
Как сделать электронный кластер
Добавил пользователь Алексей Ф. Обновлено: 04.10.2024
Настраиваем отказоустойчивый кластер Hyper-V на базе Windows Server 2012
Уже на этапе планирования будущей виртуальной инфраструктуры следует задуматься об обеспечении высокой доступности ваших виртуальных машин. Если в обычной ситуации временная недоступность одного из серверов еще может быть приемлема, то в случае остановки хоста Hyper-V недоступной окажется значительная часть инфраструктуры. В связи с чем резко вырастает сложность администрирования - остановить или перезагрузить хост в рабочее время практически невозможно, а в случае отказа оборудования или программного сбоя получим ЧП уровня предприятия.
Все это способно серьезно охладить энтузиазм по поводу преимуществ виртуализации, но выход есть и заключается он в создании кластера высокой доступности. Мы уже упоминали о том, что термин "отказоустойчивый" не совсем корректен и поэтому сегодня все чаще используется другая характеристика, более точно отражающая положение дел - "высокодоступный".
Для создания полноценной отказоустойчивой системы требуется исключить любые точки отказа, что в большинстве случаев требует серьезных финансовых вложений. В тоже время большинство ситуаций допускает наличие некоторых точек отказа, если устранение последствий их отказа обойдется дешевле, чем вложение в инфраструктуру. Например, можно отказаться от недешевого отказоустойчивого хранилища в пользу двух недорогих серверов с достаточным числом корзин, один из которых настроен на холодный резерв, в случае отказа первого сервера просто переставляем диски и включаем второй.
В данном материале мы будем рассматривать наиболее простую конфигурацию отказоустойчивого кластера, состоящего из двух узлов (нод) SRV12R2-NODE1 и SRV12R2-NODE2, каждый из которых работает под управлением Windows Server 2012 R2. Обязательным условием для этих серверов является применение процессоров одного производителя, только Intel или только AMD, в противном случае миграция виртуальных машин между узлами будет невозможна. Каждый узел должен быть подключен к двум сетям: сети предприятия LAN и сети хранения данных SAN.
Вторым обязательным условием для создания кластера является наличие развернутой Active Directory, в нашей схеме она представлена контроллером домена SRV12R2-DC1.
Хранилище выполнено по технологии iSCSI и может быть реализовано на любой подходящей платформе, в данном случае это еще один сервер на Windows Server 2012 R2 - SRV12R2-STOR. Сервер хранилища может быть подключен к сети предприятия и являться членом домена, но это необязательное условие. Пропускная способность сети хранения данных должна быть не ниже 1 Гбит/с.
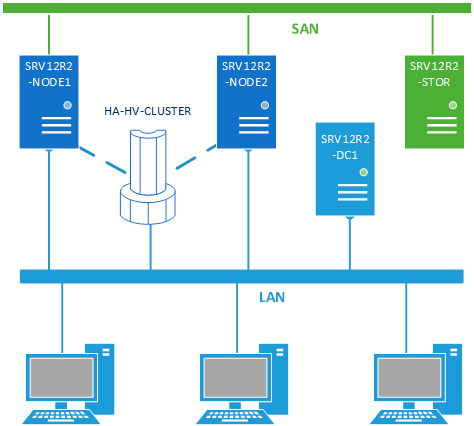
Будем считать, что на оба узла уже установлена операционная система, они введены в домен и сетевые подключения настроены. Откроем Мастер добавления ролей и компонентов и добавим роль Hyper-V.
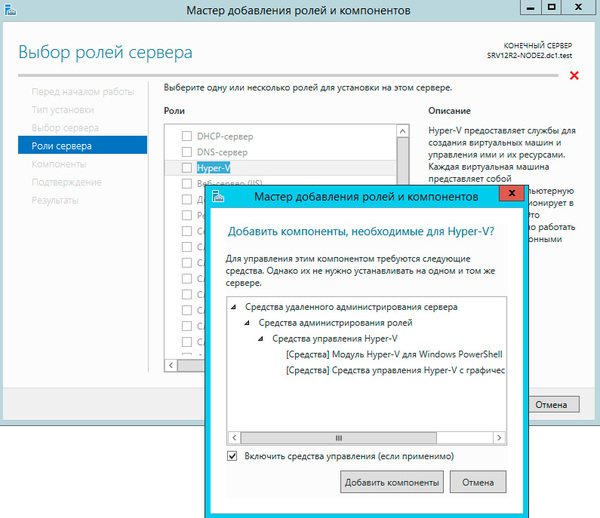
Следующим шагом добавим компоненту Отказоустойчивая кластеризация.
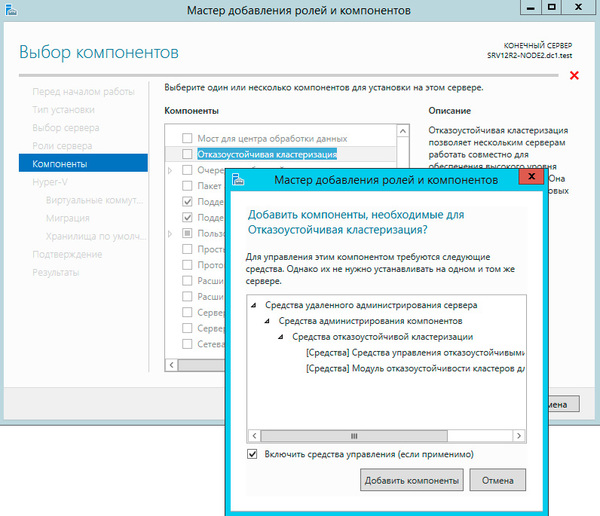
На странице настройки виртуальных коммутаторов выбираем тот сетевой адаптер, который подключен к сети предприятия.

Миграцию виртуальных машин оставляем выключенной.
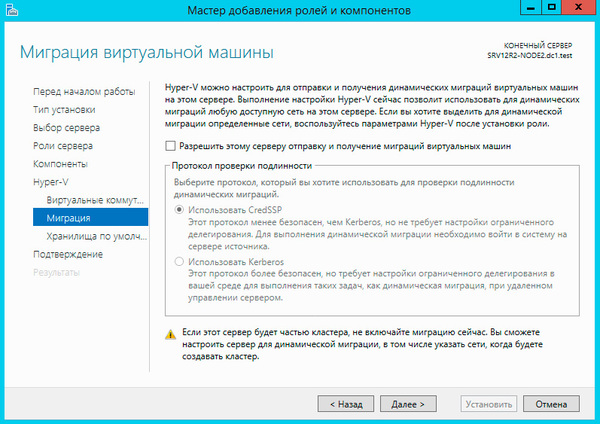
Остальные параметры оставляем без изменения. Установка роли Hyper-V потребует перезагрузку, после чего аналогичным образом настраиваем второй узел.
Затем перейдем к серверу хранилища, как настроить iSCSI-хранилище на базе Windows Server 2012 мы рассказывали в данной статье, но это непринципиально, вы можете использовать любой сервер цели iSCSI. Для нормальной работы кластера нам потребуется создать минимум два виртуальных диска: диск свидетеля кворума и диск для хранения виртуальных машин. Диск-свидетель - это служебный ресурс кластера, в рамках данной статьи мы не будем касаться его роли и механизма работы, для него достаточно выделить минимальный размер, в нашем случае 1ГБ.
Создайте новую цель iSCSI и разрешите доступ к ней двум инициаторам, в качестве которых будут выступать узлы кластера.
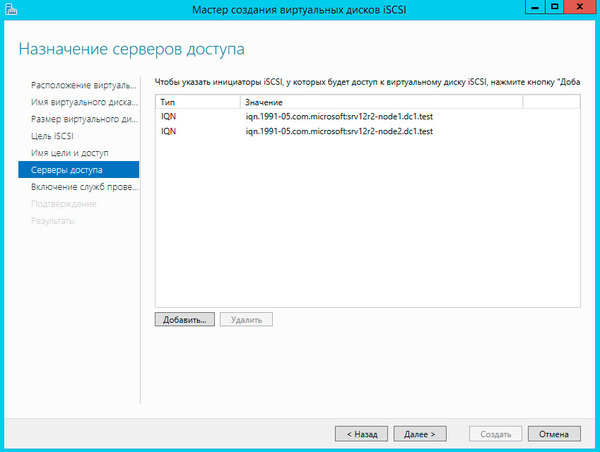
И сопоставьте данной цели созданные виртуальные диски.
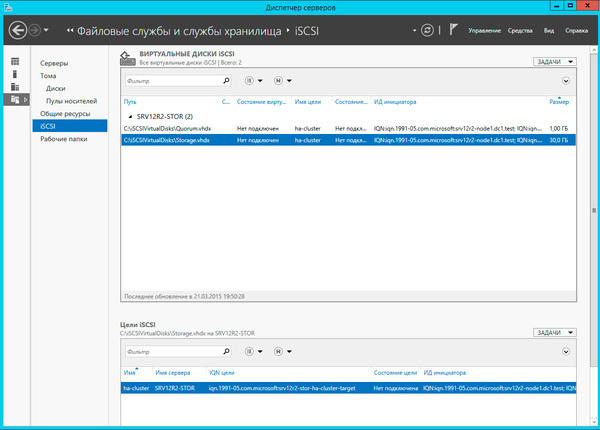
Настроив хранилище, вернемся на один из узлов и подключим диски из хранилища. Помните, что если сервер хранилища подключен также к локальной сети, то при подключении к цели iSCSI укажите для доступа сеть хранения данных.
Подключенные диски инициализируем и форматируем.
После чего откроем Диспетчер Hyper-V и перейдем к настройке виртуальных коммутаторов. Их название на обоих узлах должно полностью совпадать.
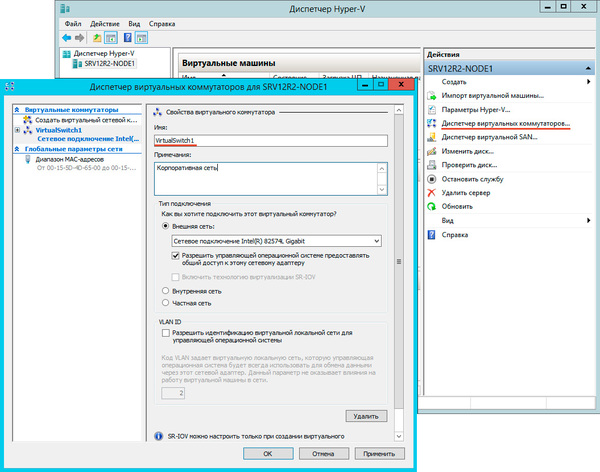
Теперь у нас все готово к созданию кластера. Запустим оснастку Диспетчер отказоустойчивых кластеров и выберем действие Проверить конфигурацию.
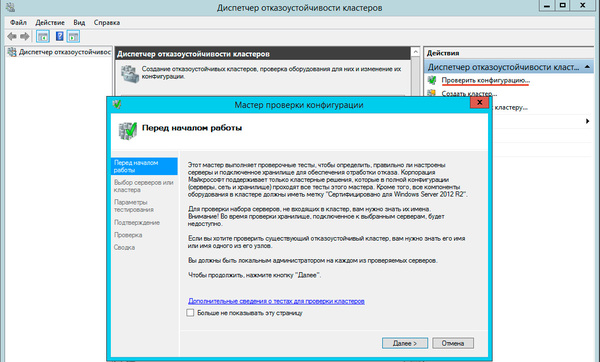
В настройках мастера добавим настроенные нами узлы и выберем выполнение всех тестов.
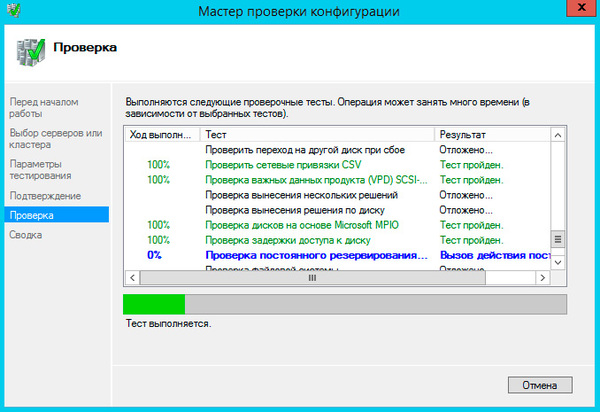
Если существенных ошибок не обнаружено работа мастера завершится и он предложит вам создать на выбранных узлах кластер.
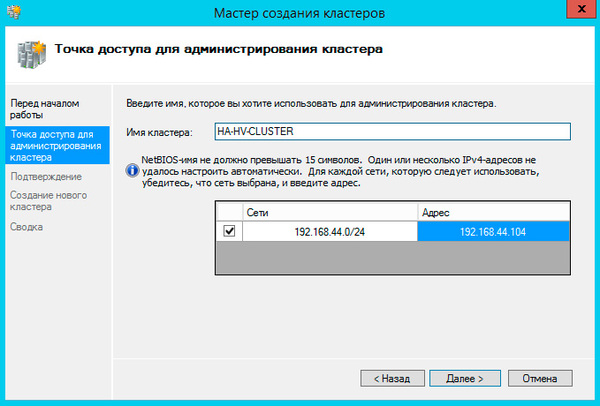
При создании кластера для него создается виртуальный объект, обладающий сетевым именем и адресом. Укажем их в открывшемся Мастере создания кластеров.
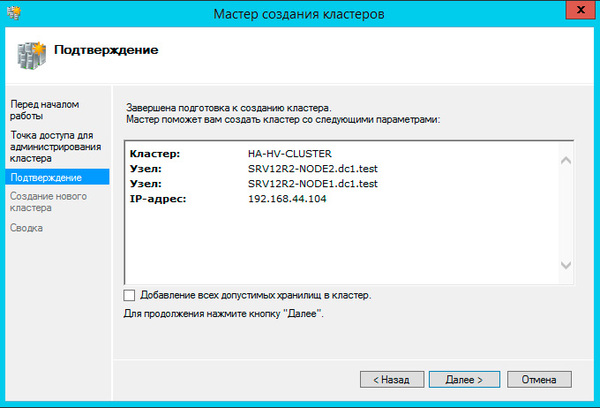
На следующем шаге советуем снять флажок Добавление всех допустимых хранилищ в кластер, так как мастер не всегда правильно назначает роли дискам и все равно придется проверять и, при необходимости исправлять, вручную.
Больше вопросов не последует и мастер сообщит нам, что кластер создан, выдав при этом предупреждение об отсутствии диска-свидетеля.
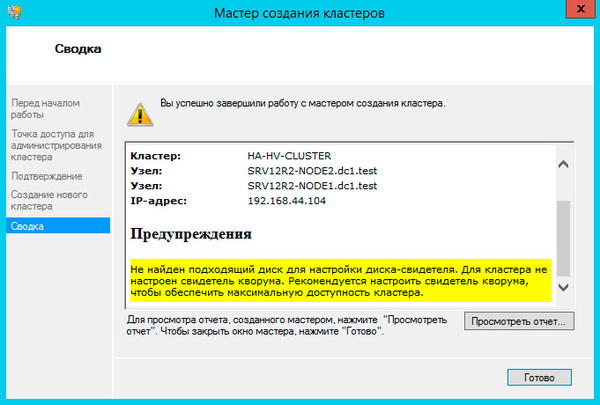
Закроем мастер и развернем дерево слева до уровня Хранилище - Диски, в доступных действиях справа выберем Добавить диск и укажем подключаемые диски в открывшемся окне, в нашем случае их два.
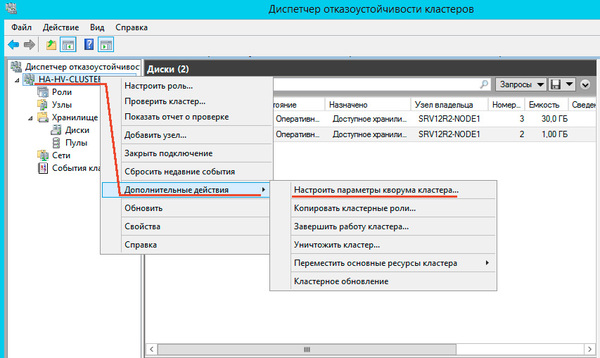
Далее последовательно выбираем: Выбрать свидетель кворума - Настроить диск-свидетель и указываем созданный для этих целей диск.
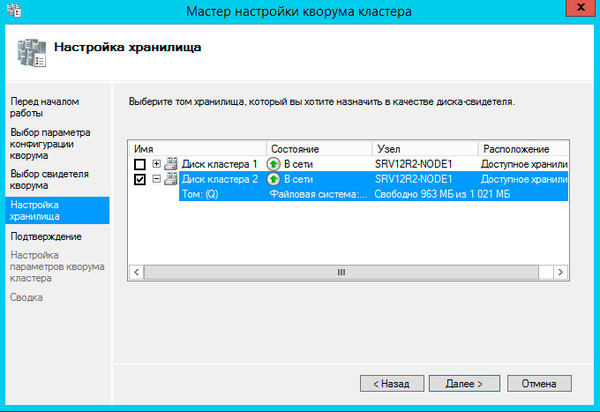
Теперь настроим диск хранилища, с ним все гораздо проще, просто щелкаем на диске правой кнопкой и указываем: Добавить в общие хранилища кластера.
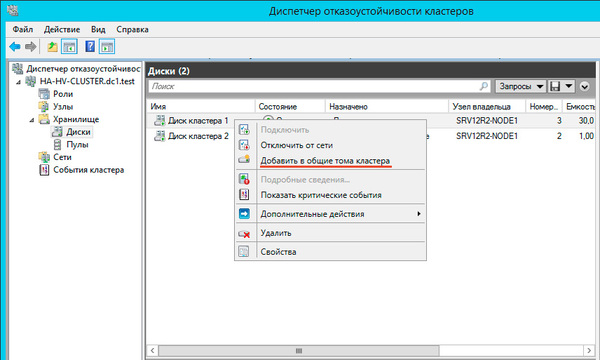
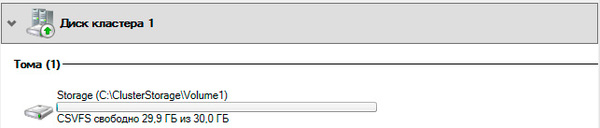
Для того, чтобы диск мог использоваться сразу несколькими участниками кластера на нем создается CSVFS - реализуемая поверх NTFS кластерная файловая система, впервые появившаяся в Windows Server 2008 R2 и позволяющая использовать такие функции как Динамическая (Живая) миграция, т.е. передачу виртуальной машины между узлами кластера без остановки ее работы.
Общие хранилища становятся доступны на всех узлах кластера в расположении C:\ClusterStorage\VolumeN. Обратите внимание, что это не просто папки на системном диске, а точки монтирования общих томов кластера.
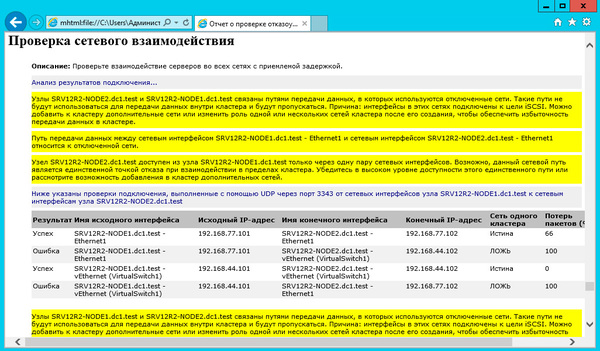
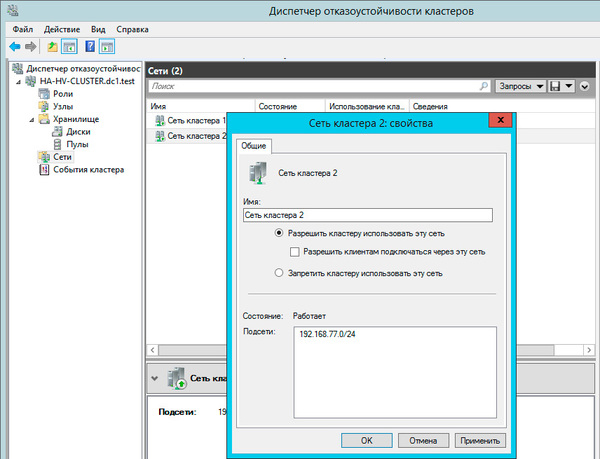
Закончив с дисками, перейдем к настройкам сети, для этого перейдем в раздел Сети. Для сети, которая подключена к сети предприятия указываем Разрешить кластеру использовать эту сеть и Разрешить клиентам подключаться через эту сеть. Для сети хранения данных просто оставим Разрешить кластеру использовать эту сеть, таким образом обеспечив необходимую избыточность сетевых соединений.
На этом настройка кластера закончена. Для работы с кластеризованными виртуальными машинами следует использовать Диспетчер отказоустойчивости кластеров, а не Диспетчер Hyper-V, который предназначен для управления виртуалками расположенными локально.
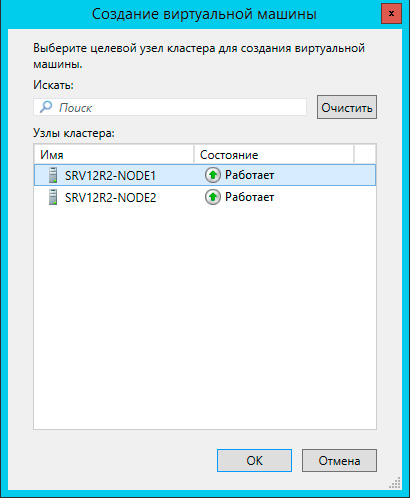
Чтобы создать виртуальную машину перейдите в раздел Роли в меню правой кнопки мыши выберите Виртуальные машины - Создать виртуальную машину, это же можно сделать и через панель Действия справа.

Прежде всего выберите узел, на котором будет создана виртуальная машина. Каждая виртуалка работает на определенном узле кластера, мигрируя на другие узлы при остановке или отказе своей ноды.
После выбора узла откроется стандартный Мастер создания виртуальной машины, работа с ним не представляет сложности, поэтому остановимся только на значимых моментах. В качестве расположения виртуальной машины обязательно укажите один из общих томов кластера C:\ClusterStorage\VolumeN.
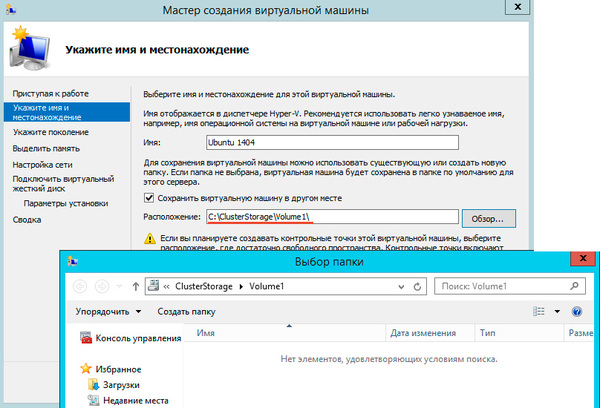
Здесь же должен располагаться и виртуальный жесткий диск, вы также можете использовать уже существующие виртуальные жесткие диски, предварительно скопировав их в общее хранилище.
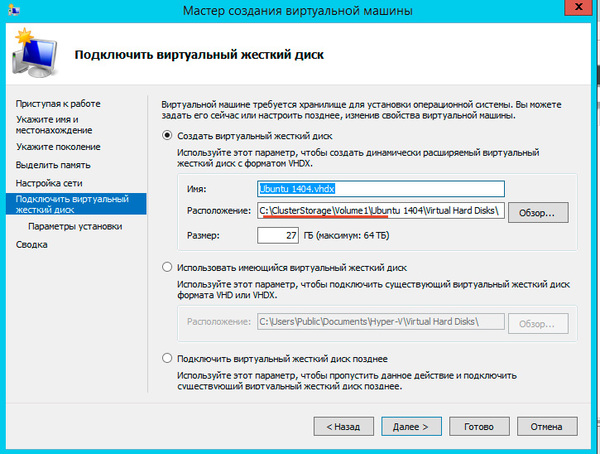
После создания виртуальной машины перейдите в ее Параметры и в пункте Процессоры - Совместимость установите флажок Выполнить перенос на физический компьютер с другой версией процессора, это позволит выполнять миграцию между узлами с разными моделями процессоров одного производителя. Миграция с Intel на AMD или наоборот невозможна.
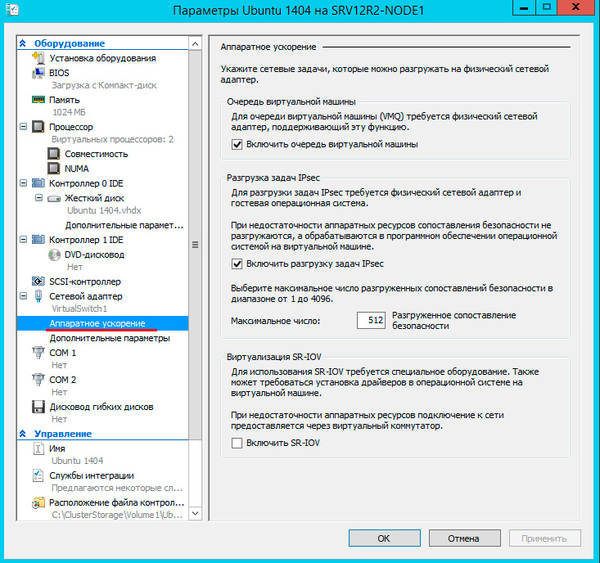
Не забудьте настроить автоматические действия при запуске и завершении работы узла, при большом количестве виртуальных машин не забывайте устанавливать задержку запуска, чтобы избежать чрезмерной нагрузки на систему.
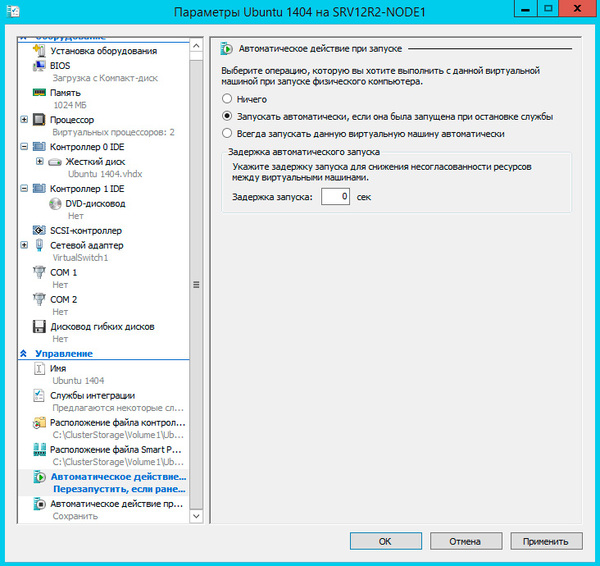
Закончив с Параметрами перейдите в Свойства виртуальной машины и укажите предпочтительные узлы владельцев данной роли в порядке убывания и приоритет, машины имеющие более высокий приоритет мигрируют первыми.
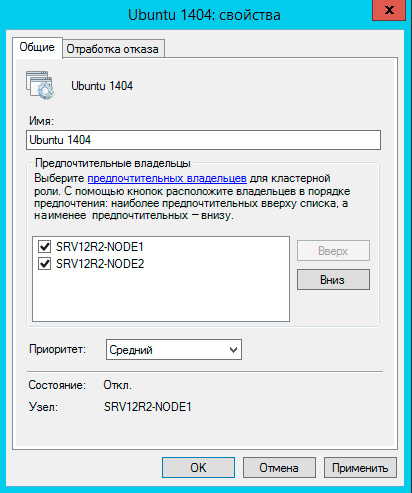
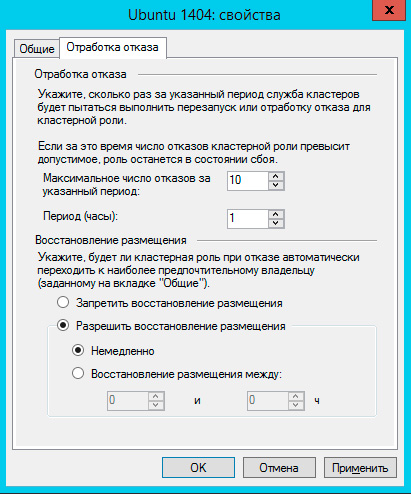
На закладке Обработка отказа задайте количество допустимых отказов для виртуальной машины за единицу времени, помните, что отказом считается не только отказ узла, но и потеря пульса виртуальной машины, например, ее зависание. На время настройки и тестов есть смысл указать значения побольше.
Также настройте Восстановление размещения, эта опция позволяет передавать виртуальные машины обратно наиболее предпочтительному владельцу при восстановлении его нормальной работы. Чтобы избежать чрезмерных нагрузок воспользуйтесь опцией задержки восстановления.
На этом настройка виртуальной машины закончена, можем запускать и работать с ней.
Теперь самое время проверить миграцию, для этого щелкните на машине правой кнопкой мыши и выберите Переместить - Динамическая миграция - Выбрать узел. Виртуалка должна переместиться на выбранную ноду не завершая работы.
Каким образом происходит миграция в рабочей обстановке? Допустим нам надо выключить или перезагрузить первый узел, на котором в данный момент выполняется виртуальная машина. Получив команду на завершение работы узел инициирует передачу виртуальных машин:

Завершение работы приостанавливается до тех пор, пока не будут переданы все виртуальные машины.

Когда работа узла будет восстановлена, кластер, если включено восстановление размещения, инициирует обратный процесс, передавая виртуальную машину назад предпочтительному владельцу.

Что произойдет если узел, на котором размещены виртуальные машины аварийно выключится или перезагрузится? Все виртуалки также аварийно завершат свою работу, но тут-же будут перезапущены на исправных узлах согласно списка предпочтительных владельцев.
Как мы уже говорили, прижившийся в отечественной технической литературе термин "отказоустойчивый" неверен и более правильно его было бы переводить как "с обработкой отказа", либо использовать понятие "высокая доступность", которое отражает положение дел наиболее верно.
Кластер Hyper-V не обеспечивает отказоустойчивости виртуальным машинам, отказ узла приводит к отказу всех размещенных на нем машин, но он позволяет обеспечить вашим службам высокую доступность, автоматически восстанавливая их работу и обеспечивая минимально возможное время простоя. Также он позволяет значительно облегчить администрирование виртуальной инфраструктуры позволяя перемещать виртуальные машины между узлами без прерывания их работы.
В высоконагруженных системах 1С требуется тщательно проработать систему отказоустойчивости, чтобы бизнес не испытывал простоев, а все сбои были незаметны для конечного потребителя.
Мы в EFSOL Oblako тщательно анализируем возможности отказоустойчивости в разных системах, вплоть до холодного резервного копирования на европейских серверах (дублирование на уровне ЦОД).
В данной статье мы рассмотрим возможность кластеризации сервера 1С. Мы подобрали два аналогичных сервера, чтобы получилось распределить нагрузку на сервера 1С.
Устанавливаем 1С:Предприятие 8 на двух серверах с запуском службы “Агент сервера 1С:Предприятие 8.3 (x86-64)” .
После установки, переходим в “Администрирование серверов 1С Предприятия x86-64” .
Заходим в параметры кластера и вводим общее имя кластера, а также указываем “уровень отказоустойчивости” в нашем случае ставим 1 уровень .
На втором сервере удаляем “Локальный кластер” , сделанный по умолчанию. Подключаемся к новому созданному кластеру с именем “Cluster1C” .
Создаем “рабочий сервер” , указываем что этот рабочий сервер является “центральным” .
Заходим в Рабочие серверы => SQL => Требования назначения функциональности , создаем новое требования для клиентского соединение с ИБ, тип требования: назначить .
Повторяем тоже самое на рабочем сервере SQL2 .
Управление кластером заключается в том, что администратор определяет состав компьютеров (рабочих серверов), на которых размещается кластер. Кроме этого (при необходимости), он может определить требования к ним: какие сервисы и соединения с информационными базами должны работать на каждом из рабочих серверов.
Менеджеры кластера и рабочие процессы запускаются автоматически, исходя из назначенных требований. Требования к рабочим серверам могут быть заданы интерактивно, из консоли администрирования кластера, или программно, из встроенного языка.
После этого мы можем наблюдать как происходит распределение нагрузки на кластере 1С.
Интересует отказоустойчивое решение 1С? Мы предлагаем готовый кластер 1С в аренду .

Подготовка
Не имеет значения, какие машины вы используете — физические или виртуальные, главное, чтобы технология подходила для создания кластеров Windows. Перед тем, как начать, проверьте соответствие необходимым требованиям:
Две машины Windows 2019 с установленными последними обновлениями. У них должно быть по крайней мере два сетевых интерфейса: один для производственного трафика и один для кластерного трафика. В моем примере у машин три сетевых интерфейса (один дополнительный для трафика iSCSI). Я предпочитаю статические IP-адреса, но также можно использовать DHCP.

Далее необходимо добавить функциональность Failover clustering (Server Manager > Аdd roles and features).

Перезапустите сервер, если требуется. В качестве альтернативы можно использовать следующую команду PowerShell:
Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools

После успешной установки в меню Start, в Windows Administrative Tools появится Failover Cluster Manager .
Обновив Disk Management, вы увидите что-то типа такого:
Server 1 Disk Management (disk status online)

Server 2 Disk Management (disk status offline)

Проверка готовности отказоустойчивого кластера
Перед созданием кластера необходимо убедиться, что все настройки правильно сконфигурированы. Запустите Failover Cluster Manager из меню Start, прокрутите до раздела Management и кликните Validate Configuration.

Выберите для валидации оба сервера.

Выполните все тесты. Там же есть описание того, какие решения поддерживает Microsoft.

После успешного прохождения всех нужных тестов, можно создать кластер, установив флажок Create the cluster now using the validated nodes (создать кластер с помощью валидированных узлов), или это можно сделать позже. Если во время тестирования возникали ошибки или предупреждения, можно просмотреть подробный отчет, кликнув на View Report.

Создание отказоустойчивого кластера
В мастере нужно будет задать имя кластера — Cluster Name и сетевую конфигурацию.

На последнем шаге подтвердите выбранные настройки и подождите создания кластера.

По умолчанию мастер автоматически добавит общий диск к кластеру. Если вы его еще не сконфигурировали, будет возможность сделать это позже.


В качестве альтернативы можно создать кластер с помощью PowerShell. Следующая команда автоматически добавит подходящее хранилище:
New-Cluster -Name WFC2019 -Node SRV2019-WFC1 , SRV2019-WFC2 -StaticAddress 172.21.237.32

Результат можно будет увидеть в Failover Cluster Manager, в разделах Nodes и Storage > Disks.


Иллюстрация показывает, что в данный момент диск используется в качестве кворума. Поскольку мы хотим использовать этот диск для данных, нам необходимо сконфигурировать кворум вручную. Из контекстного меню кластера выберите More Actions > Configure Cluster Quorum Settings (конфигурирование настроек кворума).

Мы хотим выбрать диск-свидетель вручную.

В данный момент кластер использует диск, ранее сконфигурированный как диск-свидетель. Альтернативно можно использовать в качестве свидетеля общую папку или учетную запись хранилища Azure. В этом примере мы используем в качестве свидетеля общую папку. На веб-сайте Microsoft представлены пошаговые инструкции по использованию свидетеля в облаке. Я всегда рекомендую конфигурировать свидетель кворума для правильной работы. Так что, последняя опция для производственной среды не актуальна.

Просто укажите путь и завершите мастер установки.

После этого общий диск можно использовать для работы с данными.

Поздравляю, вы сконфигурировали отказоустойчивый кластер Microsoft с одним общим диском.

Следующие шаги и резервное копирование
Руководство по созданию отказоустойчивых кластеров для Windows Server 2019
Ханнес Каспарик
Ханнес Каспарик работает в ИТ-бизнесе с 2004 г. В настоящее время Ханнес — сотрудник отдела Veeam по управлению стратегией развития продуктов.
Свой первый “кластер” из одноплатных компьютеров я построил почти сразу после того, как микрокомпьютер Orange Pi PC начал набирать популярность. “Кластером” это можно было назвать с большой натяжкой, ибо с формальной точки зрения это была всего лишь локальная сеть из четырёх плат, которые “видели” друг друга и могли выходить в Интернет.
Устройство участвовало в проекте SETI@home и даже успело что-то насчитать. Но, к сожалению, никто не прилетел забрать меня с этой планеты.
Однако, за всё время возни с проводами, разъёмами и microSD-картами я многому научился. Так, например, я выяснил, что не стоит доверять заявленной мощности блока питания, что было бы неплохо распределять нагрузку в плане потребления, да и сечение провода имеет значение.
Начну, пожалуй, с неё. Задача свелась к относительно простым действиям — через заданный промежуток времени последовательно включить 4 канала, по которым подаётся 5 вольт. Самый простой способ реализовать задуманное — Arduino (коих у каждого уважающего себя гика в избытке) и вот такая чудо-плата с Али с 4мя реле.

И знаете, оно даже заработало.


Однако, “холодильник-style” щелчки при старте вызывали некоторое отторжение. Во-первых при щелчке пробегала помеха по питанию и нужно было ставить конденсаторы, а во вторых вся конструкция была довольно крупной.
Так что в один прекрасный день я просто заменил блок реле на транзисторные ключи на основе IRL520.

Это решило вопрос с помехами, но поскольку mosfet управляет “нулём”, пришлось отказаться от латунных ножек в стойке, дабы не соединить случайно землю плат.
И вот, решение отлично тиражируется и уже два кластера работают стабильно без всяких сюрпризов. Just as planned.

Но, вернёмся к тиражируемости. Зачем покупать блоки питания за ощутимую сумму, когда буквально под ногами есть много доступных ATX ?
Мало того, на них есть все напряжения (5,12,3.3), зачатки самодиагностики и возможность программного управления.
Ну тут я особо распинаться не буду — статья про управление ATX через Ардуино есть вот здесь.
Ну что, все таблетки подъедены, марки тоже наклеены ? Пора объединить это всё воедино.

Будет один головной узел, который соединяется с внешним миром по WiFi и отдаёт " интернеты" в кластер. Он будет питаться от дежурного напряжения ATX.
Фактически, за раздачу инета отвечает TBNG.
Так что при желании узлы кластера можно спрятать за TOR.
Также, будет хитрая плата, подключенная по i2c к этому головному узлу. Она сможет включать-выключать каждый из 10 рабочих узлов. Плюс, будет уметь управлять тремя вентиляторами 12в для охлаждения всей системы.
Сценарий работы такой — при включении ATX в 220в стартует головной узел. Когда система готова к работе — он последовательно включает все 10 узлов и вентиляторы.
Когда процесс включения закончен — головной узел будет обходить каждый рабочий узел и спрашивать мол, как мы себя чувствуем, какая мол температура. Если одна из стоек греется — увеличим обдув.
Ну и при команде отключения каждый из узлов будет аккуратно погашен и обесточен.
Схему платы я рисовал сам, поэтому выглядит она жутко. Однако, за трассировку и изготовление взялся хорошо обученный человек, за что ему большое спасибо.
Вот она в процессе сборки

Вот один из первых эскизов расположения компонент кластера. Сделан на листке в клетку и увековечен через Office Lens телефоном.
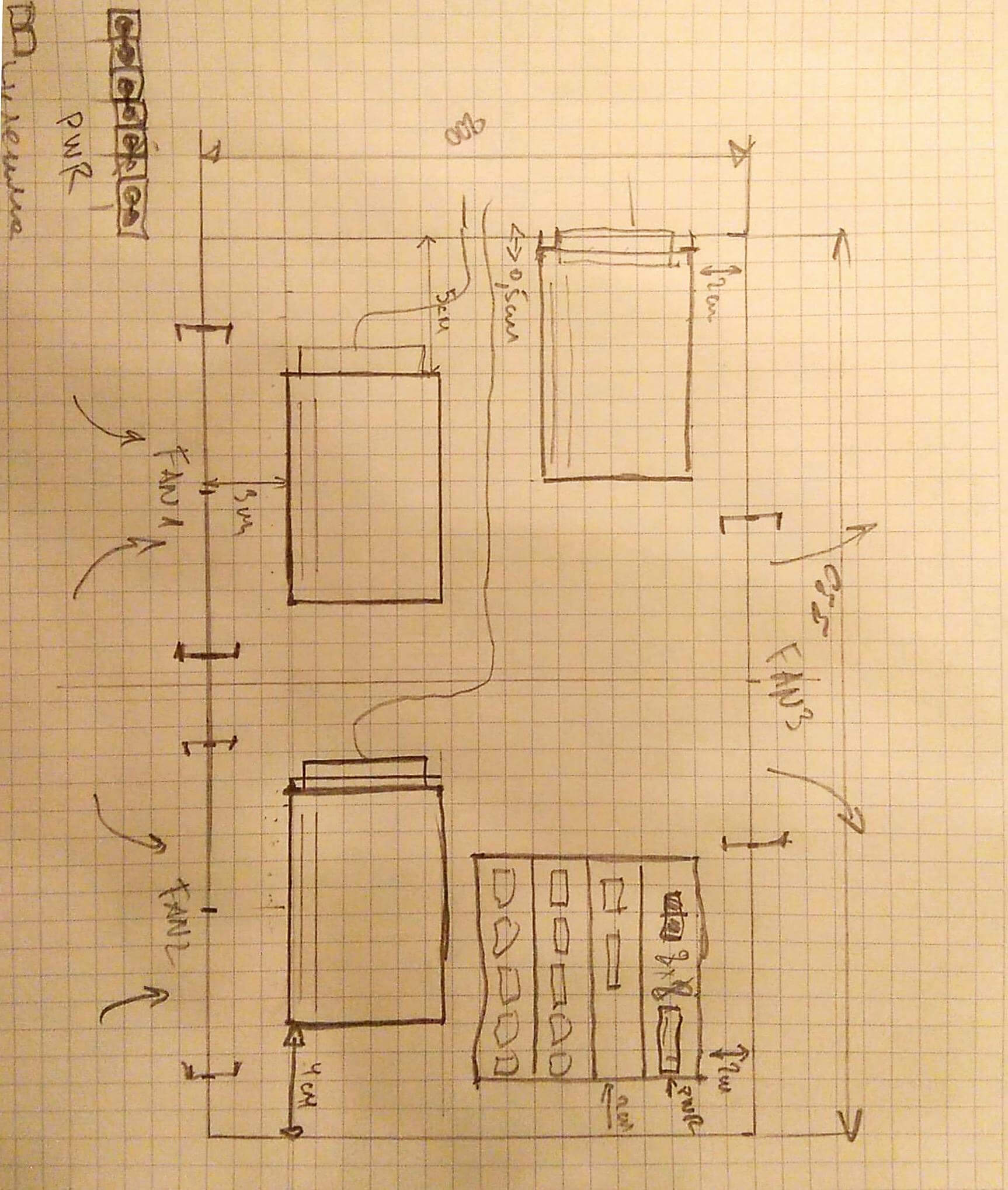
Вся конструкция помещается на листе текстолита, купленного по случаю.
Примерно так выглядит расположение узлов внутри. Две стойки по пять плат.

Тут проглядывается управляющая Arduino. Она соединена с головной Orange Pi Pc по i2c через конвертер уровней.
Ну а вот финальный (текущий вариант).

Итак, все что нужно — это написать несколько утилит на Питоне, которые бы всей этой музыкой дирижировали — включали, включали, регулировали скорость вентилятора.
Не буду утомлять техническими подробностями — выглядит примерно так:
Поскольку узлов у нас уже целых 10, берём на вооружение Ansible, который поможет , например, правильно выключить все узлы. Или запустить на каждом монитор температуры.
Меня часто в пренебрежительном тоне обвиняют, мол это просто локальная сеть одноплатников (как я уже упоминал в самом начале). Мне, в целом, насрать на чужое мнение, но пожалуй, добавим гламура и организуем docker swarm cluster.
Задача весьма простая и выполняется меньше чем за 10 минут. Потом запустим на головной ноде экземпляр Portainer, и вуаля!
Теперь можно реально масштабировать задачи. Так, в данный момент в кластере работает майнер криптовалюты Verium Reserve. И, довольно успешно. Надеюсь, ближайший туземун окупит съеденное электричество ;) Ну или сократить количество вовлеченных узлов и майнить что-нибудь ещё типа Turtle Coin.
Если хочется полезной нагрузки — в кластер можно закинуть Hadoop или устроить балансировку веб-серверов. Готовых образов в интернете много, да и обучающего материала достаточно. Ну а если образ (docker image) отсутствует — всегда можно собрать свой.
Чему меня это научило ? В целом, “стек” технологий очень широкий. Судите сами - Docker, Ansible, Python, прокачка Arduino (прости господи, ни к ночи будет сказано), ну и шелл конечно же. А так же KiCad и работа с подрядчиком :).
Что можно сделать лучше ? Многое. По софтовой части было бы неплохо переписать управляющие утилиты на Go. По железной — make it more steampunkish — КДПВ в начале отлично задирает планку. Так что есть, над чем работать.
- Головной узел — Orange Pi PC с usb wifi.
- Рабочие узлы — Orange Pi PC2 x 10.
- Сеть — 100 мбит TP-link@16ports.
- Мозг — Клон Arduino на базе Atmega8 + конвертер уровней.
- Сердце — контроллер питания АТХ с блоком питания.
- Софт (душа) — Docker, Ansible, Python 3, немного шелла и чуть чуть лени.
- Потраченное время — бесценно.
В процессе экспериментов пострадала пара плат Orange Pi PC2 из-за перепутанного питания (очень красиво горят), ещё одна PC2 лишилась Ethernet (это отдельная история, в которой я не понимаю физики процесса).
Вот вроде бы и вся история “по верхам”. Если кто-то считает её интересной — задавайте вопросы в комментариях. И голосуйте там же за вопросы (плюсуйте — у каждого коммента есть кнопка для этого). Наиболее интересные вопросы будут освещены в новых заметках.
Спасибо, что дочитали до конца.
В общем, друзья, подумал я тут намедни: а что это у меня старый системник стоит, пыль собирает? А не задействовать ли его ресуры во благо великих свершений и не объединить ли его с ноутбуком в один чудесный, прекрасный. кластер?!
Идея странная, но по-своему завораживающая: это ж если научиться вот так спокойно (или относительно спокойно) соединять несколько компов, да не простой сетью локальной, а превращая их в гибриды, превосходящие по производительности каждый из отдельно взятых компонентов системы, можно добиться превосходной эффективности, запуская "тяжеленные" программы и выполняя обширнейшие вычисления.
Конечно, подобные вещи давно практикуются в различных институтах и лабораториях, но идея иметь аналогичную технику дома кажется безумно притягательной. На этом основании вопрос - есть ли среди форумчан люди, могущие подсказать или желающие принять некоторое участие в этой затее? Составленную в результате эксперимента инструкцию можно будет прилепить на сайт, и тогда любой киберпанк исполнит свое домашнее компьютерное извращение.
Кстати сказать, отыскались первые, так сказать, источники (если кому-то будет интересно):
Не уверен, но может возникнуть такая проблема как конфликт железа. железячники не рекомендуют совмещать даже две плашки оперативной памяти разных фирм-производителей. Для кластеров, обычно, используется совместимое железно, дабы не было глюков и можно было достичь максимального быстродействия. Но, в целом-то, я в этом не разбираюсь, так что могу быть не правым в этом вопросе, да. Хотя я совсем в этом не понимаю.
Не уверен, но может возникнуть такая проблема как конфликт железа. железячники не рекомендуют совмещать даже две плашки оперативной памяти разных фирм-производителей. Для кластеров, обычно, используется совместимое железно, дабы не было глюков и можно было достичь максимального быстродействия. Но, в целом-то, я в этом не разбираюсь, так что могу быть не правым в этом вопросе, да. Хотя я совсем в этом не понимаю.
Дело в том, что по первой из прилепленных выше ссылок довольно сильно обнадежили:
" Сразу скажу, что кластер Beowulf - гетерогенная структура. В него могут входить самые разнообазные по параметрам компьютеры, построенные на различных аппаратных платформах, например Intel Pentium различных версий, Alpha, RISC-процессоры, Transmeta, 32-х и 64-х битовые процессоры. Более того, на компьютерах в кластере могут быть установлены самые различные системы: Linux, Windows, OS/2 WARP. Нашей целью будет построение кластера с минимальными усилиями. Поэтому, если вы хотите заниматься делом (сиречь научной работой), а не повышать свой профессионализм в области информационных технологий, о возможной гетерогенности кластера я предлагаю забыть. Будем считать, что аппаратная платформа комьютеров нашего будущего кластера однообразна.
Что касается различия в параметрах (быстродействие, память, . ) у компьютеров, входящих в кластер, то это допустимо. Но в этом случае, вам придется учитывать эти различия при написании параллельных программ, распределяя объем счета в зависимости от возможности каждого отдельного компьютера. В противном случае кластер будет работать как система, состоящая из машин с минимальными рабочими параметрами".
Но замечание насчет железа кажется мне очень разумным - я надеюсь, что авторы того сайта еще вернутся к этому вопросу.
Читайте также: