
Как сделать компьютерное зрение на питоне
Добавил пользователь Евгений Кузнецов Обновлено: 04.10.2024
Этот пост разделён на две части. В первой части мы рассмотрим реализацию распознавания объектов в реальном времени, используем deep-learning и OpenCV, чтобы работать с видео потоками и видеофайлами. В этом нам поможет высокоэффективный класс VideoStream, подробнее о нём читайте здесь.
Оттуда мы возьмём Deep Learning, код для обнаружения объекта и код для измерения FPS.
Часть 1: распознавание объектов в реальном времени - работаем с кодом
Чтобы сделать детектор объектов в реальном времени, нам потребуется:
- Получить доступ к нашей веб-камере/видео потоку.
- Применить распознавание объекта для каждого кадра.
Чтобы посмотреть, как это делается, откройте новый файл, назовите его real_time_object_detection.py и вставьте следующий код:
Мы начали с импортирования библиотек (на строках 2-8). Для этого вам необходим imutils и OpenCV.
Пишем код для работы с командной строкой.
Далее анализируем аргументы командной строки:
- --prototxt : Путь к prototxt Caffe файлу.
- --model : Путь к предварительно подготовленной модели.
- --confidence : Минимальный порог валидности (сходства) для распознавания объекта (значение по умолчанию - 20%).
Добавляем основные объекты.
Затем мы инициализируем список классов и набор цветов:
На строках 22-26 мы инициализируем метки CLASS и соответствующие случайные цвета.
Теперь загрузим модель и настроим наш видео поток:
Загружаем нашу сериализованную модель, предоставляя ссылки на prototxt и модели (строка 30) - обратите внимание, насколько это просто в OpenCV.
Затем инициализируем видео поток (это может быть видеофайл или веб-камера). Сначала запускаем VideoStream (строка 35), затем мы ждём, пока камера включится (строка 36), и, наконец, начинаем отсчёт кадров в секунду (строка 37). Классы VideoStream и FPS являются частью пакета imutils.
Пишем код для работы с кадрами.
Теперь проходим по каждому кадру (чтобы увеличить скорость, можно пропускать кадры).
Первое, что мы делаем - считываем кадр (строка 43) из потока, затем заменяем его размер (строка 44).
Поскольку чуть позже нам понадобится ширина и высота, получим их сейчас (строка 47). Затем следует преобразование кадра в blob с модулем dnn (строки 48 и 49).
Теперь к сложному: мы устанавливаем blob как входные данные в нашу нейросеть (строка 53) и передаём эти данные через net (строка 54), которая обнаруживает наши предметы.
"Фильтруем" объекты.
На данный момент, мы обнаружили объекты в видео потоке. Теперь пришло время посмотреть на значения валидности и решить, должны ли мы нарисовать квадрат вокруг объекта и повесить лейбл.
Мы начинаем проходить циклами через наши detections, помня, что несколько объектов могут быть восприняты как единое изображение. Мы также делаем проверку на валидность (т.е. вероятность) для каждого обнаружения. Если валидность достаточно велика (т.е. выше заданного порога), отображаем предсказание в терминале, а также рисуем на видео потоке предсказание (обводим объект в цветной прямоугольник и вешаем лейбл).
Давайте разберём по строчкам:
Проходим по detections, получаем значение валидности (строка 60).
Если значение валидности выше заданного порога (строка 64), извлекаем индекс лейбла в классе (строка 68) и высчитываем координаты рамки вокруг обнаруженного объекта (строка 69).
Затем, извлекаем (x;y)-координаты рамки (строка 70), которые будем использовать для отображения прямоугольника и текста.
Делаем текстовый лейбл, содержащую имя из CLASS и значение валидности (строки 73 и 74).
Также, рисуем цветной прямоугольник вокруг объекта, используя цвета класса и раннее извлечённые (x;y)-координаты (строки 75 и 76).
В целом, нужно, чтобы лейбл располагался над цветным прямоугольником, однако, может возникнуть такая ситуация, что сверху будет недостаточно места, поэтому в таких случаях выводим лейбл под верхней стороной прямоугольника (строка 77).
Наконец, мы накладываем цветной текст и рамку на кадр, используя значение 'y', которое мы только что вычислили (строки 78 и 79).
Оставшиеся задачи:
- Отображение кадра
- Проверка ключа выхода
- Обновление счётчика FPS
Код вверху довольно очевиден: во-первых, выводим кадр (строка 82). Затем фиксируем нажатие клавиши (строка 83), проверяя, не нажата ли клавиша "q" (quit). Если условие истинно, мы выходим из цикла (строки 86 и 87).
Наконец, обновляем наш счётчик FPS (строка 90).
Если происходит выход из цикла (нажатие клавиши "q" или конец видео потока), у нас есть вещи, о которых следует позаботиться:
При выходе из цикла, останавливаем счётчик FPS (строка 92) и выводим информацию о конечном значении FPS в терминал (строки 93 и 94).
Закрываем окно программы (строка 97), прекращая видео поток (строка 98).
Если вы зашли так далеко, вероятно, вы готовы попробовать программу на своей веб-камере. Чтобы посмотреть, как это делается, перейдём к следующему разделу.
Часть 2: тестируем распознавание объектов в реальном времени на веб-камере
Чтобы увидеть детектор объектов в реальном времени в действии, убедитесь, что вы скачали исходники и предварительно подготовленную Convolutional Neural Network.
Оттуда открываете терминал и выполняете следующие команды:
При условии, что OpenCV может получить доступ к вашей веб-камере, вы должны увидеть выходной кадр с любыми обнаруженными объектами. Я привёл примеры результатов в видео ниже:
Заметьте, что распознаватель объектов может обнаруживать не только меня (человека), но и диван, на котором я сижу и стул рядом со мной. И всё это в реальном времени.

Раньше капча с числами была отличным способом отсеять ботов, а сейчас такая разновидность уже почти не встречается. Думаю, ты и сам догадываешься, в чем дело: нейросети научились распознавать такие капчи лучше нас. В этой статье мы посмотрим, как работает нейронная сеть и как использовать Keras и Tensorflow, чтобы реализовать распознавание цифр.
Для каждого примера я приведу код на Python 3.7. Ты можешь запустить его и посмотреть, как все это работает. Для запуска примеров потребуется библиотека Tensorflow. Установить ее можно командой pip install tensorflow-gpu, если видеокарта поддерживает CUDA, в противном случае используй команду pip install tensorflow. Вычисления с CUDA в несколько раз быстрее, так что, если твоя видеокарта их поддерживает, это сэкономит немало времени. И не забудь установить наборы данных для обучения сети командой pip install tensorflow-datasets.

Типы этой функции различны, она может быть:
- прямоугольной (на выходе 0 или 1);
- линейной;
- в виде сигмоиды.
Еще в 1943 году Мак-Каллок и Питтс доказали, что сеть из нейронов может выполнять различные операции. Но сначала эту сеть нужно обучить — настроить коэффициенты w каждого нейрона так, чтобы сигнал передавался нужным нам способом. Запрограммировать нейронную сеть и обучить ее с нуля сложно, но, к счастью для нас, все необходимые библиотеки уже написаны. Благодаря компактности языка Python все действия можно запрограммировать в несколько строк кода.
Рассмотрим простейшую нейросеть и научим ее выполнять функцию XOR. Разумеется, вычисление XOR с помощью нейронной сети не имеет практического смысла. Но именно оно поможет нам понять базовые принципы обучения и использования нейросети и позволит по шагам проследить ее работу. С сетями большей размерности это было бы слишком сложно и громоздко.
Теперь мы готовы создать нейросеть. Благодаря Tensorflow на это понадобится всего лишь четыре строчки кода.

В нашем случае сеть имеет два входа (внешний слой), два нейрона во внутреннем слое и один выход.
Можно посмотреть, что у нас получилось:

Обучение нейросети состоит в нахождении значений параметров этой сети.
Наша сеть имеет девять параметров. Чтобы обучить ее, нам понадобится исходный набор данных, в нашем случае это результаты работы функции XOR.
Функция fit запускает алгоритм обучения, которое у нас будет выполняться тысячу раз, на каждой итерации параметры сети будут корректироваться. Наша сеть небольшая, так что обучение пройдет быстро. После обучения сетью уже можно пользоваться:
Результат соответствует тому, чему сеть обучалась.
Мы можем вывести все значения найденных коэффициентов на экран.
W1: [[ 2.8668058 -2.904025 ] [-2.871452 2.9036295]]
b1: [-0.00128211 -0.00191825]
Внутренняя реализация функции model.predict_proba выглядит примерно так:
Рассмотрим ситуацию, когда на вход сети подали значения [0,1]:
L1 = X1W1 + b1 = [02.8668058 + 1–2.871452 + -0.0012821, 0–2.904025 + 1*2.9036295 + -0.00191825] = [-2.8727343 2.9017112]
Функция активации ReLu (rectified linear unit) — это просто замена отрицательных элементов нулем.
Теперь найденные значения попадают на второй слой.
L2 = X2W2 + b2 = 03.9633768 +2.9017112*3.9633768 + -4.897212 = 6.468379
Наконец, в качестве выхода используется функция Sigmoid, которая приводит значения к диапазону 0. 1:
Мы совершили обычные операции умножения и сложения матриц и получили ответ: XOR(0,1) = 1.
С этим примером на Python советую поэкспериментировать самостоятельно. Например, ты можешь менять число нейронов во внутреннем слое. Два нейрона, как в нашем случае, — это самый минимум, чтобы сеть работала.
Но алгоритм обучения, который используется в Keras, не идеален: нейросети не всегда удается обучиться за 1000 итераций, и результаты не всегда верны. Так, Keras инициализирует начальные значения случайными величинами, и при каждом запуске результат может отличаться. Моя сеть с двумя нейронами успешно обучалась лишь в 20% случаев. Неправильная работа сети выглядит примерно так:
Но это не страшно. Если видишь, что нейронная сеть во время обучения не выдает правильных результатов, алгоритм обучения можно запустить еще раз. Правильно обученную сеть потом можно использовать без ограничений.
Можно сделать сеть поумнее: использовать четыре нейрона вместо двух, для этого достаточно заменить строчку кода model.add(Dense(2, input_dim=2, activation=’relu’)) на model.add(Dense(4, input_dim=2, activation=’relu’)). Такая сеть обучается уже в 60% случаев, а сеть из шести нейронов обучается с первого раза с вероятностью 90%.
Все параметры нейронной сети полностью определяются коэффициентами. Обучив сеть, можно записать параметры сети на диск, а потом использовать уже готовую обученную сеть. Этим мы будем активно пользоваться.
Рассмотрим практическую задачу, вполне классическую для нейронных сетей, — распознавание цифр. Для этого мы возьмем уже известную нам сеть multilayer perceptron, ту же самую, что мы использовали для функции XOR. В качестве входных данных будут выступать изображения 28 × 28 пикселей. Такой размер выбран потому, что существует уже готовая база рукописных цифр MNIST, которая хранится именно в таком формате.
Для удобства разобьем код на несколько функций. Первая часть — это создание модели.
На вход сети будет подаваться image_w*image_h значений — в нашем случае это 28 × 28 = 784. Количество нейронов внутреннего слоя такое же и равно 784.
С распознаванием цифр есть одна особенность. Как мы видели в предыдущем примере, выход нейросети может лежать в диапазоне 0…1, а нам нужно распознавать цифры от 0 до 9. Как быть? Чтобы распознавать цифры, мы создаем сеть с десятью выходами, и единица будет на выходе, соответствующем нужной цифре.

Структура отдельного нейрона настолько проста, что для его использования даже не обязателен компьютер. Недавно ученые смогли реализовать нейронную сеть, аналогичную нашей, в виде куска стекла — такая сеть не требует питания и вообще не содержит внутри ни одного электронного компонента.

Когда нейронная сеть создана, ее надо обучить. Для начала необходимо загрузить датасет MNIST и преобразовать данные в нужный формат.
У нас есть два блока данных: train и test — один служит для обучения, второй для верификации результатов. Это общепринятая практика, обучать и тестировать нейронную сеть желательно на разных наборах данных.
Готовый код обучения сети:
Создаем модель, обучаем ее и записываем результат в файл.

На моем компьютере c Core i7 и видеокартой GeForce 1060 процесс занимает 18 секунд и 50 секунд с расчетами без GPU — почти втрое дольше. Так что, если ты захочешь экспериментировать с нейронными сетями, хорошая видеокарта весьма желательна.
Теперь напишем функцию распознавания картинки из файла — то, для чего эта сеть и создавалась. Для распознавания мы должны привести картинку к такому же формату — черно-белое изображение 28 на 28 пикселей.
Теперь использовать нейронную сеть довольно просто. Я создал в Paint пять изображений с разными цифрами и запустил код.

Результат, увы, неидеален: 0, 1, 3, 6 и 6. Нейросеть успешно распознала 0, 1 и 3, но спутала 8 и 9 с цифрой 6. Разумеется, можно изменить число нейронов, число итераций обучения. К тому же эти цифры не были рукописными, так что стопроцентный результат нам никто не обещал.
Вот такая нейронная сеть с дополнительным слоем и большим числом нейронов корректно распознает цифру восемь, но все равно путает 8 и 9.
При желании можно обучать нейронную сеть и на своем наборе данных, но для этого данных нужно довольно много (MNIST содержит 60 тысяч образцов цифр). Желающие могут поэкспериментировать самостоятельно, а мы пойдем дальше и рассмотрим сверточные сети (CNN, Convolutional Neural Network), более эффективные для распознавания изображений.
В предыдущем примере мы использовали изображение 28 × 28 как простой одномерный массив из 784 цифр. Такой подход, в принципе, работает, но начинает давать сбои, если изображение, например, сдвинуто. Достаточно в предыдущем примере сдвинуть цифру в угол картинки, и программа уже не распознает ее.
Слой Conv2D отвечает за свертку входного изображения с ядром 3 × 3, а слой MaxPooling2D выполняет downsampling — уменьшение размера изображения. На выходе сети мы видим уже знакомый нам слой Dense, который мы использовали ранее.
Как и в предыдущем случае, сеть вначале надо обучить, и принцип здесь тот же самый, за тем исключением, что мы работаем с двумерными изображениями.
Все готово. Мы создаем модель, обучаем ее и записываем модель в файл:
Обучение нейронной сети с той же базой MNIST из 60 тысяч изображений занимает 46 секунд с использованием Nvidia CUDA и около пяти минут без нее.
Теперь мы можем использовать нейросеть для распознавания изображений:
Результат гораздо точнее, что и следовало ожидать: [0, 1, 3, 8, 9].
Все готово! Теперь у тебя есть программа, умеющая распознавать цифры. Благодаря Python работать код будет где угодно — на операционных системах Windows и Linux. При желании можешь запустить его даже на Raspberry Pi.
Ты наверняка хочешь знать, можно ли распознавать буквы аналогичным способом? Да, придется только увеличить число выходов сети и найти подходящий набор картинок для обучения.
Надеюсь, у тебя достаточно информации для экспериментов. К тому же с реальным примером перед глазами разбираться значительно проще!
Компьютерное зрение связано с моделированием и копированием человеческого зрения с использованием компьютерного программного и аппаратного обеспечения. В этой главе вы узнаете подробно об этом.
Компьютерное зрение
Компьютерное зрение — это дисциплина, которая изучает, как реконструировать, прерывать и понимать трехмерную сцену по ее 2-мерным изображениям с точки зрения свойств структуры, присутствующей в сцене.
Иерархия компьютерного зрения
Компьютерное зрение делится на три основные категории следующим образом:
Низкоуровневое зрение — включает изображение процесса для извлечения объектов.
Видение промежуточного уровня — включает распознавание объектов и интерпретацию трехмерных сцен
Видение высокого уровня — включает концептуальное описание сцены, такой как активность, намерение и поведение.
Низкоуровневое зрение — включает изображение процесса для извлечения объектов.
Видение промежуточного уровня — включает распознавание объектов и интерпретацию трехмерных сцен
Видение высокого уровня — включает концептуальное описание сцены, такой как активность, намерение и поведение.
Computer Vision Vs Обработка изображений
Компьютерное зрение — это построение явных, значимых описаний физических объектов по их изображению. Результатом компьютерного зрения является описание или интерпретация структур в трехмерной сцене.
Приложения
Компьютерное зрение находит применение в следующих областях —
робототехника
Локализация — определить местоположение робота автоматически
Сборка (колышек, сварка, покраска)
Манипуляции (например, робот-манипулятор PUMA)
Human Robot Interaction (HRI): интеллектуальная робототехника для взаимодействия и обслуживания людей
Локализация — определить местоположение робота автоматически
Сборка (колышек, сварка, покраска)
Манипуляции (например, робот-манипулятор PUMA)
Human Robot Interaction (HRI): интеллектуальная робототехника для взаимодействия и обслуживания людей
Лекарственное средство
Классификация и обнаружение (например, классификация повреждения или клеток и обнаружение опухоли)
2D / 3D сегментация
3D реконструкция человеческого органа (МРТ или УЗИ)
Классификация и обнаружение (например, классификация повреждения или клеток и обнаружение опухоли)
2D / 3D сегментация
3D реконструкция человеческого органа (МРТ или УЗИ)
Безопасность
- Биометрия (радужная оболочка, отпечаток пальца, распознавание лица)
- Наблюдение — обнаружение определенных подозрительных действий или поведения
- Автономное транспортное средство
- Безопасность, например, мониторинг бдительности водителя
Применение промышленной автоматизации
- Промышленный контроль (обнаружение дефектов)
- сборочный
- Считывание штрих-кода и этикетки на упаковке
- Сортировка объектов
- Понимание документа (например, OCR)
Установка полезных пакетов
Для компьютерного зрения с Python вы можете использовать популярную библиотеку OpenCV (Open Source Computer Vision). Это библиотека функций программирования, в основном предназначенная для компьютерного зрения в реальном времени. Он написан на C ++, а его основной интерфейс — на C ++. Вы можете установить этот пакет с помощью следующей команды —
Здесь X представляет версию Python, установленную на вашем компьютере, а также win32 или 64-битную версию, которую вы используете.
Если вы используете среду anaconda , используйте следующую команду для установки OpenCV:
Чтение, запись и отображение изображения
Большинство приложений CV должны получать изображения в качестве входных данных и выводить изображения в качестве выходных. В этом разделе вы узнаете, как читать и писать файл изображения с помощью функций, предоставляемых OpenCV.
Функции OpenCV для чтения, отображения, записи файла изображения
OpenCV предоставляет следующие функции для этой цели —
Функция imread () — это функция для чтения изображения. OpenCV imread () поддерживает различные форматы изображений, такие как PNG, JPEG, JPG, TIFF и т. Д.
Функция imshow () — это функция для отображения изображения в окне. Окно автоматически подгоняется под размер изображения. OpenCV imshow () поддерживает различные форматы изображений, такие как PNG, JPEG, JPG, TIFF и т. Д.
Функция imwrite () — это функция для записи изображения. OpenCV imwrite () поддерживает различные форматы изображений, такие как PNG, JPEG, JPG, TIFF и т. Д.
Функция imread () — это функция для чтения изображения. OpenCV imread () поддерживает различные форматы изображений, такие как PNG, JPEG, JPG, TIFF и т. Д.
Функция imshow () — это функция для отображения изображения в окне. Окно автоматически подгоняется под размер изображения. OpenCV imshow () поддерживает различные форматы изображений, такие как PNG, JPEG, JPG, TIFF и т. Д.
Функция imwrite () — это функция для записи изображения. OpenCV imwrite () поддерживает различные форматы изображений, такие как PNG, JPEG, JPG, TIFF и т. Д.
Opencv (Open Source Computer Vision Library или библиотека компьютерного зрения с открытым исходным кодом) – это модуль Python, используемый для решения задач с помощью компьютерного зрения. Это огромный модуль с исключительными возможностями. Используя компьютерное зрение, мы можем решать самые разные задачи. Примером таких задач может быть распознавание лиц и движения.
Сегодня мы с вами научимся писать код для обнаружения лиц на изображениях, видео и для распознавания движения.
Посмотрите другие статьи "Python простым языком":
Распознавание лиц на изображениях
В файле GitHub OpenCV есть подкаталог (opencv-master\samples\data) с именем data, в котором доступны образцы изображений и видео для работы. Мы будем использовать фотографии и видео из этого каталога. В частности, давайте возьмем файл lena.jpg. Скопируем и вставим его в свой рабочий каталог в PyCharm (или в любом другом редакторе). Теперь приступим к распознаванию лиц на этом изображении.
Для начала загрузим необходимые нам модули:
Файл, который мы будем использовать, находится по адресу opencv-master\data\haarcascades\haarcascade_frontalface_default.xml в файле, загруженном с GitHub. Разместим ссылку на файл haarcascade следующим образом:
Загрузим фотографию, чтобы выполнить распознавание лица с помощью метода imread () библиотеки cv2 .
Наша следующая цель – превратить фотографию в оттенки серого. Сделаем это с помощью метода cv2.cvtColor ().
Этот метод принимает два аргумента. Первый – имя файла, который нужно преобразовать, а второй – формат, в который нужно преобразовать этот файл. В данном случае мы будем использовать формат cv2. COLOR_BGR2GRAY .
Затем воспользуемся функцией detectMultiScale () для обнаружения объектов (в нашем случае — лиц). Здесь мы напишем face_cascade . detectMultiScale (), который будет обнаруживать лица (это указано параметром face_cascade).
Функция detectMultiScale() принимает несколько аргументов: изображение, коэффициент масштабирования, минимальное количество соседей, флаги, минимальный и максимальный размер. Мы укажем только первые 3 аргумента.
Чтобы разместить прямоугольную рамку вокруг лица, нам нужно использовать метод cv2. rectangle (). Он принимает несколько аргументов. Первый – это наше изображение, второй – начальная точка прямоугольника, третий – конечная точка прямоугольника, четвертый – цвет прямоугольника, а пятый – его толщина. В данном случае w – ширина, h – высота, x и y – координаты начальной точки.
Наконец, мы выводим изображение на экран с помощью метода cv2. imshow (). Мы также используем cv2. waitKey (0), чтобы установить бесконечное время ожидания, и cv2. destroyAllWindows (), чтобы закрыть окно.
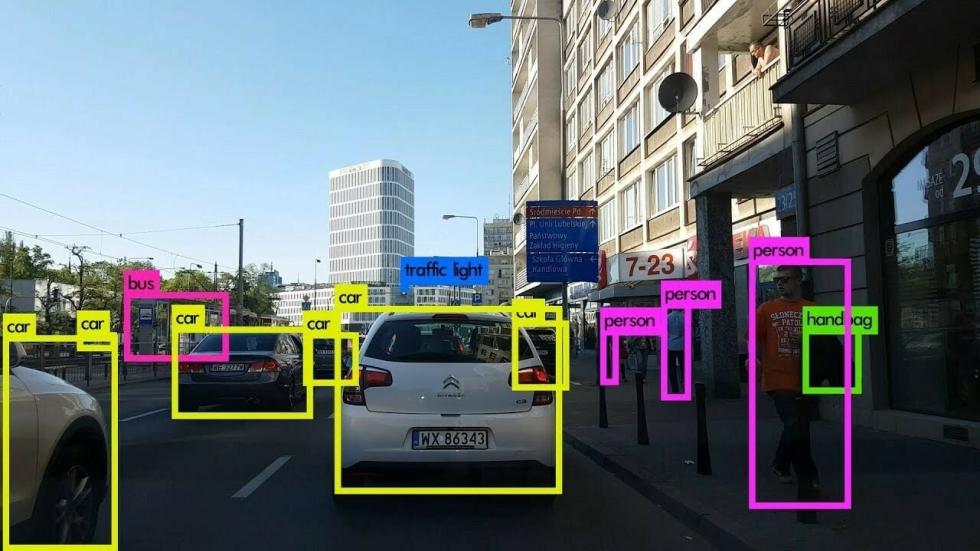
Обнаружение объектов — это задача компьютерного зрения и обработки изображений, которая связана с обнаружением объектов на изображениях или видео. Сейчас решения подобного рода задач актуальны в самых разных реальных приложениях, включая видеонаблюдение, беспилотные автомобили, отслеживание объектов и т. д.
Например, для того, чтобы автомобиль был действительно автономным, он должен понимать и отслеживать окружающие его объекты (такие как автомобили, пешеходы и светофоры), и основным источником информации для этого является камера. Более того, чтобы автомобиль мог безопасно перемещаться по улице, очень важно, обнаруживать объекты в режиме реального времени.
В этом уроке вы узнаете, как найти и обнаружить объекты с помощью современной техники YOLO v3 с OpenCV или PyTorch в Python.
Содержание
YOLO (You Only Look Once, что в нашем контексте на русском означает с единственного взгляда) — это алгоритм обнаружения объектов в реальном времени, который представляет собой одну глубокую сверточную нейронную сеть, которая разбивает входное изображение на набор ячеек, образующих сетку, поэтому, в отличие от классификации изображений или обнаружения лиц, каждая ячейка сетки в алгоритме YOLO в выходных данных будет иметь связанный вектор, который сообщает нам:
- Присутствует ли объект в ячейке сетки.
- Класс объекта (т.е. метка).
- Предполагаемые геометрические характеристики объекта (местоположения).
Существуют и другие подходы, такие как Fast R‑CNN , Faster R‑CNN , которые используют скользящие по изображению окна, что требует тысячи прогнозов для одного изображения (в каждом окне), как вы можете догадаться, это делает YOLO v3 примерно в 1000 раз быстрее, чем R‑CNN, и в 100 раз быстрее, чем Fast R‑CNN.
YOLO v3 — последняя версия YOLO, в которой используется несколько приемов для улучшения обучаемости и повышения производительности. Подробные сведения см. в статье YOLO v3 .
Начало без проблем ↑
Прежде чем мы погрузимся в код, давайте установим необходимые библиотеки для наших упражнений (если вы хотите использовать код PyTorch, ознакомьтесь с инструкциями для установки ):
Довольно сложно строить всю систему YOLO v3 (модель и используемые методы) с нуля. Библиотеки с открытым исходным кодом, такие как Darknet или OpenCV значительно упрощают этот процесс и уже многое сделали для вас. Так, что даже некоторые простые человеки уже реализовали свои проекты для YOLO v3 (посмотрите, как это сделано для TensorFlow. 2 реализация)
Импорт необходимых модулей:
Давайте определим некоторые переменные и параметры, которые нам понадобятся:
Мы инициализировали наши параметры, но поговорим о них позже. config_path и weights_path представляют собой соответственно конфигурацию модели (это YOLO v3) и соответствующие предварительно обученные веса модели. labels — это список всех меток классов для различных объектов. Каждый класс объекта при обнаружении нарисуем уникальным цветом, для чего генерируем случайные цвета.
За необходимыми файлами, пожалуйста, обратитесь к этому репозиторию , а поскольку файл весов очень большой (около 240 МБ) и в репозитории его нет, загрузите его отсюда .
Приведенный ниже код загружает модель:
Подготовка изображения ↑
Загрузим пример изображения (изображение есть в репозитории ):
Затем нам нужно нормализовать, масштабировать и изменить это изображение, чтобы оно подходило в качестве входных данных для нейронной сети:
Здесь происходит нормализация значения пикселей в диапазоне от 0 до 1 и изменяется размер изображения до (416, 416) с изменит его формы, давайте посмотрим:
Прогнозирование ↑
Теперь загрузим изображение в нейронную сеть и получим прогноз на выходе:
У меня получилось, что для извлечения выходных данных нейронной сети потребовалось:
Возникает резонный вопрос, почему всё не так быстро? 1,5 секунды — это довольно медленно? Что ж, мы использовали наш ЦП только для вывода, а для реальных задач это совсем не идеально. Поэтому немного позже перейдем к PyTorch. С другой стороны, 1,5 секунды — это относительно хорошо по сравнению с другими методами, такими как R‑CNN. Вы также можете использовать крохотную версию YOLO v3, которая работает намного быстрее, но менее точна. Её можно скачать здесь .
Теперь нам нужно перебрать выходные данные нейронной сети и отбросить все объекты, уровень достоверности идентификации которых меньше, чем параметр CONFIDENCE , указанный нами ранее (т.е. 0,5 или 50%).
Здесь перебираются все прогнозы и сохраняются объекты с высокой степенью достоверности, давайте посмотрим, что представляет собой вектор обнаружения:
В каждом прогнозе объекта есть вектор из 85 элементов. Первые 4 значения представляют местоположение объекта, координаты (x, y) для центральной точки, а также ширину и высоту ограничивающего прямоугольника, остальные числа соответствуют меткам объектов. Поскольку это набор данных COCO , он имеет 80 меток классов.
Например, если обнаруженный объект — человек, первое значение в векторе длины 80 должно быть 1, а все остальные значения должны быть 0, число 2 для велосипеда, 3 для автомобиля, вплоть до 80-го объекта. Вот почему мы используем функцию np.argmax() для получения идентификатора класса, поскольку она возвращает индекс максимального значения из этого вектора длиной 80.
Отрисовываем обнаруженные объекты ↑
Теперь у нас есть все, что нужно и мы сможем нарисовать прямоугольники объектов и метки. Посмотрим на результат:

В текущем каталоге появится новое изображение, которое уверенно маркирует каждый обнаруженный объект. Однако посмотрите на эту часть изображения:
Как вы уже догадались, две ограничивающие рамки для одного объекта, это проблема, не так ли? Что ж, создатели YOLO для её решения использовали технику под названием Non-maximal Suppression (Немаксимальное подавление).
Non-maximal Suppression ↑
Non-maximal Suppression — метод, который подавляет перекрывающиеся ограничивающие прямоугольники, у которых вероятности для обнаружения объекта меньше максимальной. В основном это достигается в два этапа:
- Выбираем ограничивающую рамку с наибольшей достоверностью (то есть вероятностью).
- Затем сравниваем её с вероятностями всех других ограничивающих прямоугольников и удаляем те, которые имеют высокий IoU.
Что такое IoU ↑

IoU (Intersection over Union или пересечение над объединением) — это метод, используемый в Non-maximal Suppression для сравнения того, насколько близки два разных ограничивающих прямоугольника. Это просто показано на следующем рисунке:
Чем выше IoU, тем ближе ограничивающие рамки. IoU, равное 1, означает, что две ограничивающие рамки совпали, а IoU, равное 0, означает, что они даже не пересекаются.
В результате мы будем использовать пороговое значение IoU 0,5 (которое задано в начале урока) и это означает, что будет удалятся любая ограничивающая рамка со значением ниже значения ограничивающей рамки с максимальной вероятностью.
SCORE_THRESHOLD удалит любую ограничивающую рамку, которая имеет достоверность ниже этого значения:
Теперь давайте снова нарисуем рамки:
Вы можете использовать cv2.imshow("image", image) и показать изображение, но мы просто сохраним его на диск:


Вот еще один пример изображения:
Потрясающие! Теперь используйте свои собственные изображения, настройте параметры и посмотрите, что лучше всего работает!
Кроме того, если изображение имеет высокое разрешение, убедитесь, что вы увеличили параметр font_scale , чтобы увидеть ограничивающие прямоугольники и соответствующие им метки.
Код PyTorch ↑
Как упоминалось ранее, если вы хотите использовать графический процессор для вывода (который намного быстрее, чем центральный процессор), то можете попробовать библиотеку PyTorch એ , которая поддерживает вычисления CUDA, вот код для этого (получите darknet.py и utils.py из репозитория):
Примечание. Для приведенного выше кода требуются файлы darknet.py и utils.py в текущем каталоге. Также должен быть установлен PyTorch (рекомендуется ускорение на GPU).
Заключение ↑
Я подготовил для вас код использования видеокамеры для обнаружения объектов в реальном времени, посмотрите файл live_yolo_opencv.py.
Кроме того, если вы хотите прочитать видеофайл и выполнить обнаружение объекта на нем, то код из файла read_video.py вам поможет.
Вот пример работы этого скрипта, для которого я взял заставку с сайта группы студентов Бизнес-информатики . Результатом я не очень доволен, но это объясняется тем, что использован рисованный мультик и у искусственного интеллекта просто сносит крышу от человечьего художественного творчества — конфликт, понимаешь, интеллекта искусственного с естественным. Судите сами:
Обратите внимание, что есть некоторые недостатки детектора объектов YOLO, один из основных недостатков заключается в том, что YOLO изо всех сил пытается обнаружить объекты, сгруппированные близко друг к другу, особенно более мелкие. Существуют также SSD (Single Shot MultiBox Detector) , где часто наблюдается компромисс между скоростью и точностью.
Для этого урока использованы коды из следующих источников:
Есть несколько проектов и репозиториев с решениями подобных задач, и если вы хотите использовать TensorFlow 2 вместо показанного здесь, то я рекомендую вам посмотреть этот .
Читайте также: