
Как сделать миграции в docker
Добавил пользователь Alex Обновлено: 05.10.2024
Приветствую, вопрос следующий, пытаюсь связать 2 отдельных docker контейнера в docker-compose, но постоянно натыкаюсь на грабли то в одном то в другом.
Вкратце, сейчас логика развертывания в текущих отдельных контейнерах следующая:
1.1 docker run mysql:latest, dockerfile этого контейнера (в упрощнном виде):
1.2 docker exec mysql "mysql "
Мигрирую на docker-compose и сразу же натыкаюсь на ворох проблем:
1) Как правильно организовать логику скачивания дампа базы wget’ом и закачивания её в mysql?
Мейнтейнеры образа предлагают шарить volume с дампами, которые будут залиты, мне этот подход не рабоатет тк мне надо слить образы wget’ом, который, кстати, на борту образа не присутсвует.
Пробовал в compose создавать build context со ссылкой на dockerfile по подобию оригинального докерфайла:
Есть вариант обновить Entrypoint по умолчанию, добавив туда нужную логику сверху, но это КМК совсем грязный хак учитывая типовость задачи.
Гугление навело на stackoverflow где оптимальным решением было принято создание -1) просто mysql контейнера без дампа и -2) доп контейнера где отрабатывает wget и , собственно, mysql .
Может есть менее кривые способы?
2) Если всё таки завести 2-й контейнер,
упрощаю освной mysql до
- доавляю новый контейнер в docker-compose (фрагмент):
где, в свою очередь ./db-seed/Dockerfile выглядит примерно так:
Если же я закомментриую RUN ping db , стартанну стек через docker-compose up , дождусь пока контейнеры поднимуться , залогинюсь на mysql-seed и вручную пингану db/запущу залив дампа - всё ок, всё отрабатывает. Хост виден.
Что я делаю не так? На этапе build контейнер не должен видеть другие контейнеры?
Если так, то как тогда наиболее канонично запилить такую логику?
Пост не читал, но ты делаешь не так абсолютно всё. docker-compose не для прода, а для разработки и тестирования, а за MySQL в контейнере — вон из професии. Ты кто по должности и почему старшие позволяют тебе такое воротить?

причём тут прод вообще? Всё что я делаю - собираю стек для возможности быстрого развёртывания в любом окружении.
а за MySQL в контейнере — вон из професии.
это почему? Аргументы?
Ты даже данные никуда не примонтировал для персистентности, какие тебе ещё аргументы? Ты попросту не одупляешь, что делаешь.
Какой в жопу пинг на этапе сборки, какой нахрен залив дампа, алё? Собирать ты можешь на одном хосте сегодня, а запускать на другом через неделю. И разберись с тем как файловая система в контейнере работает, а то стыд испанский.
WitcherGeralt ★★ ( 27.02.20 03:33:10 )
Последнее исправление: WitcherGeralt 27.02.20 03:34:15 (всего исправлений: 1)

Просто понты вместо объяснения, таких токсичных ублюдков как раз из профессии и надо гнать ссаными тряпками.
По теме, второй контейнер можно без mysql а просто какой либо стандартный Alpine и там уже поставить mysql-tools внутри.
На момент собирания пакета Dockerfile-ом, он еще не добавляется в network, вся логика должна быть потом, популярное решение это скрипт который ждет пока успешно отработает ping, либо Wait-for-it
У бестолкового петушонка пригорело?
В нормальных тредах я нормально отвечаю и дажее более того, пруфов можешь найти вагон. Да и здесь я заяснил всё вполне доходчиво.
Человеку нужен быстро развёртываемый dev env, ты зачем-то начал плакать о мускуле на проде.

Мне кажется зашивать дамп базы внутрь image концептуально неверно. Соответственно надо подпихнуть его именно при запуске контейнера.
Вариант 1. Поменять логику старта mysql в контейнере, добавив скрипт, который загрузит базу.
Вариант 2. Сделать загрузку базы внешним инструментом, например вторым контейнером.
Вариант 3. Примонтировать volume, где перед запуском контейнера будет размещен дамп базы.

На этапе build контейнер не должен видеть другие контейнеры?
Нет. На этапе сборки в доступе нет ничего, кроме билд-директории, интернета и переданных переменных окружения.
Если так, то как тогда наиболее канонично запилить такую логику?
Все стандартные сервисные контейнеры, вроде мускуля, используешь как есть, в соответствии с их документацией. Для своего приложения создаёшь свой контейнер, и всё наполнение сервисных контейнеров контентом запихиваешь в скрипт запуска внутри своего контейнера. Если тебе надо сохранять данные между запусками - читай ещё раз про volumes и пиши свой скрипт соответствующе, что бы он не перетирал данные если они уже есть.
По большей части всё на данный момент. Мне кажется тут дело не в том, что именно ты делаешь, а в непонимании концепции докера и микросервисов в целом. Попробуй начать знакомство ещё раз, тут основные идеи могут показаться местами контринтуитивными.
manntes-live ★★★ ( 27.02.20 09:50:35 )
Последнее исправление: manntes-live 27.02.20 09:51:08 (всего исправлений: 1)
В одной из прошлых статей мы рассматривали как запустить контейнер Docker из образа. Основная идея Docker в том, что для каждого отдельного процесса должен быть создан отдельный контейнер Docker с окружением, нужным этому процессу. Но для сложных приложений здесь кроется проблема.
Например, для веб-приложения уже нужна база данных, веб-сервер, и возможно ещё интерпретатор PHP. Это уже три контейнера, настраивать и запускать их вручную не удобно, поэтому была придумана утилита docker-compose, которая позволяет управлять группами контейнеров, создавать их, настраивать, а также удалять одной командой. В этой статье мы разберемся как пользоваться docker для чайников. Подробно рассмотрим docker-compose, а также реальное применение утилиты.
Использование Docker для чайников
Поскольку эта инструкция про Docker для начинающих, я рекомендую сразу прочитать статью про запуск контейнера, вы поймете некоторые основы Docker, которые могут здесь вам пригодится. Там рассказано как всё делать вручную, а здесь мы уже поговорим как автоматизировать этот процесс.
1. Установка docker-compose
Если программа ещё не установлена, её необходимо установить. Для этого надо просто скачать исполняемый файл из официального сайта разработчиков:
sudo curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
И дать ему права на выполнение:
sudo chmod +x /usr/local/bin/docker-compose
После этого вы сможете посмотреть её версию:
2. Создание проекта
Если вы уже видели проекты, использующие docker, то, наверное, замечали, что в папке с проектом лежит файл под названием docker-compose.yaml. Именно в этом файле настраиваются контейнеры, которые надо создать для вашего проекта, потом они будут созданы автоматически с помощью docker-compose. Файл использует синтаксис YAML и должен содержать такие данные:
Версия указывает на версию синтаксиса файла, в разных версиях доступны разные ключевые слова, это сделано для обратной совместимости. Мы будем использовать версию 3.5. Далее нужно перечислить хранилища (volumes), сети (networks) и сами контейнеры.
Синтаксис YAML похож на JSON, здесь тоже есть пары ключ: значение, разделенные двоеточием, только тут значение может быть вообще нулевым, может содержать другие ключи, а также оно может быть массивом значений, тогда каждый элемент массива начинается с чёрточки "-". Но в отличие от JSON, здесь очень важны отступы, чтобы показать вложенность значений, поэтому не теряйте их.
Давайте создадим папку losst-docker и создадим в ней файл docker-compose.yaml:
version: '3.5'
services:

3. Добавление контейнеров
Рассмотрим содержимое самого простого пункта настройки контейнера:
Здесь нам обязательно надо указать имя будущего контейнера, а также образ, на основании которого он будет создан. Через двоеточие можно указывать версию контейнера. Версии можно посмотреть на Dockerhub они там отмечены как tags. Если версия не указана используется latest, последняя.
Например, добавим контейнер для веб-сервера Nginx:

Уже имея эти данные в конфигурационном файле можно запускать контейнер.
4. Запуск контейнеров
Когда настройка docker завершена, надо запускать полученные контейнеры. Чтобы запустить группу контейнеров, настроенную в docker-compose.yaml необходимо перейти в папку, где находится этот файл конфигурации и выполнить там команду docker-compose up. Например:

После этого контейнеры будут запущены, все их потоки вывода будут объединены в один и вам будет выводится информация в терминал. Чтобы остановить контейнеры достаточно нажать Ctrl+C. Если вы хотите запустить контейнеры в фоновом режиме используйте опцию -d:
docker-compose up -d

Остановить контейнеры, запущенные в фоновом режиме можно командой stop:
Команда down не просто останавливает все запущенные контейнеры, но и удаляет их:

Остановите пока этот контейнер, мы продолжим его настройку.
5. Порты контейнера
Контейнер работает, но толку пока нам от него мало. С помощью docker мы можем пробросить порт 80 контейнера в основную операционную систему и получить к нему доступ. Для этого используйте директиву ports. Синтаксис такой:
ports:
- внешний_порт : внутренний порт
Например, пробросим порт 80 как 8094:


Но это все ещё не интересно, потому что мы не можем размещать там свои файлы. Сейчас это исправим.
6. Монтирование папок
Для монтирования хранилищ или внешних папок хоста используется пункт volumes. Синтаксис очень похож на работу с портами:
volumes:
- /путь/к/внешней/папке : /путь/к/внутренней/папке
Например, давайте создадим в текущей папке проекта файл index.html и смонтируем эту папку вместо папки /usr/share/nginx/html/ контейнера:
После перезапуска контейнера вы увидите в браузере уже свою страницу. Это очень мощный инструмент, с помощью которого вы можете пробрасывать в контейнер всё, начиная от исходников и заканчивая конфигурационными файлами. Очень удобно.

7. Настройка хранилищ
Мы можем монтировать к контейнеру не только внешние папки, но и хранилища, создаваемые в docker. Для этого сначала надо добавить хранилище в главную секцию volumes. Например losst-vl:
Большинству веб приложений необходима база данных, например, MySQL. Добавим ещё один контейнер для этой базы данных и добавим в него наше хранилище. Хранилище добавляется также, как и внешняя папка, только вместо папки указывается название хранилища:

Здесь мы ещё добавили пункт environment, в котором задали переменные окружения для контейнера. Они необходимы, для того, чтобы указать имя базы данных и пароль root, которые будут использоваться по умолчанию. Как видите, с переменными окружения нет ничего сложного.

8. Настройка сети
Контейнеры должны взаимодействовать между собой. У нас уже есть Nginx и MySQL, им пока не нужно обращаться друг к другу, но как только у нас появится контейнер для PhpMyAdmin, которому надо обращаться к MariaDB ситуация поменяется. Для взаимодействия между контейнерами используются виртуальные сети, они добавляются похожим образом на хранилища. Сначала добавьте сеть в глобальную секцию networks:
Затем для каждого контейнера, которые будут иметь доступ к этой сети, надо добавить сеть в раздел networks.
Далее контейнеры будут доступны по сети по их имени. Например, добавим PhpMyAdmin и дадим ему доступ к базе данных:


9. Модификация контейнера
Это уже более сложные вещи, но зато вы разберетесь с Docker на практике. В большинстве случаев можно обойтись без модификации контейнера, иногда туда надо скопировать специфические конфигурационные файлы либо установить дополнительное программное обеспечение, для таких случаев docker-compose позволяет создавать свои контейнеры на основе уже существующих образов. Для этого надо создать файл Dockerfile на основе которого будет создаваться контейнер. Давайте добавим контейнер php-fpm и установим в него несколько расширений php с помощью Dockerfile.
Сначала создадим папку для файлов контейнера:
FROM php:7.2.26-fpm-stretch
RUN docker-php-ext-install pdo pdo_mysql pcntl
Вот основные директивы, которые можно использовать в этом файле:
- FROM - образ, на основе которого будет создаваться наш образ;
- RUN - выполнить команду в окружении образа;
- COPY - скопировать файл в образ;
- WORKDIR - задать рабочую папку для образа;
- ENV - задать переменную окружения образа;
- CMD - задать основной процесс образа;
Теперь надо добавить новую секцию в наш docker-compose.yaml. Здесь вместо image мы используем директиву build, которой надо передать путь к папке с конфигурацией образа:
Дальше, раз мы уже добавили php-fpm надо примонтировать для Nginx верный конфиг, который будет поддерживать php-fpm. Создайте папку nginx и поместите в неё такой конфигурационный файл:
server listen 80;
server_name _ !default;
root /var/www/;
add_header X-Frame-Options "SAMEORIGIN";
add_header X-XSS-Protection "1; mode=block";
add_header X-Content-Type-Options "nosniff";
index index.html index.htm index.php;
charset utf-8;
location / try_files $uri $uri/ /index.php?$query_string;
>
error_page 404 /index.php;
location ~ \.php$ fastcgi_pass docker-php-fpm:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
include fastcgi_params;
>
>

Осталось создать файл index.php и можно тестировать:
Теперь можно запускать контейнеры:

В отличие от предыдущего раза, теперь перед запуском будет собран новый контейнер на основе файла Dockerfile. Такие контейнеры собираются только первый раз, если они не существуют. Чтобы их пересобрать используйте опцию --build:
docker-compose up --build
Теперь у вас есть полноценное веб-приложение, которое доступно на вашем компьютере, может использовать базу данных, PHP и много чего другого. Вы можете добавить любые недостающие вам контейнеры.
10. Подключение к контейнеру
С помощью docker-compose вы можете подключится к любому контейнеру из группы. Для этого просто используйте команду exec. Например, запустите проект в фоновом режиме:
docker-compose up -d
И используйте docker-compose exec. Подключимся к контейнеру с Nginx:
docker-compose exec docker-nginx /bin/bash

Перед вами откроется оболочка Bash этого контейнера. Устанавливать здесь что-то вручную не рекомендуется, так как всё сотрётся после удаления контейнера, но для тестирования работы чего либо такая возможность будет очень кстати.
Выводы
В этой статье мы разобрали использование docker для чайников. Тема довольно обширная и сложная, но очень интересная. Развернув таким образом проект на одной машине, вы сможете развернуть его там, где вам нужно просто скопировав туда конфигурацию. Поэтому эта технология завоевала такую большую популярность среди разработчиков и DevOps.
Нет похожих записей
Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна.

Важная характеристика Docker-контейнеров — эфемерность. В любой момент контейнер может рестартовать: завершиться и вновь запуститься из образа. При этом все накопленные в нём данные будут потеряны. Но как в таком случае запускать в Docker приложения, которые должны сохранять информацию о своём состоянии? Для этого есть несколько инструментов.
В этой статье рассмотрим docker volumes, bind mount и tmpfs, дадим советы по их использованию, проведём небольшую практику.
Особенности работы контейнеров
Прежде чем перейти к способам хранения данных, вспомним устройство контейнеров. Это поможет лучше понять основную тему.
Контейнер создаётся из образа, в котором есть всё для начала его работы. Но там не хранится и тем более не изменяется ничего важного. В любой момент приложение в контейнере может быть завершено, а контейнер уничтожен, и это нормально. Контейнер отработал — выкидываем его и собираем новый. Если пользователь загрузил в приложение картинку, то при замене контейнера она удалится.

На схеме показано устройство контейнера, запущенного из образа Ubuntu 15.04. Контейнер состоит из пяти слоёв: четыре из них принадлежат образу, и лишь один — самому контейнеру. Слои образа доступны только для чтения, слой контейнера — для чтения и для записи. Если при работе приложения какие-то данные будут изменяться, они попадут в слой контейнера. Но при уничтожении контейнера слой будет безвозвратно потерян, и все данные вместе с ним.
В идеальном мире Docker используют только для запуска stateless-приложений, которые не читают и не сохраняют данные о своём состоянии и готовы в любой момент завершиться. Однако в реальности большинство программ относятся к категории stateful, то есть требуют сохранения данных между перезапусками.
Поэтому нужны способы сделать так, чтобы важные изменяемые данные не зависели от эфемерности контейнеров и, как бонус, были доступными сразу из нескольких мест.
В Docker есть несколько способов хранения данных. Наиболее распространенные:
- тома хранения данных (docker volumes),
- монтирование каталогов с хоста (bind mount).
- именованные каналы (named pipes, только в Windows),
- монтирование tmpfs (только в Linux).
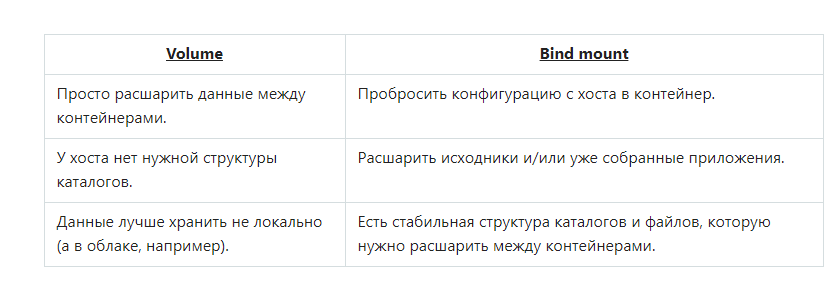
Тома (docker volumes)
Тома — рекомендуемый разработчиками Docker способ хранения данных. В Linux тома находятся по умолчанию в /var/lib/docker/volumes/. Другие программы не должны получать к ним доступ напрямую, только через контейнер.
Тома создаются и управляются средствами Docker: командой docker volume create, через указание тома при создании контейнера в Dockerfile или docker-compose.yml.
В контейнере том видно как обычный каталог, который мы определяем в Dockerfile. Тома могут быть с именами или без — безымянным томам Docker сам присвоит имя.
Один том может быть примонтирован одновременно в несколько контейнеров. Когда никто не использует том, он не удаляется, а продолжает существовать. Команда для удаления томов: docker volume prune.
Можно выбрать специальный драйвер для тома и хранить данные не на хосте, а на удалённом сервере или в облаке.
Для чего стоит использовать тома в Docker:
- шаринг данных между несколькими запущенными контейнерами,
- решение проблемы привязки к ОС хоста,
- удалённое хранение данных,
- бэкап или миграция данных на другой хост с Docker (для этого надо остановить все контейнеры и скопировать содержимое из каталога тома в нужное место).
Монтирование каталога с хоста (bind mount)
Это более простая концепция: файл или каталог с хоста просто монтируется в контейнер.
Используется, когда нужно пробросить в контейнер конфигурационные файлы с хоста. Например, именно так в контейнерах реализуется DNS: с хоста монтируется файл /etc/resolv.conf.
Другое очевидное применение — в разработке. Код находится на хосте (вашем ноутбуке), но исполняется в контейнере. Вы меняете код и сразу видите результат. Это возможно, так как процессы хоста и контейнера одновременно имеют доступ к одним и тем же данным.
Особенности bind mount:
- Запись в примонтированный каталог могут вести программы как в контейнере, так и на хосте. Это значит, есть риск случайно затереть данные, не понимая, что с ними работает контейнер.
- Лучше не использовать в продакшене. Для продакшена убедитесь, что код копируется в контейнер, а не монтируется с хоста.
- Для успешного монтирования указывайте полный путь к файлу или каталогу на хосте.
- Если приложение в контейнере запущено от root, а совместно используется каталог с ограниченными правами, то в какой-то момент может возникнуть проблема с правами на файлы и невозможность что-то удалить без использования sudo.
Монтирование tmpfs
Tmpfs — временное файловое хранилище. Это некая специально отведённая область в оперативной памяти компьютера. Из определения выходит, что tmpfs — не лучшее хранилище для важных данных. Так оно и есть: при остановке или перезапуске контейнера сохранённые в tmpfs данные будут навсегда потеряны.
На самом деле tmpfs нужно не для сохранения данных, а для безопасности, полученные в ходе работы приложения чувствительные данные безвозвратно исчезнут после завершения работы контейнера. Бонусом использования будет высокая скорость доступа к информации.
Например, приложение в контейнере тормозит из-за того, что в ходе работы активно идут операции чтения-записи, а диски на хосте не очень быстрые. Если вы не уверены, в какой каталог идёт эта нагрузка, можно применить к запущенному контейнеру команду docker diff. И вот этот каталог смонтировать как tmpfs, таким образом перенеся ввод-вывод с диска в оперативную память.
Такое хранилище может одновременно работать только с одним контейнером и доступно только в Linux.
Общие советы по использованию томов
Монтирование в непустые директории
Если вы монтируете пустой том в каталог контейнера, где уже есть файлы, то эти файлы не удалятся, а будут скопированы в том. Этим можно пользоваться, когда нужно скопировать данные из одного контейнера в другой.
Если вы монтируете непустой том или каталог с хоста в контейнер, где уже есть файлы, то эти файлы тоже не удалятся, а просто будут скрыты. Видно будет только то, что есть в томе или каталоге на хосте. Похоже на простое монтирование в Linux.
Монтирование служебных файлов
С хоста можно монтировать любые файлы, в том числе служебные. Например, сокет docker. В результате получится docker-in-docker: один контейнер запустится внутри другого. UPD: (*это не совсем так. mwizard в комментариях пояснил, что в таком случае родительский docker запустит sibling-контейнер). Выглядит как бред, но в некоторых случаях бывает оправдано. Например, при настройке CI/CD.
Монтирование /var/lib/docker
Разработчики Docker говорят, что не стоит монтировать с хоста каталог /var/lib/docker, так как могут возникнуть проблемы. Однако есть некоторые программы, для запуска которых это необходимо.
Практика: создадим тестовый том
Ключ командной строки для Docker при работе с томами.
Для volume или bind mount:
Команды для управления томами в интерфейсе CLI Docker:
Commands:
create Create a volume (Создать том)
inspect Display detailed information on one or more
volumes (Отобразить детальную информацию)
ls List volumes (Вывести список томов)
prune Remove all unused volumes (Удалить все неиспользуемые тома)
rm Remove one or more volumes (Удалить один или несколько томов)
Создадим тестовый том:
$ docker volume create slurm-storage
slurm-storage
Вот он появился в списке:
$ docker volume ls
DRIVER VOLUME NAME
local slurm-storage
Команда inspect выдаст примерно такой список информации в json:
Попробуем использовать созданный том, запустим с ним контейнер:
После самоуничтожения контейнера запустим другой и подключим к нему тот же том. Проверяем, что в нашем файле:
$ docker run --rm -v slurm-storage:/data -it centos:8 /bin/bash -c "cat /data/file"
13279
То же самое, отлично.
Теперь примонтируем каталог с хоста:
$ docker run -v /srv:/host/srv --name slurm --rm -it ubuntu:20.10 /bin/bash
Docker не любит относительные пути, лучше указывайте абсолютные!
Теперь попробуем совместить оба типа томов сразу:
$ docker run -v /srv:/host/srv -v slurm-storage:/data --name slurm --rm -it ubuntu:20.10 /bin/bash
Отлично! А если нам нужно передать ровно те же тома другому контейнеру?
$ docker run --volumes-from slurm --name backup --rm -it centos:8 /bin/bash
Вы можете заметить некий лаг в обновлении данных между контейнерами, это зависит от используемого Docker драйвера файловой системы.
Создавать том заранее необязательно, всё сработает в момент запуска docker run:
$ docker run -v newslurm:/newdata -v /srv:/host/srv -v slurm-storage:/data --name slurm --rm -it ubuntu:20.10 /bin/bash
Посмотрим теперь на список томов:
$ docker volume ls
DRIVER VOLUME NAME
local slurm-storage
local newslurm
Ещё немного усложним команду запуска, создадим анонимный том:
$ docker run -v /anonymous -v newslurm:/newdata -v /srv:/host/srv -v slurm-storage:/data --name slurm --rm -it ubuntu:20.10 /bin/bash
Такой том самоуничтожится после выхода из контейнера, так как мы указали ключ –rm.
Если этого не сделать, давайте проверим что будет:
$ docker run -v /anonymous -v newslurm:/newdata -v /srv:/host/srv -v slurm-storage:/data --name slurm -it ubuntu:20.10 /bin/bash
$ docker volume ls
DRIVER VOLUME NAME
local 04c490b16184bf71015f7714b423a517ce9599e9360af07421ceb54ab96bd333
local newslurm
local slurm-storage
Хозяйке на заметку: тома (как образы и контейнеры) ограничены значением настройки dm.basesize, которая устанавливается на уровне настроек демона Docker. Как правило, что-то около 10Gb. Это значение можно изменить вручную, но потребуется перезапуск демона Docker.
При запуске демона с ключом это выглядит так:
$ sudo dockerd --storage-opt dm.basesize=40G
Однажды увеличив значение, его уже нельзя просто так уменьшить. При запуске Docker выдаст ошибку.
Если вам нужно вручную очистить содержимое всех томов, придётся удалять каталог, предварительно остановив демон:
$ sudo service docker stop
$ sudo rm -rf /var/lib/docker

Создание каждого проекта начинается с файла docker-compose.yml в корне проекта:
Здесь указываются реквизиты подключения к создаваемой базе данных (саму базу создавать не нужно) и путь к корню сайта внутри виртуального контейнера — /var/doodle .
Там же, в корне, создаём папку .docker , в ней будет лежать файл Dockerfile — здесь команды, которые будут выполнены при создании контейнера для PHP. Обычно из проекта в проект файл не меняется, там всё стандартно — .docker/Dockerfile
И в этой же папке будем хранить конфиг сервера, в файле vhost.conf — .docker/vhost.conf, он тоже стандартный, единственное, указываем правильный путь к публичной директории. У меня это /var/doodle/www .

Вот так выглядит набор файлов на первом этапе:
Теперь запускаем создание контейнеров — docker-compose up -d . В первый раз будут скачиваться нужные файлы, будет происходить установка контейнеров и прочее. В дальнейшем эта команда просто запустит уже готовые контейнеры.
В качестве хоста для базы данных на MacOS нужно использовать host.docker.internal . Логин, пароль и имя базы данных указываем те, которые мы указали в docker-compose.yml

После установки MODX можно добавить в корень проекта .gitignore , чтобы лишние файлы в репозиторий не выгружались — .gitignore. И создать, собственно, git-репозиторий:
Думаю, всем более-менее понятно, что в репозитории легко хранятся файловые элементы. Но в MODX до сих пор очень плотно приходится работать с базой данных и в команде нужно как-то синхронизировать записи в таблицах, саму структуру и пр.
Поэтому в командной работе приходится плотно знакомиться с миграциями. Миграции — это просто скрипты, которые производят операции в базе данных. То есть вместо того, чтобы создавать ресурс через админку MODX, вам нужно писать скрипт, который будет это делать — через newObject или runProcessor .
Для миграций удобно использовать phinx. Его просто установить через composer:
Настройки миграций хранятся в файле phinx.php — здесь мы подключаем конфиг MODX, соответственно, реквизиты подключения к базе данных берём из этого конфига. Так же указываем шаблон для создания новых миграций db/modx_migration_template.php, где вы можете сохранить требуемую вам структуру файла миграций. Этот шаблон будет использоваться для всех новых команд.
Мы окажемся в папке /var/www/html . Перейдём в папку проекта и создадим нашу первую миграцию:
Эта команда создаст файл в папке db/migrations . Вот так выглядит переименование главной страницы — db/migrations/20211010090307_first_migration.php, а вот так можно установить нужные пакеты — db/migrations/20211010092235_install_packages.php
Но все эти сложности нужны не просто так, а для реализации командной разработки и лёгкого деплоя. Давайте, разберёмся, как теперь выгрузить нашу работу на продакшен.
Первая сложность, с которой мы столкнёмся — это доступы к базе данных в конфиг-файле. Во-первых, хранить пароль к базе данных от продакшена в гитхабе — это плохая идея. А во-вторых, у каждого локальные доступы к базе данных будут свои, нужно это предусмотреть. Отредактируем www/core/config/config.inc.php — в начале файла проверим наличие локального конфига с доступами:
Таким образом в файле config.environment.inc.php мы будем переопределять доступы к базе данных. Этот файл уже добавлен в .gitignore и в репозиторий выгружаться не будет. Так же нужно отредактировать файлы config.core.php — поменять там пути на относительные.

Чтобы сайт был доступен извне, создадим символическую ссылку для папки www
И укажем доступы к базе данных в файле doodle/www/core/config/config.environment.inc.php :
Теперь останется запустить миграции:
На этом всё — продакшен развёрнут. Можно продолжать разработку локально, в разных ветках. А деплой будет заключаться в стягивании изменений из гитхаба и запуске миграций:
Читайте также: