
Как сделать чтобы страница не индексировалась
Добавил пользователь Дмитрий К. Обновлено: 04.10.2024
Содержание
- Закрыть и открыть сайт
- Директива User-agent
- Директива Disallow
- Директива Allow
- Директива Host
- Директива Sitemap
- Спецсимволы *, $ в robots.txt
- Как проверить robots.txt
- Кириллица в файле Robots
- Что нужно обязательно закрывать в robots.txt
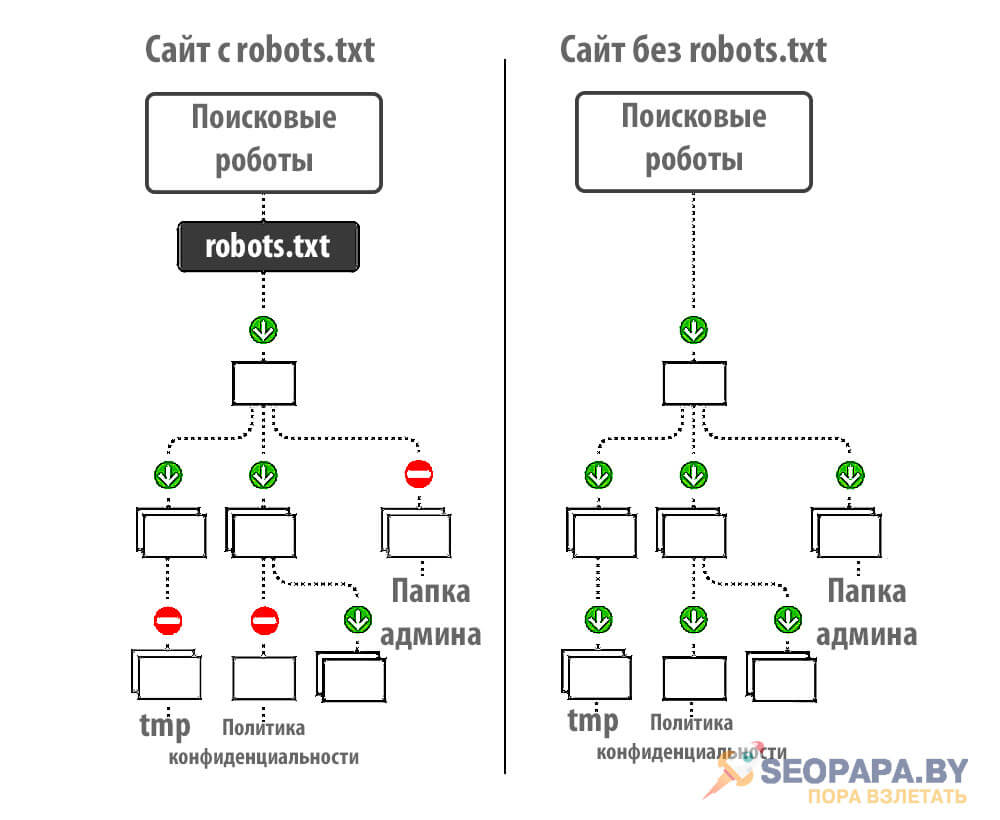
Полностью разбираем один из самых важных файлов сайта - robots.txt, ведь от него зависит корректная индексация страниц и продвижение всего сайта в целом.
Закрыть и открыть сайт
Закрыть от индексации сайт
Запрещаем индексацию сайта всем роботам:
Открыть к индексации сайт
Разрешаем всем роботам индексацию сайта:
Директива – это некое указание для поисковых роботов на то, что необходимо индексировать.
Кроме файла robots.txt закрыть или открыть сайт (страницы сайта) можно с помощью специального meta тега robots, однако данный тег не освобождает владельца сайта от необходимости иметь на сервере отдельный файл robot.txt
Директива User-agent
User-agent – самая первая директива, которая позволяет обратиться к роботам поисковых систем. Рядом с ней указывается название поисковой системы или * (звездочка).
* (звездочка) в директиве User-agent позволяет обращаться ко всем поисковым системам сразу.
| Система | Запись в User-agent | Описание |
| GoogleBot | Робот Google | |
| Яндекс | YandexBot | Основной робот Яндекса |
| Яндекс | YandexMobileBot | Мобильный робот Яндекса |
| Яндекс | Yandex | Робот, который будет использовать все другие боты от Яндекса (основной и мобильый) – используется чаще всего. |
| Bing | BingBot | Основной робот от поисковой системы bing.com |
| Mail.ru | Mail.ru | Робот от поисковой системы mail |
| Rambler | StackRambler | Робот от поисковой системы rambler |
В большинстве своих проектов нам достаточно лишь:
Директива Disallow
Директива Disallow – означает запрет к индексации страницы, раздела или файла.
* (звездочка) означает то, что перед нашим названием файла (папки) может стоять все, что угодно.
Директива Allow
Директива Allow – означает допуск к индексации страницы, раздела или файла.
Как открыть к индексации страницу или раздел:
На данном примере мы открыли раздел /uploads.
Как открыть файл из закрытого раздела:
В этом примере мы запрещаем индексировать все страницы, в которых содержится слово bitrix, но разрешаем индексировать страницы, в которых есть и bitrix и jpg, однако все другие страницы со словом bitrix в url адресе, которые не содержат символов jpg будут закрыты.
Директива Host
Директива Host – ранее в ней указывалось главное зеркало, но сейчас данная директива не используется поисковыми системами и ее можно не прописывать в файле robots.txt, т.к. сейчас все роботы смотрят на корректную настройку 301 редиректа, а не на то, что написано в директиве host. Информацию по этому поводу можно прочитать в статье Яндекса. Если вы добавите данную директиву в свой файл robots.txt, то ничего страшного от этого не произойдет, главное не забудьте настроить правильно зеркала.
Директива Sitemap
Sitemap – директива, служащая для указания на xml карту сайта, которая также обязательно должна быть на любом сайте (даже одностраничном). В карте сайта указывается список страниц, которые должны быть проиндексированы поисковой системой.
Директива указывается в самом конце файла robots.txt в виде url-адреса до файла карты сайта .xml
Спецсимволы *, $ в robots.txt
В файле robots.txt при указании путей можно использовать символы * и $ , задавая определенные регулярные выражения.
* означает любую последовательность символов. По-умолчанию к концу каждого правила, описанного в файле роботс тхт, приписывается спецсимвол *
$ данный спецсимвол служит для отмены * на конце.
Примеры:
Disallow /*visit/
Для данного правила:
Disallow /*visit/$
Как проверить robots.txt
Чтобы проверить правильное заполнение файла robots.txt можно воспользоваться сервисом Яндекс.Webmaster, в который уже должен быть добавлен ваш сайт.
На странице Инструменты -> Анализ robots.txt
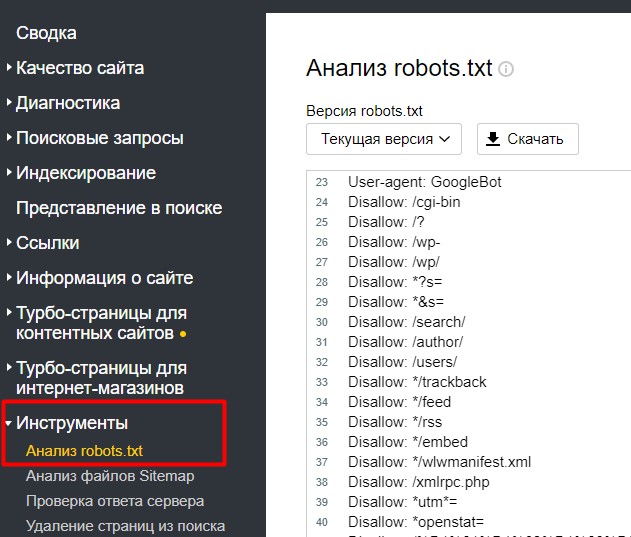
Внизу есть поле для проверки страницы (доступна она для индексации или нет).
Вы можете скопировать интересующий вас url адрес вашего сайта в данную форму и проверить – доступна страница к индексации или нет.
и вот, что получилось:
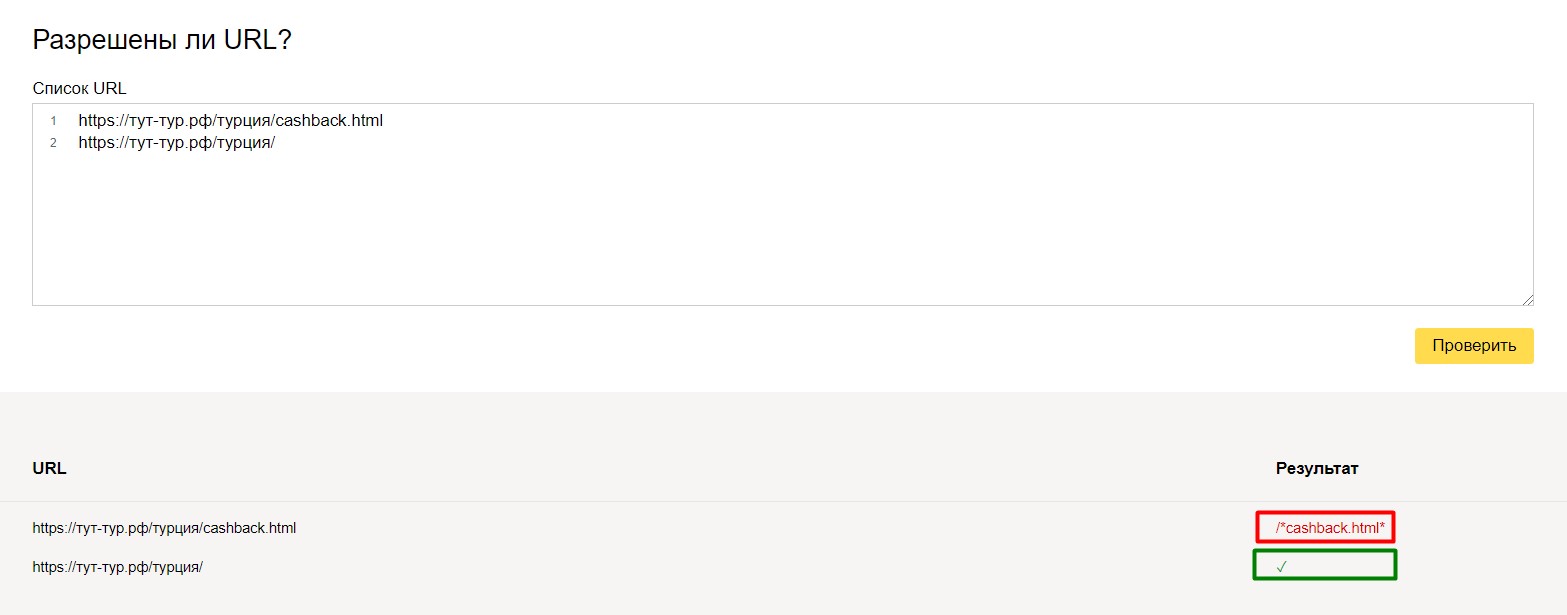
Для перепроверки, можно производить различные тесты над вашим файлом robots.txt.
На своем примере — мы удалили строчку Disallow: /*cashback.html
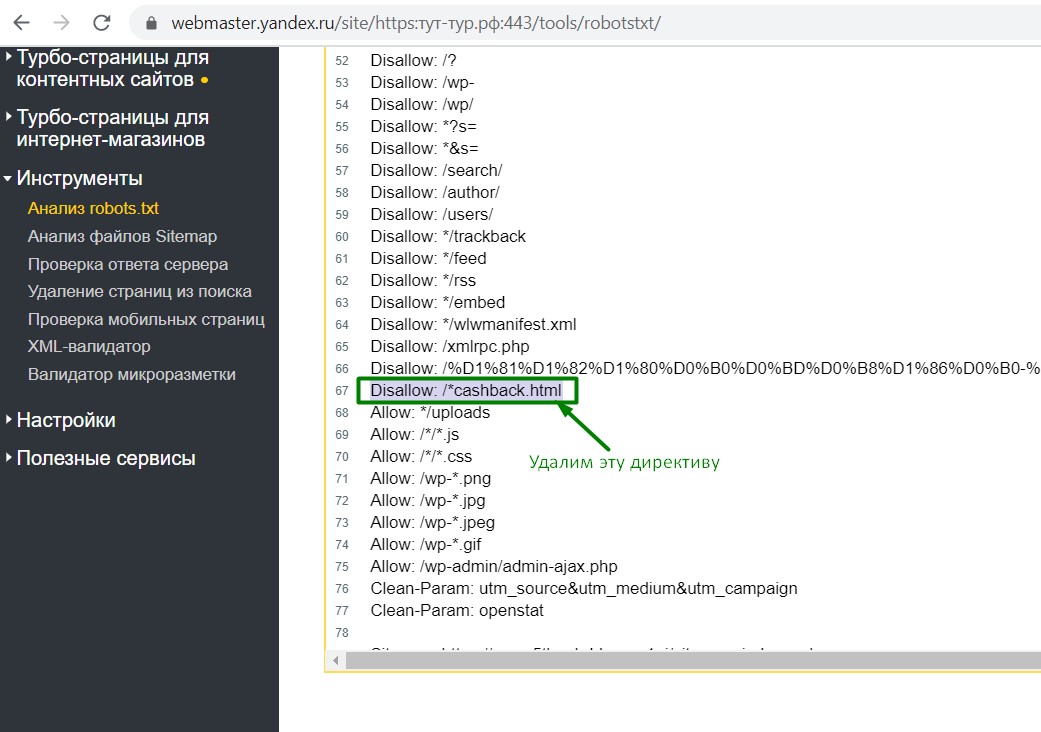
и вот, что у нас получилось:
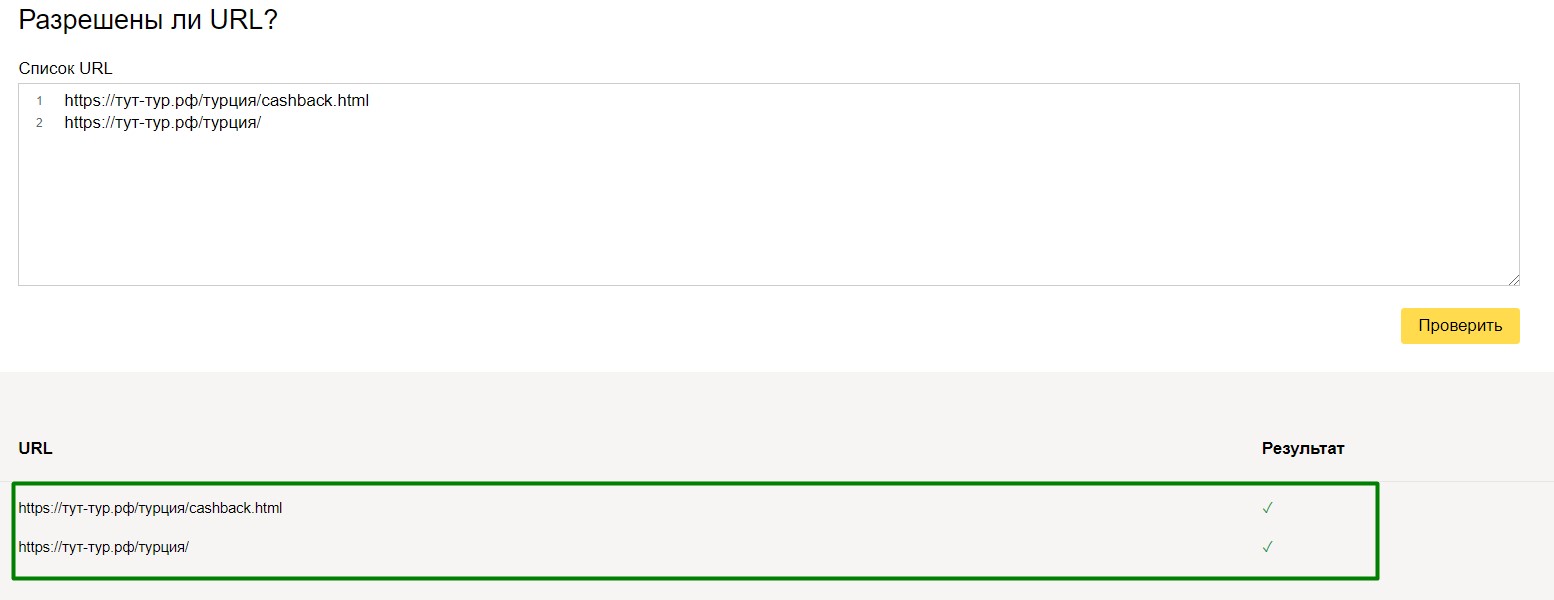
Все страницы доступны к индексации.
Данные методы тестирования применимы как к небольшим, так и к крупным проектам. Особенно, если есть мультиязычная версия и добавлено много правил.
Например, нам нужно, чтобы не индексировалась страница /travelguides/, но индексировалась travelguides/austria/. В этом случае мы создаем такое правило:
Кириллица в файле Robots
Что нужно обязательно закрывать в robots.txt
Например, мы видим, что в платном канале используются url с хвостами, где содержится параметр param=id
Мы не будем закрывать каждую страницу от индексации, а используем маску:
то есть мы закрыли тем самым от индексации станицы, которые содержат param=id , т.к. это является дублями.
Также, необходимо закрывать от индексации страницы с результатами поиска, фильтрации, страницам печати, страницы пагинации и т.п.
Например, закрываем страницу с выводами результатов поиска:
Для данного примера конструкция закрытия от индексации будет:
Иностранная версия сайта
Если сайт содержит в себе иностранную версию страниц и контент на этих страницах полностью дублирует русскоязычную версию, то обязательно нужно закрывать данную страницу от индексации (если только это не является русскоязычным переводом).
Примеры, когда сайт нужно закрывать от индексации
Строгие алгоритмы краулеров не могут учитывать частные моменты. Факторы времени, обстоятельств, творческие противоречия, оригинальность замысла вебмастера . Запретить роботам прийти на страницы, когда вы не готовы, нельзя, а вот написать запрет на просмотр файлов можно. Вот причины, чтобы отключить индексацию сайта, отдельных страниц, блоков:
- Сайт в работе. Есть пустые страницы, меняется дизайн, ссылки не работают или отсутствуют. Вы не хотите, чтобы ваш проект люди увидели таким.
- Есть два варианта ресурса. Один основной, а дубликат – для тестирования нововведений. Краулеры такое совпадение посчитают плагиатом, что повлияет на ранжирование в поисковой выдаче.
- Информация личная или служебная. Например, корзина клиента, его адрес, телефон. Может быть, секретные данные, которые нельзя делать общедоступными по закону или в целях безопасности.
- Есть информация, которую невозможно сделать уникальной: законы, инструкции, календари, цитаты и т.д.
Возможны другие причины закрыть сканирование роботами. Процесс смены домена или сайт только для друзей. Ссылки, оставляемые в комментариях, тоже не желательно индексировать.
Способы запрета индексирования сайта или страницы
Вариантов много. Попробуем их структурировать.
Запрет индексирования сайта, раздела или страницы
Итак, есть необходимость не допустить роботов на сайт. Смотрим таблицу и выбираем подходящий способ. Выбор зависит от задачи и возможностей инструмента. Начнем со случая, когда цель не меньше страницы.
Инструмент robots.txt
В программе блокнот создаем файл с названием robots и расширением .txt. Чтобы закрыть сайт от индексации с помощью robots.txt, вводим в этом файле обращение ко всем поисковым роботам User-agent: * и команду Disallow: /. Сохраняем и загружаем файл на сервер в корневую папку через файловый менеджер или админпанель . Этот простой алгоритм поможет запретить индексацию сайта целиком.
Если надо закрыть доступ к сайту определенным поисковым системам, то в обращении вместо User-agent: * нужно поставить имя поисковых роботов данной системы. Например: User-agent: Yandex. И для каждого нежелательного поисковика делать свое обращение отдельной строкой.
Для скрытия раздела по этому алгоритму, после команды Disallow: / пишется razdel. Если нужно спрятать от роботов одну страницу, то после Disallow: / вставляем ее url-адрес.
Важно не увлекаться. Максимальное количество файлов robots.txt — 1024. Но большое количество запретов, приведет к их игнорированию.
Закрыть страницу и сайт с помощью метатега robots

Если у вас есть доступ к редактированию исходного кода, то мета-тег robots, прописанный в head перед ,тоже может сообщить поисковикам о нежелательности индексации. В метатеге используют команды:
- noindex, скрывает главную страницу, или при дополнении, поможет не индексировать содержимое страницы. Она не появится в результатах поиска;
- nofollow – это для ссылок. Команда показывает роботу, что переходить по ним не надо. Но ссылки могут попасть в индексацию, если информация о них есть в других источниках;
- none – заменяет обе предыдущие команды вместе. То есть none = nofollow + noindex.
Запрет на индексацию сайта robots работает для страниц, текста, ссылок. Но если вам нужно закрыть сайт от индексации целиком, то лучше воспользоваться инструментом robots.txt .
Закрыть сайт от индексации на WordPress
Запрет индексации сайта с помощью .htaccess
Запрет индексирования контента страницы
На страницах могут содержаться блоки, картинки, текст и другие элементы. Скрыть их помогут уже названные инструменты.
Заключение
Возможностей для скрытия контента от поисковиков достаточно. Каждая из них имеет свои плюсы и особенности. Применяя любой способ, связанный с написанием кода, важно делать это внимательно. Допущенные ошибки могут дать результат обратный ожидаемому. Многие проблемы можно решить без запрета. Например, закрывать ли фильтры на сайте от индексации? Не обязательно – грамотные скрипты оставят на странице только один параметр, а остальные будут появляться по клику. К каждому вопросу оптимизации надо подойти индивидуально, особенно пока опыта еще нет.
Есть тысяча и одна причина, почему необходимо отключить индексацию части или всех страниц вашего сайта. Составим подробную инструкцию: как это сделать и какие варианты настроек индексирования сайта доступны.
О чем статья?
- Каким страницам и сайтам не нужно индексирование
- Когда нужно скрыть весь сайт, а когда — только часть его
- Как выбирать теги, закрывающие индексацию
- Контент-редакторам
- Администраторам сайтов
- Владельцам сайтов
Итак, в то время как все ресурсы мира гонятся за вниманием поисковых роботов ради вхождения в ТОП, вы решили скрыться от индексирования. На самом деле для этого может быть масса объективных причин. Например, сайт в разработке или проводится редизайн интерфейса.
Когда закрывать сайт целиком, а когда — его отдельные части?
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Если ресурс имеет большое количество служебной информации, делайте закрытый портал или закрывайте страницы и целые разделы.
Лучше скрыть также всплывающие окна и баннеры, скрипты, размещенные на сайте файлы, особенно если последние много весят. Это уменьшит время индексации в целом, что положительно воспринимается поиском, и снизит нагрузку на сервер.
Как узнать, закрыт ресурс или нет?
Закрываем сайт и его части: пошаговая инструкция.
- Для начала найдите в корневой папке сайта файл robots.txt. Для этого используйте поиск.
- Если ничего не нашли — создайте в Блокноте или другом текстовом редакторе документ с названием robots расширением .txt. Позже его надо будет загрузить в корневую папку сайта.
- Теперь в этом файле HTML-тегами детально распишите, куда заходить роботу, а куда не стоит.
Как полностью закрыть сайт в роботс?
Приведем пример закрытия сайта для основных роботов. Все вместе они обозначаются значком *.

Файл robots.txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. При этом также указывайте запрет для индексации всем роботам или тем из них, кто ищет картинки, видео и т.п. Например, указание Яндексу не засылать к вам поиск картинок будет выглядеть как
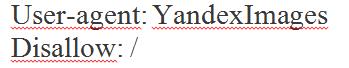
Здесь YandexImages — название робота Яндекса, который ищет изображения. Полные списки роботов можно посмотреть в справке поисковых систем.
Как закрыть отдельные разделы/страницы или типы контента?
Выше мы показали, как запрещать основным или вспомогательным роботам заходить на сайт. Можно сделать немного по-другому: не искать имена роботов, отвечающих за поиск картинок, а запретить всем роботам искать на сайте определенный тип контента. В этом случае в директиве Disallow: / указываете либо тип файлов по модели *.расширениефайлов, либо относительный адрес страницы или раздела.

Прячем ненужные ссылки
Иногда скрыть от индексирования нужно ссылку на странице. Для этого у вас есть два варианта.
- В HTML-коде самой этой страницы укажите метатег robots с директивой nofollow. Тогда поисковые роботы не будут переходить по ссылкам на странице, но на них может вести другой материал вашего или сторонних сайтов.
- В саму ссылку добавьте атрибут rel="nofollow".
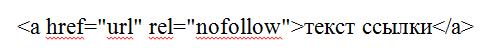
Данный атрибут рекомендует роботу не принимать ссылку во внимание. В этом случае запрет индексации работает и тогда, когда поисковая система находит ссылку не через страницу, где переход закрыт в HTML-коде.
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt являются теги, закрывающие индексации сайта или видов контента. Это мета-тег robots. Прописывайте его в исходный код сайта в файле index.html и размещайте в контейнере .
Существуют два варианта записи мета-тега.

Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название: Googlebot, Яндекс.

1. Закрываем сайт от индексации с помощью файла robots.txt.
Для начала вам нужно создать файл robots.txt. Для этого создаете на своем компьютере обычный текстовый документ с названием robots и расширением .txt. Вот я только что создал его:
Теперь этот файл нужно загрузить в корневую папку своего блога. Если ресурс сделан на движке вордпрес, то корневая папка находится там, где папки wp-content, wp-includes и т. д.
Итак, мы загрузили пустой файл на хостинг, теперь нужно с помощью этого файла как-то закрыть блог от индексации. Это можно сделать, как я уже написал только для Яндекса, Гугла или сразу всех поисковиков. Давайте обо всем по порядку.
Как закрыть сайт от индексации только для Яндекса?
Пропишите в файле robots.txt вот такую строчку:
User-agent: Yandex
Disallow: /

Как закрыть сайт от индексации только для Google?
Откройте файл robots.txt и пропишите там вот такую строчку:
User-agent: Googlebot
Disallow: /

Как закрыть сайт от индексации для всех поисковых систем?
Чтобы запретить сразу всем поисковикам индексировать ваш ресурс, пропишите в robots.txt вот такую строчку:
User-agent: *
Disallow: /
Теперь вы также можете перейти в Яндекс или Гугл Вебмастер и проверить запрет индексации.
Свой файл robots.txt вы можете увидеть по такому адресу:
Все что вы прописали в этом файле должно отображаться в браузере. Если при переходе по этому адресу перед вами выскакивает ошибка 404, значит, вы не туда загрузили свой файл.
Кстати, мой robots.txt находиться здесь. Если ваш ресурс сделан на движке wordpress, то можете просто скопировать его. Он правильно настроен для того, чтобы поисковые боты индексировали только нужные документы и что бы на сайте не было дублей.

3. Закрываем сайт от индексации вручную.
Когда вы закрываете целый ресурс или страницу от индексации, то в исходном коде автоматически появляется вот такая строчка:
meta name="robots" content="noindex,follow"
Она и говорит поисковым ботам, что документ индексировать нельзя. Вы можете просто вручную прописать эту строчку в любом месте своего сайта, главное чтобы она отображалась на всех страницах и тогда ресурс будет закрыт от индексации.
Кстати, если вы создаете ненужный документ на своем сайте, и не хотите чтобы поисковые боты его индексировали, то можете также вставить в исходном коде эту строчку.
После обновления откройте исходный код страницы (CTRL + U) и посмотрите, появилась ли эта строчка там. Если есть, значит все хорошо. На всякий случай можете еще проверить с помощью инструментов для вебмастеров от Яндекса и Гугла.
На этом все на сегодня. Теперь вы знаете, как закрыть сайт от индексации. Надеюсь, эта статья была полезна для вас. Всем пока.
Читайте также: