
Как сделать спайдера
Обновлено: 07.07.2024
Конечно, на картинке всё выглядит красиво. НО.
1. Один конец на сосне. На какую высоту вы эффективно забросите это конец . 10-12м. При этом этот конец с пучностями напряжения окажется в кроне сосны, которая внесёт свою ёмкость. какую. Только сосне и известно. )))
2. Второй конец окажется у земли. у самой земли. Со своими вытекающими последствиями.
3 –эл. мне кажется не проще, может я не нашел подходящую ссылку… если есть, поделитесь. Видел одну, предполагалось ее вешать горизонтально за 4 точки к соснам (это мне кажется тяжелее, а как ее вращать. ) Проще было бы (если это возможно. ) сделать 3-эл. несимметричную яги по аналогии с 2-х элементной несимметричной добавив еще один луч. Если конечно, будет с нее толк. Но таких наработок я не встречал.
Я предполагаю, Спайдер на природе будет направленный. Если направление не понравилось, переставил 3 колышка и уже другое направление… при этом крепление на сосне осталось прежним.
"На какую высоту вы эффективно забросите это конец 10-12м. " - думал об этом. На какую реально заброшу, покажет жизнь. Но теоретически хочется, чтобы центр антенны был на высоте 20 метров (я думаю это будет оптимальной высотой!?), т.е. хотелось бы забросить метров на 30. Руками скорее не получится. Попробовать решить проблему хочу так: выбрать отдельно стоящее дерево высотой метров 30. Взять увесистую гайку, привязать к ней леску и попробовать из рогатки перебросить леску через дерево. Если это удастся, то далее уже дело техники. См. картинку.
Еще возможный вариант - переброска лески между двумя деревьями. Так можно отдалить антенну от деревьев.
Спайдер (spider) — это программа, используемая для получения некоторых или всех ресурсов с большого числа Web-сайтов. На первых порах спайдеры [Fic94] использовались в качестве вспомогательного средства при обслуживании Web-сай- тов. В настоящее время спайдеры в основном используются для сбора информации в интересах поисковых систем. До сих пор мы обсуждали роль Web-браузеров — наиболее распространенного типа Web-клиентов. Поиск информации в Web также остается одним из популярных приложений, что и явилось причиной для создания таких инструментов, как спайдеры. Далее мы подробно рассмотрим клиенты-спай- деры и поговорим об их использовании в поисковых системах.
В главе 1 мы говорили о роли, которую играли предшествующие Web-системы в оказании помощи пользователям при поиске интересующих их документов в Internet. Эти системы имели каталоги, служившие в качестве предметпых указателей для наборов документов. Gopher и WAIS имели дополнительные возможности для индексирования документов, хотя при этом каждый сайт должен был регистрировать свое содержимое на центральных серверах.
Системы, связанные с Web, такие как Gopher, были также ориептироваиы на поиск информации. Централизованный характер Gopher с его требованиями глобальной регистрации создали условия для всеобъемлющего поиска, однако необходимость обслуживания центрального реестра стало серьезной помехой в достижении успеха. С самого пачала поиск активно использовался приложениями в Web. При быстром увеличении числа Web-сайтов, пользователей и Web-страниц, отсутствовала расширяемая технология, позволяющая отдельным пользователям или владельцам сайтов ориентироваться в быстро растущем наборе доступных документов. Децентрализованная суть Web сделала поиск сайтов и страниц необходимостью. Если пользователь ищет вхождения строки в небольшом файле, можно выполнить поиск по запросу. Выполнение же поиска в наборе из нескольких гысяч файлов потребует времени. Если же следует просмотреть десятки тысяч файлов, размещенных на тысячах компьютеров, задержка для пользователя будет еще больше. Наконец, если сотни тысяч пользователей ищут текстовые строки в десятках миллионов документов, размещенных на миллионах компьютеров, проблема становится значительно более сложной. Именно эту проблему призваны решать поисковые системы.
Первоначально, когда коллекция документов на удаленных сайтах была небольшой, имело смысл создавать локальные инвертированные индексы на каждом из удаленных сайтов. Однако с резким расширением Web создание локальных инвертированных индексов стало нецелесообразным. Лучшим выходом стало иметь несколько централизованных предметпых указателей, которые могли бы использоваться миллионами пользователей. Для осуществления масштабного поиска необходимы два компонента: спайдеры и поисковые системы. В этом разделе мы познакомимся со снайдерами и увидим, как они используется совместно с поисковыми системами. .
На практике, однако, с сайтов может запрашиваться только часть ресурсов. Многие спайдеры, например, не запрашивают изображепия или мультимедийные ресурсы. Это делается, если спайдер используется для построения индекса только текстовых ресурсов.
После того как сайт был проиндексирован, спайдер должен периодически повторно посещать сайт, поскольку содержимое последнего может изменяться. Однако содержимое одних сайтов может меняться не столь часто, как содержимое других сайтов. Спайдер должен обладать достаточным интеллектом, чтобы переиндексировать сайты в соответствии со скоростью изменения информации на них. Это позволяет сократить объем работы и избежать излишних обращений к сайту. Кроме того, некоторые составные части сайта могут меняться чаще, чем другие. Спайдер должен, таким образом, учитывать структуру информации на сайте и просматривать регулярно меняющиеся части более часто.
Существует два соглашения, которым обычно следуют сайты, чтобы каким-то образом контролировать работу индексирующих их снайдеров. должны иметь стимул вести себя надлежащим образом; в противпом случае поисковая система может заслужить плохую репутацию. На уровне сайта это может быть реализовано следующим образом: администратор Web-сайта ведет файл с именем robots.txt. Робот — это одно из названий автоматизированного клиента (такого, как спайдер), а файл robots.txt содержит правила доступа, которым должны следовать роботы. Web-сайты используют этот файл в соответствии со стандартом Robot Exclusion Standard [RES]. Файл содержит список каталогов, которые спайдеры не должны посещать, а также спецификацию агентов пользователя, к которым эти ограничения применяются.
Например, рассмотрим следующий файл robots.txt:
User-agent: * Disallow: /stats Disallow: /cgi-bin/ Disallow: /Excite/
В нем указывается, что всем агентам пользователя разрешается загружать ресурсы с сайта для индексирования. Если в поле User-agent присутствуют одпа или несколько строк (вместо "*"), например:
User-agent: ArachnoPhobia, BlackWidow
то два указанных агента пользователя распознаются как клиенты, которые не могут обращаться к сайгу для индексирования. Web-сервер не осуществляет ка- кой-либо явпой проверки или действий по запрету доступа.
Таблица 2.4. Некоторые поисковые систсмы
Поисковая система
Доменное имя спайдера

Второй способ сообщить роботам о том, какие ресурсы не следует индексировать — воспользоваться HTML-тегом МЕТА. Например, тег
ипформирует робота, что текущий ресурс не должен индексироваться и не следует осуществлять переходы по гиперссылкам в ресурсе. При синтаксическом анализе HTML-документа спайдеры просматривают значение атрибута CONTENT тега МЕТА с целью выяснения, могут ли они индексировать этот документ или осуществлять переходы по имеющимся в нем гиперссылкам.
В таблице 2.4 представлен список известпых спайдеров [Spi], используемых некоторыми популярными поисковыми системами. В первом столбце указано название поисковой системы, во втором столбце — имя, присвоенное спайдеру, а в третьем столбце — доменное имя компьютера, на котором размещен спайдер. Информация предоставляется в виде идентификационных данных, которые Web-сайт может использовать, для обеспечения не слишком частого доступа спайдера к сайгу. Большинство известных спайдеров следуют стандарту Robot Exclusion Standard. К главным отличиям между спайдерами относятся общее число посещаемых сайтов, общее количество индексируемых ресурсов и частота нереиндексировапия. Ряд современных спайдеров способны осуществлять индексирование миллиардов Web-страииц и делать их доступными для поиска. Сравнение эффективности различных поисковых систем можно найти в [LG99]. Большинство компаний не раскрывают информацию о своих спайдерах, поскольку среди поисковых систем имеется силытая конкуренция. Подробную информацию о расширяемом средстве сканирования Web с описанием его возможностей можно найти в [HN99].
Использование спайдеров в поисковых системах
помогают поисковым системам индексировать страницы Web-сайтов. В зависимости от сложности спайдера, размера пачалыюго списка и достунных спайдеру ресурсов, инвертированный индекс может быть создан для всех или для некоторых страниц. За последние 20 лет были созданы сложные алгоритмы построения предметных указателей для больших наборов документов [WMB99].
Список возвращенных документов (или указателей на документы) называется результирующим множеством. Поисковые системы различаются но уровню сложности. Большинство поисковых систем предоставляет простые функции поиска, с помощью которых в предметном указателе ищется одно или несколько ключевых слов и возвращаются указатели на документы, в которых найдепо любое вхождение ключевого слова. Наличие нескольких ключевых слов интерпретйруется как требование выполнения логического оператора or (wiu). Поисковая система Google [Goo] предоставляет пользователям простой интерфейс. Искомые термины объединяются с помощью логического оиератора and (и), при этом возвращаются ссылки только на документы, содержащие все ключевые слова. Усовершенствованная версия поисковой системы AltaVista [Alt] и ее вариаит Raging [Rag] имеют более сложный интерфейс: пользователи могут использовать любую комбинацию операторов and (и), or (wiu), not (не) и near (около). Оператор not (не) представляет собой унарное отрицание, и документы, содержащие искомый термин, исключаются из результирующего множества. Оператор near (около) используется для задания расстояния между ключевыми словами в документе Путем сочетаний различных операторов можно получить результирующее множество, соответствующее требованиям пользователя и содержащее умеренное число документов.
Интервал времени между обработкой документа снайдером, составлением поисковой системой инвертированного ипдекса и использованием его при поиске может быть различным для различных поисковых систем. Обычно он находится в пределах от одной до двух недель. Если за это время документ изменяется, искомые ключевые слова могут больше не присутствовать в документе, когда пользователь осуществляет поиск. Что еще хуже, документ может быть удален с сайта. Web-сайт может быть недоступен во время проведения поиска. В действительности, принимая во внимание эти возможности, некоторые поисковые системы кэши- руют копии искомых ресурсов во время индексирования. Пользователь может, rio крайней мере, увидеть версию документа, имевшуюся на момент индексирования. Часго кэшируется только текст HTML, а встроенные изображения игнорируются.
Спайдер — довольно активно работающий клиент в смысле частоты и числа запросов. Он играет важную роль в одном из наиболее популярных приложений в Web — поиске. Совершенствование алгоритмов функционирования и эффективности спайдеров может оказать значительное влияние на Web.
Спайдеры предназначены для автоматизации операций по захвату, удержания на весу, освобождения и центрирования колонны насосно-компрессорных или бурильных труб в процессе спуска их в скважину.
Спайдеры состоят из нескольких частей:
механизмов подъема клиньев.
Известно несколько конструктивных схем спайдеров, отличающихся способом создания усилий зажима трубы, однако широкое применение получили лишь клиньевые спайдеры, представляющие собой самозажимные устройства, усилия зажима трубы в которых возрастают с увеличением осевого усилия, приложенного к зажатой клиньями трубы.
Эффект захвата и удержания трубы в клиньях спайдера объясняется свойствами клиньевого соединения, характеризуемого для спайдера.
Для функционирования спайдера необходимо выполнение нескольких условий, главные из которых заключаются в обеспечении, с одной стороны, надежного захвата трубы клиньями, исключающего ее проскальзывание, а с другой — в исключении при этом повреждения зажатой трубы клиньями.
Эти условия должны выполняться при захвате каждой трубы, так как их нарушение приводит к аварийной ситуации или к невозможности выполнения спуско-подъемных операций.
В Spider-Man не обошлось без своих мини-игр. С двумя из них вы познакомитесь еще в прологе во время посещения лаборатории Октавиуса. За ручную сборку проектов электросхем дают опыт и научные жетоны для создания костюмов. В этом гайде мы будем выкладывать скриншоты верных решений.

В Spider-Man не обошлось без своих мини-игр. С двумя из них вы познакомитесь еще в прологе во время посещения лаборатории Октавиуса. За ручную сборку проектов электросхем дают опыт и научные жетоны для создания костюмов.
Если хотите, в настройках эти мини-игры можно отключить. Зайдите в "Параметры", затем в "Доступность", а после этого в "Возможность пропуска задач". По умолчанию пропуск выключен. Имейте ввиду, что бонусы дают только за самостоятельную сборку.
В этом гайде мы будем выкладывать скриншоты верных решений. Новые электросхемы открываются по мере продвижения по сюжету. Первые две доступны сразу, еще три появляются, когда приходите чинить костюм Человека-паука.
За ручную сборку всех электросхем и решение всех задачек спектрографа в лаборатории вы получите достижение "Мелкий ремонт".
Проект 1: Точность привода
Это первая и самая простая ваша схема. Достаточно просто расставить детальки в указанном на скриншоте ниже порядке. Ячейки с замком заблокированы и не могут быть использованы.
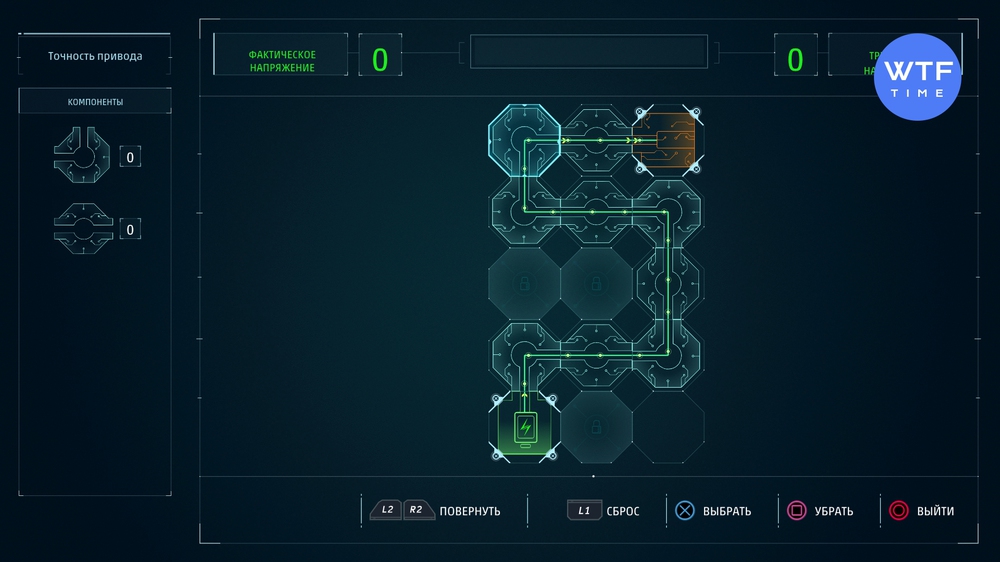
Проект 2: Минимальное усиление захвата
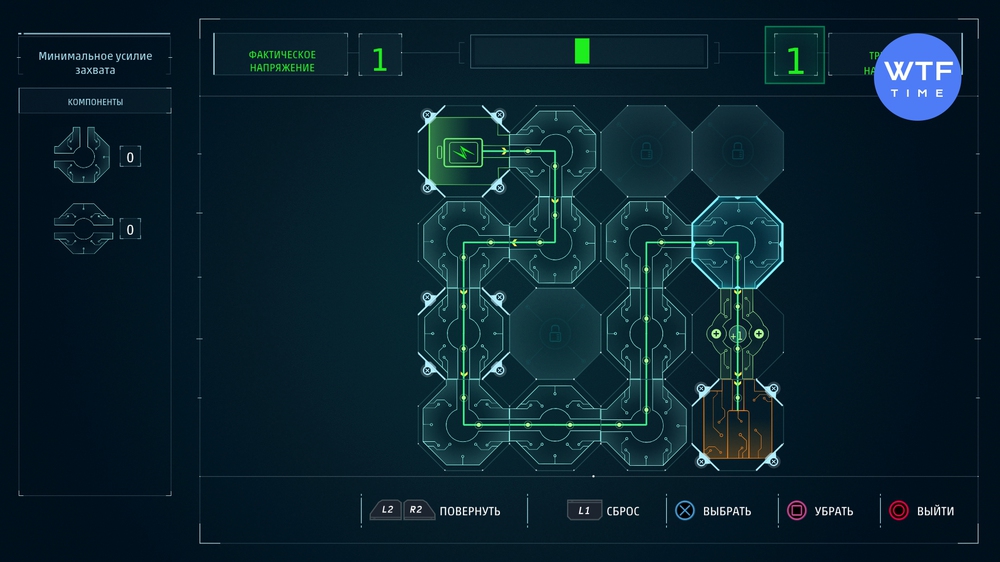
Проект 3: Пространственная карта
В этот раз ничего принципиально нового не появится. Просто спишите решение задачки со скриншота ниже.
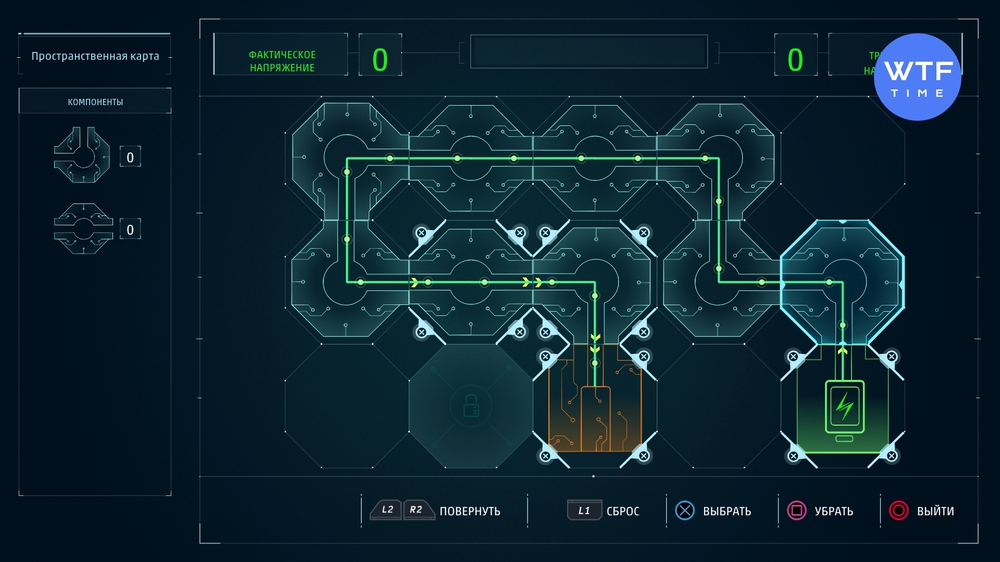
Проект 4: Компенсация баланса
Внимательно рассмотрите приложенный скриншот, а лучше разверните его на весь экран. На этот раз обращайте внимание не только на цифры напряжения на зеленых деталях, но и на направление оранжевых стрелок на деталях стандартного типа.
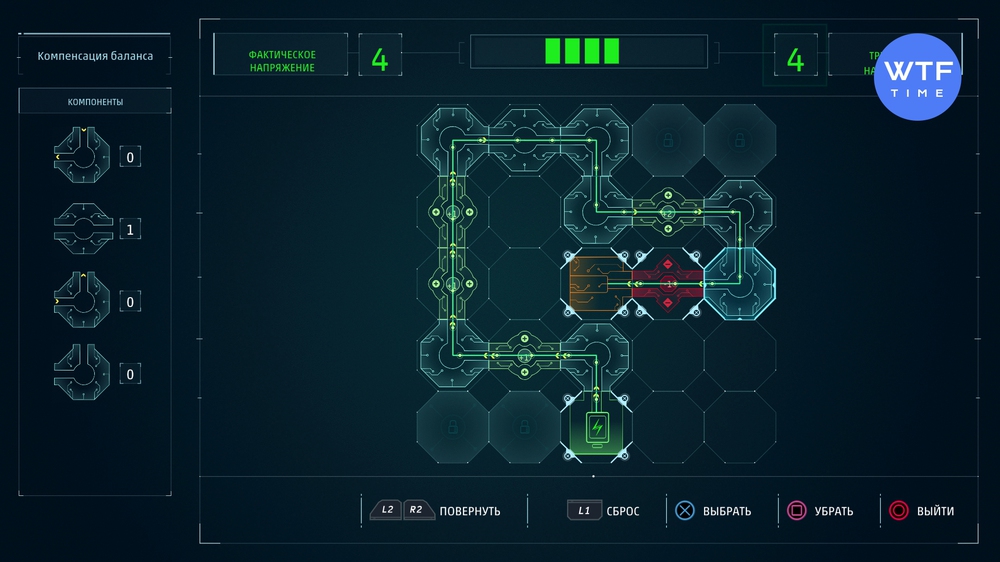
Проект 5: Энергоэффективность
Принцип сборнки ничем не отличается от предыдущей схемы. К зеленым деталям добавляются красные. Нужно подобрать их так, чтобы на выходе получить напряжение 8.
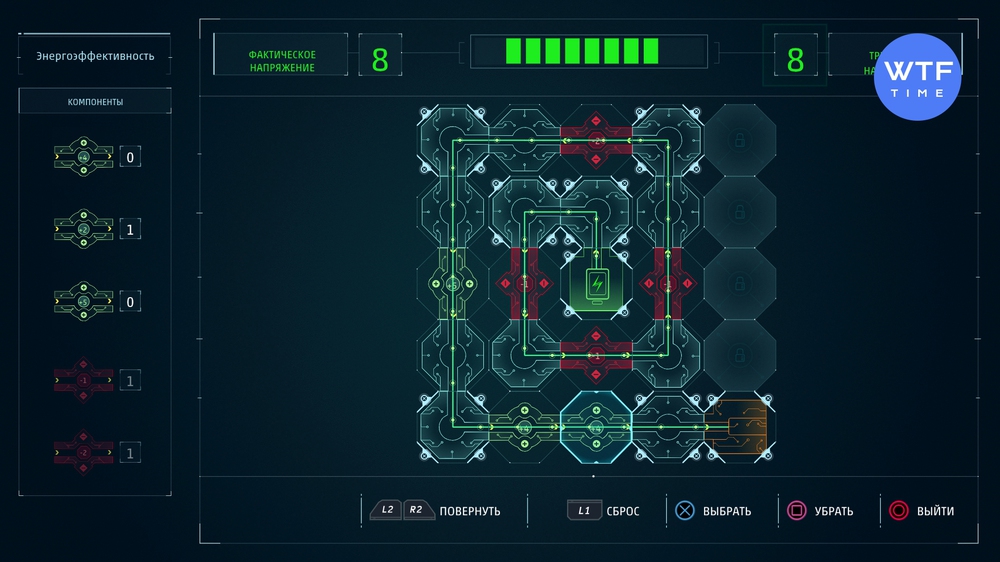
Проект 6: Калибровка микрокабеля
Эту и две следующие схемы мы смогли разблокировать, когда вернулись в лабораторию Октавиуса, чтобы посмотреть на его новые наработки. На скриншоте ниже верное решение.
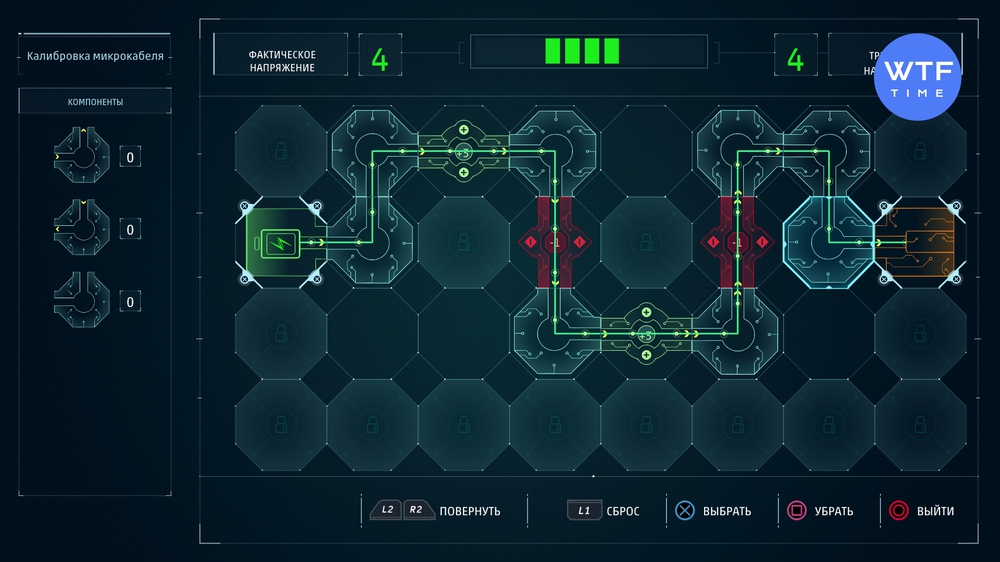
Проект 7: Подсистема машинного обучения
Эта схема сама подсказывает вам верный путь, заблокировав все ненужные ячейки. Просто расставьте имеющиеся детали, обращая внимание на напряжение и направление оранжевых стрелок.
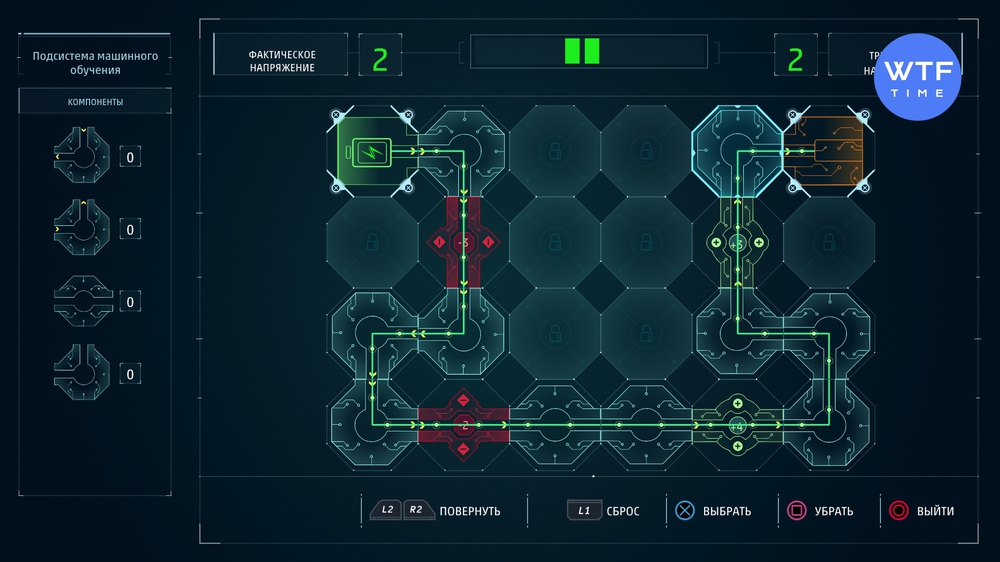
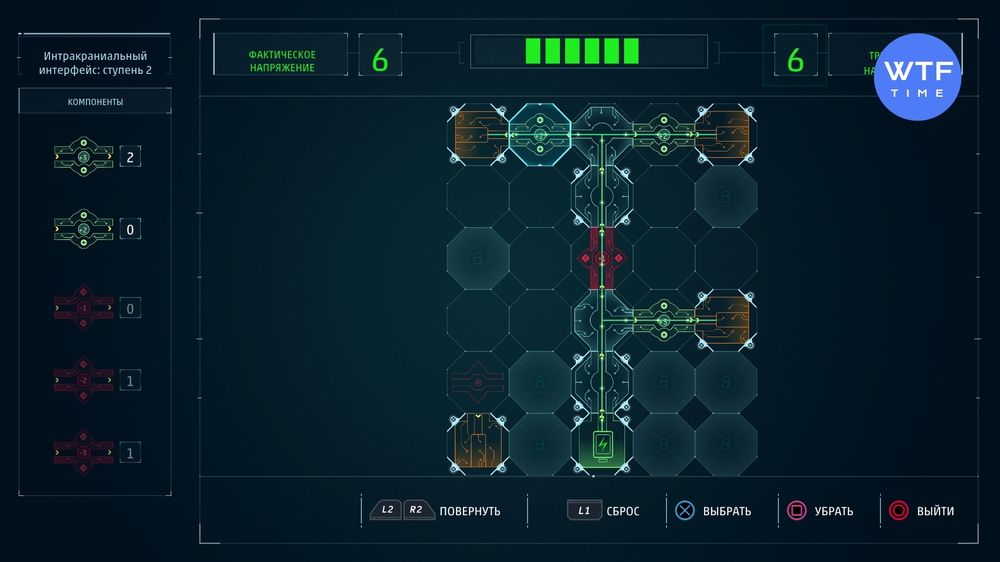
Проект 8: Интракраниальный интерфейс - ступень 1
Никаких принципиально новых деталей в этой схеме не появилось, а вот лишнего места на этот раз предостаточно. Ниже мы выложили свое решение.
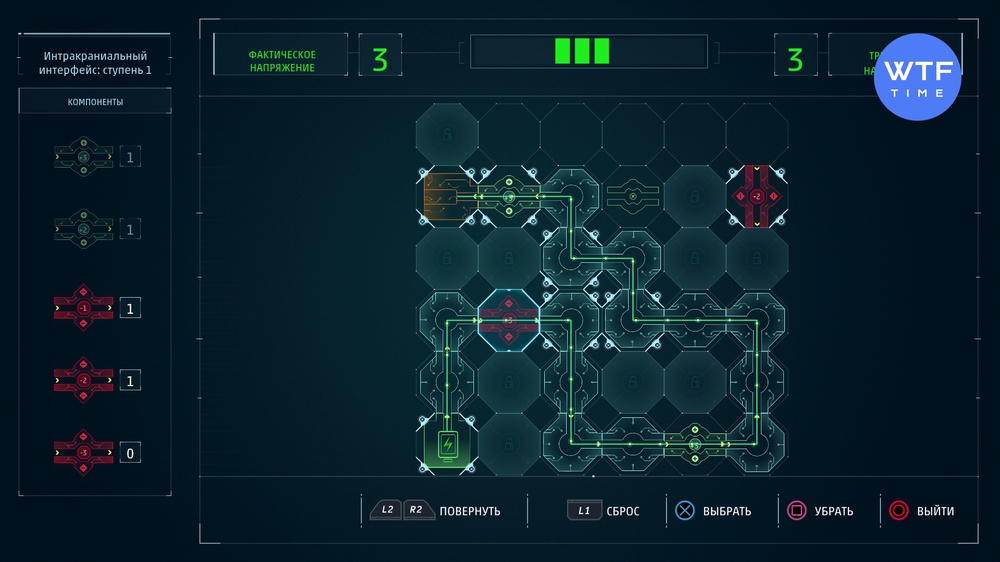
Проект 9: Интракраниальный интерфейс - ступень 1
Последние два проекта стали доступны для расшифровки, когда мы в очередной раз вернулись в лабораторию по сюжету. На этот раз чтобы помочь профессору со шлемом и оценить его костюм. Обратите внимание, здесь появились новые детали - они разводят поток сразу по двум направлениям. Конечных точек теперь тоже несколько.
Проект 10: Точное наведение
Последняя схема, после которой все проекты этого типа будут считаться выполненными. В награду вы получите 5 бонусных научных жетонов. Принцип решения загадки такой же, так и у предыдущей. Используйте детали т-образной формы, чтобы довести поток до трех финальных точек и набрать нужное напряжение.
Читайте также: