
Как сделать логистическую регрессию в питоне
Обновлено: 06.07.2024
Существует два типа алгоритмов машинного обучения с учителем: регрессия и классификация. Первый прогнозирует непрерывные выходы значений, а второй – дискретные. Например, прогнозирование стоимости дома в долларах является проблемой регрессии, тогда как прогнозирование злокачественной или доброкачественной опухоли является проблемой классификации.
В этой статье мы кратко изучим, что такое линейная регрессия и как ее можно реализовать с помощью библиотеки Python Scikit-Learn, которая является одной из самых популярных библиотек машинного обучения для Python.
Теория линейной регрессии
Давайте рассмотрим скрипт, в котором мы хотим определить линейную зависимость между количеством часов, которые студент учится, и процентом оценок, которые студент набирает на экзамене. Мы хотим выяснить, сколько часов ученик готовится к тесту, насколько высокий балл он может набрать? Если мы нанесем независимую переменную (часы) на ось x, а зависимую переменную (процент) на ось y, линейная регрессия даст нам прямую линию, которая наилучшим образом соответствует точкам данных, как показано на рисунке ниже.

Мы знаем, что уравнение прямой в основном:
Где, b – точка пересечения, а m – наклон линии. Таким образом, алгоритм линейной регрессии дает нам наиболее оптимальное значение для точки пересечения и наклона (в двух измерениях). Переменные y и x остаются неизменными, поскольку они являются функциями данных и не могут быть изменены. Значения, которые мы можем контролировать, – это точка пересечения и наклон. В зависимости от значений точки пересечения и наклона может быть несколько прямых линий. По сути, алгоритм линейной регрессии помещает несколько строк в точки данных и возвращает строку, которая дает наименьшую ошибку.
Эту же концепцию можно распространить на случаи, когда существует более двух переменных. Это называется множественной линейной регрессией. Например, рассмотрим скрипт, в котором вы должны спрогнозировать цену дома на основе его площади, количества спален, среднего дохода людей в этом районе, возраста дома и т.д. В этом случае зависимая переменная зависит от нескольких независимых переменных. Модель регрессии, включающая несколько переменных, может быть представлена как:
Это уравнение гиперплоскости. Помните, что модель линейной регрессии в двух измерениях – это прямая линия, в трех измерениях – это плоскость, а в более чем трех измерениях – гиперплоскость.
Линейная регрессия
В этом разделе мы увидим, как библиотеку Scikit-Learn в Python для машинного обучения можно использовать для реализации функций регрессии. Мы начнем с простой линейной регрессии с участием двух переменных, а затем перейдем к линейной регрессии с участием нескольких переменных.
Простая линейная регрессия
В этой задаче регрессии мы спрогнозируем процент оценок, которые, как ожидается, получит студент, на основе количества часов, которые он изучил. Это простая задача линейной регрессии, поскольку она включает всего две переменные.
Импорт библиотек
Чтобы импортировать необходимые библиотеки для этой задачи, выполните следующие операторы импорта:
Примечание. Как вы могли заметить из приведенных выше операторов импорта, этот код был выполнен с использованием Jupyter iPython Notebook.
Набор данных
Следующая команда импортирует набор данных CSV с помощью Pandas:
Теперь давайте немного исследуем наш набор данных. Для этого выполните следующий скрипт:
После этого вы должны увидеть следующее:
Это означает, что в нашем наборе данных 25 строк и 2 столбца. Давайте посмотрим, как на самом деле выглядит наш набор данных. Для этого используйте метод head():
Вышеупомянутый метод извлекает первые 5 записей из нашего набора данных, которые будут выглядеть следующим образом:
| Часы | Очки | |
|---|---|---|
| 0 | 2,5 | 21 год |
| 1 | 5.1 | 47 |
| 2 | 3,2 | 27 |
| 3 | 8,5 | 75 |
| 4 | 3.5 | 30 |
Чтобы увидеть статистические детали набора данных, мы можем использовать description():
| Часы | Очки | |
|---|---|---|
| count | 25,000000 | 25,000000 |
| mean | 5,012000 | 51,480000 |
| std | 2,525094 | 25,286887 |
| min | 1 100 000 | 17,000000 |
| 25% | 2,700000 | 30,000000 |
| 50% | 4,800000 | 47,000000 |
| 75% | 7,400000 | 75,000000 |
| max | 9.200000 | 95,000000 |
И, наконец, давайте нарисуем наши точки данных на двухмерном графике, чтобы взглянуть на наш набор данных и посмотреть, сможем ли мы вручную найти какую-либо связь между данными. Мы можем создать сюжет с помощью следующего скрипта:
В результате сюжет будет выглядеть так:

Из приведенного выше графика мы можем ясно видеть, что существует положительная линейная зависимость между количеством изученных часов и процентом набранных баллов.
Подготовка данных
Теперь, когда у нас есть атрибуты и метки, следующим шагом будет разделение этих данных на обучающий и тестовый наборы. Мы сделаем это с помощью встроенного в Scikit-Learn метода train_test_split():
Приведенный выше скрипт разделяет 80% данных на обучающий набор, а 20% данных – на набор тестов. Переменная test_size -–это то место, где мы фактически указываем пропорцию набора тестов.
Обучение алгоритму
Мы разделили наши данные на наборы для обучения и тестирования, и теперь, наконец, пришло время обучить наш алгоритм. Выполните следующую команду:
С Scikit-Learn чрезвычайно просто реализовать модели линейной регрессии, поскольку все, что вам действительно нужно сделать, это импортировать класс LinearRegression, создать его экземпляр и вызвать метод fit() вместе с нашими обучающими данными. Это примерно так же просто, как и при использовании библиотеки машинного обучения.
В разделе теории мы сказали, что модель линейной регрессии в основном находит наилучшее значение для точки пересечения и наклона, в результате чего получается линия, которая наилучшим образом соответствует данным. Чтобы увидеть значение точки пересечения и наклона, вычисленное алгоритмом линейной регрессии для нашего набора данных, выполните следующий код.
Чтобы получить перехват:
Полученное значение должно быть примерно 2,01816004143.
Для получения наклона (коэффициента x):
Результат должен быть примерно 9.91065648.
Это означает, что на каждую единицу изменения в изученных часах изменение оценки составляет около 9,91%. Или, проще говоря, если студент учится на один час больше, чем готовился к экзамену ранее, он может рассчитывать на повышение на 9,91% баллов, полученных студентом ранее.
Прогнозы
Теперь, когда мы обучили наш алгоритм, пришло время сделать некоторые прогнозы. Для этого мы воспользуемся нашими тестовыми данными и посмотрим, насколько точно наш алгоритм предсказывает процентную оценку. Чтобы сделать прогнозы на тестовых данных, выполните следующий скрипт:
Y_pred – это массив numpy, который содержит все предсказанные значения для входных значений в серии X_test.
Чтобы сравнить фактические выходные значения для X_test с прогнозируемыми значениями, выполните следующий скрипт:
Результат выглядит так:
| Действительный | Прогнозируемый | |
|---|---|---|
| 0 | 20 | 16,884145 |
| 1 | 27 | 33,732261 |
| 2 | 69 | 75.357018 |
| 3 | 30 | 26.794801 |
| 4 | 62 | 60,491033 |
Хотя наша модель не очень точна, прогнозируемые проценты близки к фактическим.
Значения в вышеприведенных столбцах могут отличаться в вашем случае, потому что функция train_test_split случайным образом разбивает данные на обучающие и тестовые наборы, и ваши разбиения, вероятно, будут отличаться от показанного в этой статье.
Оценка алгоритма
- Средняя абсолютная ошибка (MAE) – это среднее абсолютное значение ошибок. Он рассчитывается как:

К счастью, нам не нужно выполнять эти вычисления вручную. Библиотека Scikit-Learn поставляется со встроенными функциями, которые можно использовать, чтобы узнать эти значения для нас.
Давайте найдем значения этих показателей, используя наши тестовые данные. Выполните следующий код:
Результат будет выглядеть примерно так (но, вероятно, немного иначе):
Вы можете видеть, что значение среднеквадратичной ошибки составляет 4,64, что составляет менее 10% от среднего значения процентов всех студентов, т.е. 51,48. Это означает, что наш алгоритм проделал достойную работу.
Множественная линейная регрессия
В этом разделе мы будем использовать множественную линейную регрессию для прогнозирования потребления газа (в миллионах галлонов) в 48 штатах США на основе налогов на газ (в центах), дохода на душу населения (в долларах), дорог с твердым покрытием (в милях) и доли население, имеющее водительские права.
Первые два столбца в приведенном выше наборе данных не предоставляют никакой полезной информации, поэтому они были удалены из файла набора данных. Теперь давайте разработаем регрессионную модель для этой задачи.
Импорт библиотек
Следующий скрипт импортирует необходимые библиотеки:
Набор данных
Следующая команда импортирует набор данных из файла:
Как и в прошлый раз, давайте посмотрим, как на самом деле выглядит наш набор данных. Выполните команду head():
Первые несколько строк нашего набора данных выглядят так:
| Petrol_tax | Средний заработок | Асфальтированные, шоссе | Population_Driver_license (%) | Petrol_Consumption | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 г. | 0,525 | 541 |
| 1 | 9.0 | 4092 | 1250 | 0,572 | 524 |
| 2 | 9.0 | 3865 | 1586 | 0,580 | 561 |
| 3 | 7,5 | 4870 | 2351 | 0,529 | 414 |
| 4 | 8.0 | 4399 | 431 | 0,544 | 410 |
Чтобы увидеть статистические детали набора данных, мы снова воспользуемся командой describe():
| Petrol_tax | Средний заработок | Асфальтированные, шоссе | Population_Driver_license (%) | Petrol_Consumption | |
|---|---|---|---|---|---|
| count | 48,000000 | 48,000000 | 48,000000 | 48,000000 | 48,000000 |
| mean | 7,668333 | 4241.833333 | 5565.416667 | 0,570333 | 576.770833 |
| std | 0,950770 | 573,623768 | 3491.507166 | 0,055470 | 111,885816 |
| min | 5,000000 | 3063.000000 | 431,000000 | 0,451000 | 344,000000 |
| 25% | 7,000000 | 3739.000000 | 3110.250000 | 0,529750 | 509 500 000 |
| 50% | 7,500000 | 4298.000000 | 4735.500000 | 0,564500 | 568 500 000 |
| 75% | 8,125 000 | 4578.750000 | 7156.000000 | 0,595250 | 632,750000 |
| max | 10,00000 | 5342.000000 | 17782,000000 | 0,724000 | 986,000000 |
Подготовка данных
Следующим шагом является разделение данных на атрибуты и метки, как мы делали ранее. Однако, в отличие от прошлого раза, на этот раз мы собираемся использовать имена столбцов для создания набора атрибутов и метки. Выполните следующий скрипт:
Выполните следующий код, чтобы разделить наши данные на обучающий и тестовый наборы:
Обучение алгоритму
И, наконец, для обучения алгоритма мы выполняем тот же код, что и раньше, используя метод fit() класса LinearRegression:
Как было сказано ранее, в случае многомерной линейной регрессии регрессионная модель должна найти наиболее оптимальные коэффициенты для всех атрибутов. Чтобы увидеть, какие коэффициенты выбрала наша регрессионная модель, выполните следующий скрипт:
Результат должен выглядеть примерно так:
| Коэффициент | |
|---|---|
| Petrol_tax | -24.196784 |
| Average_income | -0,81680 |
| Paved_Highways | -0,000522 |
| Population_Driver_license (%) | 1324.675464 |
Прогнозы
Чтобы сделать прогнозы на тестовых данных, выполните следующий скрипт:
Чтобы сравнить фактические выходные значения для X_test с прогнозируемыми значениями, выполните следующий скрипт:
Результат выглядит так:
| Действительный | Прогнозируемый | |
|---|---|---|
| 36 | 640 | 643.176639 |
| 22 | 464 | 411.950913 |
| 20 | 649 | 683,712762 |
| 38 | 648 | 728.049522 |
| 18 | 865 | 755.473801 |
| 1 | 524 | 559.135132 |
| 44 год | 782 | 671.916474 |
| 21 год | 540 | 550,633557 |
| 16 | 603 | 594,425464 |
| 45 | 510 | 525.038883 |
Оценка алгоритма
Последний шаг – оценить производительность алгоритма. Мы сделаем это, найдя значения для MAE, MSE и RMSE. Выполните следующий скрипт:
Результат будет выглядеть примерно так:
Вы можете видеть, что значение среднеквадратичной ошибки составляет 60,07, что немного больше 10% от среднего значения потребления газа во всех штатах. Это означает, что наш алгоритм не был очень точным, но все же может делать достаточно хорошие прогнозы.
- Требуется больше данных: данных за один год – это не так уж и много, тогда как накопление данных за несколько лет могло бы помочь нам немного повысить точность.
- Ошибочные предположения: мы предположили, что эти данные имеют линейную зависимость, но это может быть не так. Визуализация данных может помочь вам определить это.
- Плохие функции: используемые нами функции могли не иметь достаточно высокой корреляции со значениями, которые мы пытались предсказать.
Заключение
В этой статье мы изучили один из самых фундаментальных алгоритмов машинного обучения, то есть линейную регрессию. Мы реализовали как простую линейную регрессию, так и множественную линейную регрессию с помощью библиотеки машинного обучения Scikit-Learn.

Для примера можно взять сотрудников какой-нибудь компании и понять, как значение зарплаты зависит от других данных, таких как опыт работы, уровень образования, роль, город, в котором они работают, и так далее.
Регрессия решает проблему единого представления данных анализа для каждого работника. Причём опыт, образование, роль и город – это независимые переменные при зависимой от них зарплате.
Таким же способом можно установить математическую зависимость между ценами домов в определённой области, количеством комнат, расстоянием от центра и т. д.
Регрессия рассматривает некоторое явление и ряд наблюдений. Каждое наблюдение имеет две и более переменных. Предполагая, что одна переменная зависит от других, вы пытаетесь построить отношения между ними.
Другими словами, вам нужно найти функцию, которая отображает зависимость одних переменных или данных от других.
Зависимые данные называются зависимыми переменными, выходами или ответами.
Независимые данные называются независимыми переменными, входами или предсказателями.
Общей практикой является обозначение данных на выходе – ?, входных данных – ?. В случае с двумя или более независимыми переменными, их можно представить в виде вектора ? = (?₁, …, ?ᵣ), где ? – количество входных переменных.
Регрессия полезна для прогнозирования ответа на новые условия. Можно угадать потребление электроэнергии в жилом доме из данных температуры, времени суток и количества жильцов.
Где она вообще нужна?
Регрессия используется во многих отраслях: экономика, компьютерные и социальные науки, прочее. Её важность растёт с доступностью больших данных.
Линейная регрессия – одна из важнейших и широко используемых техник регрессии. Эта самый простой метод регрессии. Одним из его достоинств является лёгкость интерпретации результатов.
Постановка проблемы
Линейная регрессия некоторой зависимой переменной y на набор независимых переменных x = (x₁, …, xᵣ), где r – это число предсказателей, предполагает, что линейное отношение между y и x: y = 𝛽₀ + 𝛽₁x₁ + ⋯ + 𝛽ᵣxᵣ + 𝜀. Это уравнение регрессии. 𝛽₀, 𝛽₁, …, 𝛽ᵣ – коэффициенты регрессии, и 𝜀 – случайная ошибка.
Линейная регрессия вычисляет оценочные функции коэффициентов регрессии или просто прогнозируемые весы измерения, обозначаемые как b₀, b₁, …, bᵣ. Они определяют оценочную функцию регрессии f(x) = b₀ + b₁x₁ + ⋯ + bᵣxᵣ. Эта функция захватывает зависимости между входами и выходом достаточно хорошо.
Для каждого результата наблюдения i = 1, …, n, оценочный или предсказанный ответ f(xᵢ) должен быть как можно ближе к соответствующему фактическому ответу yᵢ. Разницы yᵢ − f(xᵢ) для всех результатов наблюдений называются остатками. Регрессия определяет лучшие прогнозируемые весы измерения, которые соответствуют наименьшим остаткам.
Для получения лучших весов, вам нужно минимизировать сумму остаточных квадратов (SSR) для всех результатов наблюдений: SSR = Σᵢ(yᵢ − f(xᵢ))². Этот подход называется методом наименьших квадратов.
Простая линейная регрессия
Простая или одномерная линейная регрессия – случай линейной регрессии с единственной независимой переменной x.
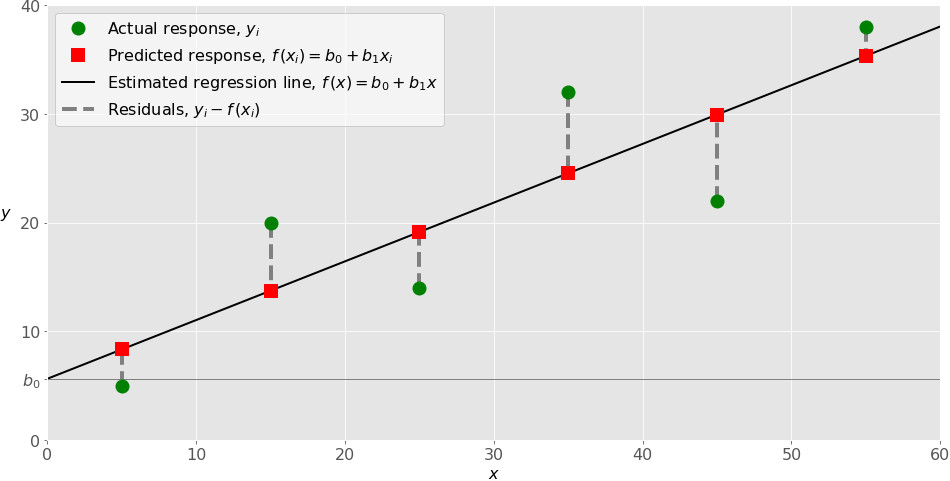
Реализация простой линейной регрессии начинается с заданным набором пар (зелёные круги) входов-выходов (x-y). Эти пары – результаты наблюдений. Наблюдение, крайнее слева (зелёный круг) имеет на входе x = 5 и соответствующий выход (ответ) y = 5. Следующее наблюдение имеет x = 15 и y = 20, и так далее.
Оценочная функция регрессии (чёрная линия) выражается уравнением f(x) = b₀ + b₁x. Нужно рассчитать оптимальные значения спрогнозированных весов b₀ и b₁ для минимизации SSR и определить оценочную функцию регрессии. Величина b₀, также называемая отрезком, показывает точку, где расчётная линия регрессии пересекает ось y. Это значение расчётного ответа f(x) для x = 0. Величина b₁ определяет наклон расчетной линии регрессии.
Предсказанные ответы (красные квадраты) – точки линии регрессии, соответствующие входным значениям. Для входа x = 5 предсказанный ответ равен f(5) = 8.33 (представленный крайним левыми квадратом).
Остатки (вертикальные пунктирные серые линии) могут быть вычислены как yᵢ − f(xᵢ) = yᵢ − b₀ − b₁xᵢ для i = 1, …, n. Они представляют собой расстояния между зелёными и красными пунктами. При реализации линейной регрессии вы минимизируете эти расстояния и делаете красные квадраты как можно ближе к предопределённым зелёным кругам.
Пришло время реализовать линейную регрессию в Python. Всё, что вам нужно, – подходящие пакеты, функции и классы.
Пакеты Python для линейной регрессии
NumPy – фундаментальный научный пакет для быстрых операций над одномерными и многомерными массивами. Он облегчает математическую рутину и, конечно, находится в open-source.
Незнакомы с NumPy? Начните с официального гайда.
Пакет scikit-learn – это библиотека, широко используемая в машинном обучении. Она предоставляет значения для данных предварительной обработки, уменьшает размерность, реализует регрессию, классификацию, кластеризацию и т. д. Находится в open-source, как и NumPy.
Начните знакомство с линейными моделями и работой пакета на сайте scikit-learn.
Простая линейная регрессия со scikit-learn
Начнём с простейшего случая линейной регрессии.
Следуйте пяти шагам реализации линейной регрессии:
- Импортируйте необходимые пакеты и классы.
- Предоставьте данные для работы и преобразования.
- Создайте модель регрессии и приспособьте к существующим данным.
- Проверьте результаты совмещения и удовлетворительность модели.
- Примените модель для прогнозов.
Это общие шаги для большинства подходов и реализаций регрессии.
Шаг 1: Импортируйте пакеты и классы
Первым шагом импортируем пакет NumPy и класс LinearRegression из sklearn.linear_model :
Теперь у вас есть весь функционал для реализации линейной регрессии.
Фундаментальный тип данных NumPy – это тип массива numpy.ndarray . Далее под массивом подразумеваются все экземпляры типа numpy.ndarray .
Класс sklearn.linear_model.LinearRegression используем для линейной регрессии и прогнозов.
Шаг 2 : Предоставьте данные
Теперь у вас два массива: вход x и выход y. Вам нужно вызвать .reshape() на x, потому что этот массив должен быть двумерным или более точным – иметь одну колонку и необходимое количество рядов. Это как раз то, что определяет аргумент (-1, 1).
Вот как x и y выглядят теперь:
Шаг 3: Создайте модель
На этом шаге создайте и приспособьте модель линейной регрессии к существующим данным.
Давайте сделаем экземпляр класса LinearRegression , который представит модель регрессии:
Эта операция создаёт переменную model в качестве экземпляра LinearRegression . Вы можете предоставить несколько опциональных параметров классу LinearRegression :
- fit_intercept – логический ( True по умолчанию) параметр, который решает, вычислять отрезок b₀ ( True ) или рассматривать его как равный нулю ( False ).
- normalize – логический ( False по умолчанию) параметр, который решает, нормализовать входные переменные ( True ) или нет ( False ).
- copy_X – логический ( True по умолчанию) параметр, который решает, копировать ( True ) или перезаписывать входные переменные ( False ).
- n_jobs – целое или None (по умолчанию), представляющее количество процессов, задействованных в параллельных вычислениях. None означает отсутствие процессов, при -1 используются все доступные процессоры.
Наш пример использует состояния параметров по умолчанию.
Пришло время задействовать model . Сначала вызовите .fit() на model :
С помощью .fit() вычисляются оптимальные значение весов b₀ и b₁, используя существующие вход и выход (x и y) в качестве аргументов. Другими словами, .fit() совмещает модель. Она возвращает self - переменную model . Поэтому можно заменить две последние операции на:
Эта операция короче и делает то же, что и две предыдущие.
Шаг 4: Получите результаты
После совмещения модели нужно убедиться в удовлетворительности результатов для интерпретации.
Вы можете получить определения (R²) с помощью .score() , вызванной на model :
.score() принимает в качестве аргументов предсказатель x и регрессор y, и возвращает значение R².
model содержит атрибуты .intercept_ , который представляет собой коэффициент, и b₀ с .coef_ , которые представляют b₁:
Код выше показывает, как получить b₀ и b₁. Заметьте, что .intercept_ – это скаляр, в то время как .coef_ – массив.
Примерное значение b₀ = 5.63 показывает, что ваша модель предсказывает ответ 5.63 при x, равном нулю. Равенство b₁ = 0.54 означает, что предсказанный ответ возрастает до 0.54 при x, увеличенным на единицу.
Заметьте, что вы можете предоставить y как двумерный массив. Тогда результаты не будут отличаться:
Как вы видите, пример похож на предыдущий, но в данном случае .intercept_ – одномерный массив с единственным элементом b₀, и .coef_ – двумерный массив с единственным элементом b₁.
Шаг 5: Предскажите ответ
Когда вас устроит ваша модель, вы можете использовать её для прогнозов с текущими или другими данными.
Получите предсказанный ответ, используя .predict() :
Применяя .predict() , вы передаёте регрессор в качестве аргумента и получаете соответствующий предсказанный ответ.
Вот почти идентичный способ предсказать ответ:
В этом случае вы умножаете каждый элемент массива x с помощью model.coef_ и добавляете model.intercept_ в ваш продукт.
Вывод отличается от предыдущего примера количеством измерений. Теперь предсказанный ответ – это двумерный массив, в отличии от предыдущего случая, в котором он одномерный.
Измените количество измерений x до одного, и увидите одинаковый результат. Для этого замените x на x.reshape(-1) , x.flatten() или x.ravel() при умножении с помощью model.coef_ .
На практике модель регрессии часто используется для прогнозов. Это значит, что вы можете использовать приспособленные модели для вычисления выходов на базе других, новых входов:
Здесь .predict() применяется на новом регрессоре x_new и приводит к ответу y_new . Этот пример удобно использует arange() из NumPy для генерации массива с элементами от 0 (включительно) до 5 (исключительно) – 0, 1, 2, 3, и 4.

Изучение
Машинное обучение — это быстрорастущая технология в современном мире. Машинное обучение уже интегрировано в нашу повседневную жизнь с такими инструментами, как распознавание лиц, помощники по дому, сканеры резюме и беспилотные автомобили.
Scikit-learn — самая популярная библиотека Python для выполнения алгоритмов классификации, регрессии и кластеризации. Это важная часть других библиотек науки о данных Python, таких как matplotlib, NumPy(для графиков и визуализации) и SciPy(для математики).
В нашей последней статье о Scikit-learn мы познакомили с основами этой библиотеки наряду с наиболее распространенными операциями. Сегодня мы расширяем наши знания Scikit-learn на один шаг дальше и научим вас проводить классификацию и регрессию, а затем 10 самых популярных методов для каждого из них.
Напоминание о машинном обучении
Машинное обучение учит компьютер выполнять и изучать задачи без явного программирования. Это означает, что система обладает определенной степенью способности принимать решения. Машинное обучение можно разделить на три основные категории:
- Контролируемое обучение
- Неконтролируемое обучение
- Обучение с подкреплением

Контролируемое обучение
В этой модели машинного обучения наша система обучается под наблюдением учителя. Модель имеет известные входные и выходные данные, используемые для обучения. Учитель знает результат в процессе обучения и тренирует модель, чтобы уменьшить ошибку в прогнозировании. Двумя основными типами контролируемых методов обучения являются классификация и регрессия.
Неконтролируемое обучение
Неконтролируемое обучение относится к моделям, в которых нет руководителя процесса обучения. Модель использует только входные данные для обучения. Выход узнается только из входов. Основным типом обучения без учителя является кластеризация, в которой мы группируем похожие вещи вместе, чтобы найти закономерности в немаркированных наборах данных.
Обучение с подкреплением
В этом посте я собираюсь объяснить два основных метода обучения с учителем :
Как реализовать классификацию и регрессию
Python предоставляет множество инструментов для реализации классификации и регрессии. Самая популярная библиотека науки о данных Python с открытым исходным кодом — scikit-learn. Давайте узнаем, как использовать scikit-learn для выполнения классификации и регрессии простым языком.
Классификация – отнесение объекта к одной из категорий на основании его признаков.
Метрики качества классификаторов
Матрица ошибок (Confusion matrix)
Матрица ошибок — это способ разбить объекты на четыре категории в зависимости от комбинации истинного ответа и ответа алгоритма.

Гораздо более информативными критериями являются точность (precision) и полнота (recall).
Точность показывает, какая доля объектов, выделенных классификатором как положительные, действительно является положительными: P r e c i s i o n = T P T P + F P Precision = \frac P rec i s i o n = TP + FP TP

Полнота показывает, какая часть положительных объектов была выделена классификатором: R e c a l l = T P T P + F N Recall = \frac R ec a ll = TP + FN TP
Среднее гармоническое обладает важным свойством — оно близко к нулю, если хотя бы один из аргументов близок к нулю. Именно поэтому оно является более предпочтительным, чем среднее арифметическое (если алгоритм будет относить все объекты к положительному классу, то он будет иметь recall = 1 и precision больше 0, а их среднее арифметическое будет больше 1/2, что недопустимо).
В sklearn есть удобная функция sklearn.metrics.classification_report, возвращающая recall, precision и F-меру для каждого из классов, а также количество экземпляров каждого класса.
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
micro avg 0.60 0.60 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5
Линейная классификация

Основная идея линейного классификатора заключается в том, что признаковое пространство может быть разделено гиперплоскостью на две полуплоскости, в каждой из которых прогнозируется одно из двух значений целевого класса. Если это можно сделать без ошибок, то обучающая выборка называется линейно разделимой.
Указанная разделяющая плоскость называется линейным дискриминантом.
Логистическая регрессия
Логистическая регрессия является частным случаем линейного классификатора, но она обладает хорошим "умением" – прогнозировать вероятность отнесения наблюдения к классу. Таким образом, результат логистической регрессии всегда находится в интервале [0, 1].
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
/usr/local/lib/python3.7/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
(array([[3.5, 1. ],
[5.5, 1.8],
[5.7, 2.5],
[5. , 1.5],
[5.8, 1.8]]), array([[-0.18295039, -0.29318114],
[ 0.93066067, 0.7372463 ],
[ 1.04202177, 1.63887031],
[ 0.6522579 , 0.35083601],
[ 1.09770233, 0.7372463 ]]))
/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:433: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:460: FutureWarning: Default multi_class will be changed to 'auto' in 0.22. Specify the multi_class option to silence this warning.
"this warning.", FutureWarning)
LogisticRegression(C=100.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='warn',
n_jobs=None, penalty='l2', random_state=1, solver='warn',
tol=0.0001, verbose=0, warm_start=False)
array([[2.77475804e-08, 6.31730607e-02, 9.36826912e-01],
[7.87476628e-03, 9.91707489e-01, 4.17744834e-04],
[8.15542033e-01, 1.84457967e-01, 8.14812482e-12]])
Предсказываем класс первого наблюдения
На основе его коэффициентов:
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Машина опорных векторов
Основная идея метода — перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
На практике случаи, когда данные можно разделить гиперплоскостью, довольно редки. В этом случае поступают так: все элементы обучающей выборки вкладываются в пространство X более высокой размерности, так, чтобы выборка была линейно разделима.
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=False, random_state=1,
shrinking=True, tol=0.001, verbose=False)

Kernel (ядро) отвечается за гиперплоскость и может принимать значения linear (для линейной), rbf (для нелинейной) и другие.
С - параметр регуляризации. Он в том числе контролирует соотношение между гладкой границей и корректной классификацией рассматриваемых точек.
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Нелинейная классификация

SVC(C=10.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.1, kernel='rbf',
max_iter=-1, probability=False, random_state=1, shrinking=True,
tol=0.001, verbose=False)
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Деревья решений
Деревья решений используются в повседневной жизни в самых разных областях человеческой деятельности.
До внедрения масштабируемых алгоритмов машинного обучения в банковской сфере задача кредитного скоринга решалась экспертами. Решение о выдаче кредита заемщику принималось на основе некоторых интуитивно (или по опыту) выведенных правил, которые можно представить в виде дерева решений:
В этом случае можно сказать, что решается задача бинарной классификации (целевой класс имеет два значения: "Выдать кредит" и "Отказать") по признакам "Возраст", "Наличие дома", "Доход" и "Образование".
Дерево решений как алгоритм машинного обучения – по сути то же самое. Огромное преимущество деревьев решений в том, что они легко интерпретируемы, понятны человеку.
В основе популярных алгоритмов построения дерева решений лежит принцип жадной максимизации прироста информации – на каждом шаге выбирается тот признак, при разделении по которому прирост информации оказывается наибольшим. Дальше процедура повторяется рекурсивно, пока энтропия не окажется равной нулю или какой-то малой величине (если дерево не подгоняется идеально под обучающую выборку во избежание переобучения). Плюсы:
-
Порождение четких правил классификации, понятных человеку, например, "если возраст
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=4,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=1,
splitter='best')
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45

Метод ближайших соседей
Метод ближайших соседей (k Nearest Neighbors, или kNN) — тоже очень популярный метод классификации, также иногда используемый в задачах регрессии. Это, наравне с деревом решений, один из самых понятных подходов к классификации. На уровне интуиции суть метода такова: посмотри на соседей, какие преобладают, таков и ты. Формально основой метода является гипотеза компактности: если метрика расстояния между примерами введена достаточно удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Для классификации каждого из объектов тестовой выборки необходимо последовательно выполнить следующие операции:
- Вычислить расстояние до каждого из объектов обучающей выборки
- Отобрать k объектов обучающей выборки, расстояние до которых минимально
- Класс классифицируемого объекта — это класс, наиболее часто встречающийся среди k ближайших соседей
Под задачу регрессии метод адаптируется довольно легко – на 3 шаге возвращается не метка, а число – среднее (или медианное) значение целевого признака среди соседей.
Примечательное свойство такого подхода – его ленивость. Это значит, что вычисления начинаются только в момент классификации тестового примера, а заранее, только при наличии обучающих примеров, никакая модель не строится. В этом отличие, например, от ранее рассмотренного дерева решений, где сначала на основе обучающей выборки строится дерево, а потом относительно быстро происходит классификация тестовых примеров.
Качество классификации/регрессии методом ближайших соседей зависит от нескольких параметров:
- число соседей
- метрика расстояния между объектами (часто используются метрика Хэмминга, евклидово расстояние, косинусное расстояние и расстояние Минковского). Отметим, что при использовании большинства метрик значения признаков надо масштабировать. Условно говоря, чтобы признак "Зарплата" с диапазоном значений до 100 тысяч не вносил больший вклад в расстояние, чем "Возраст" со значениями до 100.
- веса соседей (соседи тестового примера могут входить с разными весами, например, чем дальше пример, тем с меньшим коэффициентом учитывается его "голос")
Плюсы и минусы метода ближайших соседей
- Простая реализация;
- Неплохо изучен теоретически;
- Как правило, метод хорош для первого решения задачи;
- Можно адаптировать под нужную задачу выбором метрики или ядра (ядро может задавать операцию сходства для сложных объектов типа графов, а сам подход kNN остается тем же);
- Неплохая интерпретация, можно объяснить, почему тестовый пример был классифицирован именно так.
- Метод считается быстрым в сравнении, например, с композициями алгоритмов, но в реальных задачах, как правило, число соседей, используемых для классификации, будет большим (100-150), и в таком случае алгоритм будет работать не так быстро, как дерево решений;
- Если в наборе данных много признаков, то трудно подобрать подходящие веса и определить, какие признаки не важны для классификации/регрессии;
- Зависимость от выбранной метрики расстояния между примерами. Выбор по умолчанию евклидового расстояния чаще всего ничем не обоснован. Можно отыскать хорошее решение перебором параметров, но для большого набора данных это отнимает много времени;
- Нет теоретических оснований выбора определенного числа соседей — только перебор (впрочем, чаще всего это верно для всех гиперпараметров всех моделей). В случае малого числа соседей метод чувствителен к выбросам, то есть склонен переобучаться;
- Как правило, плохо работает, когда признаков много, из-за "прояклятия размерности". Про это хорошо рассказывает известный в ML-сообществе профессор Pedro Domingos – тут в популярной статье "A Few Useful Things to Know about Machine Learning", также "the curse of dimensionality" описывается в книге Deep Learning в главе "Machine Learning basics".
Класс KNeighborsClassifier в Scikit-learn
Основные параметры класса sklearn.neighbors.KNeighborsClassifier:
- weights: "uniform" (все веса равны), "distance" (вес обратно пропорционален расстоянию до тестового примера) или другая определенная пользователем функция
- algorithm (опционально): "brute", "ball_tree", "KD_tree", или "auto". В первом случае ближайшие соседи для каждого тестового примера считаются перебором обучающей выборки. Во втором и третьем — расстояние между примерами хранятся в дереве, что ускоряет нахождение ближайших соседей. В случае указания параметра "auto" подходящий способ нахождения соседей будет выбран автоматически на основе обучающей выборки.
- leaf_size (опционально): порог переключения на полный перебор в случае выбора BallTree или KDTree для нахождения соседей
- metric: "minkowski", "manhattan", "euclidean", "chebyshev" и другие
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 1.00 1.00 18
virginica 1.00 1.00 1.00 11
micro avg 1.00 1.00 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45
Примените изученные классификаторы для предсказания выживаемости на Титанике и постойте наилучший классификатор. Каковы значения основных его метрик?
Читайте также: