
Как сделать кодирование по информатике
Добавил пользователь Дмитрий К. Обновлено: 05.10.2024
Среди всего разнообразия информации, обрабатываемой на компьютере, значительную часть составляют числовая, текстовая, графическая и аудиоинформация. Познакомимся с некоторыми способами кодирования этих типов информации в ЭВМ.
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2 k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
1) перевести число N в двоичную систему счисления; 2) полученный результат дополнить слева незначащими нулями до k разрядов.
Пример Получить внутреннее представление целого числа 1607 в 2-х байтовой ячейке. Переведем число в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке будет следующим: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
1) получить внутреннее представление положительного числа N; 2) обратный код этого числа заменой 0 на 1 и 1 на 0; 3) полученному числу прибавить 1.
Пример Получим внутреннее представление целого отрицательного числа -1607. Воспользуемся результатом предыдущего примера и запишем внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Инвертированием получим обратный код: 1111 1001 1011 1000. Добавим единицу: 1111 1001 1011 1001 -- это и есть внутреннее двоичное представление числа -1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p .
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства: 12.345 = 0.0012345 x 10 4 = 1234.5 x 10 -2 = 0.12345 x 10 2
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию: 0.1p 8 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов. О кодировании символов русского алфавита рассказывается в главе "Обработка документов".
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части -- растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится -- не светится), а для его кодирования достаточно одного бита памяти: 1 -- белый, 0 -- черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 -- черный, 10 -- зеленый, 01 -- красный, 11 -- коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов -- красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
| R | G | B | цвет |
|---|---|---|---|
| 0 | 0 | 0 | черный |
| 0 | 0 | 1 | синий |
| 0 | 1 | 0 | зеленый |
| 0 | 1 | 1 | голубой |
| R | G | B | цвет |
|---|---|---|---|
| 1 | 0 | 0 | красный |
| 1 | 0 | 1 | розовый |
| 1 | 1 | 0 | коричневый |
| 1 | 1 | 1 | белый |
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов -- К и количество битов для их кодировки -- N связаны между собой простой формулой: 2 N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения -- линия, прямоугольник, окружность или фрагмент текста -- располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Подробнее о графических форматах рассказывается в разделе "Графика на компьютере".
Кодирование звука
Из курса физики вам известно, что звук -- это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой -- аналоговый -- сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его -- аналого-цифровым преобразователем (АЦП).
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь -- ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки -- нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Наиболее популярные таблицы кодировки:
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.
Заключение
Кодирование текстовой информации — это обычный и стандартный процесс, который происходит во всех современных компьютерах. Раньше чаще ощущалась проблема с кодировками при переносе одного текста между компьютерами. Теперь таких проблем меньше, потому что во многих устройствах имеются встроенные программы-конверторы, которые автоматически отслеживают кодировки и находят нужную, чтобы пользователь об этом вообще не беспокоился.
Кодирование — это преобразование информации из одной ее формы представления в другую, наиболее удобную для её хранения, передачи или обработки.
Кодом называют правило отображения одного набора знаков в другом.
Двоичный код – это способ представления информации с помощью двух символов - 0 и 1.
Длина кода – это количество знаков, используемых для представления кодируемой информации.
Бит - это одна двоичная цифра 0 или 1. Одним битом можно закодировать два значения: 1 или 0. Двумя битами можно закодировать уже четыре значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений. Добавление одного бита удваивает количество значений, которое можно закодировать.
Виды кодирования информации
Различают кодирование информации следующих видов:
- Кодирование текстовой информации;
- Кодирование цвета;
- Кодирование графической информации;
- Кодирование числовой информации;
- Кодирование звуковой информации;
- Кодирование видеозаписи.
Кодирование текстовой информации
Любой текст (к примеру, студенческий реферат) состоит из последовательности символов. Символами могут быть буквы, цифры, знаки препинания, знаки математических действий, круглые и квадратные скобки и т.д.
Текстовая информация, как и любая другая, хранится в памяти компьютера в двоичном виде. Для этого каждому ставится в соответствии некоторое неотрицательное число, называемое кодом символа, и это число записывается в память ЭВМ в двоичном виде. Конкретное соотношение между символами и их кодами называется системой кодировки. В персональных компьютерах обычно используется система кодировки ASCII (American Standard Code for Informational Interchange – Американский стандартный код для информационного обмена).
Готовые работы на аналогичную тему
Восьмибитными кодировками, распространенными в нашей стране, являются KOI8, UTF8, Windows-1251 и некоторые другие.
Кодирование цвета
Чтобы сохранить в двоичном коде фотографию, ее сначала виртуально разделяют на множество мелких цветных точек, называемых пикселями (что-то на подобии мозаики). После разбивки на точки цвет каждого пикселя кодируется в бинарный код и записывается на запоминающем устройстве.
Если говорят, что размер изображения составляет, например, х 512х512 точек, это значит, что оно представляет собой матрицу, сформированную из 262144 пикселей (количество пикселей по вертикали, умноженное на количество пикселей по горизонтали).
Прибором, "разбивающим" изображения на пиксели, является любая современная фотокамера (в том числе веб-камера, камера телефона) или сканер. И если в характеристиках камеры значится, например, "10 Mega Pixels", значит количество пикселей, на которые эта камера разбивает изображение для записи в двоичном коде, - 10 миллионов. Чем на большее количество пикселей разделено изображение, тем реалистичнее выглядит фотография в декодированном виде (на мониторе или после распечатывания).
Однако качество кодирования фотографий в бинарный код зависит не только от количества пикселей, но также и от их цветового разнообразия. Алгоритмов записи цвета в двоичном коде существует несколько. Самым распространенным из них является RGB. Эта аббревиатура – первые буквы названий трех основных цветов: красного – англ.Red, зеленого – англ. Green, синего – англ. Blue. Смешивая эти три цвета в разных пропорциях, можно получить любой другой цвет или оттенок.
На этом и построен алгоритм RGB. Каждый пиксель записывается в двоичном коде путем указания количества красного, зеленого и синего цвета, участвующего в его формировании.
Чем больше битов выделяется для кодирования пикселя, тем больше вариантов смешивания этих трех каналов можно использовать и тем значительнее будет цветовая насыщенность изображения.
Цветовое разнообразие пикселей, из которых состоит изображение, называется глубиной цвета.
Кодирование графической информации
Описанная выше техника формирования изображений из мелких точек является наиболее распространенной и называется растровой. Но кроме растровой графики, в компьютерах используется еще и так называемая векторная графика.
Векторные изображения создаются только при помощи компьютера и формируются не из пикселей, а из графических примитивов (линий, многоугольников, окружностей и др.).
Чтобы записать на запоминающем устройстве векторное изображение круга, компьютеру достаточно в двоичный код закодировать тип объекта (окружность), координаты его центра на холсте, длину радиуса, толщину и цвет линии, цвет заливки. В растровой системе пришлось бы кодировать цвет каждого пикселя. И если размер изображения большой, для его хранения понадобилось бы значительно больше места на запоминающем устройстве.
Тем не менее, векторный способ кодирования не позволяет записывать в двоичном коде реалистичные фото. Поэтому все фотокамеры работают только по принципу растровой графики. Рядовому пользователю иметь дело с векторной графикой в повседневной жизни приходится не часто.
Кодирование числовой информации
При кодировании чисел учитывается цель, с которой цифра была введена в систему: для арифметических вычислений или просто для вывода. Все данные, кодируемые в двоичной системе, шифруются с помощью единиц и нолей. Эти символы еще называют битами. Этот метод кодировки является наиболее популярным, ведь его легче всего организовать в технологическом плане: присутствие сигнала – 1, отсутствие – 0. У двоичного шифрования есть лишь один недостаток – это длина комбинаций из символов. Но с технической точки зрения легче орудовать кучей простых, однотипных компонентов, чем малым числом более сложных.
Целые числа кодируются просто переводом чисел из одной системы счисления в другую. Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число преобразуют в стандартный вид.
Кодирование звуковой информации
Любой звук, слышимый человеком, является колебанием воздуха, которое характеризируется двумя основными показателями: частотой и амплитудой. Амплитуда колебаний - это степень отклонения состояния воздуха от начального при каждом колебании. Она воспринимается нами как громкость звука. Частота колебаний - это количество отклонений состояний воздуха от начального за единицу времени. Она воспринимается как высота звука. Так, тихий комариный писк - это звук с высокой частотой, но с небольшой амплитудой. Звук грозы наоборот имеет большую амплитуду, но низкую частоту.
Схему работы компьютера со звуком в общих чертах можно описать так. Микрофон превращает колебания воздуха в аналогичные по характеристикам электрических колебаний. Звуковая карта компьютера преобразовывает электрические колебания в двоичный код, который записывается на запоминающем устройстве. При воспроизведении такой записи происходит обратный процесс (декодирование) - двоичный код преобразуется в электрические колебания, которые поступают в аудиосистему или наушники. Динамики акустической системы или наушников имеют противоположное микрофону действие. Они превращают электрические колебания в колебания воздуха.
Принцип разделения звуковой волны на мелкие участки лежит в основе двоичного кодирования звука. Аудиокарта компьютера разделяет звук на очень мелкие временные участки и кодирует степень интенсивности каждого из них в двоичный код. Такое дробление звука на части называется дискретизацией. Чем выше частота дискретизации, тем точнее фиксируется геометрия звуковой волны и тем качественней получается запись.
Качество записи сильно зависит также от количества битов, используемых компьютером для кодирования каждого участка звука, полученного в результате дискретизации. Количество битов, используемых для кодирования каждого участка звука, полученного при дискретизации, называется глубиной звука.
Кодирование видеозаписи
Видеозапись состоит из двух компонентов: звукового и графического.
Кодирование звуковой дорожки видеофайла в двоичный код осуществляется по тем же алгоритмам, что и кодирование обычных звуковых данных. Принципы кодирования видеоизображения схожи с кодированием растровой графики (рассмотрено выше), хотя и имеют некоторые особенности. Как известно, видеозапись - это последовательность быстро меняющихся статических изображений (кадров). Одна секунда видео может состоять из 25 и больше картинок. При этом, каждый следующий кадр лишь незначительно отличается от предыдущего.
Учитывая эту особенность, алгоритмы кодирования видео, как правило, предусматривают запись лишь первого (базового) кадра. Каждый же последующий кадр формируются путем записи его отличий от предыдущего.
Закодировать текст – значит сопоставить ему другой текст. Кодирование применяется при передаче данных – для того, чтобы зашифровать текст от посторонних, чтобы сделать передачу данных более надежной, потому что канал передачи данных может передавать только ограниченный набор символов (например, - только два символа, 0 и 1) и по другим причинам.
При кодировании заранее определяют алфавит, в котором записаны исходные тексты (исходный алфавит) и алфавит, в котором записаны закодированные тексты (коды), этот алфавит называется кодовым алфавитом. В качестве кодового алфавита часто используют двоичный алфавит, состоящий из двух символов (битов) 0 и 1. Слова в двоичном алфавите иногда называют битовыми последовательностями.
2. Побуквенное кодирование
Пример 1. Исходный алфавит – алфавит русских букв, строчные и прописные буквы не различаются. Размер алфавита – 33 символа.
Кодовый алфавит – алфавит десятичных цифр. Размер алфавита - 10 символов.
Применяется побуквенное кодирование по следующему правилу: буква кодируется ее номером в алфавите: код буквы А – 1; буквы Я – 33 и т.д.
Тогда код слова АББА – это 1221.
Внимание: Последовательность 1221 может означать не только АББА, но и КУ (К – 12-я буква в алфавите, а У – 21-я буква). Про такой код говорят, что он НЕ допускает однозначного декодирования
Пример 2. Исходный и кодовый алфавиты – те же, что в примере 1. Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А – 01, код Б – 02 и т.д.
В этом случае кодом текста АББА будет 01020201. И расшифровать этот код можно только одним способом. Для расшифровки достаточно разбить кодовый текст 01020201 на двойки: 01 02 02 01 и для каждой двойки определить соответствующую ей букву.
Такой способ кодирования называется равномерным. Равномерное кодирование всегда допускает однозначное декодирование.
Далее рассматривается только побуквенное кодирование
3. Неравномерное кодирование
Равномерное кодирование удобно для декодирования. Однако часто применяют и неравномерные коды, т.е. коды с различной длиной кодовых слов. Это полезно, когда в исходном тексте разные буквы встречаются с разной частотой. Тогда часто встречающиеся символы стоит кодировать более короткими словами, а редкие – более длинными. Из примера 1 видно, что (в отличие от равномерных кодов!) не все неравномерные коды допускают однозначное декодирование.
Есть простое условие, при выполнении которого неравномерный код допускает однозначное декодирование.
Код называется префиксным, если в нем нет ни одного кодового слова, которое было бы началом (по-научному, - префиксом) другого кодового слова.
Код из примера 1 – НЕ префиксный, так как, например, код буквы А (т.е. кодовое слово 1) – префикс кода буквы К (т.е. кодового слова 12, префикс выделен жирным шрифтом).
Код из примера 2 (и любой другой равномерный код) – префиксный: никакое слово не может быть началом слова той же длины.
Пример 3. Пусть исходный алфавит включает 9 символов: А, Л, М, О, П, Р, У, Ы, -. Кодовый алфавит – двоичный. Кодовые слова:
Кодовые слова выписаны в алфавитном порядке. Видно, что ни одно из них не является началом другого. Это можно проиллюстрировать рисунком
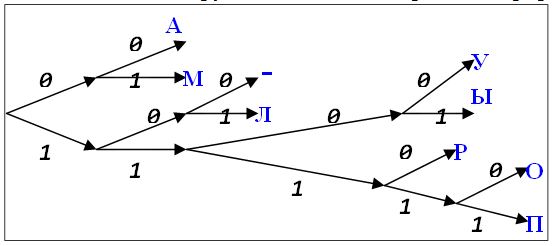
На рисунке изображено бинарное дерево. Его корень расположен слева. Из каждого внутреннего узла выходит два ребра. Верхнее ребро имеет пометку 0, нижнее – пометку 1. Таким образом, каждому узлу соответствует слово в двоичном алфавите. Если слово X является началом (префиксом) слова Y, то узел, соответствующий слову X, находится на пути из корня в узел, соответствующий слову Y. Наши кодовые слова находятся в листьях дерева. Поэтому ни одно из них не является началом другого.
Теорема (условие Фано). Любой префиксный код (а не только равномерный) допускает однозначное декодирование.
Разбор примера (вместо доказательства). Рассмотрим закодированный текст, полученный с помощью кода из примера 3:
Будем его декодировать таким способом. Двигаемся слева направо, пока не обнаружим код какой-то буквы. 0 – не кодовое слово, а 01 – код буквы М.
0100010010001110110100100111000011100
Далее таким же образом находим следующее кодовое слово 00 – код буквы А.
Доведите расшифровку текста до конца самостоятельно. Убедитесь, что он расшифровывается (декодируется) однозначно.
Замечание. В расшифрованном тексте 14 букв. Т.к. в алфавите 9 букв, то при равномерном двоичном кодировании пришлось бы использовать кодовые слова длины 4. Таким образом, при равномерном кодировании закодированный текст имел бы длину 56 символов – в полтора раза больше, чем в нашем примере (у нас 37 символов).
4. Как все это повторять. Задачи на понимание
Знание приведенного выше материала достаточно для решения задачи 5 из демо-варианта и близких к ней (см. здесь). Повторять (учить) этот материал стоит в том порядке, в котором он изложен. При этом нужно решать простые задачи – до тех пор, пока не будет достигнуто полное понимание. Ниже приведены возможные типы таких задач. Опытные учителя легко придумают (или подберут) конкретные задачи таких типов. Если будут вопросы – пишите.
1) Понятие побуквенного кодирования.
Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Закодировать заданный текст в алфавите Ф. Коды могут быть с использованием разных кодовых алфавитов, равномерные и неравномерные.
2) Префиксные неравномерные коды.
2.1) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Построить дерево кода (см. рис.1) и убедиться, что код – префиксный.
2.2) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Декодировать (анализом слева направо) данный текст в кодовом алфавите.
2.3) Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Определить, является ли данный код префиксным, или нет. В качестве примеров полезно приводить:
2.4) Решать задачи для самостоятельного решения, например, отсюда
Читайте также: