
Как сделать связь многие ко многим в базе данных
Обновлено: 05.07.2024
Разработка проекта Диски
Часть 3. Создание связей таблиц по типу Многие-ко-многим
Основные положения
Отношение Многие-ко-многим означает, что множеству записей в одной таблице соответствует множество записей в связанной таблице. Этот тип связи возможен только с помощью третьей (вспомогательной) таблицы, с которой каждая из двух основных таблиц связана отношением Один-ко-многим. Отношение Многие-ко-многим по сути дела представляет собой два отношения Один-ко-многим с третьей таблицей.
Постановка задачи
1. Добавить в созданную базу данных таблицу Актеры.
2. Связать эти две таблицы отношением Многие-ко-многим (в одном фильме снялось несколько актеров, причем каждый актер может сыграть в нескольких фильмах), для чего создать вспомогательную таблицу Участие.
3. Создать формы на основе связи Многие-ко-многим.
Рекомендуемый план разработки проекта
- КодАктера – ключевое поле код (тип данных – счетчик);
- Актер – текстовое поле необходимой длины (по умолчанию – 50);


- КодАктера – поле для выбора значений из таблицы Актеры. Для определения типа данных этого поля воспользуйтесь мастером подстановок и выберите для столбца подстановок значения поля Актер, задав ему подпись Актер. Ключевое поле на этом этапе создавать не надо;
- КодФильма – поле для выбора значений из таблицы Фильмы. Для определения типа данных этого поля воспользуйтесь мастером подстановок и выберите для столбца подстановок значения поля Название, задав ему подпись Фильм.


Рис.4

Рис.5.1
При этом соответствующие фильмы можно будет увидеть и в таблице Актеры (рис.5.2).

Вспомогательная таблица Участие (рис.5.3), благодаря которой мы установили отношение Многие-ко-многим, будет сама заполняться по мере ввода данных о фильмах и актерах.



На втором шаге предоставляется возможность выбора между подчиненными и связанными формами. В первом случае (рис.6.3) будет создана одна форма для таблицы Актеры, на которой в табличном виде будут показаны фильмы с участием соответствующего актера.


В следующем окне (рис.6.5) представлены для выбора различные стили для создаваемой формы.

На последнем шаге (рис.6.6) предлагаются имена для создаваемых форм, которые можно при необходимости изменить.


Упражнения. Совершенствование проекта
1. Создайте форму для таблицы Актеры (рис. С1) с кнопкой для вызова связанной с ней формой таблицы Фильмы (рис. С2).
Подсказка. Для этого на втором шаге (см. рис.6.3) выберите связанные формы для представления данных.


2. Создайте подчиненные формы для таблиц Фильмы и Актеры.
3. Создайте связанные формы для таблиц Фильмы и Актеры.
4. Создать запрос, в котором актерам сопоставлено количество фильмов с их участием (рис. С3).
MySQL - это реляционная база данных. Это означает, что данные в базе могут быть распределены в нескольких таблицах, и связаны друг с другом с помощью отношений (relation). Отсюда и название - реляционные.
Связи между таблицами происходят с помощью ключей. К примеру, в созданной нами ранее таблице пользователей есть первичный ключ - поле id. Если мы захотим сделать таблицу со статьями и хранить в ней авторов этих статей, то мы можем добавить новый столбец author_id и хранить в нём id пользователей из таблицы users.
Это был лишь один из примеров. Всего же типов подобных связей может быть 3:
- один-к-одному;
- один-ко-многим;
- многие-ко-многим.
Давайте же рассмотрим пример каждой из этих связей.
Один-к-одному
При связи один-к-одному каждой записи таблицы соответствует только одна запись в другой таблице.
Давайте заведем ещё одну таблицу, в которой будет храниться профиль пользователя. В нём можно будет указать информацию о себе и ссылку на профиль в VKontakte.
Добавим для каждого пользователя профиль:
Посмотрим на получившиеся профили:

Теперь каждой записи из таблицы users соответствует только одна запись из таблицы users_profiles и наоборот.
INNER JOIN
Прежде чем идти дальше и рассматривать другие типы связей, стоит изучить ещё один оператор SQL - INNER JOIN. Он используется для объединения строк из двух и более таблиц, основываясь на отношениях между ними. Для запроса используется следующий синтаксис:
Чтобы получить всех пользователей вместе с их профилями нам нужно выполнить следующий запрос:

Каждая строка из левой таблицы, сопоставляется с каждой строкой из правой таблицы, после этого проверяется условие.
Если мы хотим выбрать только некоторые столбцы, то после оператора SELECT нужно перед именем поля явно указать название таблицы, из которой оно берется:

Алиасы
Согласитесь, в прошлом примере пришлось довольно много букв написать. Чтобы этого избежать, в запросах можно использовать алиасы для имён таблиц. Для этого после имени таблицы можно написать AS alias. Давайте для таблицы users зададим алиас - u, а для таблицы profiles - p. Эти алиасы теперь можно использовать в любой части запроса:
Заметьте, запрос сократился. Писать запрос с использованием алиаса быстрее.

Один-ко-многим
При такой связи одной записи в одной таблице соответствует несколько записей в другой. В начале этого урока мы рассмотрели как раз такой пример, когда говорили о добавлении в таблицу с новостями поля author_id. Таким образом, у каждой статьи есть один автор. В то же время у одного автора может быть несколько статей.
Давайте создадим таблицу для статей. Пусть в ней будет идентификатор статьи, её название, текст, и идентификатор автора.
Добавим несколько статей:
Запросим теперь эти записи, чтобы убедиться, что всё ок

Давайте теперь выведем имена статей вместе с авторами. Для этого снова воспользуемся оператором INNER JOIN.

Как видим, у Ивана две статьи, и ещё одна у Ольги.
Если бы мы захотели на странице со статьей выводить рядом с автором краткую информацию о нем, нам нужно было бы сделать ещё один JOIN на табличку profiles.

LEFT JOIN
Помимо INNER JOIN, есть ещё несколько операторов класса JOIN. Один из самых частоиспользуемых - LEFT JOIN. Он позволяет сделать запрос к двум таблицам, между которыми есть связь, и при этом для одной из таблиц вернуть записи, даже если они не соответствуют записям в другой таблице.
Как например, если бы мы хотели вывести не только пользователей, у которых есть статьи, но и тех, кто "халтурит" :)
Давайте для начала сделаем запрос с использованием INNER JOIN, который выведет пользователей и написанные ими статьи:

Теперь заменим INNER JOIN на LEFT JOIN:

Видите, вывелись записи из левой таблицы (users), которым не соответствует при этом ни одна запись из правой таблицы (articles).
Многие-ко-многим
Такая связь возникает, когда множество строк одной таблицы соответствуют множеству строк другой таблицы. Чтобы связать их между собой, нужно создать третью таблицу, создав с каждой из первых двух связь один-ко-многим.
В качестве примера такой связи можно привести рубрики статей. Каждая статья может иметь несколько рубрик. И одновременно с этим, каждая рубрика может содержать в себе несколько статей. Давайте добавим таблицу для рубрик.
И сразу добавим в неё несколько рубрик.
Проверим, что они добавились.

Теперь нам нужно добавить ещё одну таблицу, в которой будут храниться связи между article.id и category.id. Создаём:
Обратите внимание на составной первичный ключ. Здесь нам требуется, чтобы именно пара (id_статьи - id_рубрики) была уникальной. А сами по себе значения в отдельных колонок могут повторяться.
Изучите три типа взаимосвязей таблиц базы данных: один-ко-многим, один-ко-одному и многие-ко-многим, которые основаны на ограничениях внешнего ключа.
Вступление
В реляционной базе данных связь формируется путем сопоставления строк, принадлежащих разным таблицам. Связь таблицы устанавливается, когда дочерняя таблица определяет столбец внешнего ключа, который ссылается на столбец первичного ключа родительской таблицы.
Таким образом, каждая связь таблиц базы данных строится поверх столбцов внешнего ключа, и может быть три типа связей таблиц:
- отношение “один ко многим” является наиболее распространенным, и оно связывает строку из родительской таблицы с несколькими строками в дочерней таблице.
- один к одному требует, чтобы первичный ключ дочерней таблицы был связан с помощью внешнего ключа со столбцом первичного ключа родительской таблицы.
- для многих ко многим требуется таблица ссылок, содержащая два столбца внешнего ключа, которые ссылаются на две разные родительские таблицы.
В этой статье мы опишем все эти три связи таблиц, а также их варианты использования.
Один Ко Многим
Отношение таблицы “один ко многим” выглядит следующим образом:
В системе реляционных баз данных отношение “один ко многим” связывает две таблицы на основе столбца внешнего ключа в дочернем элементе, который ссылается на Первичный ключ строки родительской таблицы.
На приведенной выше диаграмме таблицы столбец post_id в таблице post_comment имеет отношение внешнего ключа к столбцу post таблица идентификатор Первичный ключ:
Если вы хотите знать, какой лучший способ сопоставить отношения таблиц “один ко многим” с JPA и Hibernate, ознакомьтесь с этой статьей .
Один К Одному
Взаимосвязь таблиц “один к одному” выглядит следующим образом:
В системе реляционных баз данных связь таблиц “один к одному” связывает две таблицы на основе столбца первичного ключа в дочернем элементе, который также является внешним ключом, ссылающимся на Первичный ключ строки родительской таблицы.
Таким образом, мы можем сказать, что дочерняя таблица разделяет Первичный ключ с родительской таблицей.
На приведенной выше диаграмме таблицы столбец id в post_details таблица также имеет отношение внешнего ключа к столбцу post таблица идентификатор Первичный ключ:
Если вы хотите знать, какой лучший способ сопоставить отношения таблиц “один к одному” с JPA и Hibernate, ознакомьтесь с этой статьей .
Многие Ко Многим
Взаимосвязь таблиц “многие ко многим” выглядит следующим образом:
В системе реляционных баз данных связь “многие ко многим таблицам” связывает две родительские таблицы через дочернюю таблицу, которая содержит два столбца внешнего ключа, ссылающихся на столбцы первичного ключа двух родительских таблиц.
На приведенной выше диаграмме таблицы столбец post_id в таблице post_tag также связан внешним ключом со столбцом post таблица идентификатор Первичный ключ:
И столбец tag_id в таблице post_tag имеет отношение внешнего ключа к столбцу tag таблица идентификатор Первичный ключ:
Если вы хотите знать, какой лучший способ сопоставить отношения таблиц “многие ко многим” с JPA и Hibernate, ознакомьтесь с этой статьей .
Вывод
Знание трех типов табличных отношений очень важно, особенно с учетом того, что чаще всего разработчик приложения использует несколько уровней абстракций при взаимодействии с базой данных.
Кроме того, при использовании инструмента ORM очень важно проверить связи таблиц, созданные платформой доступа к данным, чтобы убедиться, что они соответствуют стандартному определению и что они не пытаются имитировать связь с использованием неоптимального подхода.
Работа с базами данных — процесс, требующий определённых навыков и понимания некоторых нюансов. Разработанная компанией Microsoft программа Access даёт пользователям возможность быстро создавать и редактировать БД. Один из важнейших моментов, с которым обязательно нужно разобраться, при создании БД — связывание её элементов. В этой статье разберёмся с тем, как создать или удалить связи между таблицами в Access. Давайте же начнём. Поехали!
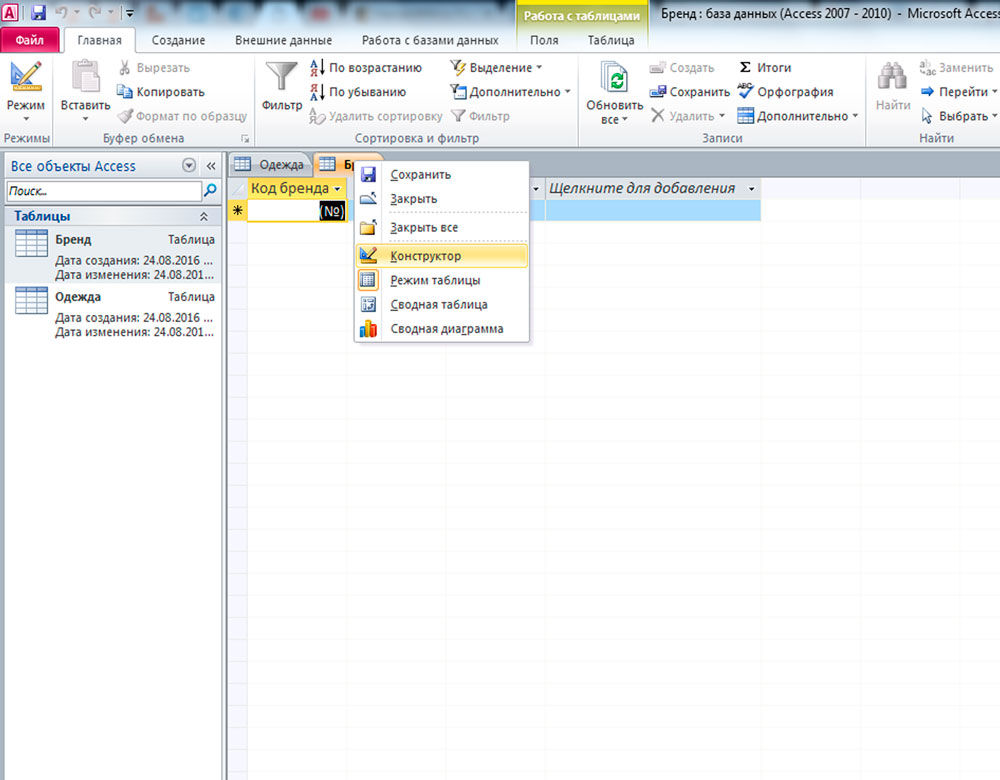
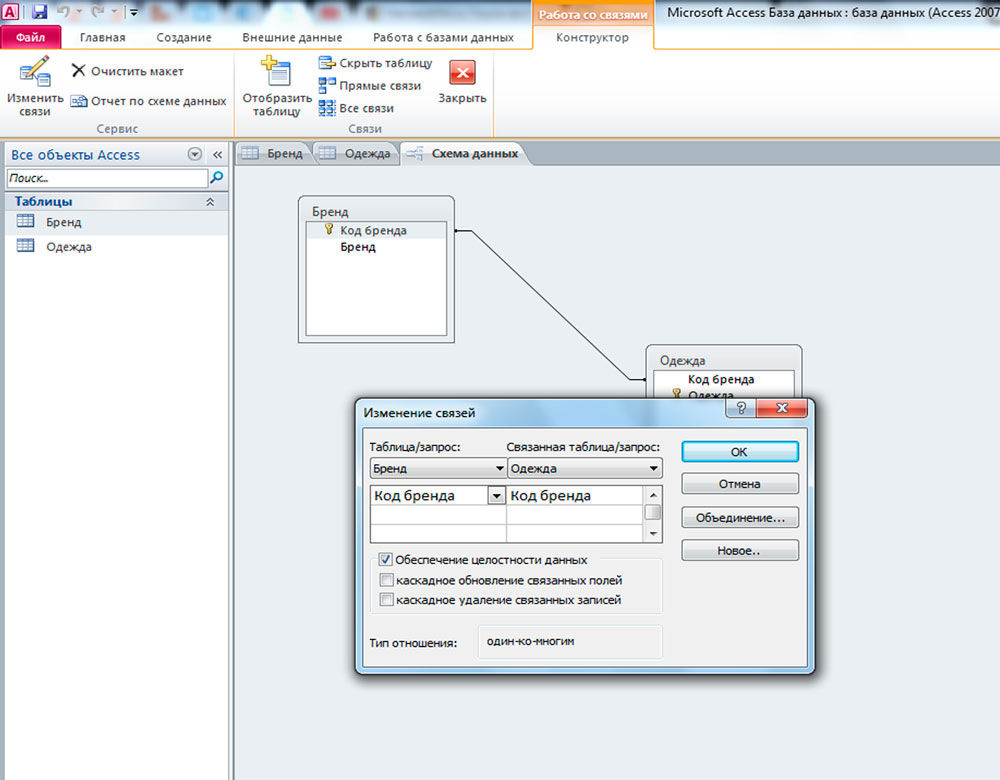
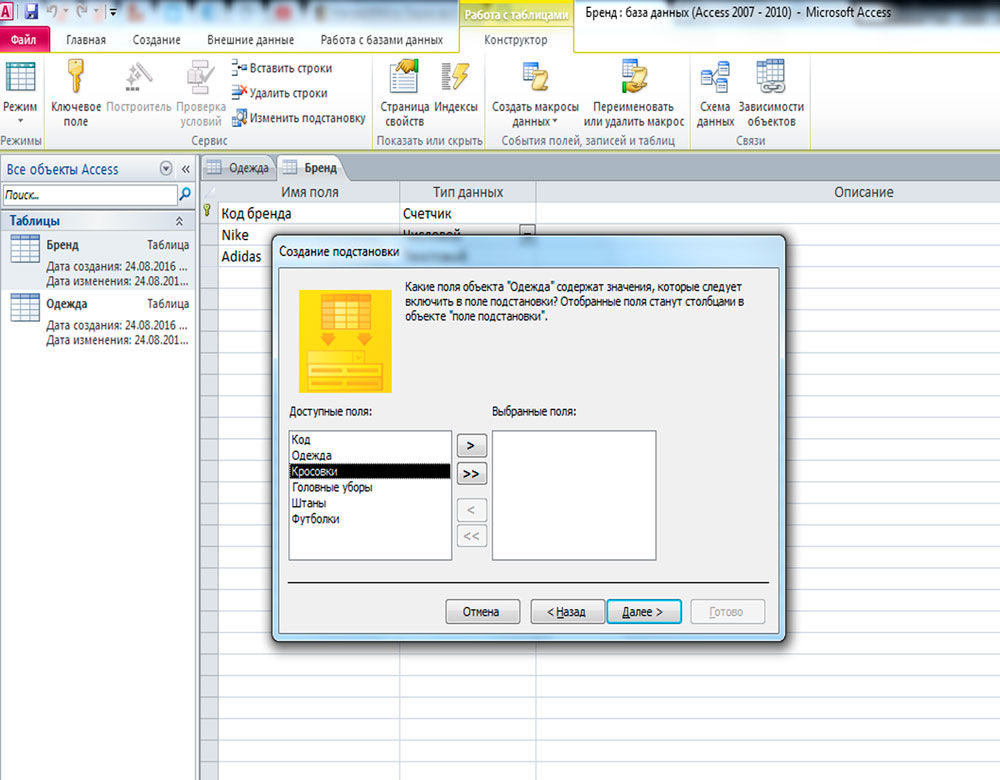
Теперь вы знаете как добавляются и удаляются связи при работе с БД в программе Microsoft Access. Обладая этими навыками, вы уже сможете создавать полноценные, функционирующие БД, однако, продолжайте развивать свои знания программы Access. Пишите в комментариях была ли полезной для вас эта статья и задавайте любые интересующие вопросы по рассмотренной теме.
В предыдущей статье были изложены основы отношений (связей). Вы узнали, зачем нам нужны отношения, и как они влияют на фильтрацию нескольких таблиц. В этой статье вы узнаете об одном из наиболее важных свойств отношений, которое называется кардинальностью или мощностью связей. Целью данной статьи является понимание смысла отношений “один-к-одному”, “один-ко-многим”, “многие-к-одному” и “многие-ко-многим”.
Необходимое условие
Загрузите набор данных Pubs.xlsx для примеров этой статьи здесь .
Отношения в Power BI
Отношения Power BI дают нам возможность получать поля из нескольких таблиц и возможность фильтрации по нескольким таблицам в модели данных. Отношения основаны на поле, которое соединит две таблицы и отфильтрует одну на основе другой (или наоборот, зависит от направления). Например, мы можем отфильтровать данные по количеству таблицы Sales по состоянию в таблице Store, если между таблицами Sales и Store существует связь на основе stor_id:

И отношения между таблицами будут следующими:

Что такое мощность отношений?
Когда вы создаете отношение между двумя таблицами, вы получаете два значения, которые могут быть 1 или * на двух концах отношения между двумя таблицами, называемые кардинальностью или мощностью отношений.

Два значения 1 или * говорят о том, что поле в этой взаимосвязи имеет определенное число значения на строку в этой таблице. Давайте проверим это на примере.
В таблице Stores у нас есть одно уникальное значение для stor_id на строку.

Таким образом, если это поле участвует в одной стороне отношения, то эта сторона примет 1 в качестве показателя кардинальности, который называется ОДНОЙ стороной отношения.
Однако stor_id в таблице Sales не уникален для каждой строки данных в этой таблице. У нас есть несколько строк для каждого stor_id. Или скажем так; в каждом магазине происходит несколько торговых транзакций (что, конечно, нормально):

Итак, основываясь на том, что мы знаем в данный момент, если мы создадим отношение на основе stor_id между двумя таблицами Sales и Stores, то получим вывод:

Эти отношения могут быть прочитаны двумя способами;
Они оба, конечно, одинаковы, и они будут выглядеть точно так же, как каждое из них в представлении схемы. Теперь, когда вы знаете, что такое мощность отношений, давайте изучим все виды мощности.
Типы мощности
Есть четыре типа кардинальности, как показано ниже:
- 1-1: “один-к одному”
- 1- *: “один-ко-многим”
- * -1: “многие-к-одному”
- * - *: “многие-ко-многим”
Давайте поочередно рассмотрим каждый из этих типов.

Один-ко-многим или многие-к-одному

Есть два способа назвать эти отношения: один-ко-многим или многие-к-одному. Зависит от того, что является исходной и целевой таблицей.


Эти две таблицы заканчиваются созданием таких отношений:

В остальной части статьи мы будем использовать термины таблиц FACT и DIMENSION, которые мы объясним отдельно в другой статье. А пока вот краткое объяснение терминов:
- Таблица фактов (FACT): таблица с числовыми значениями, которые нам нужны либо в агрегированном уровне, либо в подробном выводе. Поля из этой таблицы обычно используются в качестве раздела VALUE визуальных элементов в Power BI.
- Таблица измерений (DIMENSION): таблица, содержащая описательную информацию, которая используется для нарезки данных таблицы фактов. Поля из этой таблицы часто используются в качестве слайсеров, фильтров или осей визуалов в Power BI.

Этот тип отношений, хотя часто используется во многих моделях, всегда может быть предметом исследования для лучшего моделирования. В идеальной модели данных вы НЕ должны иметь отношения между двумя таблицами измерений напрямую. Давайте проверим это на примере.
Допустим, модель отличается от того, что вы видели в этом примере: таблица Sales, таблица Product и две таблицы для информации о категории и подкатегории продукта:

Как вы можете видеть на приведенной выше диаграмме отношений, все отношения - “многие-к-одному”. Что хорошо. Однако, если вы хотите нарезать данные таблицы фактов (например, SalesAmount) по полю из таблицы DimProductCategory (например, по имени ProductCategory), для обработки потребуется три отношения:


Отношения “один-к-одному”
Отношение “один-к-одному” происходит только в одном сценарии, когда у вас есть уникальные значения в обеих таблицах на столбец. Примером такого сценария является случай, когда у вас есть таблицы Titles и Titles Details! У них обоих есть один ряд на заголовок. Так что, если мы создадим отношения, это будет выглядеть так:

Если между двумя таблицами существует взаимно-однозначное отношение, они являются хорошим кандидатом для объединения друг с другом с помощью слияния в Power Query. Поскольку обе таблицы в большинстве случаев имеют одинаковое количество строк, или даже если в одной из них меньше строк, все еще учитывающих метод сжатия механизма Power BI xVelocity, потребление памяти будет одинаковым, если вы поместите его в одну таблицу. Так что если у вас отношения “один-к-одному”, подумайте о том, чтобы серьезно объединить эти таблицы.
Было бы лучше, если бы мы объединили обе таблицы выше в одну таблицу, в которой есть все о заголовке.
Отношения “многие ко многим”: слабые отношения

Что делать, если у вас есть более одной таблицы с этим сценарием?


Лучшая модель для вышеупомянутого образца будет использовать общие размеры, как показано на этой диаграмме:

Резюме
Читайте также: