучаются кодировать и декодировать изображения так, чтобы после восстановления они были максимально похожими на оригинал.
- Кодировщик и для донорского, и для целевого видео один и тот же, благодаря чему изображения latent face у обоих видео схожи. А вот декодировщики разные, и здесь начинается магия: как только нейросети обучились, декодировщики меняют местами, донорское изображение восстанавливается с использованием декодировщика целевого видео. Получается, что лицо донорского видео пришивается к лицу целевого видео, перенимая выражение лица, мимику и эмоции реципиента.
Один из распространённых кодов для переноса лиц таким методом написал российский разработчик-энтузиаст Иван Перов. В его репозитории DeepFaceLab на GitHub есть подробнейшие руководства с комментариями, системные требования к оборудованию и программному обеспечению и даже видеоинструкция.
В подходе с использованием этого метода улучшить результат можно только вручную, корректируя базы данных перед обучением или на постпродакшене.
Поэтому всё чаще в архитектуру с кодировщиком и декодировщиком вплетаются генеративно-состязательные сети. Их суть заключается в соревновании генератора и дискриминатора (отсюда — GAN, Generative Adversarial Network, генеративно-состязательная сеть).
Генераторы учатся создавать наиболее реалистичную картинку, дискриминаторы — определять, какая из них сгенерированная, а какая оригинальная. По мере того как генераторы обучаются обманывать дискриминатор, изображение получается всё более реалистичным.
Таким образом, кодировщик и декодировщик отвечают за перенос изображения, а дискриминатор от генеративных сетей — за улучшение результата. По этой логике работает архитектура Face Swap GAN, созданная японским разработчиком Shaoanlu.
Ещё один подход — архитектуры с использованием нескольких генеративно-состязательных сетей. Каждая сеть отвечает за свою операцию, что сводит к минимуму количество этапов с применением ручного труда.
Чтобы обучить такую нейросеть, требуется несколько суток и мощный кластер видеокарт. Несмотря на это, такой подход является наиболее перспективным, потому что даёт лучший результат.
Одно из решений, созданных по этой технологии, — FSGAN, которое в скором времени обещает опубликовать в открытом доступе его создатель, израильский исследователь Юваль Ниркин.
Здесь одна нейросеть учится подгонять лицо донора под параметры целевого видео (поворот головы, наклон вбок или вперёд), вторая переносит черты лица, а третья делает image blending (слияние изображений), чтобы картинка была более реалистичной, без разрывов или артефактов.
Сегодня перенос лиц, если он выполняется исключительно алгоритмами, всё ещё заметен человеческом глазу: выдают либо визуальные артефакты, например мимика или положение глаз, либо непохожесть нового лица ни на реципиента, ни на донора — в результате получается третья сущность.
Гладкий трансфер лиц всё ещё обеспечивают не нейросети, а навыки в CGI (многие широко известные сегодня создатели deepfake-видео вроде Corridor Crew и Ctrl Shift Face правят работу алгоритмов вручную на постпродакшене или же совершают манипуляции перед самим обучением).
На этапе препродакшена проводится работа с данными перед началом обучения нейросети. Когда два видео разложены на наборы кадров, нужно отсмотреть эти базы и обратить внимание на несколько моментов.
Во-первых, не все люди могут обменяться друг с другом лицами незаметно. Сегодня переносимая алгоритмами область — от бровей до подбородка и от уха до уха (то есть уши, лоб и волосы остаются в целевом видео родными). Поэтому на схожесть результата влияют влияют пол, возраст, цвет кожи и волос, а также комплекция и форма лица.
Некоторые студии, делая поддельные видео с известными артистами, ищут максимально похожих на них людей: ребята из Corridor нашли человека, очень похожего на Тома Круза, а актёр, играющий в ролике с Киану Ривзом, надел чёрный парик, чтобы воссоздать образ актера.
Во-вторых, если в донорском видео лицо всегда анфас, а в целевом голова поворачивается и виден профиль, алгоритм не перенесёт лицо корректно, потому что не знает, как выглядит человек в профиль. Так же обстоят дела с положением глаз, движением губ, мимикой и эмоциями (смех или плач): оба человека должны побывать в максимально совпадающем диапазоне ситуаций.
Перенос, полученный с помощью алгоритма в чистом виде (1 — целевое видео, 2 — результат). Видно, что модель неверно распознала положение глаз Ди Каприо: он смотрит в одну сторону, Бурунов — в другую
Перенос, полученный с использованием прорисовки глаз в базе данных (3 — целевое видео, 4 — результат). Положение глаз в финальном видео стало больше похоже на их положение в оригинале у Ди Каприо
После обучения то, что не углядели в начале, и то, в чём оказался бессилен алгоритм, докрашивается на постпродакшене. В ролике с Сергеем Буруновым Андрею пришлось столкнуться с проблемой разной формы лица двух актеров, которую он решал уже на завершающем этапе.
Самый быстрый способ сделать поддельный ролик — наложить лицо, не выходя за рамки головы человека с целевого видео (в данном случае — Ди Каприо). Лицо Бурунова шире, и, как мне кажется, сходство терялось, поэтому приходилось вручную масками прорисовывать его овал.
Основная программа, которой я пользуюсь на постпродакшене, — Adobe After Effects. Я делаю цветокоррекцию, добавляю размытие для имитации движения камеры и шум для эффекта кинопленки.
Отдельная история — работа с изображениями, в которых перед лицом есть искажающая преграда: скафандр, искривлённое зеркало или очки. Тут единственный выход — ПО вроде After Effects, Cinema 4D.
В них вручную создаётся текстура материала, которая затем ставится перед лицом, чтобы выглядело, как в оригинале. Из-за таких ограничений часто бывает, что очень классные сцены фильмов сложно использовать в deepfake-роликах.
Для YouTube-формата, когда каждый вышедший ролик становится информационным поводом и предполагает вау-реакцию аудитории, такой подход применим. Видео можно долго шлифовать, а потом ещё отдельно описывать процесс, как это часто делают в Corridor Crew.
Очевидно, рынок сервисов для пользователей не предполагает какой-либо постпродакшн: результат нужен сейчас. Того же хочет и профессиональная индустрия (кино и реклама), которая руками переносить лица уже умеет, но сейчас фокусируется на удешевлении и автоматизации процесса.
Монетизируется технология face swap по двум стандартным моделям. Для b2c-аудитории создаются развлекательные приложения вроде Zao или Doublicat. Для b2b-аудитории — продукты, которые используются для оптимизации продакшена, маркетинговых коммуникаций, персонализации брендированного контента или в игровой индустрии.
Среди них Dowell и RefaceAI, создатели которых рассказали, по какой логике работает их продукт и какую нишу на рынке они планируют освоить.
Dowell вырос в офисе компании Everypixel Group, которая занимается производством контента и создаёт продукты на основе искусственного интеллекта. Изучив рынок, создатели стартапа поняли, что развитие продуктов для пользователей и демонстрация deppfake-публикаций на YouTube не их путь, и проработали сценарии использования в киноиндустрии и маркетинге.
Один из кейсов они реализовали с BBDO — рекламный ролик с изображением генерального директора крупного автомобильного бренда, в съёмках которого этот человек не принимал непосредственного участия.
Наверняка вы видели в интернете небольшие коротенькие видео, в которых одно лицо заменено другим. Это и есть так называемые deepfake, основанные на работе искусственного интеллекта, или нейросети.
Что такое дипфейк?

Наибольшей популярностью пользуются короткие отрывки из фильмов, где лицо главного героя заменено на лицо обычного человека. Делают такие дипфейки чаще всего ради прикола, забавы.
При помощи нейросети вы можете заменить лица разных людей, частично совместить их между собой с получением промежуточного варианта. Посмотрите на фотографии ниже – все эти люди на самом деле не существуют и никогда не существовали! Они созданы за счет комбинации искусственным интеллектом между собой сотен и тысяч снимков.
">
Согласитесь, если бы не сказали вам, что это не реальные фотографии людей, вы никогда бы не догадались об этом. Но это статичные картинки, а как же происходит то же самое в видео?
Как заменяется лицо в видео?
Как самому сделать дипфейк?
Теория – это конечно хорошо, но не ради неё же мы собрались :) Далее рассмотрим три лучшие бесплатные программы и приложения для замены лиц в видео. Воспользоваться ими может каждый желающий.
Reface
Ранее это приложение для Андроид и iOS называлось Doublicat. Оно получило очень много положительных отзывов от пользователей из разных стран мира и имеет достаточно высокий рейтинг: 4,6 на Google Play и 4,9 на AppStore.
- Сканируете своё лицо на фронтальную камеру мобильного устройства (потом можно будет просто подгружать картинки из памяти).
- Выбираете любой видеоролик из большого списка доступных.
- Получаете результат.
DeepFaceLab
FaceSwap

FaceSwap – схожая с DeepFaceLab программа, но помимо Windows её можно установить на MacOS и Linux. Софт тоже полностью бесплатен и тоже свободно скачивается с GitHub.
FaceSwap имеет серьезный алгоритм замены лиц, требовательный к железу. Поэтому если компьютер у вас достаточно слабый, имеет устаревший CPU и слабую видеокарту, создание дипфейка займет очень много времени.
Программа имеет активное сообщество в сети, благодаря которому в неё постоянно привносятся какие-то новшества, фишки и улучшения. Так же есть много обучающих материалов по работе в FaceSwap, преимущественно англоязычных.
Несмотря на то, что большинство дипфейков создается с ради шутки, прикола, эту технологию можно использовать и со злым умыслом. Именно таким образом можно заставить человека говорить то, чего он никогда не говорил, или делать то, чего он никогда не делал. Вы можете легко манипулировать практически любым цифровым контентом, создавая виртуальные подделки.
Так, например, в Америке справедливо считается, что дипфейки могут представлять угрозу национальной безопасности, и их создание и распространение запрещены в ряде штатов. Поэтому призываем вас применять указанные в статье программы и приложения только в мирных целях, исключительно ради доброй шутки и лучше всего с использованием своего лица, а не лица другого человека, особенного без его разрешения.
Вы хотели бы побывать на бразильском карнавале? А может, на космической станции? Или станцевать менуэт на балу в Версале во времена Людовика XIV? Современные технологии позволяют создать видеоролик о вашем пребывании в любой точке мира или другой эпохе. Достаточно лишь найти подходящий видеофрагмент и заменить лицо на видео: вставить туда ваше лицо или лицо человека, которому вы хотите сделать сюрприз.
Фактически дипфейк и есть глубокое обучение искусственного интеллекта, внимательно исследующего черты и мимику объекта, чье лицо необходимо вставить в видео. Алгоритмы, при помощи которых проводится замена лица в видео, строятся по принципу GAN – генеративно-состязательных сетей. Генеративная часть программы отвечает за обучение ИИ (искусственного интеллекта) на основе фото и видео человека, состязательная – сравнивает настоящее изображение с подмененным, добиваясь высокой достоверности результата.
Лучшие программы для замены лица в видео на смартфоне и ПК – Топ-3
Работать с программами для изменения лица на видео непросто. Первая сложность, возникающая при попытке вставить лицо в видео, связана с разницей в овалах лиц. Если лицо главного героя видео уже, чем у того, чье изображение нужно вставить, при создании дипфейка, придется помучиться: может быть испорчена прическа, нарушены пропорции. Несколько проще провести подмену, если герой оригинального ролика полнее того, чье изображение вставляется. Много времени порой отнимает коррекция цвета и фона видео.
1. Reface
Одно из самых популярных и удобных приложений для создания дипфейков на мобильных устройствах, работающих под управлением Android и iOS. С помощью Reface даже неопытный пользователь легко сгенерирует мем или дружеский шарж. Программа использует универсальную нейросеть, которую разработчики обучили на миллионах изображений из открытых библиотек. Благодаря тому, что пользователю обучать нейросеть не нужно, создание дипфейкового видео или фотографии занимает несколько минут. Приложение вместе с библиотекой анимированных GIF-файлов можно скачать бесплатно.
Прежде чем поменять изображение, необходимо сделать селфи или найти подходящие фотографии в галерее. Главное условие – крупное изображение лица.
После запуска приложения следует выбрать GIF-файл, на котором предстоит заменить лицо. Библиотека программы достаточно велика, GIF-файлы отсортированы по категориям. Реализован поиск по ключевым словам. В некоторых видео несколько героев. В такие GIF-анимации с помощью Reface легко вставить несколько лиц. Удобно, что при желании понравившиеся GIF-файлы можно добавить в Избранное.
Затем на соседней вкладке нужно выбрать лицо (или лица, если в видео будет несколько героев). Приложение быстро рассчитает параметры лица и выполнит замену. На саму операцию по подмене изображения уйдет меньше минуты.
При работе в бесплатной версии пользователю постоянно придется смотреть рекламу, а на готовое видео накладывается водяной знак. Если хочется поменять лицо в GIF-файле, которого нет в библиотеке, придется купить PRO-версию программы. Зато в этом варианте пользователь будет избавлен от рекламы и водяных знаков на видео.
- Интуитивно понятный интерфейс, в котором легко разобраться неопытному пользователю
- Высокая скорость создания ролика
- Хорошая достоверность видео с подмененным лицом
- Можно создать видео с несколькими героями
- Наличие бесплатной версии с большой библиотекой GIF-анимации
- В бесплатной версии – обилие рекламы и водяные знаки на видео
- Использовать собственный GIF-файл можно только в платной PRO-версии
- Можно создавать только короткие видео
2. DeepFaceLab
Процесс создания дипфейка включает этап обучения ИИ, который может занять много времени. Чем мощнее видеокарта и больше оперативной памяти на ПК, тем быстрее будет сгенерирован дипфейк. Минимальные требования – 2 ГБ оперативной памяти с возможностью подкачки и наличие OpenCL-совместимой видеокарты. Но для стабильной работы приложения требуется 8 ГБ и видеокарта с объемом видеопамяти не менее 6 ГБ. В зависимости от параметров видеокарты пользователь выбирает модель работы (SAEHD для 6 ГБ+, Quick96 – при объеме видеопамяти 2-4 GB).
В библиотеке содержатся тестовые видео, пользователь может заменить их своими. Приложение поддерживает форматы MP4, MKV, AVI. Максимальное разрешение – 1080p.
Для обучения ИИ требуется заснять лицо, которое будет вставлено, с тщательно убранными назад волосами, в разных ракурсах, с открытыми и закрытыми глазами. Один из BAT-файлов проекта предназначен для разбивки видео на отдельные кадры, из которых пользователь должен будет удалить лишние.
В проекте предусмотрены инструменты для нарезки видео, в которое будет вставлено лицо. Нужный фрагмент сохраняется вместе со звуковой дорожкой. Чтобы изменить лицо на видео, требуется последовательно запускать пакетные (BAT) файлы согласно инструкции.
Тренировка нейросети на отснятых кадрах длится минимум сутки, а зачастую и больше. Пользователь сам задает количество итераций. Процесс разрешается прерывать, при повторном запуске он будет возобновляться с того же места. Результаты обучения выводятся в виде графика в отдельном окне.
В программе предусмотрено множество тонких настроек. Так, можно задать точность совпадения лиц, вручную совмещать их части. Многие параметры приходится подбирать интуитивно. Готовое видео нуждается в коррекции цвета.
Приложение DeepFaceLab рассчитано на продвинутых пользователей. По мнению специалистов, первый ролик можно создать уже через 7–10 дней после начала знакомства с программой. Но для того, чтобы получить хороший результат, понадобится не меньше месяца. В дальнейшем на создание ролика будет уходить несколько дней.
- Кроссплатформенность
- Бесплатность
- Возможность создания ролика длительностью несколько минут с высокой достоверностью изображения
- Наличие функций редактирования видео
- Высокие требования к графическому процессору
- Требуется много времени на изучение программы
- Необходима дополнительная обработка готового видео
3. Faceswap
Необходимо заснять лицо, которое предстоит вставлять в видео, в разных ракурсах. Первая тренировка ИИ занимает довольно много времени (около суток). По утверждению разработчиков, впоследствии при использовании тех же моделей для обучения нейросети понадобится меньше времени. После вставки изображения в видео требуется цветокоррекция. Программа предназначена для опытных пользователей, знакомых с основами программирования.
- Кроссплатформенность
- Бесплатность
- Возможность добиться высокой достоверности видео
- Можно создавать ролики длительностью несколько минут
- Сложность освоения программы
- Для обучения ИИ и создания ролика требуется много времени
При создании дипфейков необходима обработка как исходного, так и результирующего видео. Чтобы быстро вырезать фрагмент из фильма, а при необходимости преобразовать его в GIF-анимацию, проще всего использовать Movavi Видеоредактор Плюс. Специально для таких случаев в приложении предусмотрен инструмент автоматического распознавания и вырезания отдельных сцен.
Готовое видео с замененным лицом также удобно обрабатывать в этой программе. В Movavi Видеоредакторе Плюс множество фильтров для коррекции цвета. Есть готовые шаблоны, позволяющие пользователю с любым уровнем навыков быстро улучшить качество изображения. В редакторе можно работать с несколькими видео- и аудиодорожками: вставлять одно видео в другое, удалять или добавлять аудиотреки, субтитры, если нужно – записывать речь или вокал с микрофона.
Интерфейс видеоредактора интуитивно понятен и логичен. Экспериментируя с настройками Movavi Видеоредактора Плюс, можно повысить достоверность дипфейка и получить клип профессионального качества, порадовав результатами своего творчества родных и друзей.
Технология дипфейков использует глубокие нейронные сети для убедительной замены на видео одного лица другим. У этой технологии есть очевидный потенциал для злонамеренного использования, и она становится всё более распространённой. По поводу социальных и политических последствий этого тренда было написано уже много хороших статей.
И это не одна из них. Вместо этого я сам поближе ознакомлюсь с этой технологией: как работает ПО для дипфейков? Насколько сложно их создавать, и насколько хорошими получаются результаты?
И всё же довольно примечательно, что такой новичок, как я, может создать достаточно убедительное видео, причём так быстро и дёшево. Есть все основания полагать, что дипфейк-техологогия в следующие года будет становиться только лучше, быстрее и дешевле.
В данной статье я проведу вас за руку по моему дипфейк-пути. Я объясню каждый шаг, который необходимо предпринять для создания дипфейк-видео. По пути я буду объяснять, как работает эта технология и какие у неё есть ограничения.
Дипфейкам нужно много вычислительных мощностей и данных
То же верно и для дипфейков. Для данного проекта я арендовал виртуальную машину с четырьмя мощными видеокартами. И даже со всеми этими лошадками на обучение моей модели ушла почти неделя.
Мне также требовалась гора изображений Марка Цукерберга и Дейты. У меня получилось видео длиной 38 сек, но для обучения мне требовались куда как более длинные видеозаписи, причём как Цукерберга, так и Дейты.
Я загрузил все эти клипы в iMovie и удалил кадры, не содержавшие лиц Цукерберга и Дейты. Также я порезал на части самые длинные отрывки. Дипфейк-программе нужно не просто огромное количество изображений, но большое количество разных изображений. Нужна была съёмка лиц с разных ракурсов, с разными выражениями и при разном освещении. Часовое видео, на котором Цукерберг читает доклад, может дать не более ценных кадров, чем пятиминутный его отрезок, поскольку оно снято с одного и того же ракурса, в одном освещении и показывает одно и то же выражение лица. Поэтому я обрезал несколько часов видео до 9 минут с Дейтой и до 7 минут с Цукербергом.
Faceswap: пакет программ для создания дипфейков
Затем настало время использовать ПО для дипфейка. Сначала я попробовал использовать программу DeepFaceLab и у меня получилось создать довольно грубое видео. Затем я попросил совета на форуме SFWdeepfakes, и тогда несколько человек посоветовало мне Faceswap. Люди отметили, что у этой программы больше функций, лучше документация и лучше онлайн-поддержка. Я решил последовать их совету.
Faceswap работает на Linux, Windows и Mac. В пакете есть инструменты для работы на всех этапах создания дипфейка, от импортирования изначальных видеороликов до создания законченного дипфейк-видео. ПО не является интуитивно понятным, однако с ним идёт подробный обучающий материал, покрывающее все шаги процесса. Материал написан создателем Faceswap Мэттом Торой, который также очень здорово помог мне в чате на канале Deepfake в Discord.
Для Faceswap требуется мощная графическая карта. Я знал, что мой MacBook Pro не справится с этим. Я попросил техников нашей редакции арендовать мне виртуальную машину под Linux у лидирующего провайдера облачных сервисов. Я начал с виртуалки с Nvidia K80 GPU и 12GB видеопамяти. Через несколько дней я перешёл на модель с двумя GPU, а потом и на 4 GPU. У неё было четыре Nvidia T4 Tensor Core GPU с 16 Gb памяти в каждой (а ещё 48 CPU и 192 RAM, которые по большей части простаивали).
За две недели работы я получил счёт в $522. Несомненно, я потратил довольно большую сумму за удобство с арендой компьютера. Тора рассказал мне, что на текущий момент наиболее выгодным вариантом железа для дипфейка является карта Nvidia GTX 1070 или 1080 с 8 Гб памяти. Стоит такая б/у карта несколько сотен долларов. Одна карточка 1080 не обучит нейросеть так быстро, как четыре моих GPU, однако если вы готовы подождать несколько недель, то вы получите схожие результаты.
Рабочий процесс в Faceswap состоит из трёх базовых шагов:
- Извлечение: порезать видео на кадры, найти лица в каждом кадре, вывести хорошо выровненные и тщательно обрезанные изображения каждого лица.
- Обучение: использовать полученные изображения для обучения дипфейк-нейросети. Она принимает изображение лица одного человека и выдаёт изображение лица другого человека с тем же выражением, освещением и в той же позе.
- Преобразование: применить модель, обученную на предыдущем шаге, к определённому видео, чтобы выдать дипфейк. После обучения модели её можно будет применять к любому видео, на котором присутствуют те люди, на лицах которых она обучалась.
Обучение же легко настроить, и оно практически не требует человеческого участия. Однако для получения хороших результатов могут потребоваться дни или даже недели компьютерного времени. Я начал обучать свою итоговую модель 7 декабря, и она работала до 13 декабря. Возможно, что после ещё одной недели работы качество моего дипфейка улучшилось бы. И это ещё я использовал своего облачного монстра с четырьмя передовыми графическими картами. Если вы работаете на своём компьютере с единственным GPU меньшей мощности, на обучение хорошей модели у вас может уйти много недель.
Итоговый шаг, преобразование, проходит быстро и для человека, и для компьютера. Получив подходящим образом обученную модель, вы можете выдать дипфейк-видео меньше, чем за минуту.
Как работают дипфейки
Перед описанием процесса обучения Faceswap нужно пояснить, как работает технология, лежащая в её основе.
В сердце Faceswap – и других ведущих программных пакетов для создания дипфейков – находится автоэнкодер. Это нейросеть, обученная принимать на вход изображение и выдавать идентичное изображение. Само по себе это умение может быть не таким уж полезным, но, как мы увидим далее, это ключевой строительный кирпичик в процессе создания дипфейка.
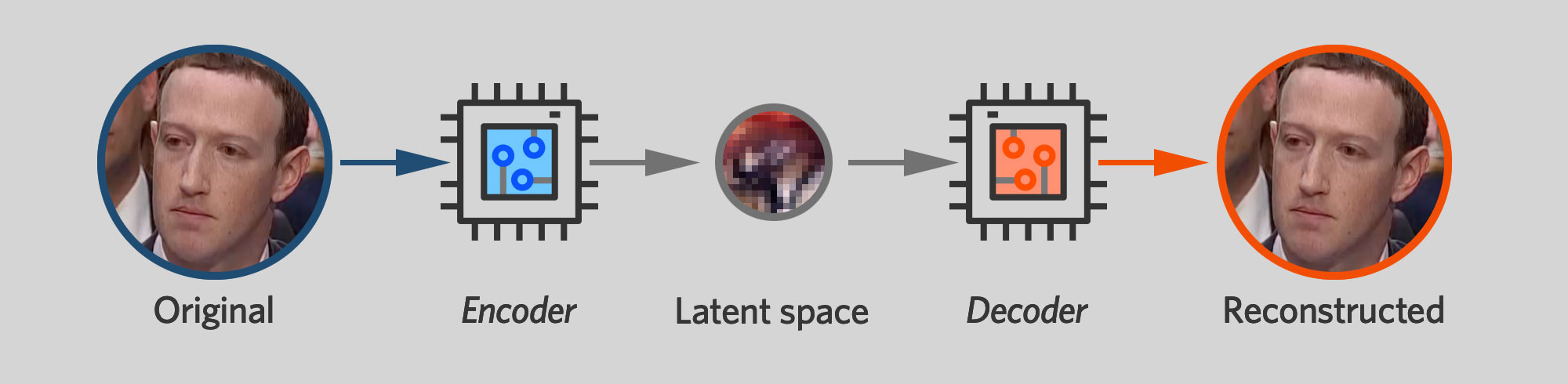
Искусственно ограничение количества данных, передаваемых от энкодера к декодеру, заставляет две этих сети разработать компактное представление человеческого лица. Энкодер – это что-то вроде алгоритма сжатия с потерями, который пытается сохранить как можно больше информации о лице при ограничениях на объём хранилища. Латентное пространство должно каким-то образом извлечь важные детали, например, в какую сторону смотрит субъект, открыты у него глаза или закрыты, улыбается он или хмурится.
Важно, что автоэнкодеру нужно сохранить только те особенности лица, которые меняются во времени. Ему не нужно хранить неизменные вещи тип цвета глаз или формы носа. Если на каждой фотографии Цукерберга у него голубые глаза, тогда декодер его сети обучится автоматически рисовать его лицо с голубыми глазами. Нет нужды запихивать в тесное латентное пространство информацию, не меняющуюся при переходе от одного изображения к другому. Как мы увидим далее, то, что автоэнкодеры по-разному относятся к постоянным и меняющемся чертам лица, крайне важно для их способности выдавать дипфейки.
Каждому алгоритму для обучения нейросети нужен какой-то способ оценить качество работы сети, чтобы его можно было улучшить. Во многих случаях это делается через обучение с учителем, когда человек обеспечивает правильный ответ для каждого элемента из набора обучающих данных. Автоэнкодеры работают по-другому. Поскольку они просто пытаются воспроизвести собственные входные данные, обучающее ПО может судить об их качестве работы автоматически. На жаргоне машинного обучения это называется обучением без учителя.
Как и любая нейросеть, автоэнкодеры в Faceswap обучаются при помощи обратного распространения. Обучающий алгоритм скармливает определённое изображение в нейросеть и смотрит, какие пиксели на выходе не соответствуют входу. Затем он подсчитывает, какие из нейронов последнего слоя внесли наибольший вклад в ошибки и немного подправляет параметры каждого нейрона так, чтобы он выдавал результаты получше.
Затем эти ошибки распространяются обратно, к предыдущему слою, где параметры каждого нейрона подправляются вновь. Ошибки распространяются таким способом всё дальше назад, пока каждый из параметров нейросети – как у энкодера, так и у декодера – не окажутся исправленными.
Затем обучающий алгоритм скармливает ещё одно изображение сети, и весь процесс повторяется снова. Могут понадобиться сотни тысяч таких повторов для того, чтобы получился автоэнкодер, хорошо воспроизводящий собственный вход.
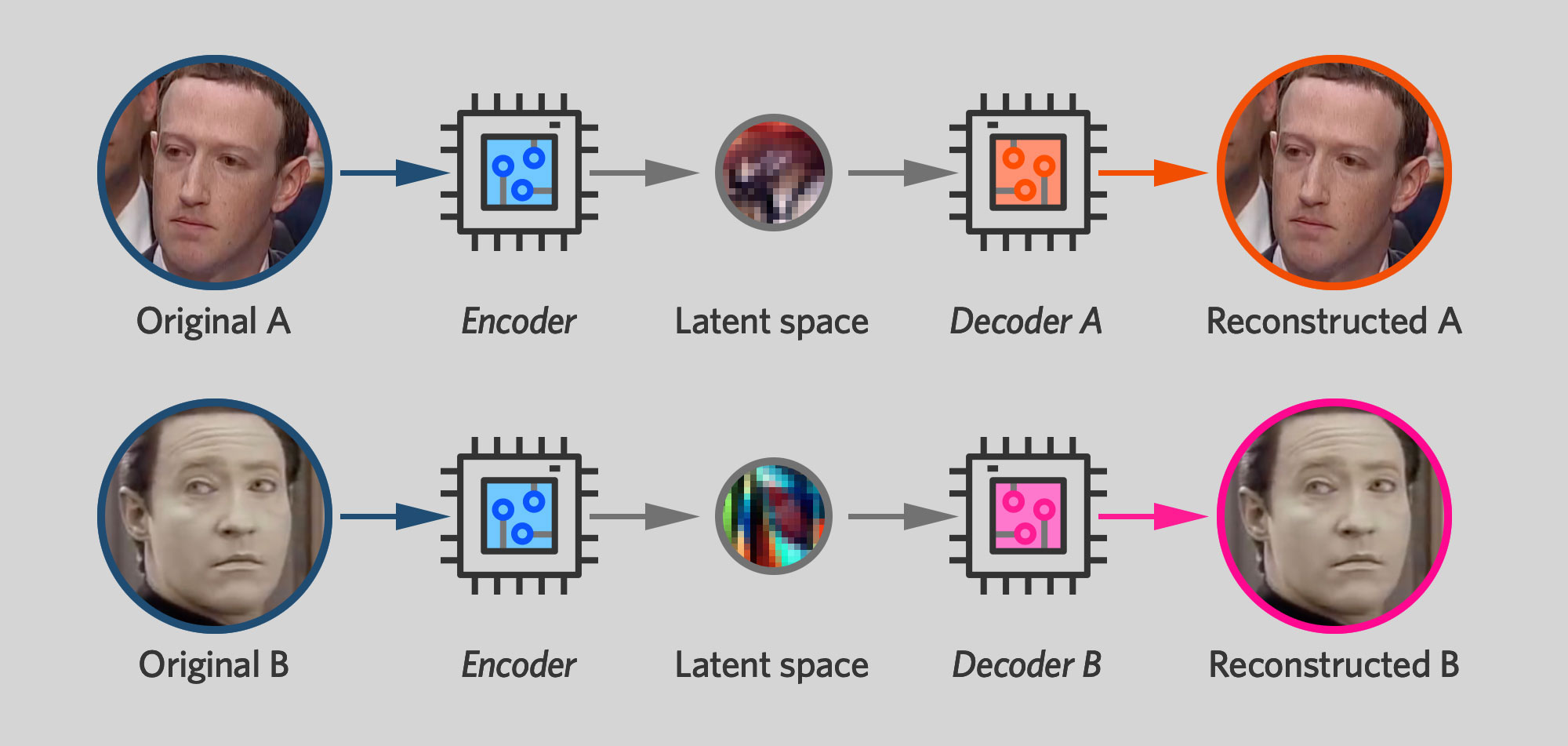
ПО для дипфейка работает, параллельно обучая два автоэнкодера, один для оригинального лица, а второй – для нового. Во время процесса обучения каждому автоэнкодеру выдают изображения только одного человека, и он обучается выдавать изображения, очень похожие на оригинал.
Есть, однако, подвох: обе сети используют один и тот же энкодер. Декодеры – нейроны в правой части сети – остаются раздельными, и каждый из них обучается выдавать разное лицо. Но нейроны в левой части сети имеют общие параметры, меняющиеся каждый раз, когда обучается любой из автоэнкодеров. Когда сеть Цукерберга обучается на лице Цукерберга, это меняет половину сети, принадлежащую энкодеру и в сети для Дейты. Каждый раз, когда сеть Дейты обучается на лице Дейты, энкодер Цукерберга наследует эти изменения.
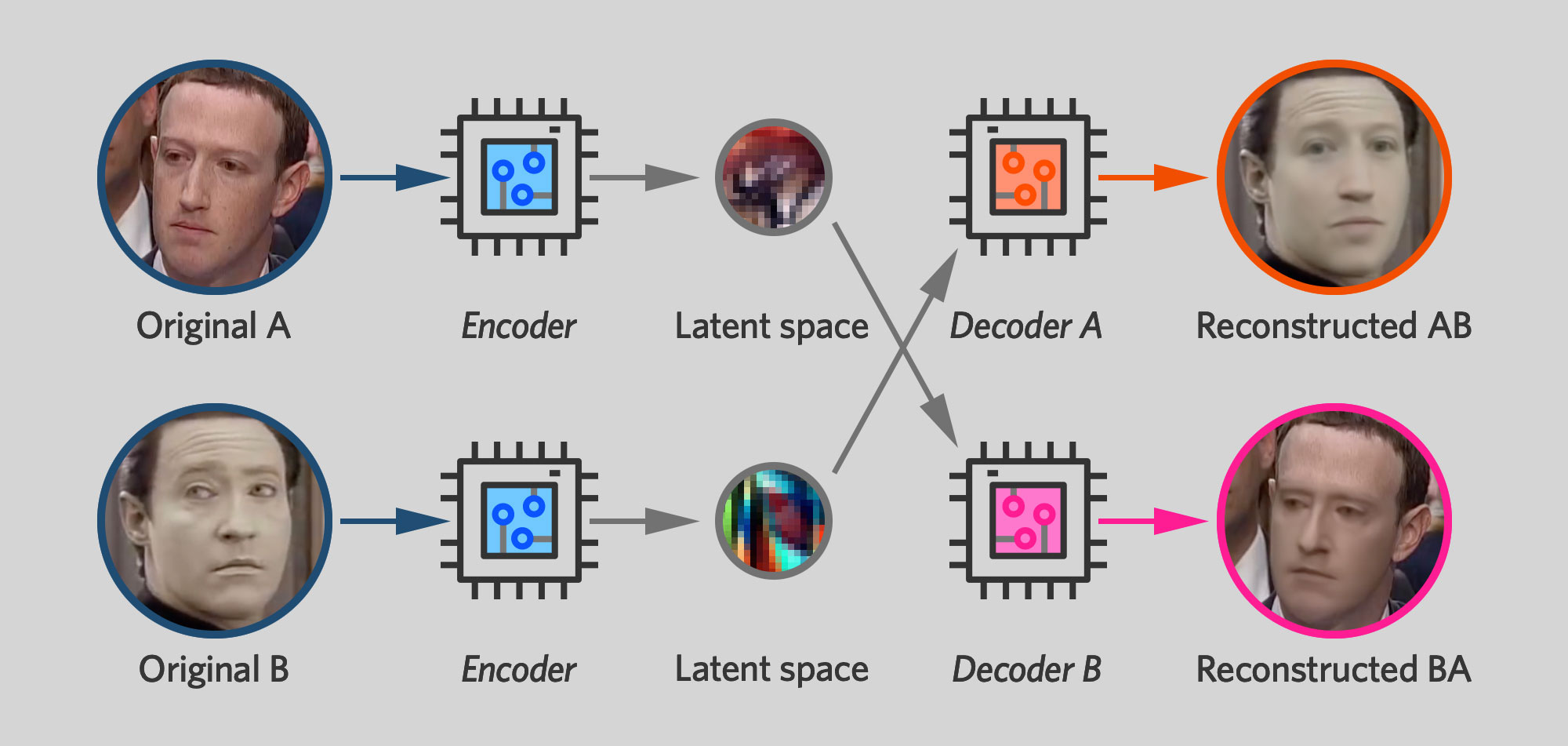
Итак, обучив таким способом пару автоэнкодеров, остаётся простой шаг создания дипфейка: вы меняете декодеры местами. Вы кодируете фото Цукерберга, но используете декодер Дейты на шаге декодирования. В итоге получается реконструированная фотография Дейты – но с тем же положением головы и выражением лица, как и у оригинальной фотографии Цукерберга.
Помните, я упоминал, что латентное пространство схватывает переменные черты лица человека – выражение, направление взгляда, расположение бровей – а такие постоянные вещи, как цвет глаз или форма рта выдаёт декодер. Это значит, что если вы закодируете изображение Цукерберга, а потом декодируете его при помощи декодера Дейты, вы получите лицо с постоянными чертами Дейты – к примеру, форму лица – но с выражением и ориентацией оригинального лица Цукерберга.
Применяя эту технику к последовательным кадрам видео с Цукербергом, вы получите новое видео, где лицо Дейты исполняет те же движения – улыбается, моргает, поворачивает голову – которые делал Цукерберг в оригинальном видео.
Обучающие данные
На практике получить хорошие результаты при создании дипфейка нелегко.
Как я уже упомянул, я набрал семь минут видео для Дейты и девять минут для Цукерберга. Затем я использовал инструмент извлечения изображений из Faceswap для нарезки видео и получения обрезанных изображений лиц обоих мужчин. В видео содержится примерно по 30 кадров в секунду, однако я извлекал лишь каждый шестой – эту практику рекомендуют в документации по Faceswap. Всё оттого, что разнообразие изображений значит больше, чем просто их количество, и сохранение каждого кадра привело бы к получению огромного количества очень похожих изображений.
Инструмент извлечения Faceswap выдал достаточно много ложных срабатываний. Также он обнаруживал реальные лица на заднем фоне некоторых кадров. Пару часов я вручную удалял все извлечённые фотографии, не принадлежавшие ни одному из двух моих подопытных. В итоге я получил 2598 изображений лица Дейты и 2224 изображения лица Цукерберга.
Затем я подождал. И ещё подождал. Процесс обучения всё ещё не закончился, когда в пятницу наступил мой дедлайн – и это после шести дней обучения. На тот момент моя модель выдавала достаточно неплохой дипфейк. Скорость прогресса замедлялась, но возможно, что у меня получился бы результат получше, будь у меня ещё неделя компьютерного времени.
Насколько хорошо получился дипфейк?
Видео выше показывает качество дипфейка на четырёх этапах процесса обучения. Видео за 10 и 12 декабря показывают частично обученную модель Villain. Видео от 6 декабря слева вверху – это ранний тест с другой моделью. Справа внизу – итоговый результат. В процессе обучения детали его лица становились всё чётче и правдоподобнее.
9 декабря, после трёх дней обучения я опубликовал предварительный ролик на внутреннем канале редакции в слаке. Видео было похоже на то, что расположено в левом верхнем углу. Наш гуру дизайна Аурих Лоусон отреагировал на него язвительно.
Думаю, что в его критике есть рациональное зерно. Я удивился тому, как быстро Faceswap смогла создавать изображения лиц, которые очень сильно напоминали Брента Спайнера, больше чем Цукерберга. Однако, если присмотреться, вы увидите характерные признаки цифрвого обмана.
Однако более фундаментальная проблема состоит в том, что алгоритмы дипфейка пока ещё не в состоянии достаточно хорошо воспроизводить мельчайшие подробности человеческих лиц. Это довольно очевидно, если посмотреть параллельно на начальное и конечное видео. Faceswap удивительно неплохо передал общую структуру лица Дейты. Но даже после недели тренировки лицо выглядит размытым, и важных деталей в нём не хватает. К примеру, ПО для дипфейков с трудом справляется с рисованием зубов человека. Иногда зубы становятся явно видны, а в следующем кадре они пропадают, оставляя черноту.
Одна из основных причин этого в том, что задача Faceswap экспоненциально усложняется при повышении разрешения. Автоэнкодеры неплохо справляются с изображениями размером 64х64 пикселя. Но воспроизводить более мелкие детали изображений 128х128 пикселей – не говоря уже об изображениях размером 256 пикселей или более – уже гораздо сложнее. Возможно, это одна из причин того, почему наиболее впечатляющие дипфейки имеют довольно широкий угол зрения, без крупных планов лиц.
Однако не стоит считать это фундаментальным ограничением технологии дипфейка. В ближайшие годы исследователи вполне могут разработать технологии, способные преодолеть эти ограничения.
ГСС, впервые появившиеся в 2014 году, могли выдавать только грубые изображения небольшого разрешения. Но в последнее время исследователи придумали, как создавать ГСС, выдающие фотореалистичные изображения размером до 1024 пикселей. Конкретные техники, используемые в этих научных работах, возможно, и неприменимы для создания дипфейка, но легко представить, как кто-либо разработает сходную технологию для автоэнкодеров – или, возможно, совершенно новую архитектуру нейросети, предназначенную для замены лиц.
Перспектива дипфейков
Рост популярности дипфейков очевидно вызывает тревогу. До недавнего времени люди могли с достаточно легко принимать видеозапись с человеком за чистую монету. Появление ПО для создания дипфейков и других цифровых инструментов привело к тому, что мы теперь относимся к видеозаписям со скептицизмом. Если мы видим ролик, в котором человек утверждает что-то скандальное – или раздевается – мы должны рассмотреть возможность того, что некто подделал это видео с целью дискредитации того человека.
Однако мой эксперимент подчёркивает ограничения технологии дипфейков – по крайней мере, в текущем виде. Требуются обширные знания и усилия для создания полностью убедительного виртуального лица. У меня этого не получилось, и я не уверен, что кто-то уже смог изготовить дипфейк-видео, реально неотличимое от настоящего.
Более того, сегодня инструменты типа Faceswap занимаются лишь заменой лиц. Они не меняют лоб, волосы, руки и ноги. И даже если лицо будет идеальным, возможно будет определить дипфейк-видео на основе элементов, которые выглядят не так, как надо.
Однако эти ограничения технологии дипфейков могут и исчезнуть. Через несколько лет ПО, возможно, научится выдавать такие видео, которые невозможно будет отличить от настоящих. Что тогда?
В данном случае полезно будет помнить, что другие типы носителей уже давно легко подделать. Тривиальной задачей будет сделать снимок экрана с электронным письмом, где кто-то пишет что-то, что он на самом деле не писал. И это не привело к росту количества оборванных карьер из-за подложных емейлов, а также не дискредитировало снимки экрана с письмами как доказательства, используемые в публичных обсуждениях.
Но люди знают, что емейлы можно подделать, и ищут дополнительные подтверждения в подобных случаях. Какая цепочка событий привлекла к письмам внимание общественности? Получали ли другие люди копии такого емейла во время его предполагаемого написания? Признал ли предполагаемый автор письма своё авторство, или заявляет о подлоге? Ответы на такие вопросы помогают людям решать, насколько серьёзно можно относиться к опубликованному письму.
Один раз можно обмануться
Так же и с видеороликами. Возможно, будет какой-то краткий период времени, когда обманщики смогут уничтожить карьеру человека, опубликовав видео, где он говорит или делает что-то возмутительное. Но вскоре общество научится относиться к видеозаписям со скептицизмом, если только у ролика не будет какого-то документального подтверждения, свидетелей или других подтверждающих факторов.
Думаю, что это сработает даже в случаях наиболее возмутительных злоупотреблений технологией дипфейка: вставкой лица человека в порнографический ролик. Это очевидно неуважительно и неприемлемо. Но люди волнуются, что такие видео могут уничтожить репутацию и карьеру. Думаю, что это не так.
Ведь в интернете можно найти полно изображений известных личностей (в основном, женщин), головы которых при помощи фотошопа приставлены к телам порнозвёзд. Страдания женщин понятны. Но общественность не заключает автоматически, что эти женщины позировали нагишом – мы знаем о существовании фотошопа и о возможности создания поддельных фотографий.
То же касается и дипфейк-порнографии. Очевидно, что нехорошо изготавливать поддельное порно с вашим участием. Но выпуск дипфейк-видео с каким-то человеком не будет иметь такого разрушительного эффекта, как реальная видеозапись секса. В отсутствие свидетельств подлинности ролика общественность придёт к выводу, что он поддельный.
Мэтт Тора, автор Faceswap, говорит мне, что это соображение было одной из составляющих для его мотивации к созданию пакета. Он считает, что ПО для подмена лиц неизбежно будут разрабатывать. Он надеется, что создав удобный для пользователя инструмент для подмены лиц с открытым кодом, он поможет снять завесу тайны с этой технологией и рассказать общественности о её возможностях и ограничениях. А это, в свою очередь, поможет нам быстрее прийти к той точке, где общественность будет с соответствующей долей скептицизма относиться к видеороликам, которые могут оказаться поддельными.
Читайте также: