
Как сделать распознавание речи
Добавил пользователь Евгений Кузнецов Обновлено: 04.10.2024
Основные возможности эффективных решений для распознавания речи
На сегодняшний день доступно множество приложений и устройств для распознавания речи, при этом в более передовых решениях применяются технологии искусственного интеллекта и машинного обучения. Для понимания и обработки человеческой речи они объединяют грамматику, синтаксис, структуру и состав звуковых и речевых сигналов. Идеальное решение способно самообучаться с каждым новым взаимодействием.
Лучшие экземпляры таких систем позволяют организациям настраивать и адаптировать технологию с учетом конкретных требований — от языка и нюансов речи до распознавания бренда. Например:
- Весовые коэффициенты для языка: использование весовых коэффициентов для наиболее часто употребляемых слов (например, названий продуктов или профессиональных терминов, отсутствующих в основном словаре) позволяет повысить точность распознавания.
- Маркировка источника речи: создание расшифровки с обозначением реплик каждого участника разговора.
- Адаптация к акустической обстановке: отслеживание акустических сигналов. Систему можно научить адаптироваться к изменениям акустических условий (например, уровня шума в контактном центре) и стиля речи (например, тона голоса, громкости и скорости речи).
- Фильтрация ненормативной лексики: с помощью фильтров можно обнаруживать определенные слова или фразы с целью их исключения из результатов обработки речи.
Тем временем технологии распознавания речи продолжают развиваться. IBM и другие компании ведут успешные разработки сразу по нескольким направлениям с целью повышения эффективности взаимодействия между человеком и компьютером.
Алгоритмы распознавания речи
Случайности и неточности, характерные для человеческой речи, усложняют задачу разработки. Эта область компьютерных наук сочетает в себе лингвистику, математику и статистику и по праву считается одной из самых сложных. Системы распознавания речи состоят из нескольких компонентов, таких как устройство речевого ввода, функции выделения признаков, векторы признаков, модули расшифровки и представления результатов в виде слов. Модуль расшифровки использует акустические модели, словарь произношения и языковые модели для определения результата.
Для оценки качества технологии распознавания речи применяются такие показатели, как степень точности, т. е. процент неправильно распознанных слов (WER), и скорость. На точность распознавания влияет множество факторов, включая произношение, акцент, тон, громкость и фоновые помехи. Главная цель систем распознавания речи — обеспечить такой коэффициент ошибок, который соответствовал бы разговору двух людей. В исследовании Lippmann (внешняя ссылка, PDF, 344 КБ) приводится показатель WER на уровне 4%, однако воспроизвести результаты, описанные в данной публикации, довольно сложно.
Подробнеео достижениях IBM в области распознавания речи можно узнать здесь.
Для преобразования речи в текст и повышения точности результатов применяются разнообразные алгоритмы и вычислительные методы. Ниже приводится краткое описание наиболее популярных методов:
В блоге Watson вы сможете узнать, как IBM использует модели разделения дикторов в своих услугах преобразования речи в текст.
Практическое применение технологии распознавания речи
Технология распознавания речи широко применяется в различных отраслях, экономя время и даже спасая жизни. Ниже приведены некоторые примеры практического использования.
Автомобильная промышленность: средства распознавания речи повышают безопасность вождения с помощью голосовых систем навигации и функций поиска в автомобильных радиостанциях.
Здравоохранение: врачи и медсестры используют приложения с функциями диктовки для сбора и обработки информации о диагнозах пациентов и схемах лечения.
Продажи: технология распознавания речи имеет широкое применение в сфере продаж. С ее помощью контактные центры могут обрабатывать тысячи телефонных звонков клиентов для выявления общих закономерностей и проблем. Кроме того, когнитивные чатботы могут общаться с посетителями веб-сайта, отвечать на общие вопросы и обрабатывать базовые запросы, не дожидаясь освобождения сотрудника контактного центра. В каждой из этих ситуаций системы распознавания речи помогают сократить время устранения проблем, возникающих у потребителей.
Безопасность: по мере внедрения технологий в повседневную жизнь людей протоколы безопасности становятся все более актуальными. Аутентификация по голосу является эффективным способом обеспечения безопасности.
Узнайте, каким образом компании используют программное обеспечение для распознавания речи, чтобы в режиме реального времени индексировать аудиоданные, транслируемые радиостанциями. Ознакомьтесь с примером внедрения в Audioburst здесь.
Распознавание речи и IBM
Компания IBM стояла у истоков разработки инструментов и услуг в области распознавания речи. Наши решения позволяют организациям автоматизировать сложные бизнес-процессы, обеспечивая при этом анализ важной информации.
-
— это облачное решение, использующее алгоритмы глубокого обучения на основе ИИ для создания настраиваемых процессов преобразования речи в текст, опираясь на знания в области грамматики, структуры языка и состава звуковых/голосовых сигналов. преобразует письменный текст в естественную речь с целью повышения качества обслуживания и степени вовлеченности клиентов, тем самым улучшая доступность для пользователей, говорящих на разных языках, за счет разнообразных вариантов взаимодействия.
Более подробная информация о том, как приступить к использованию технологии распознавания речи, приведена на страницах IBM Watson Speech to Text и IBM Watson Text to Speech.

Мы нашли несколько хороших программ, которые умеют автоматически распознавать речь и преобразовывать ее в связный текст. С их помощью вы можете надиктовывать письма или длинные тексты, а не печатать их вручную.

Представляем четыре способа преобразовать речь в текст, используя бесплатные программы и приложения.
Преобразование речи в текст непосредственно в Word
С помощью Microsoft Dictate вы можете диктовать и даже переводить текст прямо в Word.
- Скачайте и установите бесплатную программу Microsoft Dictate.
- Затем откройте Word – в нем появится вкладка Dictation. Кликнув на нее, вы увидите значок микрофона с командой Start.
- Рядом находится выбор языка. Выберите русский язык и начните запись. Старайтесь произносить слова максимально четко, и они появятся прямо в документе.
Превращаем речь в текст с помощью Speak a Message
Бесплатная программа Speak A Message записывает произнесенный текст, а затем расшифровывает его. Основные языки программы — английский, немецкий, испанский и французский, но есть и мультиязычная версия.
Преобразуем речь в текст без специальных программ
В операционной системе Windows 8 и 10 вам не требуется дополнительное программное обеспечение для преобразования голоса в текст.
Преобразование речи в текст через приложение
Если вы хотите диктовать тексты и получать их в напечатанном виде прямо на ходу, используйте специальные приложения.
Web Speech API предоставляет 2 основных типа функциональности — распознавание речи пользователя и речевое воспроизведение текста. Это предоставляет новые возможности для взаимодействия с интерфейсом и открывает перед нами новые горизонты создания уникального пользовательского опыта. Эта статья даёт краткое описание обоих направлений с примерами кода и ссылкой на работающее приложение онлайн.
Распознавание речи
Механизм распознавания речи способен принимать речевой поток через микрофон устройства, а затем проверять его, используя свои внутренние алгоритмы. Для более точной работы рекомендуется использовать интерфейс SpeechGrammar, предоставляющий контейнер для определённого набора грамматики, которое ваше приложение должно использовать. Грамматика определяется с помощью JSpeech Grammar Format(JSGF.).
После того, как пользовательская речь была распознана, алгоритм возвращает результат (список результатов) в качестве текстовой строки, с которой мы можем продолжить работу.
Внимание: В Chrome распознавание речи на веб-странице завязано на взаимодействие с сервером. Ваш звук отправляется на веб-службу для обработки распознавания, поэтому приложение не будет работать в офлайн-режиме.
Для запуска демо достаточно перейти по ссылке на приложение или скачать репозиторий, установить зависимости ( npm install ) и запустить приложение ( npm run start ), после чего открыть localhost:4001 в браузере.

после озвучки команды
Браузерная поддержка
Поддержка интерфейса ещё только распространяется на основные браузеры, и на текущий момент ограничена следующим образом:
Мобильный и десктопный Firefox поддерживает его в Gecko 44+ без префиксов, и его можно включить, установив значение флага media.webspeech.recognition.enable на true в about:config
Chrome для настольных компьютеров и версия для Android поддерживали его с версии 33, но с прописанными префиксами, поэтому вам нужно использовать префиксную версию, например webkitSpeechRecognition
Традиционно, самая актуальная информация по поддержке чего-либо в браузерах на caniuse.
HTML и CSS
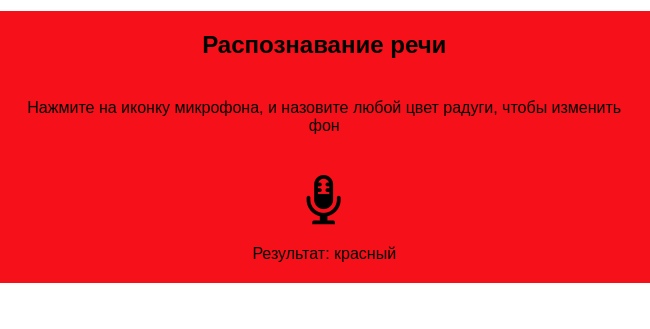
Разметка и стили предельно просты. У нас есть значок микрофона, на который мы можем кликнуть для начала записи, анимация звукозаписи, которая включается после клика, и фоновый контейнер, который будет изменять свой цвет, в зависимости от того, что озвучит пользователь.
CSS задаёт простые отзывчивые стили, для корректного отображения и работы на всех устройствах
JavaScript
А вот на реализацию логики давайте обратим более пристальное внимание.
Поддержка Chrome
Как уже упоминалось ранее, в настоящее время Chrome поддерживает интерфейс распознавания речи с указанными префиксами, поэтому в начале нашего кода мы включаем строки префиксов для использования нужных объектов в Chrome и ссылки на объекты без префиксов для Firefox.
Грамматика
Следующая часть нашего кода определяет грамматику, которую мы хотим, применять для поиска соответствий.
Определяем следующие переменные:
Быстро пробежимся по основным принципам:
Линии разделены точкой с запятой, как и в JavaScript.
Вторая строка указывает значение, которое мы хотим распознать. public объявляет, что это общедоступное правило, строка в угловых скобках определяет распознанное имя для этого значения (цвет), а список элементов, следующих за знаком равенства, - это альтернативные варианты, которые будут распознаны и могут быть приняты в качестве возможного значения. Обратите внимание, как каждый из них разделяется вертикальной линией (“|” - “pipe character”).
У вас может быть множество значений, определённых отдельно, как указано выше, и содержащих довольно сложные определения грамматики. Для нашего демонстрационного примера мы делаем все просто.
Подключение грамматики к нашему распознаванию речи
Следующее, что нужно сделать, это определить экземпляр объекта распознавания речи для управления записью нашего приложения.
Это делается с помощью конструктора SpeechRecognition() . Мы также создаём новый речевой грамматический список, чтобы содержать нашу грамматику, используя конструктор SpeechGrammarList() .
Добавляем нашу “грамматику” в список, используя метод SpeechGrammarList.addFromString() . Он принимает в качестве параметров строку, плюс необязательное значение веса, которое указывает важность этой грамматики по отношению к другим грамматикам, доступным в списке (может быть от 0 до 1 включительно). Добавленная грамматика доступна в списке как экземпляр объекта SpeechGrammar .
Затем мы добавляем SpeechGrammarList к уже созданному объекту распознавания речи, присваивая его значение свойству SpeechRecognition.grammars . Также зададим ещё несколько свойств объекту, прежде чем двигаться дальше:
SpeechRecognition.lang : устанавливает язык распознавания. Его установка - это хорошая практика, поэтому рекомендуется не пропускать.
SpeechRecognition.interimResults : определяет, должна ли система распознавания речи возвращать промежуточные результаты или только конечные результаты. Только конечные результаты подойдут для этой нашего простого приложения.
SpeechRecognition.maxAlternatives : устанавливает количество альтернативных потенциальных совпадений, которые должны быть возвращены на каждый результат. Иногда это может быть полезно, скажем, если результат распознан не точно, и вы хотите отобразить пользователю список вариантов. Но это для простого примера это не нужно, поэтому мы просто указываем один (который по сути является вариантом по умолчанию).
Внимание: SpeechRecognition.continuous задаёт, отслеживаются ли продолжающиеся результаты или только 1 результат, каждый раз, когда запись начата. Это закомментировано, поскольку данное свойство в ещё не реализовано в Gecko.
Вы можете получить аналогичный результат, просто прекратив распознавание после получения первого результата.
Запуск распознавания речи
После получения ссылок на DOM-элементы, необходимые нам для обработки пользовательских событий и обновления цвета фона приложения, мы реализуем обработчик onclick , чтобы при нажатии на значок микрофона сервис распознавания речи начинал работу. Запуск происходит путём вызова функции SpeechRecognition.start() .
Получение и обработка результата
После того, как процесс распознавания речи был запущен, есть много обработчиков событий, которые могут быть использованы для работы с результатом и другой сопутствующей информацией (см. Список обработчиков событий SpeechRecognition.) Наиболее распространённый, который вы, вероятно, и будете использовать, это SpeechRecognition.onresult, который запускается сразу после получения успешного результата. Значение цвета получаем вызовом функции getColor()
Третья строка здесь выглядит немного усложнённой, поэтому давайте разберёмся с ней подробнее. Свойство SpeechRecognitionEvent.results возвращает объект SpeechRecognitionResultList , содержащий в себе другие объекты типа SpeechRecognitionResult . У него есть геттер, поэтому он может быть доступен как массив, поэтому переменная last определяет ссылку на SpeechRecognitionResult из списка. Каждый объект SpeechRecognitionResult содержит объекты SpeechRecognitionAlternative , которые содержат отдельные распознанные слова. Они также имеют геттеры, поэтому к ним можно получить доступ как к массивам, поэтому логично, что [0] возвращает значение SpeechRecognitionAlternative по индексу 0. Затем мы возвращаем строку, содержащую индивидуально распознанный результат, используя который и можем установить цвет фона.
Мы также используем свойство SpeechRecognition.speechend , чтобы задать обработчик на завершение работы распознавателя речи (вызов SpeechRecognition.stop() ), как только одно слово было распознано, и входящий речевой поток был остановлен.
Обработка ошибок
Последние два обработчика используются для отлова ошибок: когда речь была признана не в соответствии с определённой грамматикой или произошла ошибка. По логике, SpeechRecognition.onnomatch , должен обрабатывать первый случай, но обратите внимание, что на данный момент он не срабатывает правильно в Firefox или Chrome, он просто возвращает все, что было распознано в любом случае:
SpeechRecognition.onerror обрабатывает случаи, когда имела место быть фактическая ошибка при распознавании. Свойство SpeechRecognitionError.error содержит возвращаемую фактическую ошибку:
Синтез речи
Синтез речи (text-to-speech или tts) подразумевает получение синтезированного текста приложения и его речевое воспроизведение.
Для этой цели Web Speech API предоставляет интерфейс - SpeechSynthesis - плюс ряд близких интерфейсов для нужного нам воспроизведения текста (utterances - “дикция”), набор голосов, которыми приложение будет “говорить”, и т. д.
Опять же, большинство ОС имеют некоторые встроенные системы синтеза речи, которые будут задействованы нашим API для этой цели.
То же самое приложение из предыдущего примера.
Ссылка на приложение или репозиторий (клонируем, затем npm install && npm run start в терминале, после чего открыть localhost:4001 в браузере).
Пользовательский интерфейс включает в себя набор элементов для ввода текста, задания высоты тона, скорости воспроизведения и непосредственного выбора голоса, которым будет текст произнесён.
После ввода текста вы можете нажать Play для запуска.

Браузерная поддержка
Поддержка интерфейса ещё только распространяется на основные браузеры, и на текущий момент ограничена следующим образом:
Мобильный и десктопный Firefox поддерживает его в Gecko 44+ без префиксов, и его можно включить, установив значение флага media.webspeech.synth.enabled на true в about:config
Chrome для настольных компьютеров и версия для Android поддерживали его с версии 33 без префиксов
Традиционно, самая актуальная информация по поддержке чего-либо в браузерах на caniuse.
HTML и CSS
HTML и CSS снова достаточно тривиальны.
Заголовок и форму с некоторыми простыми элементами управления.
Элемент изначально пуст, но заполняется с помощью через JavaScript (см. ниже).
CSS задаёт простые отзывчивые стили, для корректного отображения и работы на всех устройствах
JavaScript
Давайте более детально рассмотрим скрипт, задающий логику нашему приложения.
Задание переменных
Прежде всего, создаём ссылки на все нужные нам DOM-элементы.
Заполнение выпадающего списка
Чтобы заполнить элемент различными вариантами голоса, доступных на устройстве, напишем функцию populateVoiceList() . Сначала мы вызываем SpeechSynthesis.getVoices() , который возвращает список всех доступных вариантов голосов, представленных объектами SpeechSynthesisVoice . Затем мы проходимся по списку, создавая элемент для каждого отдельного случая, задаём его текстовое содержимое, соответствующее названию голоса (взято из SpeechSynthesisVoice.name ), языка голоса (из SpeechSynthesisVoice.lang ), и “по умолчанию”, если голос является голосом по умолчанию для механизма синтеза (проверяется, если функция SpeechSynthesisVoice.default возвращает значение true .)
Мы также задаём data- атрибуты для каждого варианта, содержащие имя и язык связанного голоса, благодаря чему мы можем легко их собрать их позже, а затем вложить все варианты в качестве дочерних элементов нашего списка ( ).
Когда мы собираемся запустить функцию, мы делаем следующее. Это связано с тем, что Firefox не поддерживает свойство SpeechSynthesis.onvoiceschanged и будет только возвращать список голосов при запуске SpeechSynthesis.getVoices() . Однако, в Chrome вам нужно дождаться триггера события перед заполнением списка, следовательно, нужно условие, описанное в блоке с if ниже.
Озвучка введённого текста
Затем мы создаём обработчик событий, чтобы начать “произносить” текст, введённый в текстовом поле, при нажатии на кнопку Enter/Return или на Play . Для этого используем обработчик onsubmit в html-формы. В функции-обработчике speak() мы создаём новый экземпляр SpeechSynthesisUtterance() , передавая значение текстового поля в конструктор.
Затем нам нужно выяснить, какой голос использовать. Мы используем свойство HTMLSelectElement selectedOptions для получения выбранного элемента , у которого берём атрибут data-name, и находим объект SpeechSynthesisVoice , имя которого соответствует значению имеющегося атрибута. После этого устанавливаем соответствующий “голосовой” объект как значение свойства SpeechSynthesisUtterance.voice .
Наконец, мы устанавливаем SpeechSynthesisUtterance.pitch (высота тона) и SpeechSynthesisUtterance.rate (скорость) в соответствии со значениями соответствующих элементов формы. Затем, после всего проделанного, мы запускаем произношение речи, вызывая SpeechSynthesis.speak() , и передавая ему экземпляр SpeechSynthesisUtterance в качестве аргумента.
Внутри функции speak() мы выполняем проверку на то, воспроизводится ли речь в данный момент, с помощью свойства SpeechSynthesis.speaking
Если да, то останавливаем процесс функцией SpeechSynthesis.cancel() и запускаем рекурсивно заново.
Наконец, мы назовём blur() у текстового поля. Это, прежде всего, для того, чтобы скрыть клавиатуру в ОС Firefox.
Обновление отображаемых значений высоты тона и скорости
Последний пример кода просто обновляет значения высоты тона/скорости, отображаемые в пользовательском интерфейсе, каждый раз, когда позиции ползунка перемещаются.
Владельцам сайтов, которые постоянно выкладывают видео и аудиоконтент, стоит помнить о тех, кто по тем или иным причинам просмотреть или прослушать информацию не может. Зато может ее прочитать.
Расшифровка аудио и видеофайлов — занятие нудное и не самое приятное. Но мы живем в век технологий, а, значит, к нашим услугам множество возможностей, чтобы транскрибировать аудио и видеофайлы.
В этой статье мы расскажем, как легко и быстро перевести аудио и видео в текст.
Способы перевода аудиозаписей и видео в текст
1. Онлайн-конвертеры
Вот несколько сервисов, которые могут быть вам полезны, когда необходимо записать текст с видео или расшифровать аудиофайл.
Использование сервиса Google Документы — самый простой и доступный любому способ перевести видео в текст или расшифровать аудио.

Онлайн-сервис Speechpad позволяет через браузер Google Chrome переводить речь в текст. Имеет поддержку русского языка. Может преобразовать в текст речь, сказанную на микрофон компьютера, получить текст с видео или перевести аудиофайл в печатный текст.


Онлайн-сервис RealSpeaker станет хорошим решением для пользователей, которые хотят расшифровать звуковые дорожки и видеофайлы. Конвертер имеет поддержку русского языка. Из недостатков — текстовая расшифровка файлов, длина которых превышает полторы минуты, будет платной.


Также сервис предоставляет возможность расшифровки аудио и видеофайлов, записанных в форматах .aac, .m4a, .avi, .mp3, .mp4, .mpeg, .ogg, .raw, .flac, .wav. Но эта функция платная.
Отличный сервис, который может перевести аудио или преобразовать видео в текст. Имеет поддержку русского языка. Для использования необходима регистрация.
Система за пару минут делает расшифровку и отправляет ссылку на готовый вариант на электронную почту. Сервис умеет распознавать даже песни.

У сервиса предусмотрено несколько тарифных планов. Бесплатная версия включает только 30 минут расшифровки аудио в формате MP3. Если вы исчерпали лимит, за транскрибацию придется заплатить, выбрав один из тарифов.
2. Профессиональные сервисы расшифровки
Наиболее качественный вариант перевода аудио в текст обеспечивают профессиональные сервисы расшифровки. Единственный их недостаток — они платные. Но и достоинств у них больше по сравнению с бесплатными способами — качественная расшифровка, предсказуемый результат.
Для расшифровки аудио и видео на русском языке пока существует только один профессиональный сервис — Zapisano. Помимо русского он также поддерживает английский, французский, испанский, итальянский, немецкий и другие языки. Расшифровку текстов осуществляют специалисты.
Для начала работы необходимо загрузить файл или вставить на него ссылку.

Ставки за расшифровку начинаются от 19 рублей за минуту и зависят от срочности исполнения и сложности материала. Тестовая расшифровка бесплатна.
Специалисты не только расшифруют текст, но и расставят знаки препинания, проверят орфографию и сделают легкую редактуру, убрав слова-паразиты и оговорки.
3. Программное обеспечение для десктопных устройств
Существует множество платных и бесплатных версий ПО, которые позволяют конвертировать видео в текст. И аудио тоже. Принцип работы и функционал такого программного обеспечения схож с онлайн-сервисами. Но если онлайн-конвертеры требуют подключения к интернету, ПО можно использовать всегда, когда необходимо перевести звук из видео в текст или преобразовать в текст аудио.
Эта отечественная программа для перевода видео в текст работает на ОС Windows. Она станет помощником для тех пользователей, которые не хотят расшифровывать аудиофайлы самостоятельно. Текст можно наговорить в микрофон, взять готовую аудиозапись или звуковую дорожку из видео. Программа работает со всеми популярными аудиоформатами. Программа осуществит и перевод видео в текст. Качество расшифровки — довольно высокое. Единственный и главный минус — программа платная.

Программа Express Scribe для Windows позволяет расшифровывать аудио и видео вручную. Для этого в программе предусмотрены кнопки воспроизведения, паузы и скорости проигрывания записей. Если самостоятельно набирать текст не хочется, можно включить запись, установить нужную скорость, выставить громкость и дополнительно запустить любой сервис голосового ввода, например, Google Документы.

Недостаток программы — нет версии на русском языке. При этом она интуитивно понятна и проста в использовании.
4. Приложения для смартфонов
Функция голосового ввода и распознавания речи реализована во многих приложениях для смартфонов и планшетов. Работает также, как ПО для десктопов и онлайн-сервисы. Для расшифровки аудио или распознавания текста с видео требуется открыть приложение, включить голосовой ввод и нажать воспроизведение звуковой дорожки рядом с микрофоном мобильного устройства.
Приложение для Android с функцией преобразования речи в текст. Умеет набирать текст под диктовку. Из недостатков — не работает без подключения к интернету.

Android-приложение, которое поддерживает русский язык и умеет распознавать речь. Просто включите рядом с микрофоном ролик, в котором хотите преобразовать видео в текст.

5. Расшифровка видео в текст с помощью YouTube
Когда вы ищете конвертер видео в текст, YouTube может оказаться последним сервисом, который придет к вам в голову. Однако многие успешно используют возможности видеохостинга для расшифровки видеозаписей. Все, что нужно, чтобы получить готовый текст из видео, загрузить ролик на сервис. YouTube автоматически сгенерирует субтитры для видео, которые можно будет скопировать и вставить в документ. Расшифрованный текст для видео готов!

6. Расширения для браузеров
Найти бесплатное расширение для браузера, которое качественно может сделать из видео текст или расшифровать звуковую дорожку, задача не из легких. Те, кто готовы к экспериментам и небольшим денежным затратам, могут попробовать следующие плагины из нашего списка.
Полезное расширение для браузера Chrome с функцией распознавания голоса. Может использоваться для диктовки текстов для разных сайтов, даже для заполнения форм или оставления комментариев. Если рядом с микрофоном включить аудио или видео, приложение будет набирать текст в документе. Поддерживает более 120 языков. Пробная версия бесплатна. Тем, кто захочет полноценно пользоваться расширением, придется его купить.

Chrome-приложение с функцией распознавания голоса. Имеет поддержку более 60 языков, в том числе русского. Работает по тому же принципу, что и другие сервисы распознавания речи: вы диктуете или включаете запись, приложение набирает текст. Видео также можно расшифровать, если поднести устройство с записанным роликом близко к микрофону.

Программа может использоваться для заполнения форм на сайтах, диктовки электронных писем. Умеет распознавать голосовые команды и даже позволяет с их помощью просматривать веб-страницы. Например, можно попросить перейти к другому полю, прокрутить страницу вверх или вниз, открыть вкладки или запустить воспроизведение песни с помощью голосовых команд. Также можно попробовать использовать данную программу для расшифровки видео в текст или транскрибации аудио.

7. Преобразование речи в текст в Windows
Владельцы подписки Office 365 могут использовать функции диктовки для преобразования аудио в текст. Для начала требуется войти в учетную запись и активировать микрофон. Затем необходимо включить функцию диктовки. Произнесенный в микрофон текст отобразится на экране.


Самостоятельная расшифровка
Ничто не заменит старой доброй ручной расшифровки видео и аудио, если нужны 100% точность и качество. Чтобы работа проходила эффективнее, существуют приложения и программы, облегчающие транскрибацию. Например, oTranscribe или уже упомянутый Express Scribe помогают видеть перед глазами аудио или видео, сразу вводить прослушанный текст, также имеют горячие клавиши для остановки и включения записи.
Если самостоятельно заморачиваться с расшифровкой лень, всегда можно обратиться к фрилансерам. На любой бирже фриланса можно найти исполнителей, которые помогут записать текст с видео или аудио за небольшую плату. Расшифровка одной минуты аудио или видео в среднем обойдется в 10 рублей.
Заключение
Перед каждым из нас однажды может остро встать вопрос, как перевести видео в текст или расшифровать аудио с минимальными усилиями с нашей стороны. Выбор способа транскрибации будет зависеть от материальных возможностей, срочности выполнения задачи и качества звука. Будьте готовы, что наилучший результат дают платные программы для преобразования видео в текст. А в некоторых случаях, когда качество записи очень плохое и слышны посторонние шумы, придется взяться за расшифровку самостоятельно или прибегнуть к услугам фрилансеров.
Читайте также: