
Как сделать процентное соотношение анкет
Обновлено: 03.07.2024
Чуднова Ольга Владимировна
Сахалинский государственный университет
старший преподаватель кафедры социологии
Аннотация
Статья посвящена описанию процесса обработки первичной социологической информации, получаемой в ходе интервью, анкетирования и иных количественных методов с помощью прикладной компьютерной программы Microsoft Office Excel. Проведенный анализ позволяет утверждать, что высокая адаптивность и простота работы с данным программным обеспечением позволяет решать множество разнообразных задач, необходимых для социолога-практика.
Abstract
The article describes processing of primary sociological information obtained through interviews, questionnaires and other quantitative methods using Microsoft Office Excel application. Performed analysis allows to state that high adaptability and ease of use of this software enable to solve a wide variety of Sociological Practitioner’s tasks.
В ходе проведения массовых социологических опросов перед исследователями нередко возникает проблема, связанная с обработкой больших совокупностей полученных данных и их преобразованием из рукописного вида в электронный, машиночитаемый формат.
К сожалению, практически все специализированные программы для обработки социологической информации (SPSS, Statistica, Vortex, PolyAnalyst и др.) распространяются на коммерческой основе, предъявляют серьезные требования к техническим характеристикам персональных компьютеров и зачастую не имеют русифицированного файла помощи.
В связи с этим возрастает необходимость обращения к программному обеспечению, имеющемуся на большинстве современных ЭВМ и позволяющему решать различные задачи необходимые социологу-практику. Одной из таковых программ является Microsoft Office Excel (Excel).
Рис. 1 Фрагмент анкеты
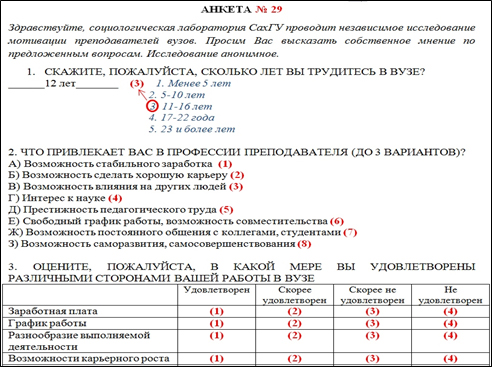
На втором этапе происходит формирование базы данных социологического опроса в Excel.
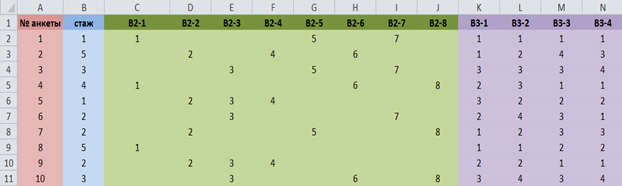
В первый столбец матрицы необходимо внести номера анкет, а в первую строку – краткие формулировки вопросов или их номера. Таким образом, каждой строке матрицы соответствует одна анкета, а каждому столбцу – один вопрос или подвопрос (рис. 2).
Рис. 2. Фрагмент базы данных социологического опроса в Excel
Поскольку во втором вопросе анкеты (рис.1) респондент может выбрать несколько вариантов, вопрос необходимо разбить на колонки по числу вариантов ответа (подвопросы).
При обработке вопроса заданного в виде таблицы, следует разбивать его на подвопросы по количеству строк.
Затем в матрицу вносятся данные всех анкет в соответствии с ранее произведенным кодированием.
Рис. 3 Матрица данных с закрепленным заголовком
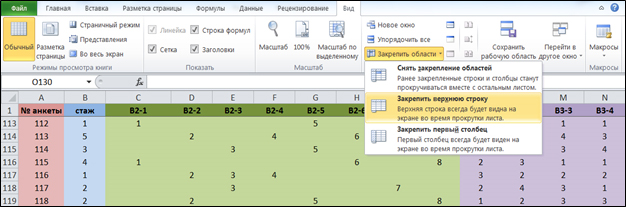
Рис. 4. Поиск ошибок ввода данных
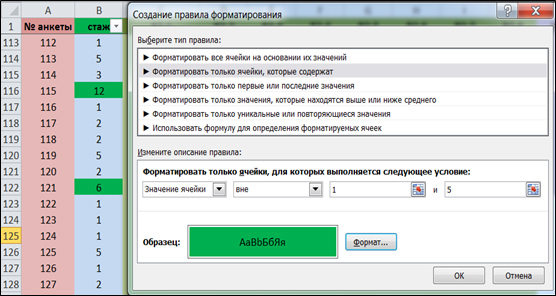
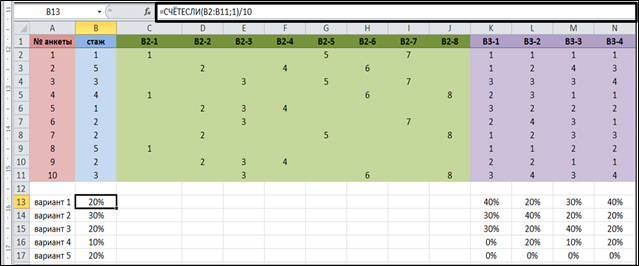
=СЧЁТЕСЛИ(B2:B11;1)/10, где
B2:B11- столбец, в котором находятся интересующие нас ответы;
1 – номер варианта ответа, процент которого необходимо посчитать;
10 – общее количество анкет.
Когда все варианты ответа в первом столбце просчитаны, формулу можно растянуть вправо для подсчета процентов по всем вопросам, предполагающим один ответ.
Далее применим формулу использованную ранее. Для подсчета процентного распределения первого варианта ответа во втором вопросе анкеты, формула будет иметь вид:
=СЧЁТЕСЛИ(C2:C11;1)/27, где
C2:C11 – диапазон столбцов, в которых находятся интересующие нас ответы;
1- номер варианта ответа, процент которого необходимо посчитать;

Если в ходе исследования социологу необходимо определить связь между признаками, например, выяснить, сколько респондентов со стажем работы от 5 до 10 лет полностью удовлетворены заработной платой (столбец В3-1), необходимо пользоваться формулой вида:
=СЧЁТЕСЛИМН(B2:B11;2;K2:K11;1)/СЧЁТЕСЛИ(B2:B11;2), где
B2:B11 – диапазон столбцов, в которых находятся ответы о стаже работы;
2 – код ответа, обозначающий стаж работы от 5 до 10 лет;
K2:K11- диапазон столбцов, в которых находятся ответы об удовлетворенностью заработной платой;
1 – код ответа, обозначающий полную удовлетворенность заработной платой.
Таким образом, с помощью программы MS Excel, социолог может в сжатые сроки базовый анализ данных, интерпретировать значительные числовые массивы, полученные в ходе эмпирических исследований. Высокая адаптивность и простота работы, легкость экспорта данных, как между пользователями, так и между другими программными продуктами, позволяет реализовать на практике любой метод количественных исследований и решить большую часть задач, встречающихся в работе социолога.
- Рабочая книга социолога / под ред. Г.В. Осипова. Изд. 4-е, стереотипное. – М.: КомКнига, 2006. – 480 с.
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте или через форму обратной связи.
Связь с автором (комментарии/рецензии к статье)
Оставить комментарий
Вы должны авторизоваться, чтобы оставить комментарий.
Проанализировав эту информацию можно сделать несколько выводов:
- возможность общения со сверстниками является одним из самых важных факторов возникновения интереса к учебной деятельности в школе вообще и к учебным предметам в частности;
- процесс самостоятельной работы, судя по полученным данным, не вызывает большого интереса у старшеклассников. В то же время, интерес к этому виду обучения и способу узнавания нового может помочь старшеклассникам при переходе на следующую стадию обучения: получение высшего профессионального образования, т.к. самообразование является основным видом учебной деятельности в вузах;
Второй вопрос был необходим для того, чтобы выявить интересные и неинтересные предметы учащихся одиннадцатых классов, а так же их оценки по этим предметам. Среди интересных предметов самое большее количество выборов получила История (24 %), далее Биология (20 %), за ней Математика (12 %), Химия (8 %), Основы безопасности жизнедеятельности (7,5 %), Русский язык (7,5 %), Физика (6 %), Обществознание (6 %), Физическая культура, Английский язык и Литература (3 %).
В списке неинтересных предметов первое место занимает ОБЖ (27 %), следующий предмет Химия (23 %), далее Физика (16 %), Английский язык (14%), Физическая культура (9 %), Математика (9 %), Биология (2 %).
Третий вопрос выявляет причину, по которой учащемуся интересен или неинтересен тот или иной школьный предмет.
На основе результатов можно сделать несколько выводов:
Как видно из результатов анкетирования, одним из главных критериев, по которым учащиеся старших классов определяют нравиться ему им какой - либо предмет или нет, является связь этого предмета с определенной профессией. То есть профессиональная ориентация старшеклассника, выбор собственного жизненного пути ведет за собой появление познавательного интереса. Необходимые для старшеклассника в будущем знания усваиваются и понимаются им лучше. Из-за этого возрастет и его успеваемость по определенным школьным предметам. В противном случае по окончании 11 класса ученик не будет обладать знаниями, которые позволят ему быть конкурентоспособным при переходе на следующую ступень образования. Он даже, возможно, будет не так успешен как его сверстники и в уже более взрослом возрасте, освоив интересную ему профессию.
Выводы по 2 главе
Методом изучения интересов старших школьников и их влияния на результаты обучения в данном исследовании является анкетирование: оно позволяет за короткие сроки опросить большое количество респондентов и выявить массовое какое - либо массовое явление или закономерность.
Для данного исследования была составлена анкета из трех вопросов: одного не основного и двух основных. Составленная анкета выявляет как наличие интереса к определенному школьному предмету, так и его отсутствие у учащегося старших классов, его оценку по этим предметам. Определяет причину, по которой эти предметы интересным (или неинтересными) для него. Эти данные позволили нам выявить зависимость результата обучения от познавательных интересов ученика.
Одним из главных критериев, по которым учащиеся старших классов определяют нравиться ему им какой - либо предмет или нет, является связь этого предмета с определенной профессией. Интересы должны быть вовлечены в систему жизненных целей и планов личности. Кроме того, должна присутствовать связь знаний с практикой, которая понятна ученикам, с насущными вопросами повседневной жизни, окружающей средой, "злобой дня", важными жизненными перспективами

Father of three kids. Ex-developer, ex-marketer, ex-analyst, ex-growth hacker, and ex-product manager.
More posts by Alexey Kartashev.
Alexey Kartashev

Рассчитывайте результаты опросов по методу Кано за несколько минут прямо в Google Sheets. Это бесплатно. Перейти к калькулятору.
Все что вам нужно для расчета результатов опросов по методу Кано. Для тех кто не знает что такое метод Кано можете прочитать вводную статью.
1. Проведите опрос среди ваших пользователей
Вы можете использовать удобный вам сервис для проведения опросов. Мы рекомендуем использовать формы Гугл, они бесплатны и полностью подходят для этой задачи.
Создание опроса в Google Forms
Ответы внутри Google Форм
3. Скопируйте и вставьте ответы ваших пользователей в калькулятор
Откройте калькулятор результатов Кано и вставьте во вкладку "Original Answers" все ответы, которые у вас есть
Копирование и вставка результатов опроса в Калькуляторе Кано
4. Укажите название идей и соответствия колонок в ответах
Чтобы завершить подсчет результатов укажите в панели таблицы Гугл с установленным скриптом соответствия колонок (их идентификаторы) и укажите описание/название каждой из идей. Если вы опрашивали NPS (Net Promoter Score), он будет посчитан автоматически.
Настройка мапинга вопросов внутри калькулятора по Кано
5. Получите результат
Нажмите на кнопку "Calculate results", дождись завершения работы скрипта. Во вкладке "Results" будет доступа визуализация результатов, а так же визуализацию со возможными статистическими отклонением по каждой из идей.
А также
Визуализация результатов
Вы можете легко сохранить результат в виде картинки, либо расшарить его с помощью таблиц Гугл
Автоматический расчет NPS
Если одним из ваших вопросов была оценка Net Promoter Score, то результат будет посчитан так же автоматически
Учет погрешности
По каждой из идей возможно видеть максимальные и минимальные значения отклонений
Минимум ручной работы
Сбор результатов требует минимум ручного труда и весь расчет занимает несколько минут
Калькулятор результатов по модели Кано
FAQ
Как начать пользоваться?
Откройте ссылку с калькулятором и создайте копию документа.В созданной копии в верхнем правом меню навигации вам должен быть доступен пункт "Kano Calculator -> Setup calculation". Согласитесь на установку допоплнения и после этого у вас откроется меню настроек скрипта в правой панели документа.

По какой формуле считается NPS?
Я не использовал вопрос про важность. Возможно ли использовать Калькулятор без вопроса про важность?
Все равно ничего не понятно, что делать?
Калькулятор результатов по модели Кано
Поделитесь обратной связью по использованию калькулятора в комментариях ниже
Если калькулятор был полезен, вы можете ☕ купить мне чашку кофе ;)
Subscribe to kartashev.me
Get the latest posts delivered right to your inbox
More in business
Автоматизация чекинов целей и ключевых результатов (Objectives & Key Results) через Google Sheets
4 Sep 2020 – 4 min read
What is lifecycle of any system?
18 Sep 2018 – 1 min read
Как много версий продукта нужны клиентам?
14 Sep 2018 – 3 min read
Модель Кано: Введение. Как проводить опросы пользователей
С помощью метода Кано вы можете без разработки определить/предугадать удовлетворенность и важность для пользователей каждой вашей й.
The Innovator's Method by Nathan Furr
Тексты с большим количеством статистики и сравнительных таблиц утомляют читателей и имеют все шансы быть недочитаными. Сохранить вовлеченность и дочитываемость материала поможет инфографика.
В этой статье мы расскажем, как создавать редакционные инфографики, которые быстро собираются, хорошо выглядят, и по структуре являются последовательным повествованием.
Редакционную инфографику создают в четыре этапа: сбор данных, интерпретация (поиск смыслов), визуализация и размещение в конкретном медиа.

Интерпретацией данных занимается редактор. Процесс похож на подготовку материала в формате объяснительной журналистики: нужно подать сложную для восприятия информацию, помочь человеку понять, как тема касается его лично.

Таблица помогала найти нужный тариф, но занимала много места и не позволяла сравнивать разные временные периоды между собой. Полезные данные здесь — это стоимость одной стирки белья, которую редакторы высчитали по специальной формуле.
Вот как это выглядит на временной шкале:

Стало не просто видно, что в квартирах с газовой плитой стирать дороже, но и насколько: днём разница составляет 2–3 рубля, а вот ночью — всего 80 копеек.
Информация интересна человеку ровно настолько, насколько может быть ему полезна. Редакционная инфографика не просто показывает красивые цифры: она превращает данные в историю, которая заинтересует читателя.

Вот данные, которыми мы располагаем:

Присоединим к этому информацию про недовольство фигурой в зависимости от размера одежды — и получим вступление (лид), которое вкратце описывает проблему и помогает читателю определить, как тема касается его лично.

Теперь видно, что вся оставшаяся статистика касется именно этих 45 женщин, которые сидят на диете: всего пять блоков о причинах и следствиях диеты, и один — о тех, кто старался и у кого ничего не получилось. Свяжем их в историю.

Обратите внимание, что первоначальные заголовки сильно поменялись, чтобы соответствовать новой структуре. Если прочитать по диагонали только заголовки, они будут похожи на предложение:
Леди на диете. Из 100 женщин 19 довольны своей фигурой, 81 недовольна. Зачем садятся на диету, когда сидят на диете, как соблюдают диету? В результате диеты 19 похудевших сохраняют результат. Почему бросают диету?
В основе хорошей инфографики — её польза для человека. Редакционная инфографика органично смотрится в статье: у нее вертикальная ориентация, поэтому ее можно прокручивать вместе со страницей. Она помогает собрать разрозненные данные в историю и повысить дочитываемость материала при коротком окне внимания читателя.
В следующем материале мы расскажем:
- О правилах и шаблонах, по которым создаем редакционную инфографику.
- Какие законы восприятия информации учитываем.
- Почему круговые диаграммы — отстой.
Больше о медиа, форматах, подаче и распространении контента, инструментах и аналитике — в нашей группе на Facebook.

Если анкета невелика (до 10 вопросов) и массив анкет небольшой (до 150 анкет), обработку можно проводить вручную, используя способ графической записи количества (см. раздел 3.1 в первой тетради).
4. Графическое изображение результатов.
Графическое изображение результатов статистической обработки не является обязательным этапом, но во многих случаях значительно облегчает анализ информации. Подробнее об этом см. в разделе 6.3.
6.2. Как провести группировку данных
Основные способы статистической обработки анкет, которые используются практически всегда, - это составление РЯДОВ РАСПРЕДЕЛЕНИЯ для каждого вопроса и ГРУППИРОВОЧНЫХ ТАБЛИЦ ключевых вопросов с некоторыми вопросами паспортички.
РЯД РАСПРЕДЕЛЕНИЯ ДЛЯ ВОПРОСА – ЭТО РЯД ЧИСЕЛ, КАЖДОЕ ИЗ КОТОРЫХ ОЗНАЧАЕТ ЧАСТОТУ (КОЛИЧЕСТВО) ВЫБОРА СООТВЕТСТВУЮЩЕГО ВАРИАНТА ОТВЕТА НА ДАННЫЙ ВОПРОС В РАССМАТРИВАЕМОЙ СОВОКУПНОСТИ АНКЕТ. РЯД ЧИСЕЛ-ЧАСТОТ ДОПОЛНЯЕТСЯ РЯДОМ ПРОЦЕНТОВ, В КОТОРОМ В КАЖДОЙ ЧАСТОТЕ СООТВЕТСТВУЕТ ЕЕ ДОЛЯ, ВЫРАЖЕННАЯ В ПРОЦЕНТАХ, В РАССМАТРИВАЕМОЙ СОВОКУПНОСТИ АНКЕТ.
Проценты рассчитываются по формуле
i – номер варианта ответа;
ni – частота выбора i-го варианта ответа на данный вопрос в рассматриваемой совокупности анкет;
N – общее количество анкет.
Читайте также: