
Как сделать кластерный анализ в программе статистика
Обновлено: 07.07.2024
В механизме анализа данных и прогнозирования реализовано несколько типов анализа данных:
- общая статистика,
- поиск ассоциаций,
- поиск последовательностей,
- кластерный анализ,
В данной статье рассмотрим пример типа анализа
кластерный анализ
Кластерный анализ ‑ математическая процедура многомерного анализа, позволяющая на основе множества показателей, характеризующих ряд объектов, сгруппировать их в кластеры таким образом, чтобы объекты, входящие в один кластер, были более однородными, сходными, по сравнению с объектами, входящими в другие кластеры.
В основе данного анализа лежит вычисление расстояния между объектами. Именно исходя из расстояний между объектами и производится их группировка по кластерам. Определение расстояния может проводиться разными способами (по разным метрикам). Поддерживаются следующие метрики:
- Евклидова метрика,
- Евклидова метрика в квадрате,
- Метрика города,
- Метрика доминирования.
После определения расстояний между объектами может использоваться один из нескольких алгоритмов распределения объектов по кластерам. Поддерживаются следующие методы кластеризации:
- Ближняя связь,
- Дальняя связь,
- k-средних,
- Центр тяжести.
Схематично механизм проведения кластерного анализа можно представить следующим образом:
Схема выполнения кластерного анализа
На вход объекту АнализДанных подается источник данных. В качестве источника может выступать результат запроса, таблица значений, область ячеек табличного документа. Колонки источника определяются как входные либо неиспользуемые. Следует отметить, что все значения колонок содержатся в системном перечислении ТипКолонкиАнализаДанныхКластеризация. В этом перечислении значений больше (не только неиспользуемые и входные), но другие значения используются при построении прогнозов.
Анализ производится в соответствии с установленными параметрами анализа.
В качестве примера, иллюстрирующего возможность проведения кластерного анализа, будем использовать следующий фрагмент кода:
Запрос выполняется по справочнику Контрагенты. По условию запроса выбираются только детальные записи справочника из группы Юридические лица.
Выполнение указанного кода приведет к тому, что в качестве начальных установок анализа данных будут определены следующие значения (часть установлена явно, часть ‑ по умолчанию):
Параметры анализа
Состав колонок определился, исходя из состава полей выборки запроса. По умолчанию они определены с равным весом. Для типов Число и Дата определен вид данных Непрерывные, для остальных типов ‑ Дискретные. При необходимости изменить параметры колонок это можно сделать по аналогии с приведенным фрагментом:
В данной строке для колонки КоличествоАвтомобилей увеличен вес.
Результат анализа будет получен в следующем виде:
Отметим тот факт, что в результате анализа получаются данные именно о найденных кластерах (их количество, центры, расстояния между ними). В результате анализа не получаются данные о том, какие объекты (в нашем случае контрагенты) в какие кластеры входят. Подобное поведение наблюдается в случае, если настройка параметров проводимого анализа не проводится явным образом (а именно параметра ТипЗаполненияТаблицы).
Для того чтобы в результате анализа увидеть распределение объектов по кластерам, необходимо перед выполнением анализа (но после определения его типа) определить следующую строку кода:
Используемые метрики
Разберемся с метриками, которые могут использоваться при проведении кластерного анализа.
1. Евклидова метрика
В данной метрике расстояние между двумя объектами вычисляется по формуле:
- Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
- Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
- i ‑ номер атрибута, от 1 до n;
- n ‑ число атрибутов.
Предположим, что объекты характеризуются одним свойством, которое у одного объекта имеет значение 9, у другого ‑ 5. Весовой коэффициент данного атрибута равен единице. Расстояние между объектами будет равно:
2. Евклидова метрика в квадрате
В данной метрике расстояние между двумя объектами вычисляется по формуле:
- Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
- Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
- i ‑ номер атрибута, от 1 до n;
- n ‑ число атрибутов.
Предположим, что объекты характеризуются одним свойством, которое у одного объекта имеет значение 5, у другого ‑ 3. Весовой коэффициент данного атрибута равен двум. Расстояние между объектами будет равно:
3. Метрика города
В данной метрике расстояние между двумя объектами вычисляется по формуле:
- Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
- Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
- i ‑ номер атрибута, от 1 до n;
- n ‑ число атрибутов.
Предположим, что объекты характеризуются двумя атрибутами, которые имеют значения 3 и 5, 7 и 3. Вес первого равен 2, вес второго равен 1:
Характеристики объектов
4. Метрика доминирования
В данной метрике расстояние между двумя объектами вычисляется по формуле:
- Xi, Yi ‑ значения атрибутов двух объектов (между которыми определяется расстояние);
- Wi ‑ весовой коэффициент атрибута (устанавливается в колонке анализа);
- i ‑ номер атрибута, от 1 до n;
- n ‑ число атрибутов.
Предположим, что объекты характеризуются двумя атрибутами, которые имеют значения 3 и 5, 7 и 3. Вес первого равен 2, вес второго равен 1 .
Кластерный анализ - это совокупность методов классификации многомерных наблюдений или объектов, основанных на определении понятия расстояния между объектами с последующим выделением из них групп наблюдений (кластеров, таксонов).
Инструкция . Укажите количество данных, нажмите Далее . Полученное решение сохраняется в файле Word .
Выбор конкретного метода кластерного анализа зависит от цели классификации.
Обычной формой представления исходных данных в задачах кластерного анализа служит матрица:
каждая строка которой, представляет результат измерений k , рассматриваемых признаков на одном из обследованных объектов.
Наиболее трудным считается определение однородности объектов, которые задаются введением расстояния между объектами хi и хj (p(xi, xj)).
Объекты будут однородными в случае p(xi, xj)£ pпор,
где pпор- заданное пороговое значение.
Выбор расстояния (р) является основным моментом исследования, от которого зависят окончательные варианты разбиения. Наиболее распространенными считаются принципы “ближайшего соседа” или “дальнего соседа”. В первом случае за расстояние между кластерами принимают расстояние между ближайшими элементами этих кластеров, а во втором - между наиболее удаленными друг от друга.
В задачах кластерного анализа часто используют Евклидово и Хемингово расстояния.
Евклидово расстояние определяется по формуле:
;
сравнивается близость двух объектов по большому числу признаков.
Хемингово расстояние:
;
используется как мера различия объектов, задаваемых атрибутивными признаками.
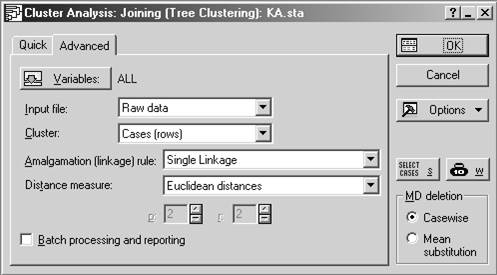
3. определить объекты кластеризации (Cluster): это могут быть переменные (столбцы) (Variables (columns)), либо наблюдения (строки) – Cases (rows). В последнем случае каждая строка таблицы исходных данных есть объект;
4. выбрать метрику, определяющую расстояние между кластерами – Amalgamation (linkage) rile;
5. выбрать метрику, определяющую расстояние между объектами – Distance measure.
Результаты кластеризации имеют следующий вид:
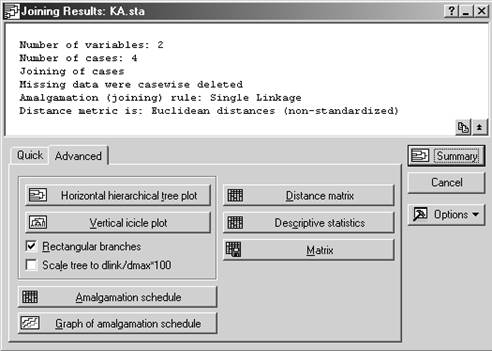
1) строится горизонтальная или вертикальная дендрограмма – график, на котором определены расстояния между объектами и кластерами при их последовательном объединении. Древовидная структура графика позволяет определить кластеры в зависимости от выбранного порога - заданного расстояния между кластерами;
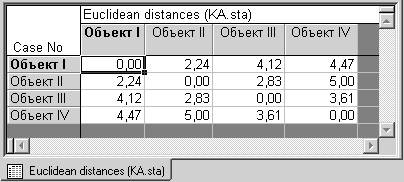
2) выводится матрица расстояний между исходными объектами (Distance matrix);
3) выводятся средние и среднеквадратичные отклонения для каждого исходного объекта (Discriptive statistics).
Для нашего примера.
Шаг 1. Для метода одиночной связи (Single Linkage).
Шаг 2.
Шаг 3.
ИЛИ
Шаг 4. Или то же, но в таблице.
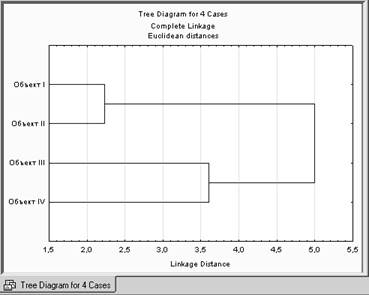
Шаг 5. Аналогично, для метода полной связи.
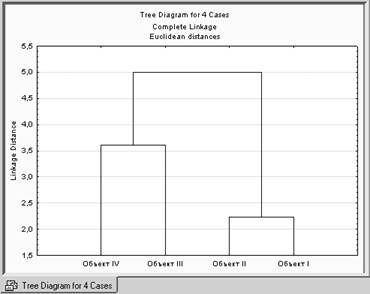
ИЛИ
Отрезки дендрограммы проводятся на уровнях, соответствующих пороговым значениям расстояний, выбираемым для данного шага кластеризации.
Например, кластеризация методом одиночной связи (ближайшего соседа) приводит к образованию одного кластера (пороговое расстояние равно 3.6), а кластеризация методом полной связи (дальнего соседа) при таком же пороговом расстоянии равным 3.6, приводит к образованию двух кластеров и т.д.
2.2. Метод К-средних (K-means clustering) относится к группе так называемых эталонных методов кластерного анализа. Число кластеров К задается пользователем. Процедура состоит в следующем. На первом шаге определяют К кластеров – эталонов (это могут быть, например, первые К объектов). Далее каждый объект присоединяется к ближайшему эталону. В качестве критерия используется минимальное расстояние внутри кластера относительно среднего. Как только объект включается в кластер, среднее пересчитывается. После пересчета эталона объекты снова распределяются по ближайшим кластерам и т.д. Процедура заканчивается при стабилизации процесса, т.е. при стабилизации центров тяжести.
Пример 3. Провести методом К-средних классификацию 10 объектов, каждый из которых характеризуется тремя признаками: X, Y, Z.
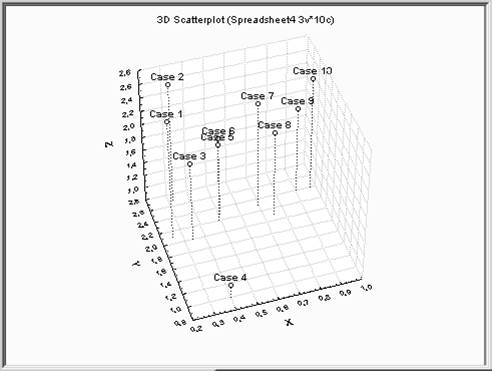
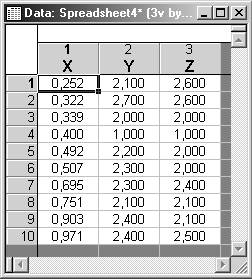
визуализация
данных
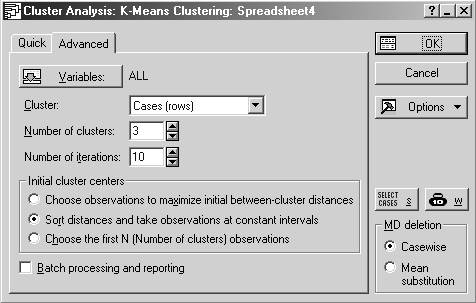
Шаг 1. Запустите модуль Кластерный анализ (Cluster Analysis). Выберите K-means clustering. В появившемся окне выполните следующие настройки:
а) выберите переменные для анализа (Variables): X, Y, Z;
б) определить объекты кластеризации (Cluster): наблюдения (строки) – Cases (rows);
в) задайте число кластеров, равное трем;
г) задайте число итераций;
д) выберите один из трех методов для начального определения центров кластеров (эталонов):
либо выбираются первые N объектов, либо выбираются объекты наиболее максимально отстоящие друг от друга, либо отстоящие друг от друга на одинаковом расстоянии.
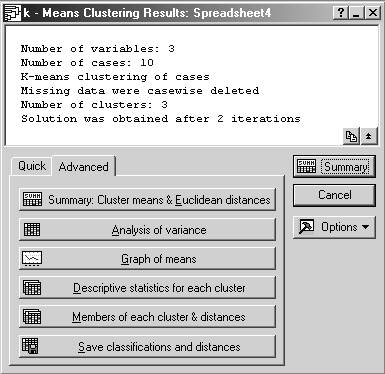
Шаг 2. Результаты кластеризации:
количество переменных: 3
количество строк: 10
метод К-средних для строк
удаление пустых строк из обработки
число кластеров: 3
процедура стабилизировалась после 2 итераций
матрица Евклидовых расстояний;
результаты дисперсионного анализа по каждому признаку;
график распределения центров кластеров;
описательные статистики для каждого кластера;
номера объектов, входящих в каждый кластер,
и расстояния до центра каждого кластера;
Шаг 3. В данном примере объекты распределились следующим образом:
МЕТОДЫ КЛАСТЕРНОГО АНАЛИЗА / СТАТИСТИЧЕСКИЙ АНАЛИЗ / СОЦИАЛЬНО-ЭКОНОМИЧЕСКИЕ ИНДИКАТОРЫ / МУНИЦИПАЛЬНАЯ СТАТИСТИКА / METHODS OF CLUSTER ANALYSIS / STATISTIC ANALYSIS / SOCIO-ECONOMICAL INDICATORS / MUNICIPAL STATISTICS
Аннотация научной статьи по математике, автор научной работы — Казанская Алина Юрьевна, Компаниец Виталий Сергеевич
Рассматриваются особенности применения различных методов кластерного анализа в решении задачи кластеризации городов по сформированной системе частных социально-экономических показателей при помощи пакета статистических программ Statsoft Statistica 6.0.
Похожие темы научных работ по математике , автор научной работы — Казанская Алина Юрьевна, Компаниец Виталий Сергеевич
THE RESEARCH EXPERIENCE OF CLUSTER ANALYSIS METHODS FROM PACKAGE STATISTICA 6.0 ON THE EXAMPLE OF TOWNS SAMPLE
Application Features of different cluster analysis methods are considered in solving the problem of towns clustering, on the basis of formed particular socio-economical indicators system, by means of program package Statsoft Statistica 6.0.
7. Майер В.В. Роль качества образования в социально-экономическом развитии // Экономика образования. 2006. - № 2 (33). - С. 71-74.
8. Красильникова Е.В., Ванеркина Т.С. Оценка качества образования с учетом требований потребителей // Экономика образования. - 2006.- № 2 (33). - С. 49-55.
9. Бурмистрова Е.В. Исследование рынка образовательных услуг с целью оценки удовлетворенности потребителей // Экономика образования. - 2006. - № 1(32). - С. 55-57.
10. Добрыднев С.И. К вопросу определения продукта вуза // Маркетинг в России и за рубежом. - 2004. - № 4 (42). - С. 28.
11. Федюкин И. Управление спросом и предложением на российском рынке образования // Отечественные записки. - 2007. - № 3 (35). - С. 45-53.
Задорожняя Елена Константиновна
347928, г. Таганрог, пер. Некрасовский, 44, тел. 371-742 Доцент.
Масыч Марина Анатольевна
Паничкина Марина Васильевна
Zadorognya Elena Konstantinovna
44, Nekrasovskiy, Taganrog, 347928, Russia, phone 371-742 Associate professor.
Masich Marina Anatolevna
А.Ю. Казанская, В.С. Компаниец
ОПЫТ ИССЛЕДОВАНИЯ МЕТОДОВ КЛАСТЕРНОГО АНАЛИЗА ИЗ ПАКЕТА STATISTICA 6.0 НА ПРИМЕРЕ ВЫБОРКИ ГОРОДОВ
Рассматриваются особенности применения различных методов кластерного анализа в решении задачи кластеризации городов по сформированной системе частных социально-экономических показателей при помощи пакета статистических программ Statsoft Statistica 6.0.
Методы кластерного анализа; статистический анализ; социально-экономические индикаторы; муниципальная статистика.
A.Y. Kazanskaya, V.S. Kompaniets
THE RESEARCH EXPERIENCE OF CLUSTER ANALYSIS METHODS FROM PACKAGE STATISTICA 6.0 ON THE EXAMPLE OF TOWNS’ SAMPLE
Application Features of different cluster analysis methods are considered in solving the problem of towns clustering, on the basis of formed particular socio-economical indicators system, by means of program package Statsoft Statistica 6.0.
Methods of cluster analysis; statistic analysis; socio-economical indicators; municipal statistics.
В пакете статистических программ Statsoft Statistica 6.0 в модуле кластерного анализа представлены семь иерархических агломеративных методов, итерационный метод k-средних и метод двухвходового объединения. В данной работе представлены результаты исследования возможности различных сочетаний методов кластеризации и мер сходства удовлетворительно решать задачу кластеризации городов по сформированной системе 12 частных индикаторов. В результате эксперимента должно быть выявлено такое сочетание метода кластеризации и меры сходства, которое лучшим, с точки зрения содержательного анализа, образом группирует города тестовой выборки. Качество получаемых в процессе эксперимента кластерных решений оценивалось формально по значению энтропии, а затем по результатам содержательного анализа. Момент остановки процедуры кластеризации, т.е. число и состав получаемых кластеров, определялся совместным анализом пошагового графика объединения и дендрограммы метода.
Эксперимент осуществлялся с группой всех иерархических агломеративных методов посредством перебора всех возможных сочетаний методов и мер сходства для кластеризации тестовой выборки.
Метод одиночной связи. Как и следовало ожидать, метод одиночной связи оказался непригоден. Удовлетворительного решения получено не было, так как во всех рассмотренных случаях с различными мерами сходства проявился цепной эффект.
Неудачей закончилось использование процента несогласия в качестве меры сходства. Ни один из семи методов с использованием данной меры не привел к решению. И этот результат следовало ожидать, так как исходные данные не являются категориальными.
Метод полной связи. Используя метод полной связи и евклидово расстояние в качестве меры сходства, было получено решение о разбиении тестовой выборки на два кластера. Резкий вертикальный скачок графика на последнем шаге итерации можно интерпретировать как объединение несхожих кластеров. Следовательно, решение уже получено и дальнейшее объединение кластеров не имеет смысла. Аналогично выполнялся поиск решений для других вариантов меры сходства. С помощью метода полной связи в четырех случаях из семи было получено решение
о разбиении тестовой выборки на два кластера. Использование в качестве меры сходства расстояния Чебышева и коэффициента корреляции привели к решению из трех кластеров. Процент несогласия в качестве меры сходства, как уже указывалось, к решению не привел.
Метод невзвешенного попарного среднего (UPGMA). Используя различные варианты меры сходства, метод позволил получить все решения из трех кластеров.
Методы средней связи. Из четырех рассмотренных методов средней связи решения позволили получить только два метода попарного среднего. Центроид-ные методы привели к цепочному эффекту. Объяснить такой результат можно неравными размерами образуемых кластеров.
Метод Уорда. Этот метод единственный из всех позволил получить решение из четырех кластеров (один случай из семи). Большинство же решений сводилось к трем кластерам.
Подводя общий предварительный итог использования агломеративных методов кластеризации, можно сделать следующие выводы.
1. Доминирующим решением является три кластера: из 24 приведших к решению вариантов 14 выявили три кластера, 9 - два кластера, 1 - четыре кластера.
рех кластеров необходимо более тщательно исследовать, так как оно соответствует сразу обеим указанным группам.
Таким образом, при использовании итерационного метода ^-средних следует установить значение числа кластеров, равное трем как наиболее вероятное, однако проверить следует разбиение и на четыре кластера (табл. 1, 2). Отметим, что все таблицы составлены авторами по материалам исследования.
Общие результаты разбиения на три кластера тестовой выборки методом ^-средних с различными способами определения начального разбиения
Способ разбиения Н Характеристика решения кластеризации
1 кластер 2 кластер 3 кластер
1, 32 1,45 10 (Брянск, Калининград, Киров, Курск, Магнитогорск, Мурманск, Смоленск, Сочи, Ставрополь, Тверь) 25 Армавир, Балаково, Батайск, Великие Луки, Волгодонск, Глазов, Димитровград, Златоуст, Камышин, Кисловодск, Ковров, Копейск, Миасс, Муром, Невинномысск, Новомосковск, Новотроицк, Новочеркасск, Новошахтинск, Обнинск, Орск, Пятигорск, Сарапул, Шахты, Энгельс, 12 Великий Новгород, Владикавказ, Владимир, Волжский, Калуга, Кострома, Нальчик, Новороссийск, Орел, Псков, Таганрог, Тамбов
2, 31 1,47 14 (Брянск, Владикавказ, Владимир, Калининград, Киров, Курск, Магнитогорск, Мурманск, Орел, Смоленск, Сочи, Ставрополь, Тамбов, Тверь) 24 Армавир, Балаково, Батайск, Великие Луки, Волгодонск, Глазов, Димитровград, Златоуст, Камышин, Кисловодск, Ковров, Копейск, Миасс, Муром, Невинномысск, Новомосковск, Новотроицк, Новочеркасск, Новошахтинск, Обнинск, Пятигорск, Сарапул, Шахты, Энгельс 9 Великий Новгород, Волжский, Калуга, Кострома, Нальчик, Новороссийск, Орск, Псков, Таганрог
1) автоматический подбор начального разбиения с максимальным межгруп-повым расстоянием;
2) автоматический подбор начальных центров групп по сортированному списку объектов;
3) прямое указание начальных центров групп вручную (один раз способ был применен без изменения исходного алфавитного списка городов - центрами стали Армавир, Балаково и Батайск (в таблице этот вариант помечен 31); второй раз (обозначение 32) центрами были указаны Калининград, Димитровград, Псков, так как в дендрограммах метода Уорда для трех кластеров указанные города чаще всего оказывались примерным геометрическим центром своего кластера).
В табл. 2 представлены решения методом ^-средних для четырех кластеров.
Общие результаты разбиения на четыре кластера тестовой выборки методом ^ средних с различными способами определения начального разбиения
Способ разбиения Н Характеристика решения кластеризации
1 кластер 2 кластер 3 кл. 4 кластер
1 1,74 9 (Брянск, Владикавказ, Владимир, Курск, Магнитогорск, Орел, Смоленск, Тамбов, Тверь) 24 Армавир, Балаково, Батайск, Великие Луки, Волгодонск, Глазов, Димитровград, Златоуст, Камышин, Кисловодск, Ковров, Копейск, Миасс, Муром, Невинномысск, Новомосковск, Новотроицк, Новочеркасск, Новошахтинск, Обнинск, Пятигорск, Сарапул, Шахты, Энгельс 5 Калининград, Киров, Мурманск, Сочи, Ставрополь 9 Великий Новгород, Волжский, Калуга, Кострома, Нальчик, Новороссийск, Орск, Псков, Таганрог
2 1,62 14 (Брянск, Владикавказ, Владимир, Калининград, Киров, Курск, Магнитогорск, Мурманск, Орел, Смоленск, Сочи, Ставрополь, Тамбов, Тверь) 24 Армавир, Балаково, Батайск, Великие Луки, Волгодонск, Глазов, Димитровград, Златоуст, Камышин, Кисловодск, Ковров, Копейск, Миасс, Муром, Невинномысск, Новомосковск, Новотроицк, Новочеркасск, Новошахтинск, Обнинск, Пятигорск, Сарапул, Шахты, Энгельс 2 7(+2) Великий Новгород, Волжский, Калуга, Кострома, Орск, Псков, Таганрог Нальчик, Новороссийск
32 1,77 8 (Великий Новгород, Владикавказ, Владимир, Калуга, Смоленск, Орел, Тамбов, Тверь) 24 Армавир, Балаково, Батайск, Великие Луки, Волгодонск, Глазов, Димитровград, Златоуст, Камышин, Кисловодск, Ковров, Копейск, Миасс, Муром, Невинномысск, Новомосковск, Новотроицк, Новочеркасск, Новошахтинск, Обнинск, Пятигорск, Сарапул, Шахты, Энгельс 8 (Брянск, Калининград, Киров, Курск, Магнитогорск, Мурманск, Сочи, Ставрополь) 9 (Волжский, Кострома, Нальчик, Новороссийск, Орск, Псков, Таганрог)
Аналогичным образом для третьего способа формирования начального разбиения указаны два варианта (см. табл. 2): 31 - центрами кластеров являются первые в списке по алфавиту города (Армавир, Балаково, Батайск и Брянск); 3 2 - центрами начальных групп стали примерные геометрические центры по дендрограмме метода Уорда (Великие Луки, Новочеркасск, Орел и Брянск). Отдельные решения для четырех кластеров дополнительно к двум указанным выше группам решений добавляют третью. Особенностью решений (способы 2 и 31 см. табл. 2) является разделение устойчиво сформированных в предыдущих итерациях кластеров
Результаты дисперсионного анализа группировок городов, построенных разными
1- автоматический подбор начального разбиения по максимуму межгруппового
32 - определение центров групп начального разбиения вручную
Способ 1 Способ 32
Нфакт В ост ВГ2 Р Нфакт Вост Р
VI 3458 3 1936 43 25,6044 0,000 3549,7 3 1845 43 27,6 0,000
у2 1203 3 5245 43 3,28997 0,029 1344 3 5105 43 3,8 0,017
v3 1518 3 874 43 24,8929 0,000 1559 3 833,6 43 26,8 0,000
v4 18536 3 4083 43 65,0738 0,000 18827 3 3793 43 71,2 0,000
v5 9471 3 3495 43 38,8379 0,000 10058 3 2909 43 49,6 0,000
419 3 4260 43 1,40988 0,253 325,6 3 4354 43 1,1 0,371
V? 2548 3 1213 43 30,1029 0,000 2403 3 1358 43 25,4 0,000
v8 4036 3 1504 43 38,4618 0,000 3738 3 1802 43 29,7 0,000
7060 3 2632 43 38,4578 0,000 6871 3 2821 43 34,9 0,000
vI0 19681 3 2948 43 95,7077 0,000 19871 3 2758 43 103,3 0,000
vII 8251 3 4114 43 28,7493 0,000 8112 3 4253 43 27,3 0,000
vI2 4614 3 3038 43 21,7726 0,000 4091 3 3561 43 16,5 0,000
Сравнивая по табл. 3 значения сумм квадратов отклонения, можно сделать вывод, что межгрупповая вариация ффакт) больше внутригрупповой фост) для всех индикаторов, кроме v2 и v6 (труд, законопослушность). Сопоставляя представленные значения ^-критерия с критическим фкрит=2,82 для df1=3, df2=43 ^=0,05) [1] следует сделать вывод, что в обоих случаях (1 и 32) влияние на формирование групп всех индикаторов, за исключением v6, является существенным, т.е. статистически значимым, так как F>Fкрит. Примечательно, что если совсем исключить из анализа индикатор v6, то оказывается, что состав кластеров не изменяется.
ков предлагается использовать значения удельного веса социально-экономических показателей городов в идентичных показателях соответствующего субъекта РФ. В частности, в официальных публикациях Росстата [3] используются ряд показателей, характеризующих вклад городов в общие социально-экономические показатели субъекта РФ: численность населения, среднегодовая численность работающих в организациях, основные фонды организаций, объемы промышленной продукции и работ, выполненных по договорам строительного подряда, ввод в действие жилых домов, оборот розничной торговли, инвестиции в основной капитал. Указанные показатели на самом деле являются внешними, так как характеризуют город как часть более общей социально-экономической системы - субъекта РФ. К тому же значения показателей уже являются относительными, что избавляет от необходимости их нормировать.
Результаты проверки обоснованности двух кластерных решений тестом значимости для внешних показателей
Внешние показатели к Вфакт Вост Р
Способ 1 начального разбиения
Численность населения (% субъекта) 0,72 4937 1646 21,374 0,0
Среднегодовая численность работающих (% субъекта) 0,72 6720 2240 23,480 0,0
Основные фонды организаций (% субъекта) 0,67 11761 3920 17,523 0,0
Объем промышленной продукции (% субъекта) 0,62 9463 3154 14,783 10'5
Объем работ по дог. строит. подряда (% субъекта) 0,66 11875 3958 18,814 0,0
Ввод в действие жилых домов (% субъекта) 0,67 13290 4430 17,551 0,0
Оборот розничной торговли (% субъекта) 0,74 16549 5516 25,431 0,0
Инвестиции в основной капитал (% субъекта) 0,70 12821 4274 16,819 0,0
Способ З2 начального разбиения
Численность населения (% субъекта) 0,73 5270 1757 25,374 0,0
Среднегодовая численность работающих (% субъекта) 0,75 7226 2409 28,797 0,0
Основные фонды организаций (% субъекта) 0,69 11961 3987 18,198 0,0
Объем промышленной продукции (% субъекта) 0,67 10345 3448 17,879 0,0
Объем работ по дог. строит. подряда (% субъекта) 0,71 12066 4022 19,530 0,0
Ввод в действие жилых домов (% субъекта) 0,67 13117 4372 17,051 0,0
Оборот розничной торговли (% субъекта) 0,77 17158 5719 28,209 0,0
Инвестиции в основной капитал (% субъекта) 0,69 12848 4283 16,896 0,0
В таблице 4 представлены результаты проверки значимости внешних показателей для группировки городов двумя способами.
Таким образом, проведенное экспериментальное исследование методов кластеризации не позволило выявить только один наилучший метод. Примерно равными характеристиками, но лучшими по сравнению с решениями остальных методов, обладают две разновидности итерационного метода ^-средних с автоматическим подбором начального разбиения по максимуму межгруппового расстояния и определением центров групп начального разбиения вручную, по дендрограмме. Следовательно, после определения примерных центров кластеров по дендрограмме метода Уорда с обратным коэффициентом корреляции в качестве меры сходства, указанные разновидности метода ^-средних в данном исследовании следует использовать совместно. Окончательное решение можно будет принять только в результате анализа устойчивости кластеризации по имеющимся статистическим данным за четыре года и содержательного анализа кластеров каждой из групп городов.
1. Елисеева И.И., Юзбашев М.М. Общая теория статистики. - М.: ФиС, 2001.
2. Олдендерфер М.С., Блэшфилд Р.К. Кластерный анализ // Факторный, дискриминантный и кластерный анализ. - М.: Финансы и статистика, 1988.
3. Регионы России: социально-экономическое положение городов. 2004: Стат. сб. - М.: Росстат, 2004.
Казанская Алина Юрьевна
Компаниец Виталий Сергеевич
Kazanskaya Alina Yur’evna
УПРАВЛЕНИЕ СОВРЕМЕННЫМИ ИННОВАЦИОННЫМИ И СОЦИАЛЬНО-ОРИЕНТИРОВАННЫМИ ИНВЕСТИЦИОННЫМИ ПРОЕКТАМИ И ИХ КЛАССИФИКАЦИЯ1
Рассматриваются особенности процесса управления современными инновационными и социально-ориентированными инвестиционными проектами. Дает-

Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам. Данную методику можно применять в программе Excel. Посмотрим, как это делается на практике.
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
-
Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:


На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Читайте также: