
Как сделать распределенное хранилище
Обновлено: 05.07.2024
А распределенное хранилище данных это компьютерная сеть где информация хранится более чем на одном узел, часто в воспроизведен мода. [1] Обычно он специально используется для обозначения распределенная база данных где пользователи хранят информацию о количество узлов, или компьютерная сеть в котором пользователи хранят информацию о количество одноранговых сетевых узлов.
СОДЕРЖАНИЕ
Распределенные базы данных
Распределенные базы данных обычно нереляционные базы данных которые обеспечивают быстрый доступ к данным на большом количестве узлов. Некоторые распределенные базы данных предоставляют широкие возможности запросов, в то время как другие ограничены хранилище ключей и значений семантика. Примеры ограниченных распределенных баз данных: Googleс Большой стол, что намного больше, чем просто распределенная файловая система или одноранговая сеть, [2] Amazonс Динамо [3] и Хранилище Microsoft Azure. [4]
Поскольку возможность произвольных запросов не так важна, как доступностьразработчики распределенных хранилищ данных увеличили последнее за счет согласованности. Но высокоскоростной доступ для чтения / записи приводит к снижению согласованности, поскольку невозможно иметь и то, и другое. последовательность, доступность и устойчивость к разделению сети, как это было доказано CAP теорема.
Хранилища данных одноранговых сетевых узлов
В одноранговых сетевых хранилищах данных пользователь обычно может отвечать взаимностью и разрешать другим пользователям также использовать свой компьютер в качестве узла хранения. Информация может быть доступна или недоступна другим пользователям в зависимости от конструкции сети.
Наиболее пиринговый сети не имеют распределенных хранилищ данных, поскольку данные пользователя доступны только тогда, когда их узел находится в сети. Однако это различие несколько размыто в такой системе, как BitTorrent, где исходный узел может перейти в автономный режим, но контент будет продолжать обслуживаться. Тем не менее, это справедливо только для отдельных файлов, запрашиваемых распространителями, в отличие от таких сетей, как Freenet, Винни, доля и Perfect Dark где любой узел может хранить любую часть файлов в сети.
Распределенные хранилища данных обычно используют обнаружение и исправление ошибок Некоторые распределенные хранилища данных (например, Parchive через NNTP) используйте упреждающее исправление ошибок методы восстановления исходного файла, когда части этого файла повреждены или недоступны. Другие пытаются снова загрузить этот файл с другого зеркала.

Данная статья продвинутого уровня рассматривает создание масштабируемого объектного хранилища данных с помощью экосистемы Ceph. Что такое объектное хранилище данных? Это хранилище, доступ к которому осуществляется через REST API и которое хранит произвольные бинарные объекты, доступ к которым так же предоставляется с помощью REST API. Типичный и широко используемый пример объектного хранилища данных — Amazon S3.
Зачем оно надо?
Таким образом, подключая к своему приложению систему хранения данных работающую по принципу объектного хранилища Вы сразу получаете бесконечно масштабируемую систему хранения, обладающую лучшими свойствами.
Сегодня, большинство объектных хранилищ частично или полностью совместимы с протоколом хранилища Amazon S3, по крайней мере, существуют шлюзы/конвертеры протоколов, позволяющие работать с хранилищем по по данному протоколу. В связи с этим фактом, при разработке рекомендуется ориентироваться именно на протокол S3.
Обзор Ceph
Ceph — одна из самых перспективных разработок в сфере распределенных, масштабируемых хранилищ данных. Во главу угла при разработке Ceph ставится производительность, надежность и гибкость.
Ceph определяет три интерфейса для хранимых данных:
- Объектное хранилище RADOS;
- POSIX-совместимая файловая система с поддержкой в ядре linux и fuse CEPHFS;
- блочные устройства RADOS BLOCK DEVICE (RBD) с поддержкой в ядре linux.
В настоящее время (1) и (3) являются стабильными подсистемами и могут успешно использоваться в любых проектах, в то время как (2) разрабатывается с меньшим приоритетом и не должна использоваться в критических задачах. Например, мы наблюдали эффект залипания файловой системы CEPHFS при очистке PHP-сессий при использовании CEPHFS в качестве разделяемого хранилища для проекта PHP. Необходимо отметить, что проект интенсивно разрабатывается, возможно, что на момент прочтения статьи CEPHFS уже вышла в стадию стабильной.
Объектное хранилище RADOS и будет героем этой статьи, совместно с совместимым интерфейсом S3 к нему.
Архитектура CEPH определяет три типа узлов:
- OSD — узлы, на которых фактически хранятся данные;
- MON — узлы, отвечающие за управление файловой системой;
- MDS — узлы, обслуживающие файловую систему CEPHFS (если используется).
В системе должно быть нечетное количество узлов MON (минимально — 3), поскольку в системе используется алгоритм PAXOS парламент, который позволяет предотвратить ситуации Split brain, характерные для кластерных систем.
В системе должно быть минимально число OSD равное используемому фактору репликации, если 3, то 3 узла OSD.
Для обеспечения высокой доступности требуется как минимум два узла MDS, если Вы планируете использовать CEPHFS.
В CEPH используется продвинутый алгоритм распределения данных по узлам OSD, который называется CRUSH и является основным ноу-хау системы. CRUSH позволяет вам распределять данные с учетом географии, датацентров, комнат, стоек, серверов и правил, что позволяет обеспечить высокую надежность хранения данных.
Хотя CEPH достаточно свободно определяет как должен выглядеть узел хранения данных, мы на своей практике убедились, что существует две топологии — правильная и неправильная:
- правильная — узел OSD является надежным и изначально полностью укомплектован, например, 2xSSD 240GB RAID1 для журнала, 22x3TB SATA7.2K RAID-6 для данных, на узле работает 1 демон osd;
- неправильная — узел OSD комплектуется по ходу необходимости (вставляются диски) и на каждом диске запускается отдельный демон osd, по сути — своеобразный JBOD.
Поэтому, мой совет — если планируете использовать CEPH для сервиса RBD, то надо использовать 1ю топологию, если же время отклика системы не принципиально, то можно использовать — 2ю. Конечно, неправильная топология выглядит очень соблазнительно — pay as you grow, но ее недостатки перекрывают экономические плюсы.
Еще один нюанс CEPH — вес узла OSD. Этот момент так же явно не оговаривается. От веса узла будет зависеть сколько данных алгоритм CRUSH затолкает на этот OSD. Очень важный нюанс, что при этом не учитывается есть на узле свободное место или нет. Админ должен следить чтобы оно было, вот такая редиска… А если места нет — надо срочно докидывать новые OSD. Поэтому, можно 1ТБ принять за 0.1, тогда в зависимости от емкости OSD его вес Вы будете устанавливать как NTB x 0.1.
Современные приложения оперируют различными типами данных, которые хранятся в базах данных (БД). Это могут быть целочисленные, строковые, бинарные, дата-временные и другие. Такие базы данных, как MySQL или PostgreSQL, могут хранить в себе любые объёмы самых различных данных, но эффективно ли размещать в одном экземпляре всё подряд? Мы опытным путём разделили данные на три категории: часто используемые, текстово-числовые и файловые. В часто используемые попадают те данные, к которым наиболее часто обращаются пользователи. Файловые — это все файлы, в основном картинки, видео и архивы.
Для каждой категории мы используем отдельное хранилище — такой подход повышает эффективность работы с данными.
Реляционное хранилище
Главным местом хранения данных любого приложения является реляционная база данных. SimpleOne использует PostgreSQL для текстово-числовых данных. Эта реляционная система управления базами данных выбрана за стабильность и надёжность, а также множество встроенных инструментов для работы с таблицами и дополнительных модулей. База данных открыто распространяется, имеет огромное комьюнити и постоянно развивается. Например, мы используем встроенный инструмент глобального поиска, и он отлично работает в нашей системе, нет необходимости разрабатывать собственные решения или искать дополнительные расширения. В будущем, с развитием нашей платформы, PostgreSQL всегда сможет удовлетворить наши запросы.
Как бы быстро ни работала реляционная система управления базами данных, есть способ сделать работу платформы ещё быстрее — настроить кеширование самых часто используемых данных. Использовать данные из кеша более экономично, чем каждый раз обращаться к PostgreSQL. Для кеширования мы используем БД Redis, это нереляционная база данных, которая размещает информацию в оперативной памяти сервера. Redis выбрали за его простоту, удобство использования, возможность кластеризации и шардирования. Когда нам становится недостаточно одного сервера для кеша, мы добавляем дополнительные в кластер и тем самым увеличиваем производительность.
Чтобы кеш работал эффективно, он должен содержать часто используемые, но редко обновляемые данные, для этого все запросы к БД анализируются по частоте запросов. Данные в кеше могут храниться только до момента их обновления, затем кеш освобождается и перезаписывается новой информацией. Чтобы не происходило постоянного процесса стирания-записи, для кеширования выбираются те данные, которые обновляются редко. Например, это могут быть агрегаты.
Агрегаты — это сложные объекты, которые имеют много связей. Чтобы собрать агрегат и показать его пользователю, необходимо сделать несколько обращений к БД. Если агрегат целиком поместить в кеш, не надо будет каждый раз тратить время и ресурсы на его сборку. В качестве примера агрегата, помещаемого в кеш, можно назвать систему управления таблицами. Агрегат содержит элементы управления колонками и столбцами, фильтры, сортировщики, кнопки и формы. Все эти элементы описаны в различных таблицах, формируют один объект и редко обновляются. Содержимое самой таблицы, напротив, регулярно изменяется.

Схема работы с кешем Redis
Если взять такой агрегат и целиком поместить в Redis, то для его загрузки не надо будет обращаться к PostgreSQL, такая операция станет выполняться значительно быстрее. А динамично обновляющиеся данные в таблицу будут по-прежнему загружаться напрямую из базы данных.
Если все данные записывать в базу данных, то её размер будет стремительно увеличиваться, время доступа расти, а поиск замедляться. Поэтому все файлы мы храним в отдельном S3-хранилище.
MinIO по S3
S3 — это протокол доступа к неструктурированным данным, разработанный компанией Amazon для своего продукта AWS S3. Компания создала распределённое хранилище, написала для него API и предоставила к нему доступ. Протокол стал настолько популярным, что многие компании выпустили свои версии хранилищ, совместимых с S3. Для SimpleOne мы используем сервер MinIO, который нативно работает с данным протоколом. Взаимодействие платформы с MinIO реализовано с помощью инструментария AWS SDK.
Среди аналогичных продуктов, таких как OpenStack Swift, мы выбрали MinIO, так как его возможностей нам достаточно, а отсутствие лишних компонентов не перегружает систему и не мешает работать. MinIO — живой проект, постоянно развивается и имеет хорошую перспективу. С другой стороны, если его возможностей нам в какой-то момент будет недостаточно, мы всегда сможем смигрировать на другую аналогичную платформу без вмешательства в код программы, так как инструменты взаимодействия по протоколу S3 для всех одинаковы.

Схема: SimpleOne + AWS SDK
Наше хранилище S3, так же как и другие сервисы платформы, работает из контейнера Docker, с помощью технологии контейнеров происходит и взаимодействие между сервисами: backend-сервером, frontend-серером и другими. В зависимости от сложности проекта и числа пользователей мы можем запускать несколько контейнеров на одном сервере или разнести их по отдельным физическим машинам. Технология Docker позволяет автоматически масштабировать систему и динамично перераспределять нагрузку тем контейнерам, у которых в настоящий момент полная загрузка. В любой момент можно подключить дополнительный сервер — распределить нагрузку и повысить производительность системы.
Почему распределённая система хранения данных эффективнее
Существует несколько причин высокой эффективности такой системы — как скоростных, так и архитектурных.
Например, такая система отлично масштабируется. Когда пользователь загружает файл на платформу, он попадает на backend-сервер. Таких серверов может быть несколько, а обращение идёт по единому URL-адресу. Предугадать, на который из них этот файл загрузится, невозможно. Когда пользователю вновь потребуется этот файл, его может не оказаться в Сети: сервер завис, остановлен или недоступен по другим причинам. Поэтому сразу после загрузки файла система перекладывает его на выделенный сервер хранения S3, формирует ссылку и передаёт её клиенту для возможности независимой загрузки.
На хранилище S3 можно размещать файлы любых форматов и любого размера, это никак не сказывается на производительности самого хранилища, но значительно разгружает веб-сервер. Когда на S3 заканчивается место, мы всегда можем добавить диски или подключить дополнительную систему хранения данных без каких-либо структурных и программных изменений.

Схема работы с S3
Заключение
Распределённое хранение данных — это быстро и удобно. Правильно настроенные системы кеширования и файлового хранения в S3 позволили нам улучшить масштабирование и повысить скорость работы с данными более чем на 50%. Мы использовали открытые системы и протоколы, а также стандартные SDK и API — это позволило сократить сроки разработки, упростить техническую поддержку. Тем самым мы получили возможность сменить программные компоненты без вмешательства в код платформы. Для создания SimpleOne мы используем современные технологии и решения, чтобы сделать платформу, удобную как для конечных пользователей, так и для разработчиков и администраторов.

Изучение
В свете последних технологических изменений и достижений распределенные системы становятся все более популярными. Многие ведущие компании создали сложные распределенные системы для обработки миллиардов запросов и обновления без простоев.
Распределенные проекты могут показаться сложными и сложными для создания, но в 2021 году они становятся все более важными для обеспечения экспоненциального масштабирования. Начиная сборку, важно оставить место для базовой, высокодоступной и масштабируемой распределенной системы.
Когда дело доходит до распределенных систем, есть много чего. Итак, сегодня мы просто познакомим вас с распределенными системами. Мы объясним различные категории, проблемы дизайна и соображения, которые необходимо учесть.
Что такое распределенная система?
На базовом уровне распределенная система — это совокупность компьютеров, которые работают вместе, образуя единый компьютер для конечного пользователя. Все эти распределенные машины имеют одно общее состояние и работают одновременно.
Они могут выходить из строя независимо, не повреждая всю систему, как и микросервисы. Эти взаимозависимые автономные компьютеры связаны сетью, чтобы легко обмениваться информацией, общаться и обмениваться информацией.
Примечание. Распределенные системы должны иметь общую сеть для подключения своих компонентов, которые могут быть подключены с помощью IP-адреса или даже физических кабелей.
В отличие от традиционных баз данных, которые хранятся на одной машине, в распределенной системе пользователь должен иметь возможность связываться с любой машиной, не зная, что это только одна машина. Большинство приложений сегодня используют ту или иную форму распределенной базы данных и должны учитывать их однородный или неоднородный характер.
В однородной распределенной базе данных каждая система использует модель данных, а также систему управления базой данных и модель данных. Как правило, ими легче управлять, добавляя узлы. С другой стороны, гетерогенные базы данных позволяют иметь несколько моделей данных или различные системы управления базами данных, использующие шлюзы для трансляции данных между узлами.
Как правило, существует три типа распределенных вычислительных систем со следующими целями:
Примечание. Важной частью распределенных систем является теорема CAP, которая утверждает, что распределенное хранилище данных не может одновременно быть согласованным, доступным и устойчивым к разделам.
Децентрализованные и распределенные
Существует довольно много споров о разнице между децентрализованными и распределенными системами. Децентрализованная система по существу распределена на техническом уровне, но обычно децентрализованная система не принадлежит одному источнику.
Управлять децентрализованной системой сложнее, поскольку вы не можете управлять всеми участниками, в отличие от распределенного единого курса, где все узлы принадлежат одной команде / компании.
Преимущества распределенной системы
Распределенные системы могут быть сложными в развертывании и обслуживании, но такая конструкция дает много преимуществ. Давайте рассмотрим некоторые из этих льгот.
- Масштабирование: распределенная система позволяет масштабироваться по горизонтали, чтобы вы могли учитывать больший трафик.
- Модульный рост: практически нет ограничений на масштабирование.
- Отказоустойчивость: распределенные системы более отказоустойчивы, чем отдельная машина.
- Рентабельность: начальная стоимость выше, чем у традиционной системы, но благодаря своей масштабируемости они быстро становятся более рентабельными.
- Низкая задержка: пользователи могут иметь узел в нескольких местах, поэтому трафик попадет в узел в шкафу.
- Эффективность: распределенные системы разбивают сложные данные на более мелкие части.
- Параллелизм: распределенные системы могут быть разработаны для параллелизма, когда несколько процессоров разделяют сложную задачу на части.

Масштабируемость — самое большое преимущество распределенных систем. Горизонтальное масштабирование означает добавление дополнительных серверов в пул ресурсов. Вертикальное масштабирование означает масштабирование за счет увеличения мощности (ЦП, ОЗУ, хранилища и т. Д.) На ваших существующих серверах.
Горизонтальное масштабирование легче динамически масштабировать, а вертикальное масштабирование ограничено мощностью одного сервера.
Хорошими примерами горизонтального масштабирования являются Cassandra и MongoDB. Они упрощают горизонтальное масштабирование за счет добавления дополнительных машин. Примером вертикального масштабирования является MySQL, когда вы масштабируете, переключаясь с меньших компьютеров на большие.
Проблемы проектирования с распределенными системами
Несмотря на то, что распределенные системы имеют много преимуществ, важно также отметить проблемы проектирования, которые могут возникнуть. Ниже мы кратко изложили основные соображения по поводу дизайна.
- Обработка сбоев: Обработка сбоев может быть затруднена в распределенных системах, потому что некоторые компоненты выходят из строя, а другие продолжают работать. Это часто может служить преимуществом для предотвращения крупномасштабных сбоев, но также приводит к усложнению устранения неполадок и отладки.
- Параллелизм: распространенная проблема возникает, когда несколько клиентов одновременно пытаются получить доступ к общему ресурсу. Вы должны убедиться, что все ресурсы безопасны в параллельной среде.
- Проблемы безопасности: безопасность данных и совместное использование увеличивают риски в распределенных компьютерных системах. Сеть должна быть защищена, и пользователи должны иметь возможность безопасно получать доступ к реплицированным данным в нескольких местах.
- Более высокие начальные затраты на инфраструктуру: начальные затраты на развертывание распределенной системы могут быть выше, чем для одиночной системы. Эта цена включает основные проблемы настройки сети, такие как передача, высокая нагрузка и потеря информации.
Точно так же ошибки труднее обнаружить в системах, которые разбросаны по разным местам.
Облако против распределенных систем
Облачные вычисления и распределенные системы разные, но в них используются похожие концепции. Распределенные вычисления используют распределенные системы, распределяя задачи по множеству машин. С другой стороны, облачные вычисления используют серверы, размещенные в сети, для хранения, обработки и управления данными.
Распределенные вычисления направлены на создание совместного использования ресурсов и обеспечение размера и географической масштабируемости. Облачные вычисления — это предоставление среды по запросу с использованием прозрачности, мониторинга и безопасности.
По сравнению с распределенными системами облачные вычисления имеют следующие преимущества:
- Экономически эффективным
- Доступ к мировому рынку
- Инкапсулированное управление изменениями
- Доступ к хранилищу, серверам и базам данных в Интернете
Однако облачные вычисления, возможно, менее гибки, чем распределенные вычисления, поскольку для построения системы вы полагаетесь на другие сервисы и технологии. Это дает вам меньше контроля.
Такие приоритеты, как балансировка нагрузки, репликация, автоматическое масштабирование и автоматическое резервное копирование. Могут быть упрощены с помощью облачных вычислений. Инструменты создания облака, такие как Docker, Amazon Web Services (AWS), Google Cloud Services или Azure, позволяют быстро создавать такие системы, и многие команды предпочитают создавать распределенные системы вместе с этими технологиями.
Примеры распределенных систем
Распределенные системы используются во всех сферах, от электронных банковских систем до сенсорных сетей и многопользовательских онлайн-игр. Многие организации используют распределенные системы для поддержки сетевых служб доставки контента.
В сфере здравоохранения распределенные системы используются для хранения и доступа, а также для телемедицины. В сфере финансов и торговли многие сайты онлайн-покупок используют распределенные системы для онлайн-платежей или системы распространения информации в финансовой торговле.
Распределенные системы также используются для транспорта в таких технологиях, как GPS, системы поиска маршрутов и системы управления дорожным движением. Сотовые сети также являются примерами распределенных сетевых систем из-за их базовой станции.
Google использует сложную и изощренную инфраструктуру распределенной системы для своих возможностей поиска. Некоторые говорят, что это самая сложная распределенная система на сегодняшний день.

В закладки

Месяц назад я рассказывал о препарировании старенького Mac mini 2007 года. Моя цель — сделать собственный сервер и отказаться от облачных хранилищ, вроде iCloud, Google Drive, Dropbox и прочих.
После пропайки нового разъема с резистором нагрузки Mac mini исправно работает. За последний месяц он ни разу не выключался, выполняя роль домашнего FTP-сервера с внешним доступом.
В этой статье я расскажу, как поднять аналогичное хранилище у себя дома. В качестве компьютера не обязательно останавливаться на Mac mini.
Подойдет любой старенький системник, уставший ноутбук или неттоп. Можно заморочиться и с одноплатным Raspberry, но там немного другая специфика настройки и, скорее тема отдельного материала.
Что ж, приступим к созданию собственного сервера.
Предварительная подготовка
Накатываем Linux
Так случилось, что мой Mac mini был с нерабочим DVD-Rom. После безуспешных попыток запустить систему и часов, потраченных на форматирование загрузочных флешек, мне удалось выяснить кое-что интересное.
Не все Mac mini и старые Mac поддерживают установку с флешки.
У меня как раз такой случай.
Установить DVD-Rom от старенького ноутбука HP не удалось — разъемы не совпадают. Искать донора или аналогичный привод не было желания.
Решение было следующим. Я достал 2,5'' винт Mac mini, установил его в ноутбук на базе Windows. Загрузил дистрибутив Linux Debian (можно сделать это вот здесь), развернул образ на флешку и установил на HDD от Mac mini.
Потом HDD с уже накатанной Linux поставил обратно в Mac mini, включил и все заработало.
Linux неприхотлива к железу. Wi-Fi, Ethernet, графика — все заработало после первого запуска.
Все, теперь у Mac mini есть работающая операционка и можно приступать к дальнейшей настройке.
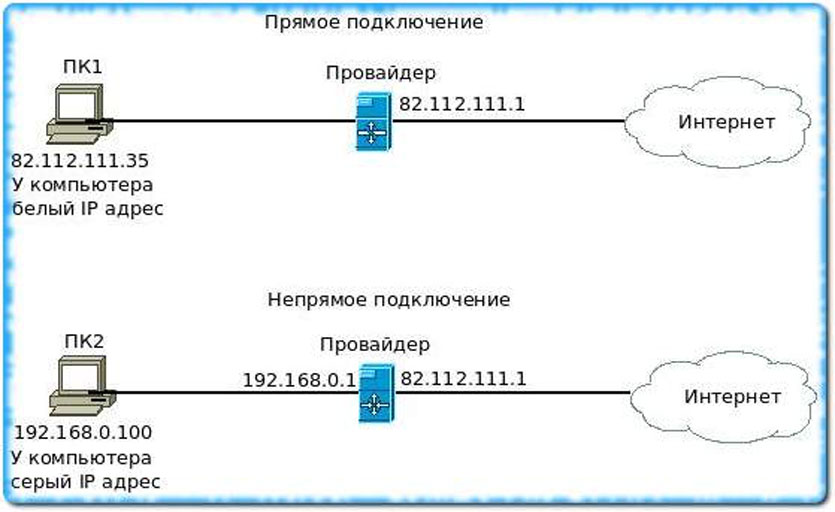
Увы, бесплатно держать свой сервер не выйдет. Зато вы можете наращивать емкость собственного хранилища, но при этом не платить заоблачные цены за гигабайты в облаке.
Время активации зависит от провайдера. У меня был белый IP уже через 30 минут после звонка провайдеру.
Пробрасываем порты
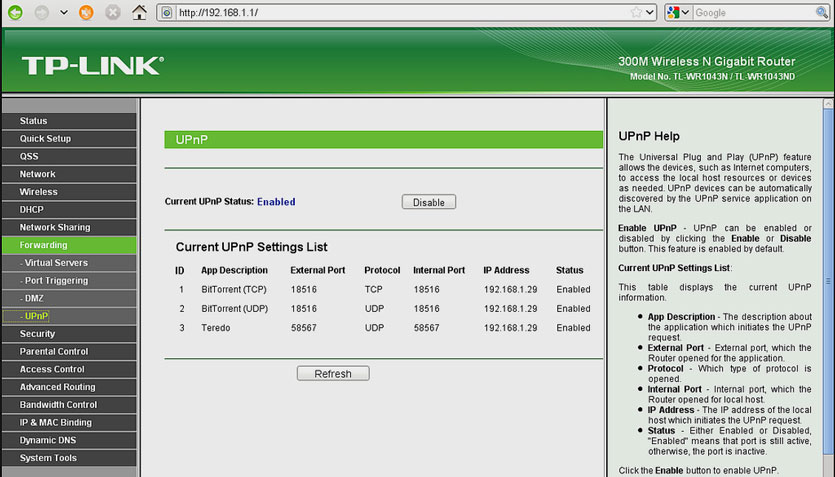
Для того, чтобы вы могли получить доступ к вашему серверу из любой точки мира, необходимо выполнить так называемый проброс портов. Суть его вот в чем.
Вы находитесь далеко от дома, пользуетесь, например интернетом от оператора сотовой связи.
Данная настройка зависит конкретно от вашей модели роутера. Логичнее будет почитать про проброс портов конкретно на ваш роутер отдельно. У меня этот пункт настроек выглядит так:
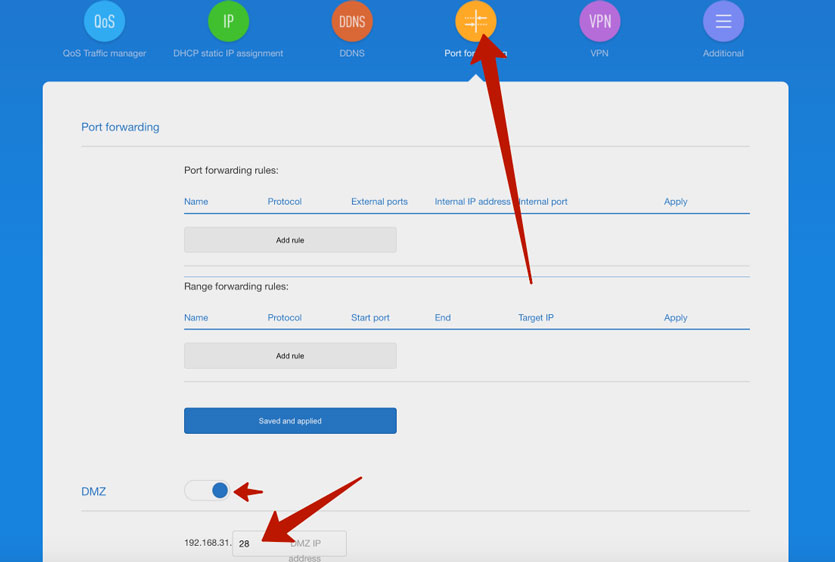
Я просто активировал DMZ (доступ к общедоступным сервисами) и прописал IP-адрес Mac mini в локальной сети.
Его, к слову, можно посмотреть как в сетевых настройках Linux, либо в веб-интерфейсе роутера в разделе подключенных устройств.
Настраиваем сервер на базе Nextcloud
Поскольку я изначально поставил перед собой цель сделать полноценную замену популярным облачным сервисам, ограничиваться банальным FTP не буду.
Хочется получить нормальный мобильный клиент, автоматическую синхронизацию и красивую оболочку.
Лучший вариант для всего этого — решением от Nextcloud.
Nextcloud — это как раз-таки специально разработанный комплекс для создания серверов с регулируемыми уровнями доступа для разных клиентов в рамках корпоративной сети. Но он позиционируется и как удобный инструмент для создания домашнего сервера.
Что ж, приступим к установке Nextcloud на наш Mac mini.
Шаг 1. Запускаем терминал в Linux Debian на Mac mini. Можно вводить все команды как на самом будущем сервере, так и воспользовавшись SSH из Терминала вашего MacBook или другого рабочего компьютера.
Для подключения по SSH необходимо ввести следующую строчку:
Затем указать пароль администратора в системе Linux (на нашем сервер).
Вводим следующую команду:
Затем устанавливаем сервер MariaDB:
su apt install mariadb-server -y
Дожидаемся загрузки и установки всех пакетов.
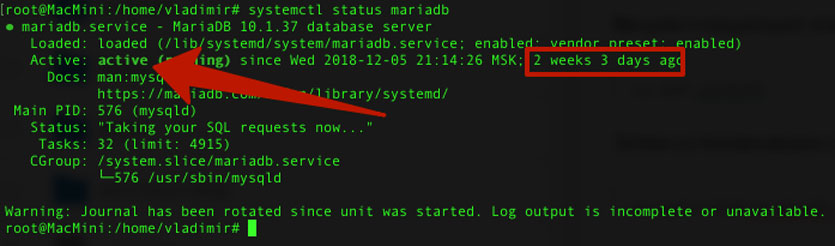
Теперь проверим статус установленного сервера:
sudo systemctl status mariadb
Видим статус active, значит все в порядке.
Чтобы выйти нажимаем Q. Продолжаем настройку.
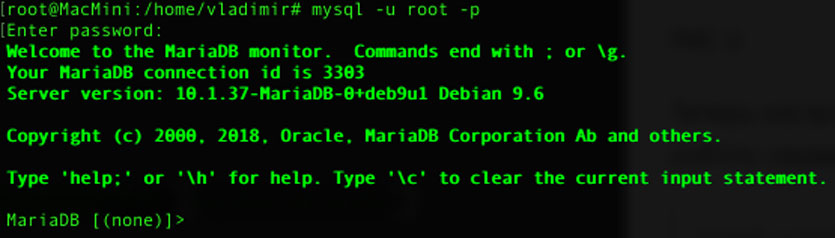
Шаг 2. Проверяем версию MySQL, указав следующую команду:

Теперь настроим систему управления базами данных MySQL под работу сервера Nextcloud. Вводим:
На запрос пароля введите либо ваш пароль администратора, либо просто нажмите Enter.
Шаг 3. Теперь нам предстоит прописать серию команд для создания базы данных под Nextcloud. Вводим:
CREATE DATABASE nextcloud CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
Нажимаем Enter и получаем ответ: Query OK, 1 row affected (0.00 sec). Продолжаем ввод команд:
GRANT ALL ON nextcloud.* TO 'nextclouduser'@'localhost' IDENTIFIED BY 'ПРИДУМАТЬ_ПАРОЛЬ';
Готово. База данных MySQL создана.
Шаг 4. Время установить PHP. Вводим следующую команду.
su apt install software-properties-common жмем еnter
su add-apt-repository ppa:ondrej/php
Жмем еще раз Enter после выполнения последней команды. Дожидаемся окончания установки.
Ставим Apache. Вводим такую строчку:
su apt install apache2 php7.1 php7.1-gd php7.1-json php7.1-mysql php7.1-curl php7.1-mbstring php7.1-intl php7.1-mcrypt php7.1-imagick php7.1-xml php7.1-zip libapache2-mod-php7.1
Подтверждаем действие, нажав Y и Enter. Дожидаемся установки всех пакетов.
Настроим Firewall. Вводим:
Теперь приступаем к загрузке Nextcloud. Меняем директорию:
Жмем Enter. Ждем окончания загрузки. Вводим:
Раскрываем список файлов:
su chown -R www-data: /var/www/nextcloud
И редактируем файл конфига Apache:
su nan /etc/apache2/conf-available/nextcloud.conf
Содержимое данного фала должно быть следующим:
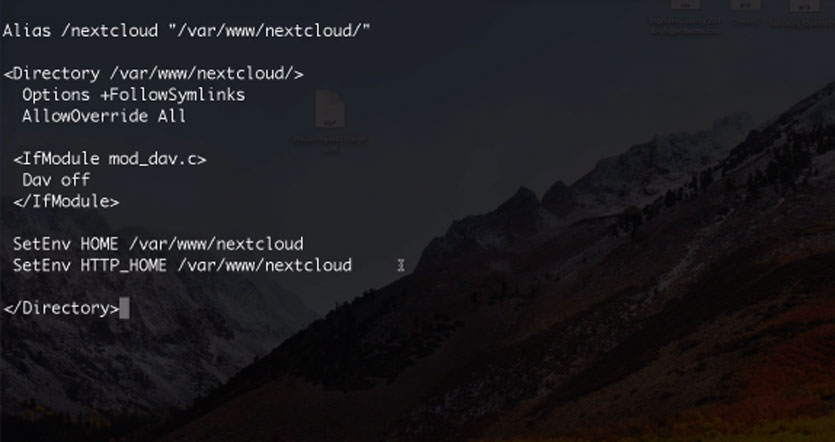
Если подобного текста нет — копируем и вставляем его в файл конфига и нажимаем CTRL + O для сохранения. Жмем Enter.
Остается включить несколько конфигурационных файлов. Ниже серия команд, которые следует вводить поочередно. Нажимаем Enter после каждой команды и дожидаемся выполнения.
su a2enconf rewrite
su systemctl reload apache2 (вводим пароль)
su a2enmod rewrite
su a2enmod headers
su a2enmod env
su a2enmod dir
su a2enmod mime
su systemctl reload apache2
Готово. Настройка Nextcloud окончена.
Краткая настройка Nexctloud
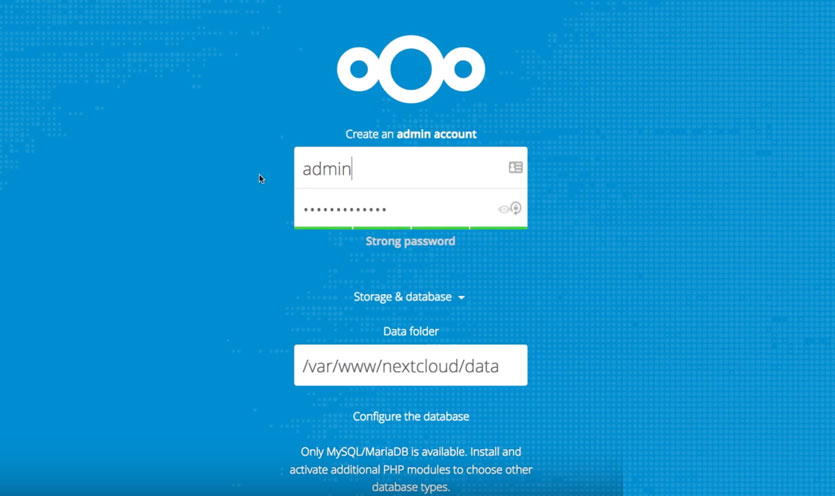
Открываем браузер и вводим адрес нашего белого IP, дописав /nextcloud. То есть во так:
80.23.23.223/nextcloud указываете ваш IP вместо предложенного
И видим окно, показанное на скриншоте выше.
Задаем пароль для пользователя Admin. Попадаем в веб-интерфейс нашего сервера.
Рассказать о всех тонкостях настройки серверного решения Nextcloud в одном материале невозможно. Главное, что следует сделать — скачать мобильный клиент для Android или iOS.
Авторизоваться в нем можно, указав ваш IP-адрес сервера и добавив /nextcloud. Вводите созданное имя пользователя и пароль.
А дальше останется выбрать папки, которые вы хотите автоматически синхронизировать с вашим облачным сервером, установить настройки синхронизации, создать учетные записи для всех членов семьи.
Nexctloud позволяет полностью отказаться от облачных решений вроде Dropbox и iCloud. И главное, вы знаете, что ваши файлы всегда доступны только вам и вашим близким.
В закладки
Владимир Кузин
DIY-техноман. Уверен, что все можно сделать своими руками. Коллайдер не в счет.
В App Store появился клон популярной игры Unpacking, обогнавший по скачиваниям TikTok. Геймеры возмутились, и Apple спешно всё удалила
Доля Apple TV+ на рынке онлайн-кинотеатров в США растёт. А Netflix сдаёт позиции
Apple объявила войну поддельным аксессуарам в Латинской Америке. Она объединилась с крупнейшим маркетплейсом (похож на Ozon)
Новую версию Tesla Cybertruck впервые показали крупным планом на видео. Дворник огромный!
Роскомнадзор хочет создать единую систему блокировки звонков с подменных номеров
Обзор Sony Xperia 1 III с дисплеем 4K. Такой уровень технологий даже не снился
Sony поразила. Все подробности про саундбар HT-A7000 со звуком 360 и систему HT-A9 с фантомными динамиками
🙈 Комментарии 72
Заголовок статьи не правда
@sdix , почему же?
@tov.Polkovnik , 40 руб за IP все-таки платить, эх….
@Владимир Кузин , потому и уточняю: у меня айпи изначально белый без доплаты.
@DastarD , устоявшееся выражение. Идиома, если хотите. Что вам не нравится? Хотите, называйте его выделенным оператором вешним IP-адресом, доступным из глобальной сети, но свои предъявы засуньте подальше.
@DastarD , :D :D :D
А Вы в автомастерской не допытывались с хренов-то у них ход холостой, есть ли у него невеста и когда он женится?
Белый IP – это так называемый, “выделенный”, “статический”, “внешний” IP. Уникальный на весь интернет адрес, который находится в предназначенном для таких целей диапазоне адресов, присваивается лично Вашему каналу, и любые Ваши действия в глобальной сети происходят “от имени” этого IP. Он виден любому устройству/ресурсу, к которому вы обращаетесь. По нему Вас идентифицируют.
Распределение таких IP согласовывается централизовано по планете и они не повторяются. С любой точки Земли, обратившись к этому IP адресу, Вы попадете именно в свою сеть.
Не белый IP, называют “внутренним” или “динамическим”. Это IP, который Вам присваивает провайдер в своей внутренней сети, только для своих внутренних коммуникаций. Когда Вы обращаетесь к сайту, ваш запрос попадает сначала к провайдеру, там у запроса меняется IP, на внешний, от провайдера и после этого он (запрос) уходит “в мир” с IP-адресом провайдера. Теоретически, внутренний IP может быть вообще какой-угодно (в рамках правил сетевого протокола). Хоть 1.2.3.4 Но там тоже есть свои диапазоны, которыми по общему соглашению пользуются для внутренних IP, чтобы не пересекаться с внешними.
Попасть на внутренний IP из другой сети в интернете можно только через внешний IP провайдера. При чем на оборудовании провайдера специально еще нужно настроить возможность такого соединения.
@tr1GGr , белый ip может быть и динамикой, и статикой.
а то, что вы расписали как “не белый, динамический” – это серый ip, который за NAT-ом провайдера ;)
Читайте также: