
Распознавание речи своими руками
Добавил пользователь Алексей Ф. Обновлено: 04.10.2024
Концепция программного обеспечения для распознавания голоса ни в коем случае не является новой технологией. Вы уже познакомились с ним через Microsoft Cortana, Amazon Alexa и Siri. Это виртуальный ИИ, который позволяет вам использовать голосовые команды для управления вашим компьютером и мобильными телефонами. Но сегодня мы рассмотрим не только основные голосовые команды. Потому что с современными технологиями вы можете делать гораздо больше с помощью голоса. Я говорю о преобразовании аудио в текст.
Независимо от того, что вы делаете на своем компьютере, всегда будет какой-то аспект, связанный с набором текста. Отвечать на электронные письма, просматривать веб-страницы, печатать документы и многое другое. А если вы работаете на административной должности или зарабатываете себе на жизнь писательством, то вы будете делать это в еще большем масштабе. Это одна из причин, по которой вам следует подумать о программе для диктовки. Другой вариант использования, когда программное обеспечение для распознавания речи может быть критичным, — это если по какой-то причине вы не можете использовать пальцы. Джон Морроу — один из самых успешных блоггеров, но из-за спинальной мышечной атрофии он не может двигать мышцами рук. Как он это делает? Вы угадали. С помощью программного обеспечения для распознавания голоса.
Раньше было довольно сложно реализовать концепцию голоса в текст из-за большого разрыва, существовавшего между тем, что вы диктовали, и выводом текста. Это означало, что после редактирования документов приходилось тратить долгие часы. Но новые технологии привели к более точному диктату. Мы перечислим 5 лучших программ для распознавания голоса, которые будут для вас неоценимы.
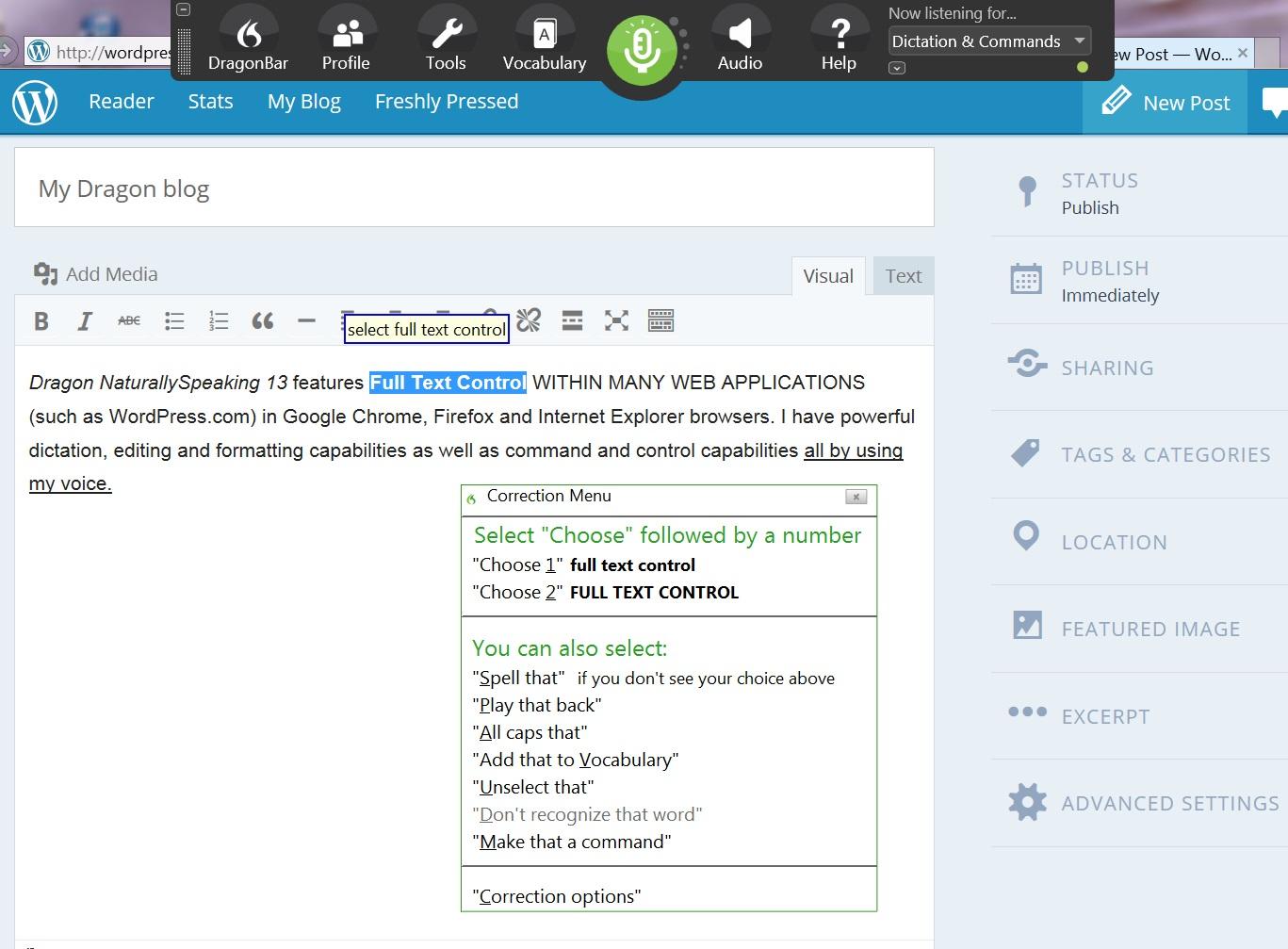
Многие люди хвалят Dragon как программу распознавания речи номер один, и мне придется согласиться с ними по очевидным причинам. Он удивительно точен с первого дня использования и становится еще более точным, когда вы продолжаете его использовать, благодаря технологии глубокого обучения. Это функция, которая позволяет ему адаптироваться к вашему голосу, чем дольше вы его используете, и будет особенно полезна, если у вас иностранный акцент.
Естественно говорящий дракон
Dragon v15 создан для ОС Windows и позволит вам напрямую диктовать текст практически во всех приложениях Windows с помощью голоса. Это включает Microsoft Office и веб-браузеры. Если вы пользователь Mac, не волнуйтесь, вы можете получить точно такой же пакет с Dragon Professional Individual для Mac.
Еще одна вещь, которая вам обязательно понравится в этом программном обеспечении, — это его гибкость. Dragon v15 предлагает бесплатное приложение для записи, которое вы можете использовать для записи качественного звука, когда у вас нет доступа к компьютеру. Затем вы можете преобразовать звук в текст позже благодаря потрясающим возможностям транскрипции Dragon. Как будто это еще не все, у них также есть бесплатное приложение для микрофона, которое можно связать с настольным приложением через Wi-Fi, что дает вам больше свободы передвижения.
Дракон Профессиональный Индивидуальный v12
Помимо диктовки, Dragon также можно использовать в качестве виртуального помощника, выполняя ваши голосовые команды, такие как открытие приложений, отправка электронных писем, просмотр сети и планирование встреч. Это программное обеспечение содержит обучающие модули на экране в каждом из своих пакетов, которые дают четкие рекомендации о том, как в полной мере использовать возможности Dragon.
Dragon Professional v12, возможно, не самый дешевый, но я могу гарантировать, что благодаря тому, что он предлагает, вы получите полную отдачу от своих денег.
Braina, созданная на основе Brain искусственного интеллекта, — еще одно отличное программное обеспечение, которое также будет служить виртуальным помощником поверх диктовки. Вы можете использовать Braina для установки будильника, чтения онлайн-книг, поиска чего-либо в Интернете или даже воспроизведения мультимедиа на вашем компьютере.

Braina
Braina позволяет диктовать текст различным приложениям на вашем компьютере и поддерживает более 100 различных языков. Это программное обеспечение также достаточно эффективно для расшифровки акцентов, и, в довершение всего, вы можете настроить его для точного распознавания слов, которые могут отсутствовать в его базе данных. Кстати, у Braina довольно обширная база данных, охватывающая различные профессии, такие как юриспруденция, медицина и наука. Подобно Дракону, Braina позволяет вам озвучивать команды / текст по беспроводной сети с помощью приложения, доступного как для устройств Android, так и для iOS.
Braina доступна как в бесплатной, так и в платной версиях. Если вы используете бесплатную версию, вам, возможно, придется пойти на компромисс с некоторыми функциями. Например, он поддерживает распознавание голоса только для английского языка.
Пользователям Windows, которые ищут быстрый способ преобразовать свою речь в текст, не нужно далеко ходить. В ОС Windows есть собственный инструмент распознавания голоса, который можно легко настроить. Для пользователей Windows 10 все, что вам нужно сделать, это выполнить поиск по распознаванию речи на панели поиска, расположенной в левой части панели задач, и это запустит процесс установки.
Распознавание речи Windows
Этот инструмент позволяет не только преобразовывать голос в текст, но и управлять вашим компьютером. Это означает, что вы сможете открывать программы и перемещаться по меню, просто используя свой голос. Кроме того, вы сможете управлять каждым приложением из их определенного интерфейса. Будь то электронное письмо или текстовый документ.
Однако для использования распознавания речи Windows вам понадобится специальный микрофон. Он предлагает поддержку микрофона гарнитуры, настольного микрофона и различных других типов, таких как массивные микрофоны. Некоторые пользователи также могут использовать микрофон по умолчанию на своих компьютерах, но в большинстве случаев это может быть проблемой.
Windows Speech Recognition может не иметь возможностей адаптивного обучения Dragon Naturally Speaking, но в нем есть функция обучения распознаванию речи, с помощью которой вы можете научить свой компьютер лучше распознавать вашу речь. Вы также можете предоставить ему доступ к вашим документам, где он определит ваш наиболее часто используемый словарный запас и, следовательно, будет способствовать более точному диктованию. Распознавание Windows доступно на английском, французском, китайском, японском и испанском языках.

Хорошо, в Windows есть встроенный инструмент для диктовки, и поэтому, естественно, Apple должна иметь собственное программное обеспечение для распознавания речи, не так ли? Вы не ошиблись, пользователи iOS и MacOS также имеют доступ к бесплатному программному обеспечению для распознавания голоса под названием Apple Dictation. Если вы используете iOS, вы можете быстро активировать его, нажав микрофон на клавиатуре устройства. Для пользователей MacOS просто перейдите в Системные настройки, нажмите на клавиатуре, а затем на диктовку.
Яблочный диктант
К сожалению, если вы используете любую версию OS X старше 10.9, у вас будет доступ только к стандартной версии этого программного обеспечения, которая имеет свои ограничения. Например, вы не можете использовать его в автономном режиме, и даже тогда вы не можете разговаривать более 40 секунд за один раз. Вероятно, это связано с тем, что ваш звук должен быть сначала отправлен в Apple, прежде чем преобразовываться в текст. Однако с расширенной версией вам не нужно подключаться к Интернету и нет ограничений по времени.
Расширенная версия диктовки также имеет набор из более чем 70 команд, которые облегчают редактирование и форматирование вашего текста. Для простоты использования эти команды видны на небольшом экране дисплея вашего устройства. И что еще лучше, программа Apple Dictation позволяет создавать свои собственные команды. В отличие от распознавания речи Windows, это программное обеспечение поддерживает 20 различных языков.
Если вы часто используете Google Docs и G-Suite в целом, вы будете рады узнать, что в нем есть встроенная функция распознавания голоса, которая позволяет вам легко диктовать текст. И если вы не являетесь пользователем, возможно, вам пора подумать о том, чтобы попробовать его.
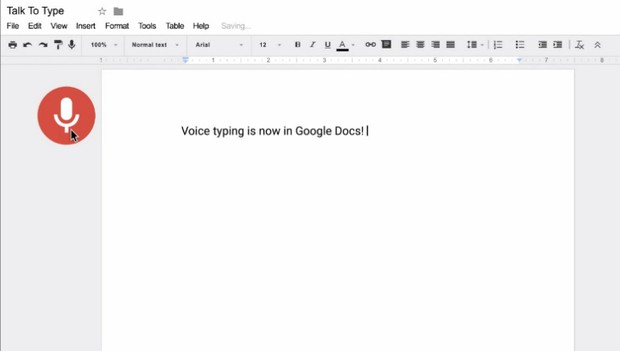
Голосовой ввод Google Документов
Чтобы использовать голосовой набор в Google docs, все, что вам нужно, это учетная запись Google. Как только вы войдете в свою учетную запись, откройте документы Google и перейдите к голосовому вводу. Во время первоначальной настройки вам будет предложено разрешить доступ к микрофону вашего компьютера. Вы также можете подключить внешний микрофон для более точного распознавания голоса. Обратите внимание: для доступа к этой функции вам нужно будет использовать Google Chrome.
Модуль распознавания голоса - Voice Recognition Module V3.1 - это компактный и простой в управлении модуль распознавания речи. На базе данного модуля можно создавать проекты с голосовым управлением.
Для работы модуля его необходимо обучить - записать через микрофон собственные голосовые команды в энергонезависимое хранилище голосовых команд модуля. Вы можете записать до 80 голосовых команд (каждая команда не более 1,5 сек., примерно одно, максимум два слова) и все они будут храниться в модуле, даже после отключения питания. Стоит отметить, что записывать можно не только голос (слова), но и различные звуки.
У модуля есть два вида памяти: память хранилища (где голосовые команды просто хранятся) и память распознавателя (где голосовые команды участвуют в сравнении со звуком поступившем через микрофон).
Перед распознаванием голосовых команд их нужно загрузить из памяти хранилища в память распознавателя. Память распознавателя рассчитана на 7 голосовых команд, значит модуль способен одновременно сравнивать до 7 голосовых команд с поступающим звуковым сигналом.
Термины:
- Хранилище голосовых команд – энергонезависимая память состоящая из 80 ячеек, в каждую ячейку можно записать одну голосовую команду с текстовым комментарием.
- Распознаватель голосовых команд – основная часть модуля распознавания речи, блок содержащий ОЗУ из 7 ячеек, в каждую ячейку можно загрузить одну голосовую команду из хранилища голосовых команд модуля. Блок распознавателя сравнивает загруженные в него голосовые команды с поступающим звуковым сигналом.
- Номер ячейки – совпадает с номером записи. Память хранилища и память распознавателя разбита на ячейки. Одна ячейка может хранить одну запись (голосовую команду). Доступ к записям хранилища и записям распознавателя осуществляется по номерам ячеек.
- Обучение – процесс записи ваших голосовых команд в хранилище.
- Загрузка – копирование записанной голосовой команды из хранилища в распознаватель.
- Подпись – текстовый комментарий (до 10 символов) к голосовой команде записанной в хранилище.
- Группа – список содержащий 7 номеров ячеек хранилища. Поддерживаются, системные группы и пользовательские группы. Загрузка группы приводит к загрузке в распознаватель тех голосовых команд хранилища, номера которых указаны в группе.
Более подробно о группах читайте в разделе Группы.
Видео:
Спецификация:
- Точность распознавания речи: 99% (при идеальных условиях).
- Объем хранилища: до 80 голосовых команд длительностью не более 1,5 сек.
- Одновременное распознавание: до 7 голосовых команд.
- Напряжение питания: 4,5 … 5,5 В (постоянного тока).
- Потребляемый ток: до 40 мА.
- Цифровой Интерфейс: UART и GPIO уровень TTL 5В.
- Аналоговый интерфейс: разъем микрофона jack 3,5-мм моноканальный.
- Габариты платы: 31х50 мм.
Подключение:
- Колодка из 4 выводов (GND, VCC, RXD, TXD) используется для подключения модуля к аппаратной или программной шине UART Arduino.
- Колодка из 4 выводов (IN0, IN1, IN2, GND) может быть использована для загрузки требуемых групп голосовых команд из хранилища в распознаватель голосовых команд.
Более подробно о группах читайте в разделе Группы.
Все выводы IN-0. IN-2 внутрисхемно подтянуты до уровня Vcc.
По умолчанию, загрузка групп при помощи выводов IN-0. IN-2 отключена.
- Колодка из 8 выводов (OUT0-OUT6, GND) может быть использована для управления маломощными устройствами напрямую или мощными устройствами через реле, или силовые ключи.
Выходы OUT модуля, так же как и ячейки распознавателя, пронумерованы от 0 до 6. Опознание модулем голосовой команды приводит к соответствующей реакции выхода OUT модуля, номер которого совпадает с номером ячейки распознавателя содержащей опознанную голосовую команду.
По умолчанию выводы OUT реагируют на опознание голосовой команды отрицательным импульсом, но реакцию можно настроить так, что выводы будут менять, устанавливать, или сбрасывать логический уровень при каждом совпадении голосовой команды.
Питание:
Подробнее о модуле:
У модуля распознавания голоса - Voice Recognition Module V3.1 есть два вида памяти: память хранилища (где голосовые команды просто хранятся, даже после отключения питания) и память распознавателя (где голосовые команды участвуют в сравнении со звуком поступившем через микрофон).
Оба типа памяти состоят из ячеек, в одну ячейку записывается одна голосовая команда. Память хранилища голосовых команд состоит из 80 ячеек пронумерованных от 0 до 79, а память распознавателя голосовых команд состоит из 7 ячеек пронумерованных от 0 до 6. Значит модуль способен хранить до 80 голосовых команд, а одновременно сравнивать до 7 голосовых команд с поступающим звуковым сигналом.
Для работы модуля его необходимо обучить - записать столько голосовых команд в энергонезависимое хранилище, сколько требуется для Вашего проекта. В распознаватель, голосовые команды не записываются, а загружаются из памяти хранилища. Модуль позволяет указать номера ячеек хранилища, голосовые команды которых будут автоматически загружаться в распознаватель при подаче питания модуля.
Такая организации памяти позволяет разделить длинные голосовые команды (произношение которых занимает более 1,5 сек.) на две и более маленьких голосовых команд, которые будут подгружаться из хранилища в распознаватель по мере опознания модулем предыдущих частей длинной голосовой команды.
Пример:
- Предположим, мы желаем создать голосовое управление светом в коридоре, комнате и на кухне, а так же управление жалюзи в комнате и на кухне.
- Записываем в ячейки хранилища следующие голосовые команды: "свет", "жалюзи", "в коридоре", "в комнате" и "на кухне".
- Голосовые команды "свет" и "жалюзи" загружаем из хранилища в распознаватель изначально.
- При распознавании голосовой команды "свет", загружаем в распознаватель голосовые команды "в коридоре", "в комнате" и "на кухне".
- При распознавании голосовой команды "жалюзи", загружаем голосовые команды "в комнате" и "на кухне" (не загружая "в коридоре", если конечно у Вас там нет жалюзей).
- Таким образом Вы можете произнести "свет, в коридоре", "свет, в комнате", "свет, на кухне", "жалюзи, в комнате", "жалюзи, на кухне", а модуль сначала распознает первое слово ("свет" или "жалюзи"), а потом оставшуюся часть Вашей длинной голосовой команды.
- Осталось добавить в программу условие, что через определённое Вами время, после опознания команды "свет" или "жалюзи", они опять должны быть загружены в распознаватель. Так модуль перейдёт в состояние готовности принять следующую длинную голосовую команду, вне зависимости от того была ли корректно распознана предыдущая, или нет.
Еще одним плюсом наличия двух типов памяти модуля (хранилища и распознавателя), является возможность создания голосового управления несколькими людьми (до 7 человек) на одном модуле. Каждый человек записывает одинаковые слова голосовых команд в разные ячейки хранилища модуля, а так же записывает одно стартовое слово, например, "Окей дом". В таком случае в распознаватель изначально загружаем все голосовые команды "Окей дом" записанные разными людьми. Если кто то скажет "Окей дом, свет, в коридоре", то по номеру ячейки опознанной модулем голосовой команды "Окей дом", Вы сможете определить кем она была сказана и подгрузить в распознаватель следующие команды "свет" и "жалюзи" записанные именно этим человеком.
Управление модулем может осуществляться 2 способами:
Примеры:
В данном разделе содержатся примеры с использованием библиотеки VoiceRecognitionV3.
Пример обучения модуля:
В мониторе последовательного порта появится таблица со списком команд, которые Вы можете вводить:



Эти настройки означают следующее:
| Baud rate | (скорость передачи данных по шине UART) | 9600 бит/сек. |
| Output IO Mode | (режим работы выходов OUT) | Импульсный. |
| Pulse Width | (ширина импульса) | 10 миллисекунд. |
| Auto Load | (автозагрузка записей в распознаватель) | Отключена. |
| Group control by external IO | (управление группами при помощи входов IN 0-2) | Отключено. |



Это означает что Ваша голосовая команда записана в хранилище голосовых команд.

Вам нужно повторить голосовые команды пока запись не будет сохранена в хранилище.

Во время обучения можно смотреть не в монитор последовательного порта, а на два светодиода расположенные рядом с разъёмом микрофона: SYS_LED (желтый) и STATUS_LED (красный).
- Желтый светодиод быстро мигает – приготовьтесь произнести голосовую команду.
- Красный светодиод горит – произнесите голосовую команду.
- Желтый светодиод мигает – приготовьтесь повторно произнести голосовую команду.
- Красный светодиод горит – произнесите голосовую команду.
- Оба светодиода мигают одновременно – голосовые команды совпали и записаны.
- Желтый светодиод медленно мигает – сравнение звукового сигнала с записями распознавателя.
7. Попробуйте обучить модуль следующей голосовой команде.
Для того что бы модуль, после обучения (записи голосовых команд), мог опознать голосовую команду, её нужно загрузить из хранилища в распознаватель. В распознаватель модуля можно загрузить до 7 из 80 записанных команд.
Процесс загрузки не удаляет записи из памяти хранилища, а копирует записи из указанных ячеек хранилища голосовых команд в память распознавателя по порядку.


Пример управления светодиодом на плате Arduino:
В мониторе последовательного порта появится следующий текст:

Так как в предыдущем примере Вы уже записали 2 команды в распознаватель, то произнесите их. Произнесение первой команды приведёт к включению светодиода на плате Arduino, а произнесение второй к выключению. При этом в мониторе последовательного порта будут отображаться те же сведения, что и при опознании голосовых команд в предыдущем примере:
Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_multi_cmd: раскрывает принцип работы с группами голосовых команд. Голосовая команда записанная в 0 ячейку хранилища (RECORD 0) используется для переключения между двумя группами голосовых команд. Первая группа содержит номера ячеек хранилища RECORD 0,1,2,3,4,5,6, а вторая группа содержит номера ячеек хранилища RECORD 0,7,8,9,10,11,12. Перед запуском данного примера необходимо обучить модуль (записать) голосовые команды от 0 до 12.
Файл -> Примеры -> VoiceRecognitionV3 -> vr_sample_check_baud_rate: позволяет узнать установленную скорость передачи данных по шине UART. Может пригодиться если Вы забыли пользовательские настройки.
Группы:
Группы используются для удобства загрузки нескольких голосовых команд из хранилища в распознаватель. Каждая группа может включать до 7 номеров ячеек хранилища голосовых команд. Загрузка группы приводит к загрузке в распознаватель всех ячеек хранилища, номера которых указаны в группе. Группы можно загружать командами UART или при помощи входов модуля IN 0-2.
Существует два вида групп: системные группы и пользовательские группы.
Системные группы имеют жесткую структуру и включают в себя 7 номеров ячеек хранилища голосовых команд:
| № системной группы | № ячеек хранилища голосовых команд входящих в группу: |
|---|---|
| 00 | 00, 01, 02, 03, 04, 05, 06 |
| 01 | 07, 08, 09, 0A, 0B, 0C, 0D |
| 02 | 0E, 0F, 10, 11, 12, 13, 14 |
| 03 | 15, 16, 17, 18, 19, 1A, 1B |
| 04 | 1C, 1D, 1E, 1F, 20, 21, 22 |
| 05 | 23, 24, 25, 26, 27, 28, 29 |
| 06 | 2A, 2B, 2C, 2D, 2E, 2F, 30 |
| 07 | 31, 32, 33, 34, 35, 36, 37 |
| 08 | 38, 39, 3A, 3B, 3C, 3D, 3E |
| 09 | 3F, 40, 41, 42, 43, 44, 45 |
| 0A | 46, 47, 48, 49, 4A, 4B, 4C |
Пользовательские группы Вы можете создавать по своему усмотрению (Вы сами решаете какие ячейки хранилища голосовых команд будут входить в группу). Допускается создание до 8 пользовательских групп с номерами от 00 до 07. Каждая пользовательская группа может содержать до 7 голосовых команд хранилища.
Управлять группами можно, как с использованием методов библиотеки VoiceRecognitionV3, так и при помощи команды протокола VR3.

Человека всегда привлекала идея управлять машиной естественным языком. Возможно, это отчасти связано с желанием человека быть НАД машиной. Так сказать, чувствовать свое превосходство. Но основной посыл — это упрощение взаимодействия человека с искусственным интеллектом. Управление голосом в Linux с переменным успехом реализуется без малого уже четверть века. Давай разберемся в вопросе и попробуем сблизиться с нашей ОС настолько, насколько это только возможно.
Суть дела
Системы работы с человеческим голосом для Linux существуют давно, и их великое множество. Но не все они корректно обрабатывают русскую речь. Некоторые и вовсе заброшены разработчиками. В первой части нашего обзора мы поговорим непосредственно о системах распознавания речи и голосовых ассистентах, а во второй — рассмотрим конкретные примеры их использования на Linux-десктопе.
Следует различать собственно системы распознавания речи (перевод речи в текст или в команды), такие как, например, CMU Sphinx, Julius, а также приложения на основе этих двух движков, и голосовые ассистенты, ставшие популярными с развитием смартфонов и планшетов. Это, скорее, побочный продукт систем распознавания речи, дальнейшее их развитие и воплощение всех удачных идей распознавания голоса, применение их на практике. Для Linux-десктопов таких пока мало.
Надо понимать, что движок распознавания речи и интерфейс к нему — это разные вещи. Таков базовый принцип архитектуры Linux — разделение сложного механизма на более простые составные части. Самая сложная работа ложится на плечи движков. Обычно это скучная консольная программа, работающая незаметно для пользователя. Пользователь же взаимодействует в основном с программой-интерфейсом. Создать интерфейс несложно, поэтому основные усилия разработчики направляют именно на разработку открытых движков распознавания речи.
Что было раньше
Исторически сложилось так, что все системы работы с речью в Linux развивались не спеша и скачкообразно. Причина не в криворукости разработчиков, а в высоком уровне вхождения в среду разработки. Написание кода системы для работы с голосом требует высокой квалификации программиста. Поэтому, перед тем как начать разбираться с системами работы с речью в Linux, необходимо сделать небольшой экскурс в историю. Была когда-то в IBM такая чудесная операционная система — OS/2 Warp (Merlin). Вышла она в сентябре далекого уже 1996 года. Кроме того, что она обладала очевидными преимуществами перед всеми остальными операционками, OS/2 была укомплектована весьма продвинутой системой распознавания речи — IBM ViaVoice. Для того времени это было очень круто, учитывая, что ОС работала на системах с 486-м процессором с объемом ОЗУ от 8 Мбайт (!).
Как известно, OS/2 проиграла битву Windows, однако многие ее компоненты продолжили существовать независимо. Одним из таких компонентов стала та самая IBM ViaVoice, превратившаяся в самостоятельный продукт. Так как IBM всегда любила Linux, ViaVoice была портирована на эту ОС, что дало детищу Линуса Торвальдса самую передовую для своего времени систему распознавания речи.
К сожалению, судьба ViaVoice сложилась не так, как хотели бы линуксоиды. Сам движок распространялся бесплатно, но его исходники оставались закрытыми. В 2003 году IBM продала права на технологию канадо-американской компании Nuance. Nuance, разработавшая, пожалуй, самый успешный коммерческий продукт для распознавания речи — Dragon Naturally Speeking, здравствует и ныне. На этом бесславная история ViaVoice в Linux практически закончилась. За то короткое время, что ViaVoice была бесплатной и доступной линуксоидам, к ней разработали несколько интерфейсов, таких, например, как Xvoice. Однако проект давно заброшен и ныне практически неработоспособен.
OS/2 Warp — система, которую мы потеряли

Другие статьи в выпуске:
Что сегодня?
Сегодня все гораздо лучше. В последние годы, после открытия исходников Google Voice API, ситуация с развитием систем распознавания речи в Linux значительно улучшилась, выросло качество распознавания. Например, проект Linux Speech Recognition на основе Google Voice API показывает очень неплохие результаты для русского языка. Все движки работают примерно одинаково: сначала звук с микрофона устройства юзера попадает в систему распознавания, после чего либо голос обрабатывается на локальном устройстве, либо запись отправляется на удаленный сервер для дальнейшей обработки. Второй вариант больше подходит для смартфонов или планшетов. Собственно, именно так и работают коммерческие движки — Siri, Google Now и Cortana.
Из всего многообразия движков для работы с человеческим голосом можно выделить несколько активных на данный момент.
WARNING
CMU Sphinx
Большая часть разработки CMU Sphinx ведется в университете Карнеги — Меллона. В разное время над проектом работали и Массачусетский технологический институт, и покойная ныне корпорация Sun Microsystems. Исходники движка распространяются под лицензией BSD и доступны как для коммерческого, так и для некоммерческого использования. Sphinx — это не пользовательское приложение, а, скорее, набор инструментов, который можно применить в разработке приложений для конечных пользователей. Sphinx сейчас — это крупнейший проект по распознаванию речи. Он состоит из нескольких частей:
- Pocketsphinx — небольшая быстрая программа, обрабатывающая звук, акустические модели, грамматики и словари;
- библиотека Sphinxbase, необходимая для работы Pocketsphinx;
- Sphinx4 — собственно библиотека распознавания;
- Sphinxtrain — программа для обучения акустическим моделям (записям человеческого голоса).
Проект развивается медленно, но верно. И главное — его можно использовать на практике. Причем не только на ПК, но и на мобильных устройствах. К тому же движок очень хорошо работает с русской речью. При наличии прямых рук и ясной головы можно настроить распознавание русской речи с помощью Sphinx для управления домашней техникой или умным домом. По сути, можно обычную квартиру превратить в умный дом, чем мы и займемся во второй части этого обзора. Реализации Sphinx имеются для Android, iOS и даже Windows Phone. В отличие от облачного способа, когда работа по распознаванию речи ложится на плечи серверов Google ASR или Яндекс SpeechKit, Sphinx работает точнее, быстрее и дешевле. И полностью локально. При желании можно научить Sphinx русской языковой модели и грамматике пользовательских запросов. Да, придется немного потрудиться при установке. Равно как и настройка голосовых моделей и библиотек Sphinx — занятие не для новичков. Так как основа CMU Sphinx — библиотека Sphinx4 — написана на Java, можно включать ее код в свои приложения для распознавания речи. Конкретные примеры использования будут описаны во второй части нашего обзора.
VoxForge
Особо выделим понятие речевого корпуса. Речевой корпус — это структурированное множество речевых фрагментов, которое обеспечено программными средствами доступа к отдельным элементам корпуса. Иными словами — это набор человеческих голосов на разных языках. Без речевого корпуса невозможна работа ни одной системы распознавания речи. В одиночку или даже небольшим коллективом создать качественный открытый речевой корпус сложно, поэтому сбором записей человеческих голосов занимается специальный проект — VoxForge.
Любой, у кого есть доступ к интернету, может поучаствовать в создании речевого корпуса, просто записав и отправив фрагмент речи. Это можно сделать даже по телефону, но удобней воспользоваться сайтом. Конечно, кроме собственно аудиозаписи, речевой корпус должен включать в себя дополнительную информацию, такую как фонетическая транскрипция. Без этого запись речи бессмысленна для системы распознавания.

VoxForge — стартовый портал для тех, кто хочет внести свой вклад в разработку открытых систем распознавания речи
HTK, Julius и Simon
HTK — Hidden Markov Model Toolkit — это инструментарий для исследования и разработки средств распознавания речи с использованием скрытых марковских моделей, разрабатывается в Кембриджском университете под патронажем Microsoft (Microsoft когда-то выкупила этот код у коммерческого предприятия Entropic Cambridge Research Laboratory Ltd, а затем вернула его Кембриджу вместе с ограничивающей лицензией). Исходники проекта доступны всем желающим, но использование кода HTK в продуктах, предназначенных для конечных пользователей, запрещено лицензией.
Однако это не означает, что HTK бесполезен для Linux-разработчиков: его можно использовать как вспомогательный инструмент при разработке открытых (и коммерческих) средств распознавания речи, что и делают разработчики открытого движка Julius, который разрабатывается в Японии. Julius лучше всего работает с японским языком. Великий и могучий тоже не обделен, ведь в качестве голосовой базы данных используется все тот же VoxForge.
Возможности HTK и Julius активно используются в приложении Simon. Проект запущен еще в 2007 году и до сих пор пребывает в перманентной бете. Движок использует библиотеки KDE, CMU Sphinx и/или Julius и акустические модели проекта VoxForge. Есть версии для Windows и Linux. Разработка Simon ведется в рамках проекта KDE в составе рабочей группы KDE Accessibility. Последняя версия Simon — 0.4.1 — вполне себе юзабельное приложение для бета-версии.
В Simon включены инструменты для создания голосовых и акустических моделей, распознавания речи и организации управления голосом. Кроме управления десктопом, Simon может использоваться для аутентификации голосом, голосового управления роботами и устройствами. Главный приоритет разработчики отдают предоставлению средств для работы на компьютере людей с ограниченными возможностями.
Помимо описанных выше, существуют и другие проекты по распознаванию речи, такие как Kaldi, наработки которого используются сейчас в других проектах. Однако в рамках данного обзора мы не будем их касаться. И дело не в том, что они не заслуживают внимания, а в том, что большинство из них скорее мертвы, чем живы. Более-менее активно развиваются лишь Sphinx и его производные, Simon, HTK и Julius. Смотри подробности на сайте Саймона.

Саймон говорит и выглядит довольно прилично
Лучшие друзья человека
Голосовые ассистенты частично воплощают мечту создателей всех систем для распознавания речи. Конечно, еще далеко до возможности полноценного общения пользователя и искусственного интеллекта машины, но уже сегодня можно искать информацию в интернете, запускать приложения, диктовать текст, прокладывать маршруты, управлять кофеваркой и холодильником, переписываться с друзьями в соцсетях и прочая, и прочая.
Условно все голосовые ассистенты можно разделить на две группы: те, которые так или иначе используют Google Voice API, и остальные. Остальные — это, например, ставшая уже знаменитой Cortana от Microsoft, которая, по слухам, скоро станет доступна для Android и iOS, что теоретически означает возможность портирования ее и на чистый Linux-десктоп. Или Siri — детище Apple, которое яблочная компания оберегает от любого стороннего использования как зеницу ока.
После открытия компанией Google своего API для работы с голосом персональные ассистенты для Linux начали появляться один за другим.

Вот правда. Именно так
Linux Speech Recognition
В начале 2013 года, после закрытого бета-тестирования был переведен в разряд свободных проект по созданию системы распознавания речевых команд на базе Google Voice API. Система позволяет через управление голосом запускать программы, выполнять операции с файлами, открывать сайты, находить ответы на произвольные вопросы, создавать электронные письма, диктовать текст документов, запускать приложения и так далее.
Вначале проект развивался независимым энтузиастом для организации речевого управления Ubuntu, но в текущем виде его код не привязан к особенностям данной системы и может быть использован в любых дистрибутивах. Код проекта написан на языке Python и открыт под лицензией GPLv3. Распознавание речи реализовано через обращение к Google Voice API, который демонстрирует достаточно неплохие результаты для русского языка. Вся дополнительная инфа тут.

Можно установить в Ubuntu и пользоваться. Удобно, быстро
Hound
Этот голосовой ассистент, хоть и создан для Android, а не для Linux, все же заслуживает упоминания в нашем обзоре. Дело в том, что в тестах на распознавание речи этот помощник обгоняет и Siri, и Google Now, справляясь с поставленными задачами значительно эффективнее и быстрее. Самое ценное в нем то, что он воспринимает фразы именно так, как пользователь их произносит, то есть тебе не придется как-то специально формулировать свои вопросы, чтобы ассистент их понял.
Пока проект находится на стадии беты и доступен только по инвайтам и только владельцам Android-девайсов, находящимся на территории США. Разработчики обещают выпустить версии для iOS после окончания бета-тестирования. Будет ли версия для десктопов, пока неизвестно. Проект развивается уже девять лет и, по словам разработчиков, достаточно стабилен для повседневного использования. Русского языка, вестимо, нет.
Hound работает почти так же, как и Google Now, только лучше
Betty
К сожалению, Betty пока не понимает русскую речь, да и набор команд у нее довольно ограничен, но разработка идет уже больше двух лет, и довольно активно, так что логично ожидать в будущем появление большего количества доступных команд.
Вот часть команд, которые Betty версии 0.1.8 понимает уже сейчас:
- count (подсчет, например количества символов и слов в файле);
- config (смена имени пользователя);
- datetime (вывод текущего времени и даты);
- поиск (внутри файлов);
- web (запросы, скачивание файлов, поиск информации в Сети и прочее);
- операции с папками и файлами (архивирование/разархивирование файлов, вычисление размера файлов, изменение прав доступа и другие);
- пользовательские команды (вывод имени пользователя, IP-адреса, имена залогинившихся в машину пользователей и так далее).
Список команд постоянно увеличивается. Над проектом работает уже семнадцать разработчиков из пяти стран. Полный список команд Betty ты можешь найти на странице проекта на GitHub.

Betty создана гиками для гиков. И работает, как гик
Sirius
Жемчужиной среди остальных можно назвать Sirius — новое и весьма амбициозное решение от группы разработчиков Clarity Lab из университета Мичигана. Несмотря на сходство названия с Siri, проект не имеет с ней ничего общего. Sirius уже может гораздо больше, чем его аналоги. Разработку Sirius взяли под свое крыло Google, DARPA, ARM, министерство обороны США и Американский национальный научный фонд. Исходники распространяются под лицензией BSD. Система основана на нескольких свободных проектах по распознаванию речи, таких как Sphinx, Kaldi, Protobuf, Speeded Up Robust Features (SURF, работает на базе OpenCV). Таким образом, в Sirius воплотилось все то лучшее, что было разработано в сфере распознавания речи за последние 35 лет.

Один из создателей Sirius Джейсон Марс уверен в будущем проекта
Заключение
С появлением Windows Phone Cortana, персонального помощника, активируемого речью (равно как и аналога от фруктовой компании, о котором нельзя упоминать всуе), приложения с поддержкой речи стали занимать все более значимое место в разработке ПО. В этой статье я покажу, как начать работу с распознаванием и синтезом речи в консольных Windows-приложениях, приложениях Windows Forms и Windows Presentation Foundation (WPF).
.jpg)
Рис. 1. Распознавание и синтез речи в консольном приложении
.jpg)
Рис. 2. Распознавание речи в приложении Windows Forms
Пользователь попросил приложение сложит один и два, затем два и три. Приложение распознало произнесенные команды и дало ответы голосовым способом. Позднее я опишу более полезные способы применения распознавания речи.
Использовать объект синтезатора довольно просто.
Добавление поддержки распознавания речи в консольное приложение
Далее я добавил ссылку на файл Microsoft.Speech.dll, который находится в C:\ProgramFiles (x86)\Microsoft SDKs\Speech\v11.0\Assembly. Эта DLL отсутствовала на моем компьютере, и мне пришлось скачивать ее. Установка файлов, необходимых для добавления распознавания и синтеза речи в приложение, не столь уж и тривиальна. Я подробно объясню процесс установки в следующем разделе, а пока допустим, что Microsoft.Speech.dll есть в вашей системе.
Добавив ссылку на речевую DLL, я удалил из верхней части кода все выражения using, кроме указывавшего на пространство имен System верхнего уровня. Потом я добавил выражения using для пространств имен Microsoft.Speech.Recognition, Microsoft.Speech.Synthesis и System.Globalization. Первые два пространства имен сопоставлены с речевой DLL. Заметьте: существуют и такие пространства имен, как System.Speech.Recognition и System.Speech.Synthesis, что может сбить с толку. Вскоре я поясню разницу между ними. Пространство имен Globalization было доступно по умолчанию и не требовало добавления новой ссылки в проект.
Весь исходный код демонстрационного консольного приложения приведен на рис. 3, а также доступен в пакете исходного кода, сопутствующем этой статье. Я убрал всю стандартную обработку ошибок, чтобы по возможности не затуманивать главные идеи.
Рис. 3. Исходный код демонстрационного консольного приложения
После выражений using демонстрационный код начинается так:
Объект SpeechSynthesizer на уровне класса дает возможность приложению синтезировать речь. Объект SpeechRecognitionEngine позволяет приложению прослушивать и распознавать произносимые слова или фразы. Булева переменная done определяет, когда завершается приложение в целом. Булева переменная speechOn управляет тем, слушает ли приложение какие-то команды, кроме команды на выход из программы.
Здесь идея в том, что консольное приложение не принимает набираемый с клавиатуры ввод, поэтому оно всегда слушает команды. Однако, если speechOn равна false, распознается и выполняется только команда на выход из программы; прочие команды распознаются, но игнорируются.
Метод Main начинается так:
Экземпляр объекта SpeechSynthesizer был создан при его объявлении. Использовать объект синтезатора довольно просто. Метод SetOutputToDefaultAudioDevice отправляет вывод на динамики, подключенные к вашему компьютеру (вывод можно отправлять и в файл). Метод Speak принимает строку, а затем произносит ее. Вот так все несложно.
Распознавание речи гораздо сложнее ее синтеза. Метод Main продолжает созданием объекта распознавателя:
Сначала в объекте CultureInfo указывается распознаваемый язык, в данном случае United States English. Объект CultureInfo находится в пространстве имен Globalization, на которое мы сослались с помощью выражения using. Затем после вызова конструктора SpeechRecognitionEngine голосовой ввод назначается аудиоустройству по умолчанию — чаще всего микрофону. Заметьте, что в большинстве лэптопов есть встроенный микрофон, но на настольных компьютерах потребуется внешний микрофон (в наши дни он часто комбинируется с наушниками).
Далее демонстрационная программа настраивает возможность распознавания команд для сложения двух чисел:
В демонстрационной программе я ограничиваю для сложения от 1 до 4 и добавляю их как строки в набор Choices. Более эффективный подход:
Я представляю вам менее эффективный подход к созданию набора Choices по двум причинам. Во-первых, добавление одной строки единовременно было единственным подходом, который я видел в других примерах с распознаванием речи. Во-вторых, вы могли подумать, что добавление одной строки единовременно вообще не должно работать; Visual Studio IntelliSense в реальном времени показывает, что одна из перегрузок Add принимает параметр типа params string[] phrases. Если вы не заметили ключевое слово params, то, возможно, сочли, что метод Add принимает только массивы строк, а одну строку — нет. Но это не так: он принимает и то, и другое. Я советую передавать массив.
Создание набора Choices из последовательных чисел в какой-то мере является особым случаем и дает возможность использовать программный подход наподобие:
После создания Choices для заполнения слотов GrammarBuilder демонстрационная программа создает GrammarBuilder, а затем управляющий Grammar:
Похожий шаблон демонстрационная программа использует при создании Grammar для команд, относящихся к старту и остановке:
Создав все объекты Grammar, вы помещаете их в распознаватель речи, и распознавание речи активируется:
Аргумент RecognizeMode.Multiple необходим, когда у вас более одной грамматики, что будет во всех программах, кроме самых простейших. Метод Main завершается следующим образом:
Странно выглядящий пустой цикл while позволяет сохранить работающей оболочку консольного приложения. Цикл будет завершен, когда булева переменная done уровня класса будет установлена в true обработчиком событий распознавания речи.
Обработка распознаваемой речи
Код обработки событий, связанных с распознаванием речи, начинается так:
Распознанный текст хранится в свойстве Result.Text объекта SpeechRecognizedEventArgs. Кроме того, можно использовать набор Result.Words. Свойство Result.Confidence хранит значение от 0.0 до 1.0, которое является примерной оценкой того, насколько произнесенный текст соответствует любой из грамматик, связанных с распознавателем. Демонстрационная программа инструктирует обработчик событий игнорировать текст с низкой достоверностью (low confidence) распознанного текста.
Значения Confidence сильно зависят от сложности ваших грамматик, качества микрофона и других факторов. Например, если демонстрационной программе нужно распознавать лишь числа от 1 до 4, то значения достоверности на моем компьютере обычно находятся на уровне 0.75. Но, если грамматика должна распознавать числа от 1 до 100, значения достоверности падают приблизительно до 0.25. Если в двух словах, то обычно вы должны экспериментировать со значениями достоверности, чтобы добиться хороших результатов распознавания речи.
Далее обработчик событий распознавателя речи включает и отключает распознавание:
Хотя, возможно, это не совсем очевидно поначалу, эта логика должна иметь смысл, если вдуматься в нее. Затем обрабатывается секретная команда выхода:
Далее обрабатываются команды сложения двух чисел, и обработчик событий, класс Program и пространство имен заканчиваются следующим кодом:
Установка библиотек
Объяснение демонстрационной программы подразумевает, что все необходимые речевые библиотеки установлены на вашем компьютере. Чтобы создавать и запускать демонстрационные программы, нужно установить четыре пакета: SDK (обеспечивает возможность создания демонстраций в Visual Studio), исполняющую среду (выполняет демонстрации после их создания), распознаваемый и синтезируемый (произносимый программой) языки.
.jpg)
Рис. 4. Основная страница установки SDK в Microsoft Download Center
.jpg)
Рис. 5. Установка Speech SDK
Далее вы должны установить исполняющую среду. Найдя основную страницу и щелкнув кнопку Next, вы увидите варианты, показанные на рис. 6.
.jpg)
Рис. 6. Установка исполняющей среды
Крайне важно выбрать ту же версию платформы (в демонстрации — 11) и разрядность (32 [x86] или 64 [x64]), что и у SDK. И вновь я настоятельно советую 32-разрядную версию, даже если вы работаете в 64-разрядной системе.
.jpg)
Рис. 7. Установка распознаваемого языка
.jpg)
Рис. 8. Установка голоса и языка синтеза
Любопытно, что, хотя язык распознавания речи и голос/язык синтеза речи на самом деле являются совершенно разными вещами, оба пакета являются вариантами на одной странице скачивания. Download Center UI позволяет отметить как язык распознавания, так и язык синтеза, но попытка одновременной их установки оказалась для меня катастрофичной, поэтому я рекомендую устанавливать их по отдельности.
Сравнение Microsoft.Speech с System.Speech
Если вы новичок в распознавании и синтезе речи для Windows-приложений, вы можете легко запутаться в документации, потому что существует несколько речевых платформ. В частности, помимо библиотеки Microsoft.Speech.dll, используемой демонстрационными программами в этой статье, есть библиотека System.Speech.dll, являющаяся частью операционной системы Windows. Эти две библиотеки похожи в том смысле, что их API почти, но не полностью идентичны. Поэтому, если вы отыскиваете примеры обработки речи в Интернете и видите фрагменты кода, а не полные программы, то совершенно не очевидно, относится данный пример к System.Speech или Microsoft.Speech.
Хотя обе библиотеки имеют общую основную кодовую базу и похожие API, они определенно разные. Неокторые ключевые различия суммированы в табл. 1.
Табл. 1. Основные различия между Microsoft.Speech и System.Speech
System.Speech DLL — часть ОС, поэтому она установлена в каждой системе Windows. Microsoft.Speech DLL (и связанные с ней исполняющая среда и языки) нужно скачивать и устанавливать в систему. Распознавание с применением System.Speech обычно требует обучения под конкретного пользователя, когда пользователь начитывает какой-то текст, а система учится понимать произношение, свойственное этому пользователю. Распознавание с применением Microsoft.Speech работает сразу для любого пользователя. System.Speech может распознавать практически любые слова (это называет свободной диктовкой). Microsoft.Speech будет распознавать лишь те слова и фразы, которые имеются в объекте Grammar, определенном в программе.
Добавление поддержки распознавания речи к приложению Windows Forms
После загрузки кода шаблона в редактор я добавил ссылку на файл Microsoft.Speech.dll в окне Solution Explorer — так же, как я сделал это в консольной программе. В верхней части исходного кода я удалил ненужные выражения using, оставив только ссылки на пространства имен System, Data, Drawing и Forms. Затем добавил два выражения using для пространств имен Microsoft.Speech.Recognition и System.Globalization.
Демонстрация на основе Windows Forms не использует синтез речи, поэтому я не ссылаюсь на библиотеку Microsoft.Speech.Synthesis. Добавление синтеза речи в приложение Windows Forms осуществляется точно так же, как и в консольном приложении.
В Visual Studio в режиме проектирования я перетащил на Form элементы управления TextBox, CheckBox и ListBox. Дважды щелкнул CheckBox, и Visual Studio автоматически создал скелет метода-обработчика событий CheckChanged.
Вспомните, что демонстрационная консольная программа сразу же начинала прослушивать произносимые команды и продолжала делать это вплоть до своего завершения. Этот подход можно применить и в приложении Windows Forms, но вместо него я решил дать возможность пользователю включать и выключать распознавание речи с помощью элемента управления CheckBox (т. е. с помощью флажка).
Исходный код в файле Form1.cs демонстрационной программы, где определен частичный класс, представлен на рис. 9. Объект механизма распознавания речи объявляется и создается как член Form. В конструкторе Form я подключаю обработчик событий SpeechRecognized, а затем создаю и загружаю два объекта Grammars:
Рис. 9. Добавление поддержки распознавания речи в Windows Forms
Я мог бы создать два объекта Grammar напрямую, как в консольной программе, но вместо этого, что сделать код чуточку понятнее, определил два вспомогательных метода (GetHelloGoodbyeGrammar и GetTextBox1TextGrammar), которые и выполняют эту работу.
Заметьте, что конструктор Form не вызывает метод RecognizeAsync, а значит, распознавание речи не будет активно сразу после запуска приложения.
Вспомогательный метод GetHelloGoodbyeGrammar следует тому же шаблону, описанному ранее в этой статье:
Аналогично вспомогательный метод, который создает объект Grammar для присваивания текста элементу управления TextBox в Windows Forms, не несет никаких сюрпризов:
Обработчик событий для CheckBox определен так:
Объект механизма распознавания речи, sre (speech recognition engine), всегда существует в течение всего срока жизни приложения Windows Forms. Этот объект активируется и деактивируется вызовами методов RecognizeAsync и RecognizeAsyncCancel, когда пользователь соответственно переключает CheckBox.
Определение обработчика событий SpeechRecognized начинается с:
Помимо более-менее постоянно используемых свойств Result.Text и Result.Confidence, объект Result имеет несколько других полезных, но более сложных свойств, которые вы, возможно, захотите исследовать; например, Homophones и ReplacementWordUnits. Кроме того, механизм распознавания речи предоставляет несколько полезных событий вроде SpeechHypothesized.
Обработчик событий завершается таким кодом:
Распознанный текст выводится в ListBox, используя делегат MethodInvoker. Поскольку распознаватель речи выполняется в другом потоке, отличном от UI-потока Windows Forms, попытка прямого доступа к ListBox наподобие:
закончится неудачей и приведет к генерации исключения. Альтернатива делегату MethodInvoker — применение делегата Action:
Теоретически, в этой ситуации использование делегата MethodInvoker чуть эффективнее, чем Action, так как MethodInvoker является частью пространства имен Windows.Forms, а значит, специфичен для приложений Windows Forms. Делегат Action более универсален. Этот пример показывает, что вы можете полностью манипулировать приложением Windows Forms через механизм распознавания речи — это невероятно мощная и полезная возможность.
Заключение
В случае консольных программ вы можете создавать интересные взаимные диалоги, где пользователь задает вопрос, а программа отвечает, в результате чего вы, по сути, получаете среду, подобную Cortana. Вы должны соблюдать некоторую осторожность, потому что, когда речь исходит из динамиков вашего компьютера, она будет подхвачена микрофоном и может быть распознана снова. Я сам попадал в довольно забавные ситуации, где задавал вопрос, приложение распознавало его и отвечало, но произносимый ответ инициировал следующее событие распознавания, и в итоге я получал смешной бесконечный речевой цикл.
Выражаю благодарность за рецензирование статьи экспертам Microsoft Research Робу Грюну (Rob Gruen), Марку Маррону (Mark Marron) и Кертису фон Ве (Curtis von Veh).
Читайте также: