
Как сделать кластерный анализ в orange
Обновлено: 02.07.2024
Orange - это пакет программного обеспечения для визуального программирования на основе компонентов для визуализации данных , машинного обучения , интеллектуального анализа данных и анализа данных .
Компоненты Orange называются виджетами, и они варьируются от простой визуализации данных, выбора подмножества и предварительной обработки до эмпирической оценки алгоритмов обучения и прогнозного моделирования .
Визуальное программирование реализуется через интерфейс, в котором рабочие процессы создаются путем связывания предопределенных или созданных пользователем виджетов , в то время как опытные пользователи могут использовать Orange в качестве библиотеки Python для манипулирования данными и изменения виджетов. [6]
Orange - это программный пакет с открытым исходным кодом, выпущенный под лицензией GPL . Версии до 3.0, включающие основные компоненты на C ++ с оболочками на Python, доступны на GitHub . Начиная с версии 3.0, Orange использует стандартные библиотеки Python с открытым исходным кодом для научных вычислений, такие как numpy , scipy и scikit-learn , в то время как его графический пользовательский интерфейс работает в кроссплатформенной структуре Qt .
Установка по умолчанию включает ряд алгоритмов машинного обучения, предварительной обработки и визуализации данных в 6 наборах виджетов (данные, визуализация, классификация, регрессия, оценка и неконтролируемый контроль). Дополнительные функции доступны в виде надстроек (биоинформатика, слияние данных и анализ текста).
Orange поддерживается в macOS , Windows и Linux, а также может быть установлен из репозитория Python Package Index ( pip install Orange3 ).
По состоянию на май 2018 года стабильная версия - 3.13 и работает с Python 3, тогда как устаревшая версия 2.7, работающая с Python 2.7, все еще доступна. [7]
Orange состоит из холста- интерфейса, на котором пользователь размещает виджеты и создает рабочий процесс анализа данных. Виджеты предлагают базовые функции, такие как чтение данных, отображение таблицы данных, выбор функций, обучение предикторов, сравнение алгоритмов обучения, визуализация элементов данных и т. Д. Пользователь может интерактивно исследовать визуализации или загружать выбранное подмножество в другие виджеты.
- Canvas : графический интерфейс для анализа данных
- Виджеты :
- Данные : виджеты для ввода данных, фильтрации данных, выборки, вменения, манипулирования признаками и выбора признаков.
- Визуализация : виджеты для общей визуализации (прямоугольная диаграмма, гистограммы, точечная диаграмма) и многомерной визуализации (мозаичное отображение, решетчатая диаграмма).
- Classify : набор контролируемых алгоритмов машинного обучения для классификации
- Регрессия : набор контролируемых алгоритмов машинного обучения для регрессии
- Оценить : перекрестная проверка, процедуры на основе выборки, оценка надежности и скоринг методов прогнозирования
- Без учителя : алгоритмы обучения без учителя для кластеризации (k-средние, иерархическая кластеризация) и методов проекции данных (многомерное масштабирование, анализ главных компонентов, анализ соответствий).
- Дополнения :
- Associate : виджеты для поиска частых наборов элементов и изучения правил ассоциации
- Биоинформатика : виджеты для анализа набора генов, обогащения и доступа к библиотекам путей
- Объединение данных : виджеты для объединения различных наборов данных , коллективной матричной факторизации и исследования скрытых факторов
- Образовательные : виджеты для обучения концепциям машинного обучения, таким как кластеризация k-средних , полиномиальная регрессия , стохастический градиентный спуск , .
- Гео : виджеты для работы с геопространственными данными
- Аналитика изображений : виджеты для работы с изображениями и встраиваниями ImageNet
- Сеть : виджеты для графического и сетевого анализа
- Анализ текста : виджеты для обработки естественного языка и интеллектуального анализа текста
- Временные ряды : виджеты для анализа и моделирования временных рядов
- Спектроскопия : виджеты для анализа и визуализации (гипер) спектральных наборов данных [8]
Программа предоставляет платформу для выбора экспериментов, систем рекомендаций и прогнозного моделирования и используется в биомедицине , биоинформатике , геномных исследованиях и обучении. В науке он используется в качестве платформы для тестирования новых алгоритмов машинного обучения и внедрения новых методов в генетике и биоинформатике. В образовании он использовался для обучения методам машинного обучения и интеллектуального анализа данных студентов, изучающих биологию, биомедицину и информатику.
Различные проекты основываются на Orange либо путем расширения основных компонентов с помощью надстроек, либо с использованием только Orange Canvas для использования реализованных функций визуального программирования и графического интерфейса.
Пример решения задачи на базе аналитической low-code платформы Loginom:
Кластеризация — объединение объектов или наблюдений в непересекающиеся группы, называемые кластерами.
Ирисы Фишера — это набор данных для задачи классификации, на примере которого Р. Фишер (1936 г.) продемонстрировал работу разработанного им метода дискриминантного анализа. Ирисы Фишера состоят из данных о 150 экземплярах ириса, по 50 экземпляров из трёх видов — Ирис щетинистый (Iris setosa), Ирис виргинский (Iris virginica) и Ирис разноцветный (Iris versicolor). Для каждого экземпляра измерялись четыре характеристики (в сантиметрах):
- Длина чашелистика (SepalLength);
- Ширина чашелистика (SepalWidth);
- Длина лепестка (PetalLength);
- Ширина лепестка (PetalWidth).
Ирисы Фишера хорошо поддаются кластеризации метрическими алгоритмами.
Исходные данные
Имя поля Метка поля SepalLength Длина чашелистика SepalWidth Ширина чашелистика PetalLength Длина лепестка PetalWidth Ширина лепестка Class Класс Алгоритм
- Импорт исходных данных;
- Кластеризация:
-
;
- Кластеризация k-means;
- Кластеризация g-means.
- Feature (Особенности): входная переменная, используемая для создания прогнозов.
- Predictions (Прогнозы): выходные данные модели при наличии входного примера.
- Example (Пример): строка набора данных. Пример обычно содержит один или несколько объектов.
- Label (Метки): результат функции.
- Иерархическая кластеризация хуже подходит для кластеризации больших объемов данных в сравнении с методом k-средних. Это объясняется тем, что временная сложность алгоритма линейна для метода k-средних (O(n)) и квадратична для метода иерархической кластеризации (O(n 2 ))
- В кластеризации при помощи метода k-средних алгоритм начинает построение с произвольного выбора начальных точек, поэтому, результаты, генерируемые при многократном запуске алгоритма, могут отличаться. В то же время в случае иерархической кластеризации результаты воспроизводимы.
- Из центроидной геометрии построения метода k-средних следует, что метод хорошо работает, когда форма кластеров является гиперсферической (например, круг в 2D или сфера в 3D).
- Метод k-средних более чувствителен к зашумленным данным, чем иерархический метод.
- Экспертный метод. Выбор количества кластеров будет зависеть от знания о предметной области (domain knowledge)
- Метод локтя (elbow method). Мы также можем (1) обучить модель используя несколько вариантов количества кластеров, (2) измерить сумму квадратов внутрикластерных расстояний и (3) выбрать тот вариант, при котором данное расстояние перестанет существенно уменьшаться.
- n_clusters: это количество кластеров, на которые мы хотим разбить наши наблюдения
- init: определяет, как мы выберем первоначальное расположение (инициализацию) центроидов; есть два варианта, (1) выбрать центроиды случайно init = 'random' или (2) выбрать их так, чтобы центроиды с самого начала располагались максимально далеко друг от друга init = 'k-means++' ; второй вариант оптимальнее
- n_init: сколько раз алгоритм будет инициализирован, т.е. сколько раз будут выбраны центроиды до начала оптимизации; на выходе будет выбран тот вариант, где ошибка была минимальна
- max_iter: максимальное количество итераций алгоритма после первоначального выбора центроидов
- random_state: воспроизводимость результата, с этим мы уже знакомы
Сценарий
EM Кластеризация
Рассмотрим настройки обработчика EM кластеризация:
Результаты EM кластеризации представлены в разделе Интерпретация.
Кластеризация (k-means)
Примечание: отличие Кластеризации k-means от g-means в том, что если количество кластеров известно, то применяется алгоритм k-means, в противном случае g-means, который определит это количество автоматически в рамках заданного интервала. В Loginom для этого используется один и тот же обработчик Кластеризация, но настраивается по-разному.
Рассмотрим настройки узла:
Результаты Кластеризации k-means представлены в разделе Интерпретация.
Кластеризация (g-means)
Рассмотрим настройки узла:
Результаты Кластеризации g-means представлены в разделе Интерпретация.
Интерпретация
Для представления результатов используются следующие визуализаторы:
EM Кластеризация
Таблица отражает разбиение входного набора на кластеры и позволяет оценить вероятность принадлежности класса к определенной группе.

Рисунок 5. Разбиение на кластеры.
В каждом кластере получилось примерно равное количество объектов. Алгоритм выделил 3 группы, которые совпадают с количеством исходных классов и примерно равны, что говорит о хорошей работе алгоритма EM кластеризации.

Рисунок 6. Профили кластеров.
Ниже представлены статистические показатели, по которым можно сравнить кластеры:

Рисунок 7. Профили кластеров (сравнение).
Кластеризация k-means
Таблица отражает разбиение входного набора на кластеры и позволяет оценить принадлежность класса к определенной группе.

Рисунок 8. Разбиение на кластеры.
Алгоритм выделил 3 группы, которые совпадают с количеством классов входного набора, однако в каждом кластере получилось сильно различающееся количество объектов. Таким образом, k-means кластеризация получилась менее точна, чем EM.

Рисунок 9. Профили кластеров.
Ниже представлены статистические показатели, по которым можно сравнить кластеры:

Рисунок 10. Профили кластеров (сравнение).
Кластеризация g-means
Таблица отражает разбиение входного набора на кластеры и позволяет оценить принадлежность класса к определенной группе.

Рисунок 11. Разбиение на кластеры.
Алгоритм выделил 2 кластера, которые, во-первых, не совпадают с количеством классов исходного набора, а, во-вторых, получились неравномерными. Таким образом, g-means кластеризация оказалась наименее точной, и ее результаты можно оценить как неудовлетворительные.

Рисунок 12. Профили кластеров.
Ниже представлены статистические показатели, по которым можно сравнить кластеры:

Рисунок 13. Профили кластеров (сравнение).
Описаны четыре популярных метода обучения без учителя для кластеризации данных с соответствующими примерами программного кода на Python.

Обучение без учителя (unsupervised learning, неконтролируемое обучение) – класс методов машинного обучения для поиска шаблонов в наборе данных. Данные, получаемые на вход таких алгоритмов обычно не размечены, то есть передаются только входные переменные X без соответствующих меток y. Если в контролируемом обучении (обучении с учителем, supervised learning) система пытается извлечь уроки из предыдущих примеров, то в обучении без учителя – система старается самостоятельно найти шаблоны непосредственно из приведенного примера.

На левой части изображения представлен пример контролируемого обучения: здесь для того, чтобы найти лучшую функцию, соответствующую представленным точкам, используется метод регрессии. В то же время при неконтролируемом обучении входные данные разделяются на основе представленных характеристик, а предсказание свойств основывается на том, какому кластеру принадлежит пример.
Методы кластеризации данных являются одним из наиболее популярных семейств машинного обучения без учителя. Рассмотрим некоторые из них подробнее.
Для составления прогнозов воспользуемся классическим набором данных ирисов Фишера. Датасет представляет набор из 150 записей с пятью атрибутами в следующем порядке: длина чашелистика (sepal length), ширина чашелистика (sepal width), длина лепестка (petal length), ширина лепестка (petal width) и класс, соответствующий одному из трех видов: Iris Setosa, Iris Versicolor или Iris Virginica, обозначенных соответственно 0, 1, 2. Наш алгоритм должен принимать четыре свойства одного конкретного цветка и предсказывать, к какому классу (виду ириса) он принадлежит. Имеющиеся в наборе данных метки можно использовать для оценки качества предсказания.
Для решения задач кластеризации данных в этой статье мы используем Python, библиотеку scikit-learn для загрузки и обработки набора данных и matplotlib для визуализации. Ниже представлен программный код для исследования исходного набора данных.
В результате запуска программы вы увидим следующие текст и изображение.

На диаграмме фиолетовым цветом обозначен вид Setosa, зеленым – Versicolor и желтым – Virginica. При построении были взяты лишь два признака. Вы можете проанализировать как разделяются классы при других комбинациях параметров.

Цель кластеризации данных состоит в том, чтобы выделить группы примеров с похожими чертами и определить соответствие примеров и кластеров. При этом исходно у нас нет примеров такого разбиения. Это аналогично тому, как если бы в приведенном наборе данных у нас не было меток, как на рисунке ниже.
Наша задача – используя все имеющиеся данные, предсказать соответствие объектов выборки их классам, сформировав таким образом кластеры.
Наиболее популярным алгоритмом кластеризации данных является метод k-средних. Это итеративный алгоритм кластеризации, основанный на минимизации суммарных квадратичных отклонений точек кластеров от центроидов (средних координат) этих кластеров.
Первоначально выбирается желаемое количество кластеров. Поскольку нам известно, что в нашем наборе данных есть 3 класса, установим параметр модели n_clusters равный трем.
Теперь случайным образом из входных данных выбираются три элемента выборки, в соответствие которым ставятся три кластера, в каждый из которых теперь включено по одной точке, каждая при этом является центроидом этого кластера.
Далее ищем ближайшего соседа текущего центроида. Добавляем точку к соответствующему кластеру и пересчитываем положение центроида с учетом координат новых точек. Алгоритм заканчивает работу, когда координаты каждого центроида перестают меняться. Центроид каждого кластера в результате представляет собой набор значений признаков, описывающих усредненные параметры выделенных классов.
При выводе данных нужно понимать, что алгоритм не знает ничего о нумерации классов, и числа 0, 1, 2 – это лишь номера кластеров, определенных в результате работы алгоритма. Так как исходные точки выбираются случайным образом, вывод будет несколько меняться от одного запуска к другому.
Характерной особенностью набора данных ирисов Фишера является то, что один класс (Setosa) легко отделяется от двух остальных. Это заметно и в приведенном примере.
Иерархическая кластеризация, как следует из названия, представляет собой алгоритм, который строит иерархию кластеров. Этот алгоритм начинает работу с того, что каждому экземпляру данных сопоставляется свой собственный кластер. Затем два ближайших кластера объединяются в один и так далее, пока не будет образован один общий кластер.
Результат иерархической кластеризации может быть представлен с помощью дендрограммы. Рассмотрим этот тип кластеризации на примере данных для различных видов зерна.

Можно видеть, что в результате иерархической кластеризации данных естественным образом произошло разбиение на три кластера, обозначенных на рисунке различным цветом. При этом исходно число кластеров не задавалось.
Метод t-SNE (t-distributed stochastic neighbor embedding) представляет собой один из методов обучения без учителя, используемых для визуализации, например, отображения пространства высокой размерности в двух- или трехмерное пространство. t-SNE расшифровывается как распределенное стохастическое соседнее вложение.
Метод моделирует каждый объект пространства высокой размерности в двух- или трехкоординатную точку таким образом, что близкие по характеристикам элементы данных в многомерном пространстве (например, датасете с большим числом столбцов) проецируются в соседние точки, а разнородные объекты с большей вероятностью моделируются точками, далеко отстоящими друг от друга. Математическое описание работы метода можно найти здесь.
Вернемся к примеру с ирисами и посмотрим, как произвести моделирование по этому методу при помощи библиотеки sklearn.

В этом случае каждый экземпляр представлен четырьмя координатами – таким образом, при отображении признаков на плоскость размерность пространства понижается с четырех до двух.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise, плотностной алгоритм пространственной кластеризации с присутствием шума) – популярный алгоритм кластеризации, используемый в анализе данных в качестве одной из замен метода k-средних.
Метод не требует предварительных предположений о числе кластеров, но нужно настроить два других параметра: eps и min_samples. Данные параметры – это соответственно максимальное расстояние между соседними точками и минимальное число точек в окрестности (количество соседей), когда можно говорить, что эти экземпляры данных образуют один кластер. В scikit-learn есть соответствующие значения параметров по умолчанию, но, как правило, их приходится настраивать самостоятельно.

Об устройстве алгоритма простыми словами и о математической подноготной можно прочитать в этой статье.

В этой статье, переводом которой мы решили поделиться специально к старту курса о Data Science, автор представляет новый пакет Python для генерации кластерограмм из решений кластеризации. Библиотека была разработана в рамках исследовательского проекта Urban Grammar и совместима со scikit-learn и библиотеками с поддержкой GPU, такими как cuML или cuDF в рамках RAPIDS.AI.
Когда мы хотим провести кластерный анализ для выявления групп в наших данных, мы часто используем алгоритмы типа метода k-средних, которые требуют задания количества кластеров. Но проблема в том, что мы обычно не знаем, сколько кластеров существует.
Существует множество методов определения правильного числа, например силуэты или локтевой сгиб. Но они обычно не дают представления о том, что происходит между различными вариантами, поэтому цифры немного абстрактны.
Маттиас Шонлау предложил другой подход — кластерограмму. Кластерограмма — это двухмерный график, отражающий потоки наблюдений между классами по мере добавления кластеров. Это говорит вам о том, как перетасовываются ваши данные и насколько хороши ваши сплиты. Тал Галили позже реализовал кластерограмму для k-средних в R. Я использовал реализацию Таля, перенёс ее на Python и создал clustergram — пакет Python для создания кластерограмм.
clustergram в настоящее время поддерживает метод k-средних, использование scikit-learn (включая реализацию Mini-Batch) и RAPIDS.AI cuML (если у вас есть GPU с поддержкой CUDA), Gaussian Mixture Model (только scikit-learn) и иерархическую кластеризацию на основе scipy.hierarchy. В качестве альтернативы мы можем создать кластерограмму на основе меток и данных, полученных с помощью альтернативных пользовательских алгоритмов кластеризации. Пакет предоставляет API, подобный sklearn, и строит кластерные диаграммы с помощью matplotlib, что даёт ему широкий выбор вариантов оформления в соответствии со стилем вашей публикации.
Установка
Установить clustergram можно при помощи conda или pip:
conda install clustergram -c conda-forge
pip install clustergram
В любом случае вам нужно установить выбранный бэкенд (scikit-learn и scipy или cuML).
Давайте рассмотрим несколько примеров, чтобы понять, как выглядит кластерограмма и что с ней делать.
Набор данных о цветке ириса
Первый пример, который мы пытаемся проанализировать с помощью кластерограммы, — это знаменитый набор данных о цветке ириса. Он содержит данные по трём видам цветков ириса с измерением ширины и длины чашелистиков, а также и ширины и длины лепестков. Мы можем начать с разведки:

Похоже, что setosa — относительно чётко определённая группа, тогда как разница между versicolor и virginica меньше, поскольку они частично перекрываются (или, в случае ширины чашелистика, полностью).
Итак, мы знаем, как выглядят данные. Теперь мы можем увидеть кластерограмму. Помните, мы знаем, что существует три кластера, и в идеале мы должны быть в состоянии распознать это по кластерограмме. Я говорю “в идеале”, потому что, даже если есть известные метки, это не значит, что наши данные или метод кластеризации способны различать эти классы.
Давайте начнём с кластеризации методом k-средних. Чтобы получить стабильный результат, мы можем запустить кластерную программу с 1000 инициализаций.

На оси x мы видим количество кластеров. Точки представляют собой центр каждого кластера (по умолчанию), взвешенный по первой главной компоненте (это помогает сделать диаграмму более читабельной). Линии, соединяющие точки, и их толщина представляют наблюдения, перемещающиеся между кластерами. Поэтому мы можем прочитать, когда новые кластеры образуются как расщепление одного существующего класса и когда они образуются на основе наблюдений из двух кластеров.
Мы ищем разделение, т. е. отвечаем на вопрос, принёс ли дополнительный кластер какое-либо значимое разделение? Шаг от одного кластера к двум большой — хорошее и чёткое разделение. От двух до трёх — свидетельство довольно хорошего раскола в верхней ветви. Но с 3 по 4 видимой разницы нет, потому что новый четвёртый кластер почти не отличается от существующей нижней ветви. Хотя сейчас она разделена на две части, это разделение не даёт нам много информации. Таким образом, можно сделать вывод, что идеальное количество кластеров для данных Iris — три.
Мы также можем проверить некоторую дополнительную информацию, например оценку силуэта или оценку Калинского — Харабазса.

По этим графикам можно предположить наличие 3–4 кластеров по аналогии с кластерограммой, но они не очень убедительны.
Набор данных о пингвинах со станции Палмера
Теперь попробуем другие данные, где кластеры оценить немного сложнее. Пингвины Палмера содержат данные, подобные тем, что в примере Iris, но в нём измеряются несколько признаков трёх видов пингвинов.

Глядя на ситуацию, мы видим, что перекрытие между видами гораздо выше, чем раньше. Скорее всего, идентифицировать их будет гораздо сложнее. Кроме того, мы знаем, что существует три кластера, но это не означает, что данные способны их различать. В этом случае может быть особенно сложно отличить пингвинов Адели от антарктических пингвинов.

Мы ищем разделения, и эта кластерограмма показывает достаточное их количество. На самом деле определить оптимальное количество кластеров довольно сложно. Однако, поскольку мы знаем, что происходит между различными вариантами, мы можем поиграть с этим. Если у нас есть причина быть консервативными, мы можем обойтись 4 кластерами (я знаю, это уже больше, чем первоначальный вид). Но и дальнейшее разделение также разумно, а это указывает на то, что даже более высокая детализация может дать полезную информацию, что могут существовать значимые группы.
Можно ли сказать, что их три? Поскольку мы знаем, что их должно быть три. Ну, не совсем. Разница между разделениями 2–3 и 3–4 незначительна. Однако здесь виновником является метод K ближайших соседей, а не кластерограмма. Он просто не может правильно кластеризовать эти данные из-за наложений и общей структуры. Давайте посмотрим, как работает смешанная Гауссова модель (Gaussian Mixture).

Результат очень похож, хотя разница между третьим и четвёртым разделениями более выражена. Даже здесь я бы, вероятно, выбрал решение с четырьмя кластерами.
Подобная ситуация случается очень часто. Идеального случая не существует. В конечном счёте нам необходимо принять решение об оптимальном количестве кластеров. Clustergam даёт нам дополнительные сведения о том, что происходит между различными вариантами, как они расходятся. Можно сказать, что вариант с четырьмя кластерами в данных Iris не помогает. Также можно сказать, что пингвины Палмера могут быть сложными для кластеризации с помощью k-средних, что нет решающего правильного решения. Кластерограмма не даёт простого ответа, но она даёт нам лучшее понимание, и только от нас зависит, как мы её [кластерограмму] интерпретируем.
Установить clustergram можно с помощью conda install clustergram -c conda-forge или pip install clustergram. В любом случае вам всё равно придётся установить бэкенд кластеризации: либо scikit-learn, либо cuML. Документация доступна здесь, а исходный код — здесь, он выпущен под лицензией MIT.
Если вы хотите поиграть с примерами из этой статьи, блокнот Jupyter находится на GitHub. Вы также можете запустить его в среде interactive binder в браузере. Более подробную информацию можно найти в блоге Тала Галили и оригинальных статьях Матиаса Шонлау.
Вполне понятно, что идеальной кластеризации не существует. И даже сегодня, с учётом всего прогресса искусственного интеллекта, для принятия сложных решений о данных по-прежнему нужен человек. Если вам интересна наука о данных — область, в которой такие решения принимаются постоянно — вы можете обратить внимание на наш курс о Data Science, где через подкреплённую теорией практику студенты учатся ориентироваться в данных, делать обоснованные выводы и действовать с открытыми глазами.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
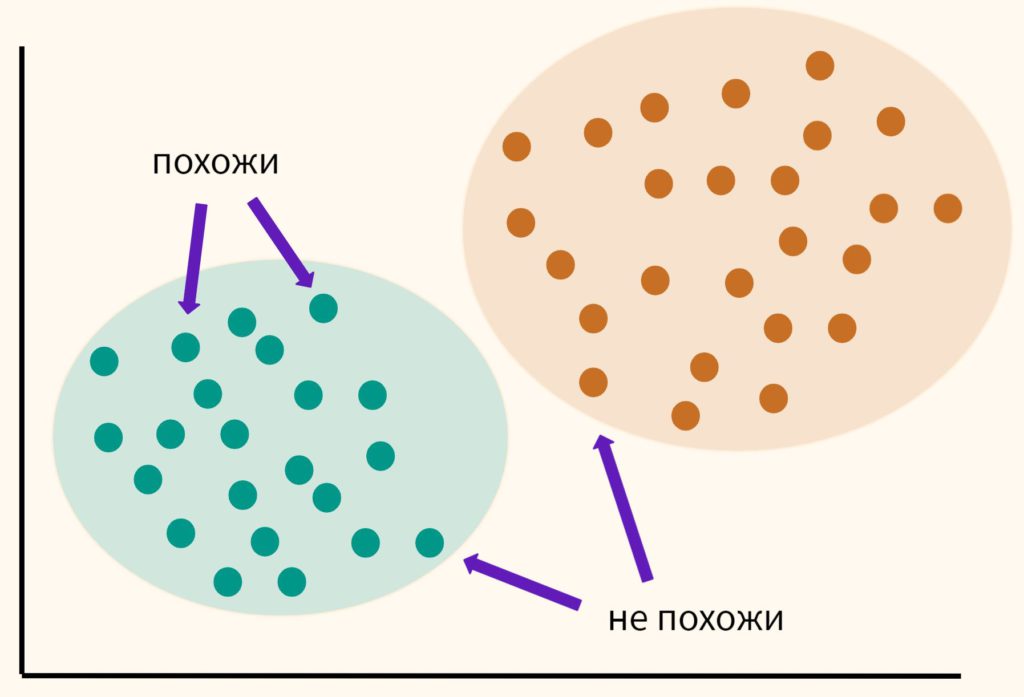
Основная идея кластерного анализа (clustering, cluster analysis) заключается в том, чтобы разбить объекты на группы или кластеры таким образом, чтобы внутри группы эти наблюдения были более похожи друг на друга, чем на объекты другого кластера.
При этом мы заранее не знаем на какие кластеры необходимо разбить наши данные. Это связано с тем, что мы обучаем модель на неразмеченных данных (unlabeled data), то есть без целевой переменной, компонента y. Именно поэтому в данном случае говорят по машинное обучение без учителя (Unsupervised Learning).
Кластерный анализ может применяться для сегментации потребителей, обнаружения аномальных наблюдений (например, при выявлении мошенничества) и в целом для структурирования данных, о содержании которых мало что известно заранее.
Как же разбить данные на кластеры?
Изучая векторы и матрицы, мы узнали, что векторы данных можно сравнивать между собой (оценивать их схожесть), измеряя расстояние между ними. Кластерный анализ использует именно этот подход. Мы измеряем расстояние между точками и на основе этого измерения принимаем решение к какому кластеру отнести то или иное наблюдение.
В рамках этого занятия мы поговорим про алгоритм, который называется методом k-средних (k-means clustering method).
Метод k-средних
Давайте пошагово разберемся в том, как работает этот алгоритм.
Шаг 1. Вначале возьмем данные и самостоятельно выберем желаемое количество кластеров и обозначим их буквой k (отсюда название метода). Пусть в данном случае их будет три.
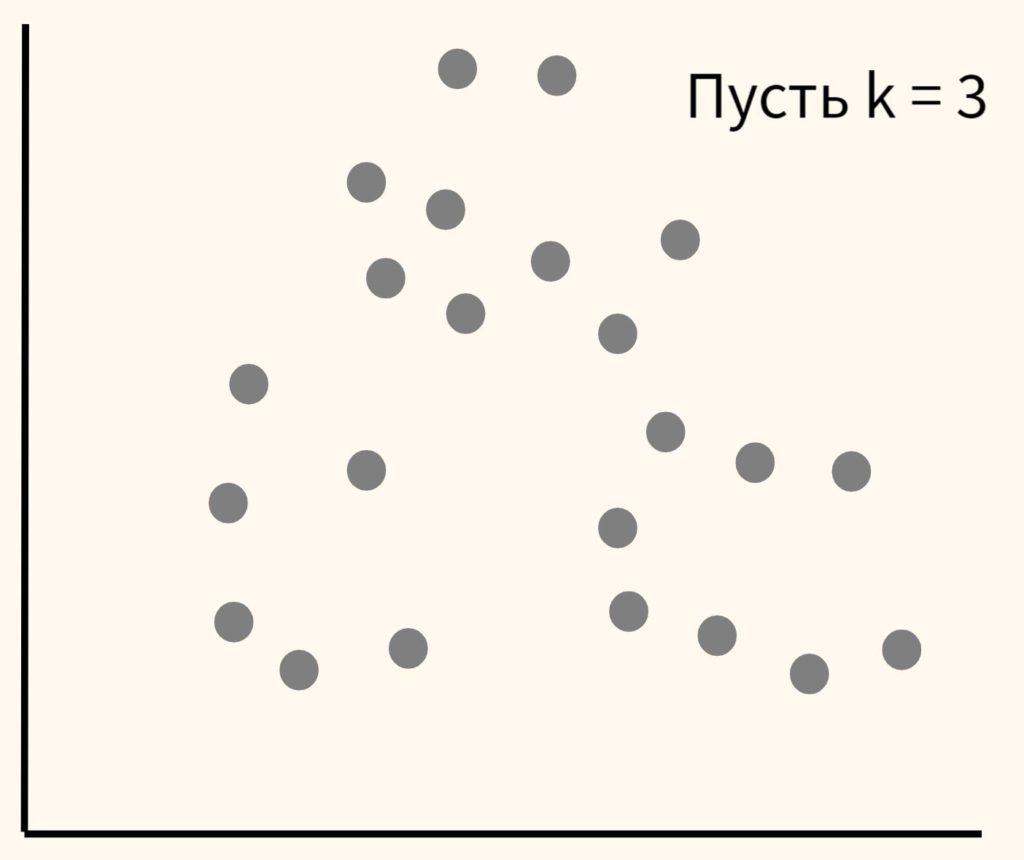
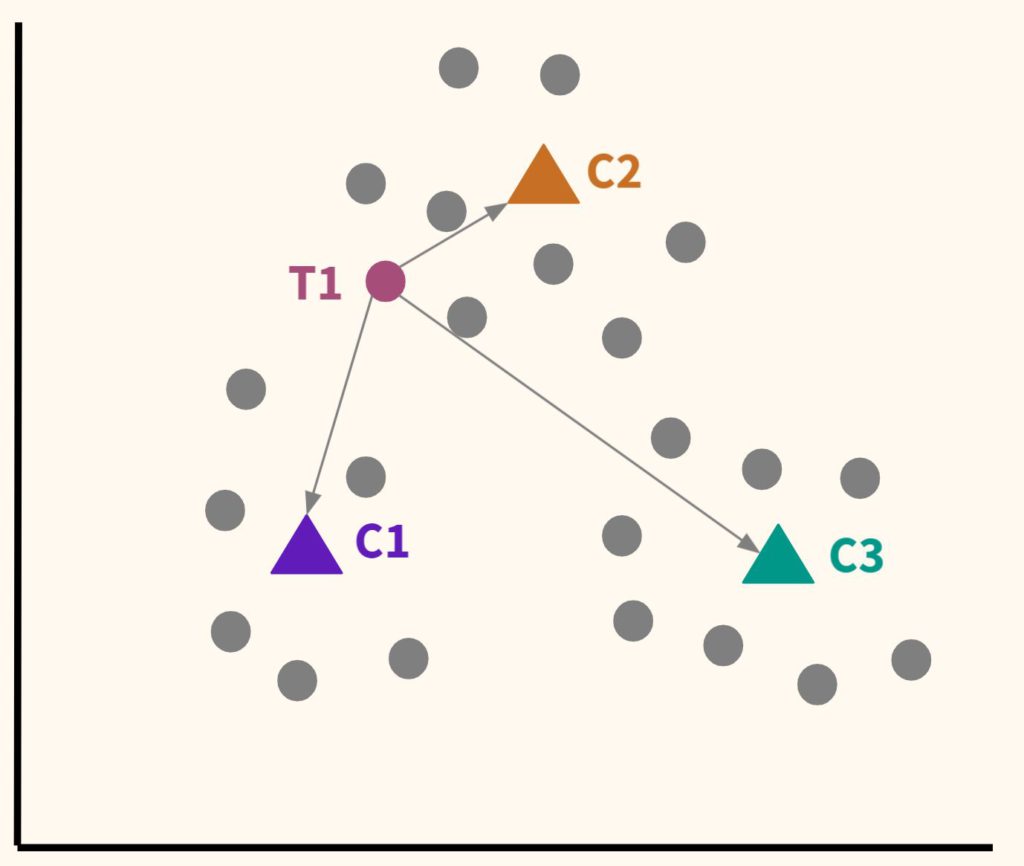
Шаг 2. Расположим несколько точек. Их количество будет равно количеству кластеров. Эти точки называются центроидами. Посчитаем расстояние от наших данных до каждого из центроидов. Логично отнести наблюдение к тому центроиду, который находится ближе.

В частности, T1 будет отнесена к C2.
Шаг 3. Таким образом, каждая точка будет отнесена к определенному центроиду (кластеру).
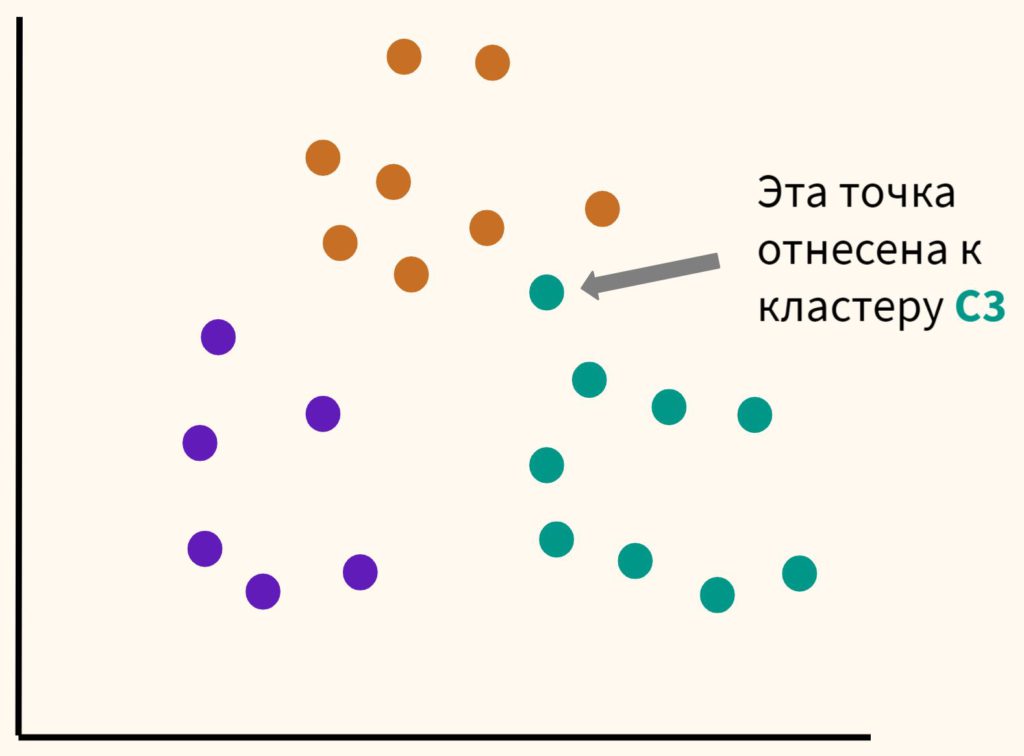
Шаг 4. Сместим наши центроиды в центр получившихся кластеров.

Мы будем повторять шаги 4 и 5 до тех пор, пока алгоритм не стабилизируется, то есть до тех пор, пока наблюдения не перестанут переходить от одного центроида (кластера) к другому.
Говоря более формально, цель алгоритма — минимизировать сумму квадратов внутрикластерных расстояний до центра кластера (within-cluster sum of squares, WCSS, наша функция потерь):
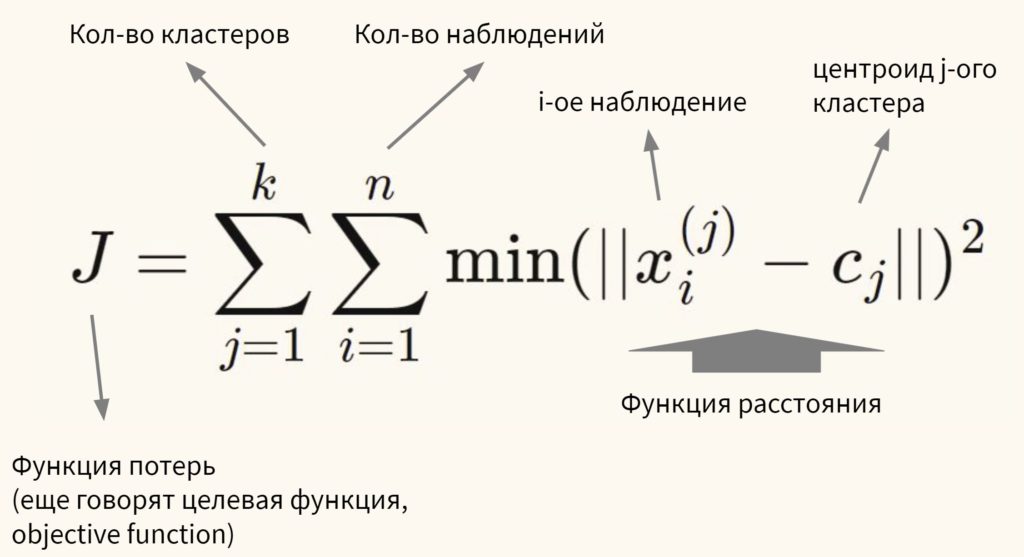
Остается нерешенным важный вопрос.
Сколько кластеров выбрать?
Есть два способа выбора количества кластеров:
На графике метод локтя выглядит следующим образом.
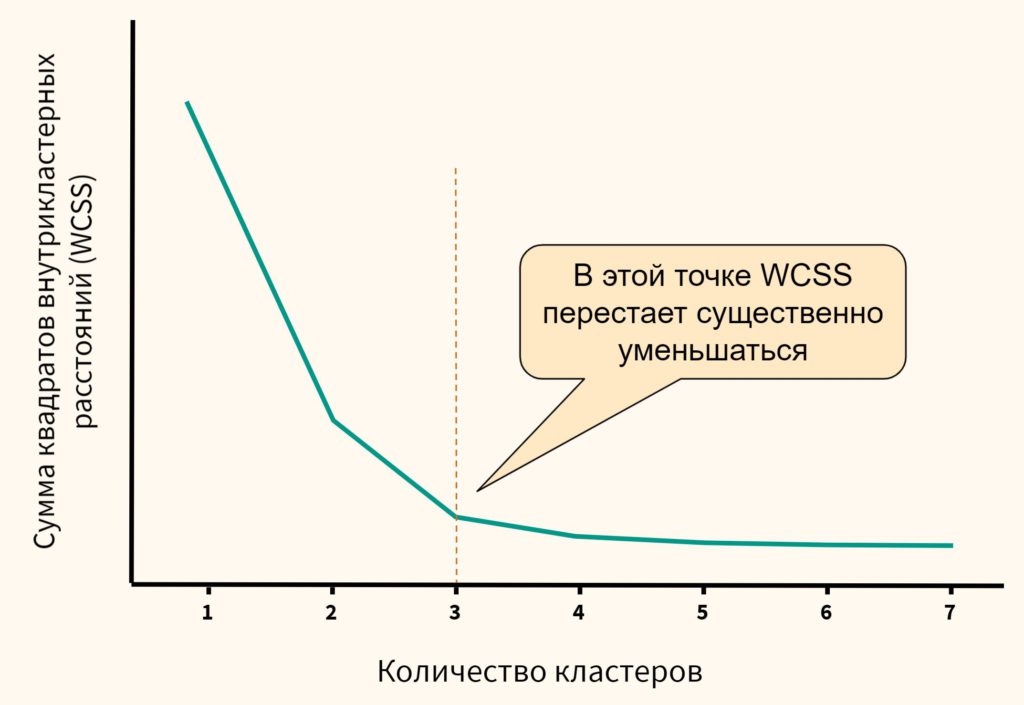
Как мы видим, после того как количество кластеров достигает трех, сумма квадратов внутрикластерных расстояний перестает существенно уменьшаться. Значит в данном случае три кластера и будет оптимальным значением.
О важности нормализации данных
Алгоритм очень чувствителен к масштабу признаков. В связи с этим нормализация данных (feature scaling) приобретает особое значение. Так как при формировании кластеров мы измеряем расстояние (в частности, Евклидово расстояние), то признаки с большим масштабом будут иметь больший вес. Приведу пример.
Предположим у вас есть данные о возрасте и ежемесячных тратах людей по кредитным картам.
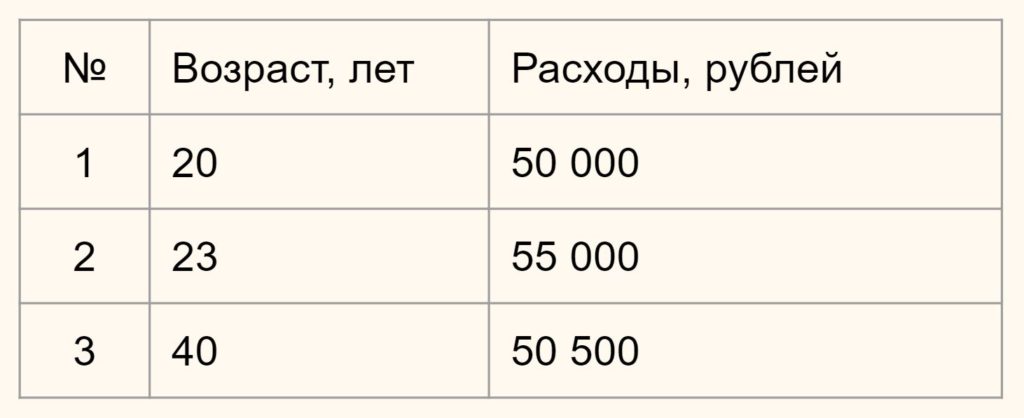
Нам нужно определить насколько человек 1 отличается (насколько велико расстояние) от человека 2 и 3. В зависимости от этого мы будем формировать наши кластеры.
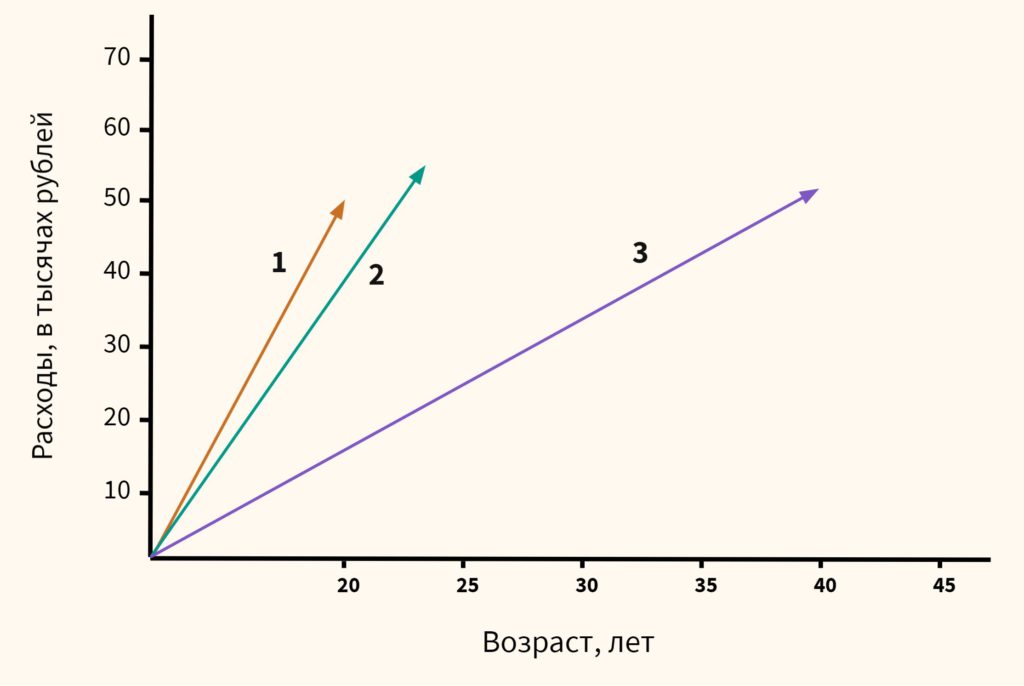
Вначале давайте обратимся к здравому смыслу. Мы видим, что респонденты 1 и 2 схожи, потому что им обоим около 20-ти и расходы у них примерно одинаковы. Респондент 3, имея схожие расходы, сильно отличается из-за своего возраста. Он в два раза старше. Это особенно легко увидеть на графике ниже:
Теперь посмотрим, что скажет математика, если мы оставим масштаб признаков без изменений.
Напомню формулу Евклидова расстояния.
В данном случае x1 и x2 — это возраст двух сравниваемых нами людей, а y1 и y2 — их расходы. Подставим значения в формулу.
$$ D_1 = \sqrt <\left( <23-20 >\right)^2 + \left( \right)^2 > \approx 5000 $$
Как мы видим, расстояние от человека 1 до человека 2 целых 5000 единиц (лет и рублей), в то время как до человека 3 только 500. Результат обратный тому, на который мы рассчитывали исходя из здравого смысла.
Это связано с тем, что масштаб второго признака (расходов) намного больше масштаба первого (возраст). И даже небольшое изменение в расходах вызывает существенное изменение расстояния, в то время как значительное изменение возраста не оказывает на него практически никакого влияния.
Практический пример — цветы ириса
Для иллюстрации работы алгоритма кластеризации мы возьмем еще один классический датасет из библиотеки sklearn, а именно данные о цветах ириса.

Этап 1. Загрузка данных
Давайте сразу загрузим данные и преобразуем их в формат датафрейма из библиотеки Pandas.
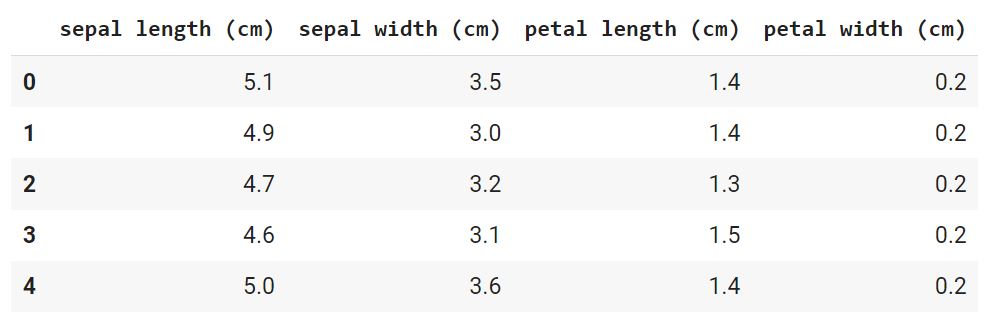
В данном случае речь идет о наборе данных, который состоит из 150 образцов цветов ириса, разделенных на три вида (Iris setosa, Iris virginica и Iris versicolor) по 50 растений в каждом. Каждый образец описан четырьмя атрибутами (длиной и шириной чашелистика и длиной и шириной лепестка).
Обратите внимание, мы сознательно не стали использовать целевую переменную, потому что решаем задачу кластеризации и предполагается, что мы не знаем заранее на какие группы или кластеры удастся разбить наши данные.
С другой стороны, тот факт, что нам заранее известно, что видов здесь три, поможет нам оценить качество кластерного анализа (об этом ниже).
Этап 2. Предварительная обработка данных
Для начала посмотрим, присутствуют ли пропущенные значения.
Мы видим, что пропущенных значений нет. Датасет был предварительно обработан.
Категорийных переменных у нас также нет. Это становится понятно из результата функции head().
Остается разобраться с масштабом признаков. Как уже было сказано, для метода k-средних нормализация данных имеет особое значение. Даже небольшое различие в масштабе признаков может повлиять на конечный результат.

Этап 3 и 4. EDA и отбор признаков
Для целей кластерного анализа мы возьмем все имеющиеся у нас данные.
Этап 5.1. Обучение модели
Самый главный вопрос, который нам предстоит решить на этапе обучения модели заключается в выборе количества кластеров.
Количество кластеров в методе k-средних являтся так называемым гиперпараметром, то есть параметром, который нужно задать до обучения модели.
Мы усложним решаемую нами задачу и сделаем вид, что не обладаем экспертными знаниями о количестве видов ириса (на самом деле напомню, мы знаем, что их три). Значит нужно использовать метод локтя.
kmeans = KMeans ( n_clusters = i , init = 'k-means++' , max_iter = 300 , n_init = 10 , random_state = 42 )

Как видно на графике, когда мы перешли от трех до четырех кластеров, ошибка перестала существенно уменьшаться (это согласуется с тем, что видом действительно три).
Давайте создадим объект класса нашей модели, используя три кластера в качестве гипепараметра модели.
kmeans = KMeans ( n_clusters = 3 , init = 'k-means++' , max_iter = 300 , n_init = 10 , random_state = 42 )
Подробнее рассмотрим параметры модели:
Обучим модель и сделаем прогноз:
Этап 5.2. Оценка качества модели
Остается проверить качество модели и здесь возникает сложность. Ведь если при обучении с учителем у нас был критерий (целевая переменная), то здесь такого критерия нет.
Впрочем, так как у нас учебный датасет, и мы заранее знаем, к какому виду относится каждый цветок, то можем сравнить результат нашей модели с целевой переменной.
На настоящих данных такое конечно невозможно.
Вначале преобразуем нашу целелевую переменную (iris.target) и наш прогноз (y_pred) в датафрейм (предварительно слегка их изменив, подробности в ноутбуке⧉).

С помощью функции where() создадим массив Numpy, в котором сравним каждую строчку датафрейма, и если целевая переменная и прогноз совпадают, зададим значение True, в противном случае — False.
Добавим этот массив в качестве столбца в датафрейм.
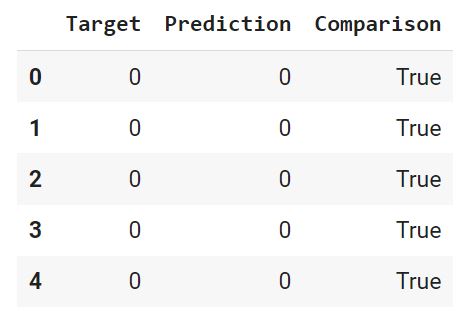
Выведем долю совпавших (True) и не совпавших (False) значений. Для этого используем функцию value_counts(), которая подсчитает, сколько раз встречается каждое значение. Параметр normalize = True вернет относительное значение или процент. Ровно это нам и нужно.
Как мы видим, модель была права в 83% случаев. Теперь давайте визуально оценим результат.
В исходном датафрейме четыре признака, а значит четыре измерения, столько мы представить графически не можем. Давайте возьмем первый (sepal length) и второй (sepal width) столбец исходного датафрейма.
Вначале построим точечную диаграмму целевой переменной.

Теперь посмотим на результат алгоритма кластеризации.
plt . scatter ( kmeans . cluster_centers_ [ : , 0 ] , kmeans . cluster_centers_ [ : , 1 ] , s = 150 , c = 'red' , marker = '^' , label = 'Centroids' )

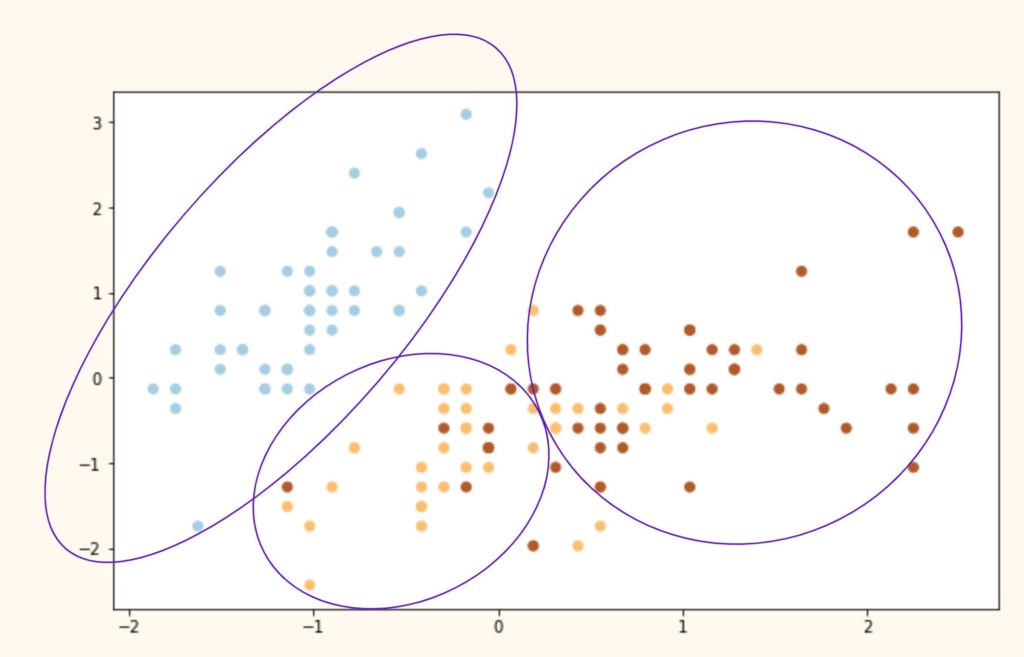
Выводы. Как мы видим, алгоритм идеально справился с кластером 0 (светлоголубой), однако допустил ошибки при разделение кластеров 1 и 2 (желтый и коричневый цвета). Почему?
Иллюстрация ниже примерно показывает, что сделал алгоритм с нашими исходными видами и почему он ошибочно группировал некоторые точки.
Подведем итог
При решении задач кластеризации мы берем данные, обязательно их масштабируем и выбираем количество кластеров (с помощью экспертной оценки или метода локтя) . К сожалению, дать точную оценку качества кластеризации бывает очень сложно из-за отсутствия разметки.
Вопросы для закрепления
Почему кластеризация называется машинным обучением без учителя?
Посмотреть правильный ответ
Ответ: в таких задачах отсутствует целевая переменная, разметка. Алгоритм пытается структурировать данные, о которых мало что известно заранее.
Как выбирается гиперпараметр модели (количество кластеров)?
Посмотреть правильный ответ
Ответ: существует два способа: (1) экспертное мнение и (2) метод локтя
В чем заключаются основные ограничения модели k-средних?
Посмотреть правильный ответ
Ответ: модель (1) очень чувствительна к масштабу признаков, и кроме того алгоритм предполагает (2) выпуклость и (3) разделенность данных
Дополнительные упражнения⧉ вы найдете в конце ноутбука.
Мы закончили третий раздел классических алгоритмов машинного обучения. Пора переходить к более продвинутым задачам. Начнем с рекомендательных систем.
Здравствуйте! Скажите, а чем init = ‘k-means++’ лучше, чем init = ‘random’? Можете чуть подробнее объяснить. Спасибо!
Максим, спасибо за вопрос. Давайте разбираться. В первую очередь, посмотрим на случайную инициализацию центроидов (). Как следует из самой формулировки, мы случайным образом выбираем центры кластеров, и затем алгоритм, как описано в лекции, старается минимизировать функцию потерь (WCSS в данном случае).

Как мы видим, алгоритм действительно минимизировал WCSS, однако лишь в пределах того, что ему позволил изначальный выбор положения центроидов. Это так называемый локальный минимум функции потерь. Глобальный же найден не был. Схематически глобальный минимум мог бы выглядеться как на графике ниже.

В данном случае глобальный оптимум был бы достигнут за счет максимизации изначального расстояния между центроидами. На этом и основан метод k-means++ ().
Читайте также: