
Как сделать полиномиальную регрессию
Обновлено: 04.07.2024
Предметом исследования являются связи и зависимости между социально-экономическими показателями регионов. Сформулирована задача, в соответствии с которой требуется выявить зависимость ВРП от численности занятых в экономике и стоимости основных фондов, и построены уравнения регрессии в виде полинома второго порядка, апробированные по данным 27 малых регионов России по величине ВРП за 2010 г. Описаны два разных способа определения параметров и статистических характеристик многофакторных полиномиальных уравнений регрессии с помощью различных функций, процедур и средств MS Excel. Дана авторская методика расчета параметров и характеристик двухфакторных моделей регрессии полиномиального вида и оценка результатов. Разработана и описана компьютерная модель, позволяющая автоматизировать все необходимые расчеты и процедуры обработки информации и строить как полные, так и неполные варианты полиномиальных уравнений регрессии. Дана сравнительная оценка различных вариантов двухфакторных полиномов второго порядка, построенных по данным малых регионов с помощью ключевых статистических характеристик, и определены наиболее значимые из уравнений.

1. Адамадзиев К.Р., Адамадзиева А.К. Оценка зависимости ВРП от инвестиций, численности занятых в экономике и стоимости основных фондов с помощью моделей панельных данных (на примере регионов России) // Международный журнал прикладных и фундаментальных исследований. – 2011. – № 9. – С. 68–70.
4. Практикум по эконометрике: под ред. И.И. Елисеевой. – 2-е изд., перераб. и доп. – М.: Финансы и статистика, 2008. – 344 с.
6. Эконометрика: учебное пособие в схемах и таблицах; под ред. д-ра экон. наук, проф. С.А. Орехова. – М.: Эксмо, 2008. – 224 с.
Важнейшими функциями, выполняемыми на любых экономических объектах, являются аналитические функции, которые, как правило, выполняются работниками среднего и высшего уровня управления. При проведении анализа часто возникает необходимость в проведении множества расчётов и процедур обработки информации. Для автоматизации расчётов и процедур обработки информации в настоящее время разработаны и применяются так называемые BI-системы (аналитические системы подготовки принятия решений).
К числу наиболее значимых задач для BI-систем можно отнести задачи, в которых требуется количественно выразить и оценить связи и зависимости между различными экономическими показателями и тенденции их изменения.
Особенность таких задач состоит в том, что связи, зависимости и тенденции носят неопределённый, вероятностный характер для любого из выбранных совокупностей и поэтому не могут быть однозначно определены. Во-первых, зависимость даже между одними и теми же показателями для одной и той же совокупности может быть описана разными видами уравнений регрессии (как линейными, так и нелинейными); во-вторых, удаление любого из объектов совокупности или добавление нового объекта в состав исследуемой совокупности может изменить степень тесноты связи и её характеристики.
Содержание
Связи и зависимости между экономическими показателями могут быть описаны одно- и многофакторными моделями регрессии. Особое место среди видов моделей регрессии занимают модели, описываемые полиномами второго порядка. Уже однофакторная модель такого вида, записываемая в виде уравнения параболы, отличается от остальных однофакторных тем, что, во-первых, она содержит три параметра (а не два, как, например, линейное, показательное и степенное); во-вторых, на ее основе можно определить величину показателя-фактора, при котором результативный показатель принимает максимальное (или минимальное) значение.
Так, если однофакторное уравнение параболы записать в виде
y = b + m1x + m2x2,
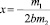
то при y принимает max или min.
При этом сама величина ymax (ymin) равна
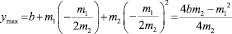
.
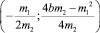
Т.о., точка max (min) – это вершина параболы, координаты которой равны .
Двухфакторная полиномиальная модель регрессии параболического вида в общем случае представляет собой уравнение, которое имеет следующую математическую запись:
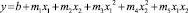
.(1)
Методика расчёта параметров этого уравнения аналогична методике построения пятифакторного уравнения линейного вида:
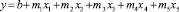
. (2)
Параметры уравнения (1) можно рассчитать методом наименьших квадратов, в соответствии с которым требуется составить и решить систему нормальных уравнений [4, 6].
Поскольку с помощью уравнений регрессии выявляются и оцениваются приближенные траектории связей и зависимостей, называемые корреляционными, то для обоснования их адекватности и возможности практического применения принято рассчитывать статистические характеристики.
На основе учебной литературы по эконометрике [2, 4, 6] нами разработан модельный инструментарий, включающий комплекс из 20 формул.
Особенности построения двухфакторных уравнений параболического вида (см. формулу (1)) и методика оценки связей и зависимостей с их помощью рассмотрим на конкретном практическом примере.
Пусть требуется построить двухфакторное уравнение регрессии для зависимости ВРП (y, млрд руб.) от численности занятых в экономике (х1, тыс. чел.) и стоимости основных фондов (х2, млрд руб.) для 27 малых регионов России по величине ВРП за 2010 г.
Для формирования выборки из 27 малых регионов достаточно создать в MS Excel таблицу с тремя рассматриваемыми показателями для всех регионов России [5], расположить регионы в порядке возрастания величины ВРП, а затем выбрать требуемые 27 регионов (табл. 1).
Линейная регрессия — метод восстановления зависимости между двумя переменными. Ниже приведен пример программы, которая строит линейную модель зависимости по заданной выборке и показывает результат на графике.
Для заданного множества из пар , , значений свободной и зависимой переменной требуется построить зависимость. Назначена линейная модель
c аддитивной случайной величиной . Переменные принимают значения на числовой прямой . Предполагается, что случайная величина распределена нормально с нулевым матожиданием и фиксированной дисперсией , которая не зависит от переменных . При таких предположениях параметры регрессионной модели вычисляются с помощью метода наименьших квадратов.
Например, требуется построить зависимость цены нарезного хлеба от времени. (См. рис. далее по тексту). В таблице регрессионной выборки первая колонка — зависимая переменная (цена батона хлеба), вторая — свободная переменная (время). Всего данные содержат 195 пар значений переменных. Данные нормированы.
Одномерная регрессия
Определим модель зависимости как
Согласно методу наименьших квадратов, искомый вектор параметров есть решение нормального уравнения
где — вектор, состоящий из значений зависимой переменной, . Столбцы матрицы есть подстановки значений свободной переменной и , . Матрица имеет вид
Зависимая переменная восстанавливается по полученным весам и заданным значениям свободной переменной
% Для оценки качества модели используется критерий суммы квадратов регрессионных остатков, SSE — Sum of Squared Errors.
Пример нахождения параметров модели и восстановления линейной регрессии (здесь и далее код на языке Matlab).

Полиномиальная регрессия
Пусть регрессионная модель — полином заданной степени ,
Матрица в случае полиномиальной регрессии называется матрицей Вандермонда и принимает вид
Одномерная регрессия — частный случай полиномиальной регрессии.
Пример нахождения параметров модели и восстановления полиномиальной регрессии.

Криволинейная регрессия
Пусть исходные признаки преобразованы с помощью некоторых заданных, в общем случае нелинейных функций . При этом функции не должны содержать дополнительных параметров. Функции должны быть определены на всей числовой прямой, либо, по крайней мере, на всех значениях, которые принимает свободная переменная.
Матрица в случае полиномиальной регрессии называется обобщенной матрицей Вандермонда и принимает вид
Полиномиальная регрессия — частный случай криволинейной регрессии.
Пример нахождения параметров модели и восстановления криволинейной регрессии.

Исходный код
(Этот раздел должен быть скрыт)
Применение линейной постановки задачи для моделирования кривых второго порядка
Постановка задачи из области контроля качества состояния трубопроводов. Заданы координаты окружности (сечения трубы) -- множество точек , измеренных с некоторой погрешностью. Требуется найти центр и радиус окружности.
Запишем регерссионную модель-- координаты окружности относительно центра и радиуса и выделим линейно входящие компоненты:
Тогда матрица плана линейной модели будет иметь вид
Аналогичным путем получаются решения задач нахождения параметров эллипсоида, параллелограмма и других геометрических фигур.
В Mathcad реализована регрессия одним полиномом, отрезками нескольких полиномов, а также двумерная регрессия массива данных.
Полиномиальная регрессия
Знаете ли Вы, что, когда некоторые исследователи, пытающиеся примирить релятивизм и эфирную физику, говорят, например, о том, что космос состоит на 70% из "физического вакуума", а на 30% - из вещества и поля, то они впадают в фундаментальное логическое противоречие. Это противоречие заключается в следующем.
Вещество и поле не есть что-то отдельное от эфира, также как и человеческое тело не есть что-то отдельное от атомов и молекул его составляющих. Оно и есть эти атомы и молекулы, собранные в определенном порядке. Также и вещество не есть что-то отдельное от элементарных частиц, а оно состоит из них как базовой материи. Также и элементарные частицы состоят из частиц эфира как базовой материи нижнего уровня. Таким образом, всё, что есть во вселенной - это есть эфир. Эфира 100%. Из него состоят элементарные частицы, а из них всё остальное. Подробнее читайте в FAQ по эфирной физике.

Сталкиваясь с какой-либо проблемой в ML, помните, что есть множество алгоритмов, позволяющих её решить. Однако не существует такого универсального алгоритма, который подходил бы под все случаи и решал абсолютно все проблемы.
Выбор алгоритма строго зависит от размера и структуры ваших данных. Таким образом, выбор правильного алгоритма может быть неясен до тех пор, пока мы не проверим возможные варианты и не наткнёмся на ошибки.
Но каждый алгоритм обладает как преимуществами, так и недостатками, которые можно использовать в качестве руководства для выбора наиболее подходящего под ситуацию.
Начнём с простого. Одномерная (простая) линейная регрессия – это метод, используемый для моделирования отношений между одной независимой входной переменной (переменной функции) и выходной зависимой переменной. Модель линейная.
Более общий случай – множественная линейная регрессия, где создаётся модель взаимосвязи между несколькими входными переменными и выходной зависимой переменной. Модель остаётся линейной, поскольку выходное значение представляет собой линейную комбинацию входных значений.
Также стоит упомянуть полиномиальную регрессию. Модель становится нелинейной комбинацией входных переменных, т. е. среди них могут быть экспоненциальные переменные: синус, косинус и т. п. Модели регрессии можно обучить с помощью метода стохастического градиента.
Преимущества:
- Быстрое моделирование. В особенности, моделирование можно назвать простым, если отсутствует большой объём данных.
- Линейную регрессию легко понять. Она может быть ценна для различных бизнес-решений.
Недостатки:
- В случае нелинейных данных полиномиальную регрессию трудно спроектировать. Необходимо иметь информацию о структуре данных и взаимосвязи между переменными.
- Основываясь на изложенных выше фактах, линейная регрессия неэффективна, когда речь идёт об очень сложных данных и больших объёмах.
Нейронные сети тренируются с помощью метода стохастического градиента и алгоритма обратного распространения ошибки.
Преимущества:
- Так как нейронные сети могут быть многослойными, они эффективны при моделировании сложных нелинейных отношений.
- Нам не нужно беспокоиться о структуре данных в нейронных сетях, которые очень гибки в изучении почти любого типа переменных признаков.
- Исследования постоянно показывают: чем больше обучающих данных “дают” нейронной сети, тем производительнее она становится.
Недостатки:
- Из-за сложности этой модели, её нелегко понять и реализовать.
- Нейронные сети требуют тщательной настройки гиперпараметров и скорости обучения.
- Для достижения высокой производительности нейронным сетям необходимо огромное количество данных, и в результате, как правило, нейросети уступают другим ML алгоритмам в тех случаях, когда данных мало.
Начнём с простого случая. Дерево принятия решений – это представления правил, находящихся в последовательной, иерархической структуре, где каждому объекту соответствует узел, дающий решение. При построении дерева важно классифицировать атрибуты так, чтобы создать “чистые” узлы. То есть выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество объектов из других классов в каждом из этих множеств было как можно меньше.
Полиномиальная регрессия – это алгоритм машинного обучения, который используется для обучения линейной модели на нелинейных данных. Иногда ваши данные намного сложнее, чем прямая линия, и в таких случаях обучение на основе алгоритма линейной регрессии – не лучший вариант, но, мы можем использовать алгоритм полиномиальной регрессии, чтобы добавить производительности каждой функции, а затем обучить линейную модель на расширенном наборе функций. Вот так работает этот алгоритм. Чтобы вы лучше поняли, в этой статье я познакомлю вас с полиномиальной регрессией в машинном обучении и ее реализацией с использованием Python.
Полиномиальная регрессия в машинном обучении
В машинном обучении алгоритм полиномиальной регрессии позволяет использовать линейную модель, даже если данные имеют очень сильную нелинейность. Он работает, добавляя дополнительные функции к данным, при этом понимая существующие функции.
Чтобы реализовать этот алгоритм, вы должны сначала обучить линейную модель на нелинейном наборе данных, скажем, мы хотим обучить алгоритм линейной регрессии на нелинейных данных, что даст нам плохие результаты. Поэтому в таких случаях нужно добавить новые функции, учитывая существующие функции, чтобы сделать наш набор данных линейным. Для этой задачи нам нужно использовать алгоритм полиномиальной регрессии, который преобразует данные в расширенные, а затем, если мы снова будем использовать алгоритм линейной регрессии для вновь преобразованных данных, он даст нам идеальные результаты.
Полиномиальная регрессия с использованием Python
Чтобы реализовать этот алгоритм с использованием Python, я начну с импорта всех необходимых библиотек Python и набора данных, который нам нужен для этой задачи:
Теперь давайте разделим данные и обучим алгоритм линейной регрессии, чтобы увидеть, какой результат мы получим, прежде чем добавлять новые функции в этот нелинейный набор данных:
Результат:
Поскольку набор данных, который мы используем, является нелинейным, мы получаем оценку 0,68, что довольно слабо, поэтому давайте посмотрим, какой результат мы получим после обучения алгоритма линейной регрессии на недавно преобразованном наборе данных с использованием полиномиальной регрессии:
Результат:
Таким образом, после обучения той же модели расширенным функциям мы получаем 0,91 балла, что уже неплохо.
Резюме
Вот как добавление новых полиномиальных функций помогает преобразовать существующие нелинейные данные в линейные. Надеюсь, вам понравилась эта статья о введении в алгоритм полиномиальной регрессии в машинном обучении и его реализации с использованием Python.
Читайте также: