
Как сделать регулярное выражение
Добавил пользователь Валентин П. Обновлено: 04.10.2024
Многие сайты, стремясь получить как можно больше информации о своих посетителях, предлагают пройти авторизацию. Как правило, от пользователя в таких случаях необходим e-mail и личный пароль. Что же происходит с этими данными дальше?
Информация поступает на сервер, где обрабатывается при помощи специального кода. Однако часто при некорректно введенных пользовательских данных, код не может обработать информацию и выдает ошибку. Поэтому для проверки адресов электронной почты и другой текстовой информации используются регулярные выражения.
Регулярные выражения представляют собой способ поиска совпадений шаблона с текстом. Такой шаблон поиска может состоять как из отдельного символа, так и более сложных символьных комбинаций и выражений, необходимых для сопоставления с оригинальным текстом. Для поиска используется строка-образец (шаблон/pattern), которая состоит из метасимволов, задающих правило поиска.
Например:
- /example/i — регулярное выражение;
- example — шаблон для поиска;
- i — модификатор, не учитывающий при поиске регистр. Могут использоваться также модификаторы g — глобальное сопоставление (находит все совпадения, не останавливаясь после первого) и m — многострочное сопоставление.
Для работы с регулярными выражениями в Java импортируется пакет java.util.regex с классами, которые помогают сопоставлять последовательности символов с шаблонами. Внутри — три основных класса:
- Pattern — скомпилированное представление регулярного выражения.
- Matcher — выполняет операции сопоставления с последовательностью символов путем интерпретации файла Pattern.
- PatternSyntaxException — является исключением, не выполняет проверку, но указывает на синтаксическую ошибку в шаблоне регулярного выражения.
Регулярные выражения имеют довольно широкую область применения. Они могут использоваться при поиске и замене текста, редактировании и управлении данными, распознавании номеров телефонов, e-mail адресов, имен пользователей (на кириллице и латинице), сопоставлении текста с рисунком, проверке ввода веб-форм, фильтровании информации и многом другом.
Как создать регулярное выражение
Существует два способа создания регулярного выражения:
- При помощи литерала (фиксированного значения). При анализе скрипта литералы вызывают регулярное выражение. Способ используется при постоянном регулярном выражении и позволяет увеличить производительность.
Например:
- Используя конструктор объектаRegExp. Компиляция регулярного выражения происходит во время выполнения скрипта. Способ стоит использовать при изменяемом регулярном выражении.
Например:
Как создать шаблон регулярного выражения
Чтобы быстро освоить регулярные выражения, можно воспользоваться генератором регулярных выражений , например, regex101.
Чтобы создать самое простое регулярное выражение, необходимо выбрать JavaScript в левой колонке Flavor и отключить флаги multi line и global.
Например: введите в поле регулярного выражения слово map, а в тестовую строку map, cap, maps, dap, sap, MAP, lap, map, rap, tap, zap.
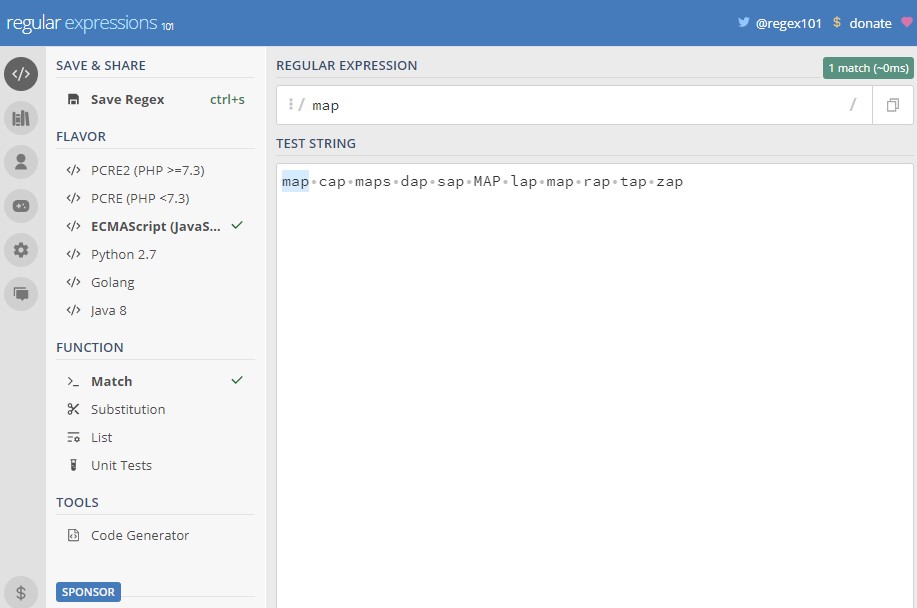
Регулярные выражения в Java находятся всегда между знаками / – /map/.
Как видим, некоторые строки в тестовой строке не совпадают. Это происходит потому, что регулярное выражение по умолчанию возвращает только первое найденное совпадение. Чтобы нашлись все совпадения, необходимо включить флаг global (g). Стоит обратить внимание, что шаблоны регулярных выражений учитывают регистр, потому следует также выбрать флаг insensitive (i).
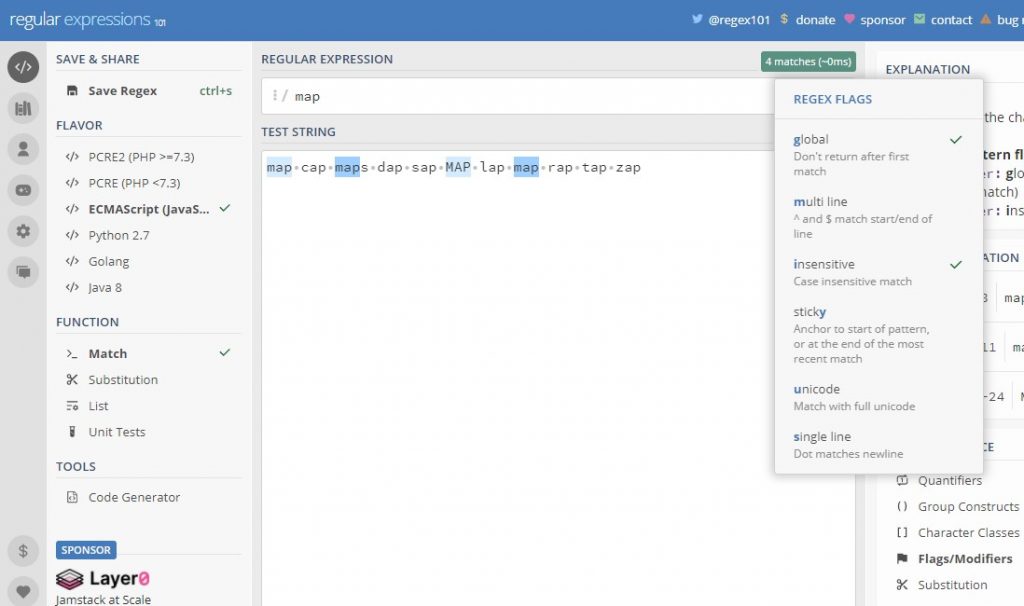
Регулярное выражение теперь имеет вид /map/gi
Регулярное выражение теперь имеет вид /map/gi, а в тестовой строке найдены все совпадения, в том числе в верхнем регистре.
Чтобы сопоставить слова map, cap, rap, необходимо расширить написание регулярного выражения и использовать наборы символов, поместив их в квадратные скобки []. Так, [mcr]ap будет соответствовать строкам:
![[mcr]ap будет соответствовать этим строкам](https://highload.today/wp-content/uploads/2021/06/image3.jpg)
[mcr]ap будет соответствовать этим строкам
![Использование диапазона [a-z]ap](https://highload.today/wp-content/uploads/2021/06/image1.jpg)
Использование диапазона [a-z]ap
Использование специальных символов
Специальные символы используются для написания более сложных регулярных выражений. Они необходимы в тех случаях, когда стоит задача найти пробелы, повторяющиеся символы. Ниже предоставлен полный список таких символов.
Специальные символы регулярных выражений
● /\bbloo/ соответствует bloo в слове blood;
Работа с регулярными выражениями
В JavaScript регулярные выражения используются в методах: exec, test, match, search, replace, split.
Методы, которые используют регулярные выражения
| exec | При совпадении в строке возвращает массив и обновляет regexp. |
| test | Производит тестирование совпадений в строке. Может быть true или false. |
| match | Выполняет поиск совпадений. Возвращает массив, содержащий результаты этого поиска. |
| search | Производит тестирование совпадений в строке. Возвращает позицию первого символа в найденной строке. Если соответствие не найдено, вернет значение -1. |
| replace | Выполняет поиск совпадений в строке. Ищет строку для регулярного выражения и возвращает новую с измененными указанными значениями. |
| split | Выполняет разбиение строки с регулярным выражением в массив по указанному разделителю. |
Методы test и search позволяют узнать, есть ли в строке соответствия шаблону регулярного выражения. Для получения более полной информации используют методы exec и match.
Приведем в пример поиск совпадения в строке с использованием метода exec. Скрипт выглядит так:
Какими могут быть результаты выполнения регулярных выражений — рассмотрим в таблице ниже.
Результаты выполнения регулярного выражения
| Объект | Индекс | Описание | Пример |
| myArray | Содержимое myArray. | [“tbbn”, “bn”] | |
| index | Индекс совпадения. Как правило, начинается с нуля. | 2 | |
| input | Исходная строка. | btbbndddpe | |
| [1], …[n] | Совпадения во вложенных скобках. Количество скобок может быть неограниченно. | [1] = bn |
Флаги регулярных выражений
В регулярных выражениях могут применяться специальные флаги. Они влияют на поиск.
| Флаг | Описание |
| i | Осуществляется поиск без привязки к регистру. Найдет соответствия в верхнем и нижнем регистрах (D и d). |
| g | Глобальный поиск. Осуществляется поиск всех совпадений, а не только первого. |
| m | Многострочный поиск. Влияет на символы ^ (поиск совпадений в начале строки) и $ (поиск совпадений в конце строки). |
| y | Поиск по заданной позиции в исходной строке. |
| u | Поддержка Unicode. |
| s | Поиск любого символа, включая перенос строки \n. |
Флаги в шаблонах регулярных выражений используются с помощью синтаксисов:
Флаги указываются после шаблона/паттерна.
Примеры использования регулярных выражений
Проверка e-mail
Как проверить, действителен ли адрес электронной почты, введенный пользователем в соответствующее поле на сайте?
Регулярное выражение, которое соответствует любому e-mail адресу:
Проверка телефонных номеров
Этот пример может применяться для проверки любого телефонного номера:
Проверка телефонного номера с кодом конкретной страны (например, Украины):
Проверка строки с адресом видео на YouTube
Подходит для всех URL-адресов на YouTube:
Проверка формата URL
Проверка текста на повторяющиеся слова
Поиск соответствий на повторяющиеся слова:
\b — это граница слова, а \1 — ссылка на зафиксированное совпадение (первое слово).
Синтаксис поисковых запросов Google
Проверка имени пользователя
Проверка надежности паролей
Чтобы создать надежный пароль, необходимо придерживаться некоторых стандартов — использовать помимо букв и цифр другие символы в разных регистрах, а также спецзнаки. Это регулярное выражение уже содержит необходимые требования для проверки надежности паролей:
Проверка номера кредитной карты
С помощью регулярных выражений можно исключить номера платежных карт, в которых содержатся умышленные или случайные ошибки, неправильные последовательности введенных цифр:
Проверка цен
Цены имеют множество представлений и форматов. Единого регулярного выражения для них не существует. Приведем пример выражения для извлечения из текста цен в долларовом эквиваленте:
где — комбинация, которая указывает на то, что символ из 6 должен повториться дважды (дробная часть цены).
Внимание! Регулярные выражения имеют в своем арсенале специальные символы, которые в обязательном порядке необходимо экранировать. В этот список входят: . ^ $ * + ? < >[ ] \ | ( ). Перед каждым таким символом необходимо добавлять обратный слэш \.
Сервисы и приложения для проверки регулярных выражений
Чтобы не писать код с нуля, существуют специальные онлайн-инструменты, которые позволяют протестировать уже написанные регулярные выражения или используются для тренировки.
Один из лучших сервисов по созданию регулярных выражений. Позволяет сгенерировать и получить ссылку на код для JavaScript, PHP, Python. Содержит огромную библиотеку уже готовых шаблонов регулярных выражений.
Удобный онлайн-тестер для выполнения простых задач. Не генерирует код, но поддерживает замену по шаблону.
Десктопная программа с рядом преимуществ. Содержит большую библиотеку шаблонов, может генерировать код. Для удобства работа осуществляется в визуальном редакторе.
Плагин для IDE. Поддерживает замены и разделения по шаблону, включает в себя подсказки и описания используемых элементов. Не сохраняет регулярные выражения, но прекрасно подходит для их проверки перед тем, как добавить в код.

Конечно, можно делать итерации с каждым словом или элементом во всех этих строках. Вероятно, вы даже можете представить, какой код вы бы использовали для этого. Но в больших приложениях это может стать слишком дорогостоящей задачей.
Что такое регулярные выражения
Давайте быстро (и не слишком углубляясь в информатику) определимся с тем, что такое регулярные выражения.
- Регулярные выражения это способы описания регулярного языка.
- Регулярный язык это формальный язык, который может быть описан конечным автоматом.
Есть много лучших пояснений того, что такое регулярные языки, так что если приведенное здесь определение вас не удовлетворяет, просто погуглите пару минут.
Учимся писать регулярные выражения
Аналогичный подход можно применять к цифрам: \d.
Пример 1
То, что мы можем посмотреть, соответствуют ли какие-то элементы строки заданному шаблону, это, конечно, хорошо. Но где это может быть полезно?
Для поиска соответствий наш бот будет использовать шаблон /Джош/.
Это возможно. Но для начала нам нужно кое-что изучить. Начнем с квантификаторов.

Регулярные выражения помогут найти иголку в стогу сена.
Квантификаторы (указатели количества вхождений символов)
0 или много
1 или много
Шаблоны (специальные символы)
С помощью шаблонов!
Шаблоны могут заменять собой буквально любой символ (или даже много символов). Синтаксически это обозначается точкой. Да, просто точкой. Не путайте с точкой в конце предложения.
Группировка символов
Группы символов это блоки символов, по порядку располагающиеся в строке. Когда вы используете * или +, это указывает на количество вхождений не просто последнего символа, после которого стоит квантификатор, а последней группы символов.
Группы полезны сами по себе, но они могут стать очень мощным инструментом в сочетании с повторяющимися символами. Определить группу символов можно с помощью круглых скобок (вот этих).
Группы символов также являются средством запоминания частей строки. С их помощью мы можем добавлять части строки в переменные нашего кода, когда видим, что строка совпадает с шаблоном.
Для этого обычно вам нужно будет использовать что-то вроде \1 – это соответствует первой определенной группе.
Возможно, это одна из самых полезных функций регулярных выражений в программировании.

Пример 2
Ффухх! Давайте теперь продолжим нашу историю с чат-ботом и используем то, чему мы научились, чтобы определить, кто вспоминает Джоша.
В этом выражении мы видим:
В Python это регулярное выражение может выглядеть так:
Обратите внимание: мы использовали .group(1) так же, как ранее использовали \1 в шаблоне регулярного выражения. Здесь нет ничего нового за исключением того, что это использование regex именно в Python.
Начало и конец
Аналогично, $ может использоваться для обозначения конца строки.
Перечисление символов
Допустим, вы пишете regex, напоминающий сандвич. Вы не знаете, захочет ли клиент пшеничный хлеб или ржаной, вам любой подойдет. Как добавить возможность выбора в регулярное выражение? С помощью перечисления символов!

Модификаторы (флаги)
До сих пор мы говорили о шаблоне внутри /слэшей/, верно? Но что располагается за их пределами?
Слева – ничего интересного. А вот справа может быть кое-что очень полезное. Просто позор, что до сих пор мы это игнорировали!
Модификаторы изменяют правила применения регулярных выражений.
Например, до сих пор все наши примеры были чувствительными к регистру. Это значит, что изменение регистра любого символа приведет к несовпадению с шаблоном. Но добавив модификатор i, мы можем сделать наш шаблон нечувствительным к регистру.
Остальные модификаторы я оставлю вам для самостоятельного разбора, замечу лишь, что в целом чаще всего используется igm.
Что дальше?
Надеюсь эта статья продемонстрировала вам, как можно более изощренно взаимодействовать со строками. Конечно, это лишь прикосновение к regexs, но вы уже сможете составить регулярное выражение для каких-то простых задач.
В регулярных выражениях используется множество символов / токенов. Скорее всего вы будете натыкаться на них на Stack Overflow. Иногда их значение можно угадать, исходя из своего предыдущего опыта (например, \n это символ новой строки). Но в любом случае, остается еще много для изучения.
Просмотреть полный список токенов и протестировать свое регулярное выражение можно здесь. Я все еще пользуюсь этим сайтом при написании regexs, потому что у них очень полезный и мощный инструмент тестирования. Он даже может сгенерировать для вас код, если вы еще не уверены, как это делать в вашем языке программирования.
А если все написанное здесь для вас легкотня, обратите внимание на regex-кроссворды. Уж они заставят вас мыслить регулярными выражениями!
Спецсимволы
Спецсимволы внутри символьного класса
Позиция внутри строки
| Позиция | Пример | Соответствие | Описание |
|---|---|---|---|
| ^ | ^a | aaa aaa | начало строки |
| $ | a$ | aaa aaa | конец строки |
| \A | \Aa | aaa aaa aaa aaa | начало текста |
| \z | a\z | aaa aaa aaa aaa | конец текста |
| \b | a\b \ba | aaa aaa aaa aaa | граница слова, утверждение: предыдущий символ словесный, а следующий - нет, либо наоборот |
| \B | \Ba\B | aaa aaa | отсутствие границы слова |
| \G | \Ga | aaa aaa | Предыдущий успешный поиск, поиск остановился на 4-й позиции — там, где не нашлось a |
Якоря
Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид:
Здесь символ ^ обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \d соответствует любой цифре от 0 до 9 включительно, \w соответствует буквам и цифрам, а \W — всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит так:
POSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Кванторы
Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
Приведенный выше шаблон найдет в этой строке вот такую подстроку:
Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание на модификатор ? ) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных кавычках по отдельности:
Экранирование в регулярных выражениях
Шаблон для нахождения точки таков:
Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
| Выражение | Соответствие |
|---|---|
| \ | не соответствует ничему, только экранирует следующий за ним символ. Это нужно, если вы хотите ввести метасимволы !$()*+.<>?[\]^ <|>в качестве их буквальных значений. |
| \Q | не соответствует ничему, только экранирует все символы вплоть до \E |
| \E | не соответствует ничему, только прекращает экранирование, начатое \Q |
Подстановка строк
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
Первым параметром будет примерно такой шаблон (возможно вам понадобятся несколько дополнительных символов для этой конкретной функции):
Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква и не цифра), отмечая его $1 . Без этого мы бы просто удалили этот символ из текста. То же касается конца подстановки ( $3 ). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы можете использовать CSS или ), выделив им вторую группу, найденную по шаблону ( $2 ).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера. Например, модификатор i заставляет парсер игнорировать регистры.
Модификаторы добавляются в конец этой строки, вот так:
Мета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
Регулярные выражения - удобный способ описывать шаблоны текстов.
С помощью регулярных выражений вы можете проверять пользовательский ввод, искать некоторые шаблоны, такие как электронные письма телефонных номеров на веб-страницах или в некоторых документах и так далее.
Ниже приведена исчерпывающая шпаргалка по регулярных выражениям всего на одной странице.
Символы¶
Простые совпадения¶
Серия символов соответствует этой серии символов во входной строке.
| RegEx | Находит |
|---|---|
| foobar | foobar |
Непечатные символы (escape-коды)¶
Для представления непечатаемого символа в регулярном выражении используется \x с шестнадцатеричным кодом. Если код длиннее 2 цифр (более U+00FF), то он обрамляется в фигурные скобки.
| RegEx | Находит |
|---|---|
| \xAB | символ с 2-значным шестнадцатеричным кодом AB |
| \x | символ с 1-4 значным шестнадцатеричным кодом AB20 |
| foo\x20bar | foo bar (обратите внимание на пробел в середине) |
Существует ряд предопределенных escape-кодов для непечатных символов, как в языке C :
Эскейпинг¶
Для представления спецсимволов ( .+*?|\()[]<>^$ ), перед ними надо поставить \ . Чтобы вставить сам обратный слэш его надо удвоить.
| RegEx | Находит |
|---|---|
| \^FooBarPtr | ^FooBarPtr здесь ^ не означает начало строки |
| \[a\] | [a] это не класс символов |
Классы символов¶
Пользовательские классы¶
Символьный класс - это список символов внутри [] . Класс соответствует любому одному символу, указанному в этом классе.
| RegEx | Находит |
|---|---|
| foob[aeiou]r | foobar , foober и т. д., но не foobbr , foobcr и т. д. |
Вы можете инвертировать класс - если первый символ после [ является ^ , то класс соответствует любому символу, кроме символов, перечисленных в классе.
| RegEx | Находит |
|---|---|
| foob[^aeiou]r | foobbr , foobcr и т. д., но не foobar , foober и т. д. |
Внутри списка символ - используется для указания диапазона, так что a-z представляет все символы между a и z включительно.
Если вы хотите, чтобы - сам был членом класса, поместите его в начало или конец списка или предварите его обратной косой чертой (escape).
Если вы хотите буквально использовать символ ] поместите его в начало списка или escape обратной косой чертой.
Метаклассы¶
Существует ряд предопределенных классов символов, которые делают регулярные выражения более компактными. Их называют метаклассы:
Все указанные в таблице метаклассы можно использовать внутри пользовательских классов.
| RegEx | Находит |
|---|---|
| foob\dr | foob1r , foob6r и т. д., но не foobar , foobbr и т. д. |
| foob[\w\s]r | foobar , foob r , foobbr и т. д., но не foob1r , foob=r и т. д. |
Свойства SpaceChars и WordChars определяют, какие символы входят в классы \w , \W , \s , \S .
Таким образом, вы можете переопределить эти классы.
Разделители¶
Разделители строк¶
| Метасимвол | Находит |
|---|---|
| . | любой символ в строке, может включать разделители строк |
| ^ | совпадение нулевой длины в начале строки |
| $ | совпадение нулевой длины в конце строки |
| \A | совпадение нулевой длины в начале строки |
| \z | совпадение нулевой длины в конце строки |
| \Z | похож на \z но совпадает перед разделителем строки, а не сразу после него, как \z |
| RegEx | Находит |
|---|---|
| ^foobar | foobar только если он находится в начале строки |
| foobar$ | foobar , только если он в конце строки |
| ^foobar$ | foobar только если это единственная строка в строке |
| foob.r | foobar , foobbr , foob1r и так далее |
Метасимвол ^ совпадает с точкой начала строки (нулевой длины). $ - в конце строки. Если включен modifier /m , они совпадают с началами или концами строк внутри текста.
Обратите внимание, что в последовательности \x0D\x0A нет пустой строки.
Если вы используете Unicode версию, то ^ / $ также соответствует \x2028 , \x2029 , \x0B , \x0C или \x85 .
Метасимвол \A совпадает с точкой нулевой длины в начале строки, \z - в конце (после символов завершения строки). Модификатор modifier /m на них не влияет. \Z тоже самое что \z но совпадает с точкой перед символами завершения строки (LF and CR LF).
Метасимвол . по умолчанию соответствует любому символу, но если вы выключите modifier /s, то . не будет совпадать с разделителями строк внутри строки.
Обратите внимание, что выражение ^.*$ не соответствует точке между \x0D\x0A , потому что это неразрывный разделитель строк. Но оно соответствует пустой строке в последовательности \x0A\x0D , поэтому из-за неправильного порядка кодов он не воспринимается как разделитель строк и считается просто двумя символами.
Многострочная обработка может быть настроена с помощью свойств LineSeparators и LinePairedSeparator.
Таким образом, вы можете использовать разделители стиля Unix \n или стиль DOS / Windows \r\n или смешивать их вместе (как описано выше по умолчанию).
Разделители слов¶
| RegEx | Находит |
|---|---|
| \b | разделитель слов |
| \B | разделитель с не-словом |
Граница слова \b - это точка между двумя символами, у которой \w с одной стороны от нее и \W с другой стороны (в любом порядке).
Повторы¶
Повтор¶
За любым элементом регулярного выражения может следовать допустимое число повторений элемента.
| RegEx | Находит |
|---|---|
| ровно n раз | |
| по крайней мере n раз | |
| по крайней мере n , но не более чем m раз | |
| * | ноль или более, аналогично |
| + | один или несколько, похожие на |
| ? | ноль или единица, похожая на |
То есть цифры в фигурных скобках определяются минимальное n и максимальное m количество повторов (совпадений во входном тексте).
эквивалентно и означает точно n раз . совпадает n или более раз.
Теоретически значение n и m не ограничены (можно использовать максимальное значение для 32-х битного числа).
| RegEx | Находит |
|---|---|
| foob.*r | foobar , foobalkjdflkj9r и foobr |
| foob.+r | foobar , foobalkjdflkj9r , но не foobr |
| foob.?r | foobar , foobbr и foobr , но не foobalkj9r |
| foobar | foobaar |
| foobar | foobaar , foobaaar , foobaaaar и т. д. |
| foobar | foobaar , или foobaaar , но не foobaaaar |
| (foobar) | 8 , 9 или 10 экземпляров foobar ( () это Группа) |
Жадность¶
Повторы в жадном режиме захватывают как можно больше из входного текста, в не жадном режиме - как можно меньше.
По умолчанию все повторы являются жадными . Используйте ? Чтобы сделать любой повтор не жадным .
Для строки abbbbc :
| RegEx | Находит |
|---|---|
| b+ | bbbb |
| Ь+? | b |
| b*? | пустую строку |
| b? | bb |
| b | bbb |
Вы можете переключить все повторы в не жадный режим (modifier /g, ниже мы используем in-line модификатор change).
| RegEx | Находит |
|---|---|
| (?-g)Ь+ | b |
Сверхжадные повторы (Possessive Quantifier)¶
Синтаксис: a++ , a*+ , a?+ , a+ . В настоящее время реализован только для простых групп и не будет работать для сложны, как например (foo|bar)+ .
Полное описание (на английском) Вкратце, сверхжадный повтор ускоряет работу в сложных случаях.
Альтернативы¶
Выражения в списке альтернатив разделяются | .
Таким образом, fee|fie|foe будет соответствовать любому из fee , fie или foe (также как и f(e|i|o)e ).
Первое выражение включает в себя все от последнего разделителя шаблона ( ( , [ или начало шаблона) до первого | , а последнее выражение содержит все от последнего | к следующему разделителю шаблона.
Звучит сложно, поэтому обычной практикой является заключение списка альтернатив в скобки, чтобы минимизировать путаницу относительно того, где он начинается и заканчивается.
Выражения в списке альтернатив пробуются слева направо, принимается первое же совпадение.
Например, регулярное выражение foo|foot в строке barefoot будет соответствовать foo - первое же совпадение.
Также помните, что | в квадратных скобках воспринимается просто как символ, поэтому, если вы напишите [fee|fie|foe] , это тоже самое что [feio|] .
| RegEx | Находит |
|---|---|
| foo(bar|foo) | foobar или foofoo |
Группы (подвыражения)¶
Скобки (. ) также могут использоваться для определения групп (подвыражений) регулярного выражения.
Позиция, длина и фактические значения подвыражений будут в MatchPos, MatchLen и Match.
Вы можете заменить их с помощью функции Substitute.
Подвыражения нумеруются слева направо по открывающим их скобкам (включая вложенные группы (подвыражения). У первой группы номер 1. У выражения в целом - 0.
Например, для входной строки foobar регулярное выражение (foo(bar)) найдет:
| Группы (подвыражения) | значение |
|---|---|
| 0 | foobar |
| 1 | foobar |
| 2 | bar |
Ссылки на группы (Backreferences)¶
Метасимволы от \1 до \9 интерпретируются как ссылки на группы (подвыражения в () ). \n соответствует ранее найденному подвыражению n .
| RegEx | Находит |
|---|---|
| (.)\1+ | aaaa и cc |
| (.+)\1+ | также abab и 123123 |
(['"]?)(\d+)\1 соответствует "13" (в двойных кавычках) или '4' (в одинарных кавычках) или 77 (без кавычек) и т. д.
Именованные группы (подвыражения) и ссылки на них¶
Чтобы присвоить имя группе используйте (?P expr) или (?'name'expr) .
Имя группы должно начинаться с буквы или _ , далее следуют буквы, цифры или _ . Именованные и не именованные группы имеют общую нумерацию от 1 до 9 .
Чтобы сослаться на именованную группу используйте (?P=name) . Или, как и для не именованных, цифры от \1 до \9 .
| RegEx | Находит |
|---|---|
| (?P ['"])\w+(?P=qq) | "word" и 'word' |
Модификаторы¶
Модификаторы предназначены для изменения поведения регулярных выражений.
Вы можете установить модификаторы глобально в вашей системе или изменить их внутри регулярного выражения, используя (?imsxr-imsxr).
Для изменения модификаторов используйте ModifierStr или соответствующие TRegExpr свойства Модификатор *.
Значения по умолчанию определены в глобальных переменных. Скажем, глобальная переменная RegExprModifierX определяет значение по умолчанию для свойства ModifierX .
i, без учета регистра¶
Регистро-независимые сравнения. Использует установленные в вашей системе языковые настройки, см. также InvertCase.
m, многострочные строки¶
Обрабатывать строку как несколько строк. Таким образом, ^ и $ соответствуют началу или концу любой строки в любом месте строки.
s, одиночные строки¶
Обрабатывать строку как одну строку. Так что . соответствует любому символу, даже разделителям строк.
Смотрите также Разделители строк, которые обычно не совпадают.
г, жадность¶
Специфичный для TRegExpr модификатор.
Отключив его Off , вы переключите повторитель в не-жадный режим.
Итак, если модификатор /g имеет значение Off , то + работает как +? , * как *? и так далее.
По умолчанию этот модификатор имеет значение Выкл .
x, расширенный синтаксис¶
Позволяет комментировать регулярные выражения и разбивать их на несколько строк.
Если модификатор включен, мы игнорируем все пробелы, которые не заэскейплены обратной косой чертой, и не включены в класс символов.
Обратите внимание, что вы можете использовать пустые строки для форматирования регулярного выражения для лучшей читаемости:
г, русские диапазоны¶
Специфичный для TRegExpr модификатор.
В русской таблице ASCII символы ё / Ё размещаются отдельно от других.
Большие и маленькие русские символы находятся в отдельных диапазонах, это не отличается от ситуации с английскими символами, но, тем не менее, я хотел иметь краткую форму.
С этим модификатором вместо [а-яА-ЯёЁ] вы можете написать [а-Я] , если вам нужны все русские символы.
Когда модификатор включен:
| RegEx | Находит |
|---|---|
| а-я | символы от а до я и ё |
| А-Я | символы от А до Я и Ё |
| а-Я | все русские символы |
Модификатор по умолчанию установлен на Вкл .
Проверки или заглядывания вперед и назад (Assertions)¶
Не захватываемые группы (подвыражения)¶
У этих групп (подвыражений) нет номера, их нельзя указать в ссылке на группу. Эти группы используют чтобы за счет группировки сделать регулярное выражение более читаемым, но нет необходимости расходовать ресурсы на то, чтобы реально отдельно захватывать то, с чем такие группы совпадут:
Атомарные группы¶
Атомарные группы это специальный случай незахватывающих групп. Подробнее
Модификаторы¶
Синтаксис для одного модификатора: (?i) чтобы включить, и (?-i) чтобы выключить. Для большого числа модификаторов используется синтаксис: (?msgxr-imsgxr) .
Можно использовать внутри регулярного выражения. Это может быть особенно удобно, поскольку оно имеет локальную область видимости. Оно влияет только на ту часть регулярного выражения, которая следует за оператором (?imsgxr-imsgxr) .
И если оно находится внутри подвыражения, оно будет влиять только на это подвыражение, а именно на ту часть подвыражения, которая следует за оператором. Таким образом, в ((?i)Saint)-Petersburg это влияет только на подвыражение ((?i)Saint) , поэтому оно будет соответствовать saint-Petersburg , но не saint-petersburg .
| RegEx | Находит |
|---|---|
| (?i)Saint-Petersburg | Saint-petersburg и Saint-Petersburg |
| (?i)Saint-(?-i)Petersburg | Saint-Petersburg , но не Saint-petersburg |
| (?i)(Saint-)?Petersburg | Saint-petersburg и saint-petersburg |
| ((?i)Saint-)?Petersburg | saint-Petersburg , но не saint-petersburg |
Комментарии¶
Обратите внимание, что комментарий закрывается ближайшим ) , поэтому нет способа вставить литерал ) в комментарий.
Рекурсия¶
Синтаксис (?R) , синоним (?0) .
Если же обрамляемый текст также может встречаться без обрамления то выражение будет b(?R)*e|m .
Вызовы подвыражений¶
Нумерованные группы (подвыражения) обозначают (?1) … (?90) (максимальное число групп определяется константой в TRegExpr).
Синтаксис для именованных групп : (?P>name) . Поддерживается также Perl вариант синтаксиса: (?&name) .
Это похоже на рекурсию, но повторяет только указанную группу (подвыражение).
Unicode категории (category)¶
- Cc - Control
- Cf - Формат
- Co - Частное использование
- Cs - Заменитель (Surrrogate)
- Ll - Буква нижнего регистра
- Lm - Буква-модификатор
- Lo - Прочие буквы
- Lt - Titlecase Letter
- Lu - Буква в верхнем регистре
- Mc - Разделитель
- Me - Закрывающий знак (Enclosing Mark)
- Mn - Несамостоятельный символ, как умляут над буквой (Nonspacing Mark)
- Nd - Десятичная цифра
- Nl - Буквенная цифра - например, китайская, римская, руническая и т.д. (Letter Number)
- No - Другие цифры
- Pc - Connector Punctuation
- Pd - Dash Punctuation
- Pe - Close Punctuation
- Pf - Final Punctuation
- Pi - Initial Punctuation
- Po - Other Punctuation
- Ps - Open Punctuation
- Sc - Currency Symbol
- Sk - Modifier Symbol
- Sm - Математический символ
- So - Прочие символы
- Zl - Разделитель строк
- Zp - Разделитель параграфов
- Zs - Space Separator
Метасимвол \p это один символ указанной Unicode категории (category). Синтаксис: \pL или \p если категория обозначается одним символом, \p для 2-символьных категорий.
Метасимвол \P это символ не из Unicode категории (category).
Эти метасимволы также поддерживаются внутри пользовательских классов.
Послесловие¶
В этой древней статье из прошлого века есть примеры использования регулярных выражений.
Читайте также: