
Как сделать скан в finereader
Обновлено: 08.07.2024
На Главной панели выбрать закладку Сканировать > Сканировать изображение. В диалоговом окне установить параметры сканирования (см. выше). Изображения страницы будут добавляться в конец открытого документа FineReader.
Как сделать чтобы Сканер сканировал в PDF?
В окне сканирования в Acrobat выберите сканер и предустановки либо нажмите Заказное сканирование. Чтобы отсканировать бумажный документ в формат PDF с помощью Acrobat, выберите Инструменты > Создать PDF. Откроется окно Создать файл PDF из любого формата. Выберите Сканер для просмотра доступных параметров.
Как работать с программой файн ридер?
Процесс обработки документов с помощью программы ABBYY FineReader состоит из четырех этапов: • Получение изображения; • Распознавание документа; • Проверка и редактирование полученного текста; • Сохранение результатов распознавания. … В списке Язык документа укажите языки распознавания. 3.
Как сканировать в Файнридере без распознавания?
Как конвертировать изображения в PDF без распознавания
- Выделите изображения, которые необходимо сохранить как PDF-файл;
- Щелкните на одном из изображений правой клавишей мыши;
- Выберите Конвертировать с помощью ABBYY FineReader PDF 15 > Конвертировать в PDF (только изображение);
- В открывшемся окне выберите директорию для сохранения PDF-файла.
Как настроить сканер в Abbyy FineReader?
Вы можете легко переключать интерфейс сканирования:
- Откройте диалог Опции на закладке Сканировать/Открыть (меню Сервис>Опции…).
- В группе Сканер установите переключатель в одно из положений: Использовать интерфейс ABBYY FineReader или Использовать интерфейс сканера.
Как настроить сканер чтобы сканировал в один файл?
Нажмите Конфигурация (Configuration) -> СКАНЕР (SCAN). Выберите тип сканирования. Возможные варианты сканирования: Изображение (Image), Электронная почта (E-mail) и Файл (File). Появится окно настройки функции сканирования.
Как отсканировать документ в электронный вид?
Как отсканировать документ
Как в Файнридере 12 Изменить текст?
Чтобы отредактировать текст PDF-документа:
- На панели инструментов нажмите кнопку . …
- Поставьте курсор в нужную строку и внесите в текст правки или измените начертание и размер шрифта c помощью инструментов на активной панели Текст. …
- Завершите редактирование внутри строки. …
- Выйдите из режима редактирования, нажав кнопку .
Как изменить текст в Файнридере?
Как в ABBYY FineReader изменить текст
Что делает программа Abbyy FineReader?
ABBYY FineReader — программа для оптического распознавания символов, разработанная российской компанией ABBYY. Программа позволяет переводить изображения документов (фотографий, результатов сканирования, PDF-файлов) в электронные редактируемые форматы.
Как в Файнридере сохранить формат JPG?
Как сохранить одну или несколько областей:
- Выделите нужные области в окне Изображение.
- В меню Файл выберите пункт Сохранить изображения….
- В открывшемся диалоге Сохранить изображения как выберите диск, папку для размещения сохраняемого файла и формат.
- Отметьте опцию Сохранить только выделенные области.
Как сканировать фото с помощью Abbyy FineReader?
На Главной панели выбрать закладку Сканировать > Сканировать изображение. В диалоговом окне установить параметры сканирования (см. выше). Изображения страницы будут добавляться в конец открытого документа FineReader.
Как отключить распознавание в FineReader при сохранении?
Как отключить автоматическую обработку изображений
Как изменить параметры сканирования?
Какое dpi выбрать для сканирования?
Совет. Отпечатанный на принтере документ рекомендуется сканировать в сером режиме с разрешением 300 dpi. Качество распознавания зависит от качества исходного документа и от того, с какими настройками отсканирован документ. Низкое качество изображения может отрицательно сказаться на полученном результате.
Диджитализация документооборота массово началась еще во второй половине ХХ века. Многие предприятия переходили на электронные документы. В офисах устанавливали первые компьютеры со специальным софтом для обработки и хранения важной информации. Тогда и появились популярные текстовые редакторы. Сотрудники набирали вручную документы, а затем, с появлением в 1993 году PDF, стали экспортировать их в этот формат.
На первый взгляд казалось: если весь документооборот станет электронным, то о шкафах с бумажными каталогами и завалах на рабочих столах можно будет забыть. На практике оказалось, что чем больше организация использует компьютеры для цифрового документооборота, тем больше документов она печатает. 64% крупных компаний уверены, что по крайней мере до 2025 года печать будет значимой частью их бизнеса. С другой стороны, если сегодня в офис по традиционной почте приходит бумажный документ, его немедленно отсканируют и переведут в цифру. Как правило, сканы документов хранят в виде PDF-файлов.
Документом в формате PDF удобнее пользоваться — его можно послать по электронной почте с уверенностью, что информация дойдет до адресата без искажений (если, конечно, кто-то не решит внести изменения собственноручно), и, в отличие от DOC, его трудно изменить. Это особенно важно, если речь идет о контрактах или коммерческих предложениях.
Почему так сложно редактировать текст в PDF?
Изначально PDF не предназначался для того, что его каким-либо образом изменяли. Что было и его преимуществом — это безопасность, одинаковое отображение на любом устройстве и удобный способ обмена информацией, и недостатком — невозможность внесения правок, поиска по тексту и сравнения документов.
Особенности отображения текста в PDF
С 2008 года PDF стал открытым форматом, что позволило разработчикам без проблем и дополнительных отчислений создавать программы для чтения файлов PDF, конвертеры и другие полезные вещи. Развитие OCR привело к тому, что у ранее неизменного PDF-документа появилась возможность редактирования — сначала построчного, а затем и в пределах абзацев.
Как ABBYY FineReader помогает редактировать PDF
Чтобы редактировать PDF-документ, его необходимо сначала подготовить к этому. Главная задача этого процесса — понять и проанализировать структуру текста. А ключевая сложность — отсутствие как абзацев, так и вообще форматирования в PDF. Поэтому сразу после того, как программа распознала текст, она начинает воссоздавать абзацы.

Следующий этап — синтез. Специальные технологии определяют внешние параметры текста — отступы и межстрочные интервалы. Благодаря этому из хаотичной структуры снова появляется текстовый документ с форматированием. И уже в него можно вносить правки — менять слова и целые абзацы, исправлять форматирование, сохранять изменения и так далее.
Как отредактировать текст в отсканированном документе
Отдельная офисная задача — отредактировать скан-копию бумажного документа. Раньше для этого пользователю приходилось конвертировать файл в редактируемый формат или просто искать исходник.
Когда пользователь редактирует скан, ABBYY FineReader 15 в первую очередь распознает документ и создает временный текстовый слой на тех страницах, которые пользователь просматривает. В режиме редактирования создается текстовое представление страницы — именно его редактирует пользователь. Затем эти правки встраиваются в изображение страницы в отсканированном документе.
Как найти в PDF внесенные правки и избежать обмана
Сравнение документов — особо важный для бизнеса сегмент офисных задач. Прежде всего, потому что неожиданные правки могут стоить очень больших денег. Иногда их незаметно пытаются внести в уже подписанный договор и воспользоваться человеческой невнимательностью — такие документы обычно сравнивают юристы, внимательно вычитывая распечатки оригинала, созданного в Word, и ответа контрагента — отсканированный вариант.
Поиск отличий в текстовых документах может быть полезен еще и в том случае, если над ними работают одновременно несколько человек или со временем один и тот же файл периодически изменяют. Это позволяет быстро найти последние правки, которые внесли в файл коллеги. В файлах DOCX для этого есть режим Track Changes, создающий на основе двух версий документа третью — с подсвеченными отличиями в тексте. В новом ABBYY FineReader 15 можно сохранить результаты сравнения любых документов в таком DOCX c Track Changes и в привычном режиме увидеть все различия.
Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов.
Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.
Сравнение проходит в три этапа. Сначала текст, полученный в результате распознавания, разбивается на параграфы. Алгоритм считает, что один параграф — это один объект для сравнения. Все несовпадающие фрагменты обрабатываются во время второго прохода алгоритма — уже по строчкам. Программа определяет, какие строки внутри параграфа совпадают не полностью.
Остается последний проход, уже в рамках несовпадающих строк, который сравнивает отдельные буквы. Этот процесс чуть сложнее: дополнительно используются различные эвристики — варианты распознавания. Если буквы совпадают по вариантам распознавания и процент уверенности распознавания этого элемента превышает 50%, то считается, что они эквивалентны. Не учитываются в качестве различий разные виды кавычек, скобок и маркеры списка.
Для каждого символа существует несколько вариантов распознавания: иногда их число доходит до 20. У каждого из этих вариантов есть процент уверенности, на сколько, по оценке технологии, буква соответствует отсканированному изображению. Затем в ходе анализа документа часть вариантов исключается, так как они не соответствуют эталону или не подходят по морфологии.
В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу.
В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word.
Среди поддерживаемых ABBYY FineReader 15 функций:
- просмотр PDF-документов;
- редактирование текста в PDF-документе в пределах абзаца;
- удаление конфиденциальных данных;
- сравнение документов разного формата и написанных на разных языках;
- автоматизация задач по оцифровке и конвертации;
- распознавание и конвертирование документов;
- комментирование и согласование;
- защита и цифровая подпись.
Как работают нейросети для распознавания иероглифов и арабской вязи
Качество и скорость в быстром и нормальном режиме

Почему важно следить за развитием языка
Новое множество символов формировалось в несколько этапов. Для тестирования создавали подходящие наборы изображений документов. Если в пакет попадала хотя бы одна страница с устаревшими формами, весь комплект оказывался непригодным. Приходилось вынимать эту страничку и формировать новый комплект материалов. Наконец удалось добиться того, чтобы в результатах распознавания почти не было устаревших символов и при этом правильно отображались все современные иероглифы.
Для китайского в FineReader всегда поддерживали традиционный и упрощенный языки. При этом по составу символов они не отличались. Получить разный результат распознавания всё равно было возможно, потому что в программе было заложено разное распределение вероятностей. В новой версии в результате экспериментов удалось выделить символы, необходимые для распознавания упрощенного китайского. В FineReader заложена возможность создавать пользовательский язык. Используя этот инструмент и внося изменения в состав, специалисты сравнивали результаты распознавания на разных образцах документов, и в результате в упрощенном китайском остался только необходимый набор иероглифов.
Корейская письменность, хангыль — нечто среднее между китайским и европейским письмом. Внешне это квадратные символы, напоминающие иероглифы, и на одной странице текста можно насчитать больше сотни уникальных. С другой стороны, это фонетическая письменность, то есть основанная на записывании звуков. Имеется алфавит, содержащий 24 буквы (плюс можно дополнительно посчитать диграфы и дифтонги). Но, в отличие от латиницы или кириллицы, звуки пишутся не в линию, а объединяются в блоки. Каждый блок может состоять из двух, трех или четырех букв. Первой всегда идет согласная, затем одна или две гласных, и в конце может стоять еще одна согласная. Для корейского обучили отдельную нейросеть, которая, помимо корейских слогов, распознает и некоторые иероглифы. Вместо распознавания символов целиком технология определяет отдельные буквы в них.
Как резать арабскую вязь на фрагменты
Арабский язык отличается от других тем, что найти линии порезки между символами в арабской вязи очень сложно. Даже гистограмма при распознавании арабского отличается: выглядит как бесконечный набор горбиков и ямочек.
Варианты разделения текста на символы создаются всегда, даже для европейских языков. В процессе работы программа выбирает наиболее вероятный путь распознавания. В случае с арабским языком таких вариантов очень много, и это приводило к ошибкам. Поэтому для повышения точности программу научили видеть не отдельную букву, а всё слово целиком. Для этого была разработана сеть end-to-end (e2e). Она полезна не только для арабского, но и для европейских языков — например, в дизайнерских шрифтах, когда на изображениях сложно построить путь для распознавания.
При e2e-подходе на вход в нейросеть поступает набор изображений — фрагментов, состоящих из отдельных слов. На выходе такая нейросеть выдает последовательность графем, которые затем проходят дополнительную обработку: проводится словарный анализ, корректируются пробелы.
Для обучения использовался набор из нескольких сотен тысяч фрагментов — отдельные слова из отсканированных газет, журналов, официальных документов. Они были выбраны в несколько итераций: сначала собирали базу из слов, которые удачно распознали, и обучали нейросеть на этом датасете. Потом еще раз обучали, корректировали, выявляли ошибки. Часть, которую не смогли распознать, отдельно отдавали на доразметку и корректировку фрагментов. В результате всё больше очищали датасет для обучения, улучшая общее качество распознавания.
Сначала в ходе обучения такой подход привел к тому, что потерялась информация об охватывающих прямоугольниках символов, которые необходимо отображать для пользователя на этапе верификации. Отказавшись от посимвольного распознавания, пришлось внедрить альтернативный механизм, который дополнял результаты распознавания информацией об охватывающих прямоугольниках и резал слова на отдельные символы.
Сочетание новых алгоритмов машинного обучения сделало возможным создание многофункционального текстового редактора для работы с PDF, сканами и digital-born-документами. Внесение правок, сравнение файлов и распознавание сложных языков дает пользователю возможность полноценно работать с файлами вне зависимости от их формата. По сути, это позволяет охватить все спектры офисных задач по работе с электронными и даже бумажными документами, максимально упрощая работу сотрудникам и снижая вероятность ошибок из-за человеческого фактора.
Сканирование фотографий позволяет преобразовать физический снимок в электронный. Цель сканирования может быть разной. Иногда надо скинуть фотографии другому человеку по электронной почте или другим способом. Но более актуальным сканирование будет в случае необходимости сохранение старых фотографий. Со временем бумага меняет свойства, износится, желтеет. Чтобы сохранить фото еще на очень долгое время, можно сделать скан снимка на компьютер. Электронный файл не подвержен износу. К тому же, при сканировании можно выставить параметры, которые могут улучшить качество фотографии – осветлить или затемнить, сделать более или менее контрастной. Если присутствует пятна или дефекты, фото в электронном формате можно отредактировать в разных программах для работы с графикой.
Отсканировать фото на компьютер можно через сканер или принтер, а, точнее, многофункциональное устройство (МФУ), которое включает в себя сразу три устройства – печатающее, сканирующее и копирующее (ксерокс). Оцифровка возможна стандартными средствами операционной системы Windows 7-10 или дополнительно установленными программами (сторонними или официальными от производителей).
Подготовка к сканированию
Чтобы сканировать фотографии или другие носители нужно:
-
Убедиться в том, что устройство может выполнять функцию сканирования. С самостоятельным сканером вопросов не возникает, так как он для этого и предназначен. А вот принтер сам по себе не сканирует. В последнем случае важно, чтобы аппарат был многофункциональным, то есть быть принтером 3 в 1 – содержать в себе одновременно сканер, принтер и копир. Убедиться в этом можно из документации к технике или просто попытаться поднять верхнюю крышку. Если под ней есть стекло, тогда сканирование, равно как и ксерокопирование, может осуществляться.
Чтобы не возникало проблем с работой любой функции МФУ, лучше всего сразу устанавливать полный пакет драйверов вместе с фирменным ПО. Так, могут установиться несколько программ – отдельно для печати, сканирования и копирования.
Сканирование через стандартное средство Windows
Подымите крышку устройства. Положите сканируемое фото на стекло, ориентируясь на направляющую стрелку, которая указывает, где должна располагаться верхняя часть бумаги. Фото должно лежать лицевой стороной вниз.


Найдите значок нужного аппарата. Если устройство готово к работе, то значок не будет слегка прозрачным и возле себя не содержит никаких знаков предупреждения.

Откроется встроенный в Windows мастер работы со сканером. В окне настраиваются параметры, которые влияют на процесс сканирования и конечное качество цифровой копии фотографии.

В зависимости от выставленного качества создание скана может занимать разное время, от нескольких секунд до минуты и более.




Другие стандартные программы
В Windows версий 7-10 есть другой встроенный софт, который позволяет сделать скан.
Paint
Многие привыкли использовать стандартный графический редактор Paint только для простого оформления картинок или подписей. Но внутри программы есть функция получения изображения.

Сделайте базовые настройки.


Сделайте предварительный просмотр, а после отсканируйте. Скан появится в виде изображения в открытом окне Paint.

Даже если изначально фото было неправильно уложено внутри сканера, в редакторе доступен поворот. Также можно сделать подписи текстом, изменить размер и другое.
Но для редактирования рекомендуется использовать инструменты более продвинутых редакторов фото.

Выберите формат, который обеспечит наилучшее качество – BMP или PNG. JPG тоже даст хорошее качество, но в сравнении с предыдущими форматами недотягивает, размер, естественно, будет меньше.
Программы от разработчиков
Производители дополнительно к стандартному пакету ПО предлагают утилиты. Внутренний интерфейс может отличаться, но интуитивно понятен. Перечень параметров также практически всегда одинаковый.
Софт устанавливается либо сразу с драйверами, либо отдельно через запуск установочного файла на диске. Все программы доступны для загрузки с официальных ресурсов компаний.
- HP Scan. Программы от компании лидера на рынке печатающей техники Hewlett-Packard. По интерфейсу практически идентична стандартной утилите сканирования в Windows.
- Epson Scan. Как и предыдущее ПО, разработано брендом Epson для работы со своими продуктами. Настройки таки же, интерфейс прост даже для новичка в пользовании ПК.
Сторонние программы
Если необходимо более гибко настраивать сканер и управляться с полученным документом, например, сразу отправлять файл по E-mail, тогда предлагается воспользоваться специализированными программами для сканирования.
ABBYY FineReader
Программа известна и широко используется благодаря встроенному функционалу, позволяющему распознавать текст и таблицы с изображений. Есть несколько версий программы, которые отличаются возможностями, Цена за каждую версию разная, а стоимость максимального пакета превышает 30 тыс. р.
Обладает как достоинствами, так и недостатками. Для обычного сканирования покупать софт нет смысла. Больше пригодится для профессиональной работы. Также позволяет сканировать в PDF из нескольких листов.
VueScan

Известное приложение, которое рекомендуют даже производители техники. Если нужно гибко и настраивать качество, тогда софт то, что необходимо. Программа поддерживает работу большинства марок, моделей многофункциональных и сканирующих устройств. Имеет встроенную функцию оптического распознавания символов – преобразования изображения в текст.
Сканер CuneiForm

Бесплатная программа, которая доступна для скачивания на официальном сайте разработчика OpenOCR. Имеет минимальные системные требования, не грузит компьютер и быстро работает.
ScanPapyrus
Программа позволяет значительно ускорить сканирование за счет выбора ограниченной области обработки. Например, если считывается фотография размером 10x15, то нет необходимости выполнять сканирование всей области. В настройках можно выставить нужный размер и сканирование пройдет быстрее. Для фото 10 на 15 больше всего подходит размер А6.

Откройте крышку сканера и ориентируясь на разметку, положите фото в нужное место. На корпусе могут быть отметки, которые указывают, какой размер бумаги кладется в конкретную область.
Если подобных отметок нет, то фотографию необходимо класть в угол, где находится стрелка (указывает начало хода сканера).





Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.
ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк). Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети! Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
3.1 Текст
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-07-33](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-07-33.jpg)
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
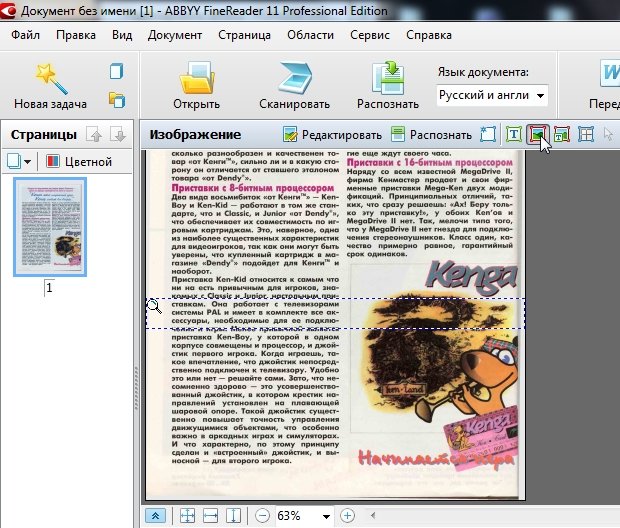
3.3 Таблицы
![]()
3.4 Ненужные элементы
Для этого переходим в режим редактирования изображения.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-11](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-11.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-21.jpg)
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-19-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-19-21.jpg)
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
Во-первых, нужна проверка документа!
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-24-08](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-24-08.jpg)
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…
Читайте также: