
Как сделать экспертную систему в эксель
Добавил пользователь Валентин П. Обновлено: 16.09.2024
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Больше. Основные параметры
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку "Пакет анализа".
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки "Надстройка анализа", вы можете загрузить надстройку VBA так же, как и надстройку "Надстройка анализа". В поле Доступные надстройки выберите "Надстройка анализа — VBA".
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий , имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений , используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения "различаются". В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные "различаются".
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа "Описательная статистика" применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа "Экспоненциальное сглаживание" применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f 1, "P(F
Инструмент "Анализ Фурье" применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.
Инструмент "Гистограмма" применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа "Скользящее среднее" применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент "Генерация случайных чисел" применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа "Регрессия" применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа "Выборка" создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как "t-статистика" в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t =0 "P(T
Z-тест. Средство анализа "Две выборки для середины" выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. "P(Z = ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. "P(Z = ABS(z) или Z
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Пикалов И.Ю., Тарасюк В.Б., Травкин Е.И.
В статье представлена экспертная система , реализованная в среде MS Excel средствами VBA, ориентированная на решение проблемно-ориентированной инженерной задачи . Определены некоторые приемы решения задачи проектирования тягово-транспортных машин на стадии принятия концептуальных решений с использованной вновь разработанной экспертной системы .
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Пикалов И.Ю., Тарасюк В.Б., Травкин Е.И.
Автоматизация бизнес-процессов логистических транспортных компаний на основе технологии объектно-ориентированного программирования в среде VBA
Использование объектноориентированного подхода в разработке программного обеспечения системы тестирования
ТЕХНОЛОГИЯ ПОСТРОЕНИЯ И ОБУЧЕНИЯ ИНТЕЛЛЕКТУАЛЬНОГО МОДУЛЯ ЭКСПЕРТНОЙ СИСТЕМЫ ДЛЯ РЕШЕНИЯ ИНЖЕНЕРНОЙ ЗАДАЧИ СРЕДСТВАМИ VBA
© 2018 И. Ю. Пикалов1, В. Б. Тарасюк2, Е. И. Травкин3
Курский государственный университет
В статье представлена экспертная система, реализованная в среде MS Excel средствами VBA, ориентированная на решение проблемно-ориентированной инженерной задачи. Определены некоторые приемы решения задачи проектирования тягово-транспортных машин на стадии принятия концептуальных решений с использованной вновь разработанной экспертной системы.
Ключевые слова: экспертная система, интеллектуальный модуль, модуль сопряжения данных, инженерная задача, колесная тягово-транспортная машина.
Важнейшим ресурсом повышения эффективности решения инженерных задач является применение систем автоматизированного проектирования, автоматизированных систем принятия решений, интегрированных цифровых баз данных и баз знаний, экспертных систем и интеллектуальных систем проектирования. На каждом этапе разработки проектной документации приоритет имеют те или иные из выше перечисленных инструментов. Представляется, что наиболее перспективными из них являются интеллектуальные системы проектирования и экспертные системы, базирующиеся на современных экспертных знаниях, интегрирующие в себе предыдущий опыт проектирования. Под интеллектуальными системами понимаются технические или программные системы, способные решать задачи, традиционно считающиеся творческими, принадлежащие конкретной предметной области, знания о которой хранятся в памяти такой системы. Структура интеллектуальной системы включает три основных блока — базу знаний, механизм вывода решений и интеллектуальный интерфейс [Головицына 2008.].
При создании экспертных систем, ориентированных на решение инженерных задач, возможно использование специализированных оболочек, реализующих экспертные системы, универсальных языков программирования высокого уровня, различных инструментальных сред и т.п. Однако для отработки модельных решений на первоначальном этапе первоначальном этапе предпочтительнее использовать инструмент, позволяющий наиболее транспарентно и развернуто представлять взаимосвязи, присутствующие в структуре системе. Немаловажное значение в реализации транспарентности имеет адекватный выбор инструмента для построения экспертной системы. Этот инструмент должен обеспечивать возможность построения
экспертной системы непрограммирующим пользователям; обеспечивать визуализацию базы знаний и механизма принятия решений; удобный и интуитивно-понятный интерфейс. Наиболее популярным инструментом, соответствующим данным требованиям является MS Excel. Ранее нами [Пикалов, Тарасюк, Травкин 2018] достаточно развернуто представлено обоснование применения MS Excel в комплексе с инструментарием VBA для решения задачи построения экспертных систем, ориентированных на решение проблемно-ориентированных задач.
Ранее установлено, что на склонность к галопированию оказывают влияние следующие параметры конструкции колесных тягово-транспортных машин [Тарасюк 1985]:
- координаты центра масс остова;
- радиальная и тангенциальная жесткость шин;
- инерционные характеристики и трансмиссии;
- динамический радиус движителей;
- жесткостные и демпфирующие параметры системы.
Однако на начальных стадиях концептуального проектирования колесных тягово-транспортных машин требуется определить основные схемные характеристики: конструкционную массу; распределение нормальных нагрузок по мостам и статический прогиб в ходовой системе. Следовательно, комплекс значений этих параметров может служить входным набором атрибутов, оцениваемых экспертной системой по критерию галопирования. Данные параметры имеют числовые значения, варьируемые в широком диапазоне, и в случае попытки использовать их фронтально может возникнуть ситуация, когда экспертная система будет вынуждена обрабатывать бесконечное количество наборов. Для преодоления данной ситуации предлагается формализовать их и привести к максимально оптимизированному множеству безразмерных интегральных характеристик, алгебраически связанных с базовыми проектными характеристиками тягово-транспортной машины.
Сформируем множество атрибутов, планируемых к использованию в качестве исходных переменных для экспертной системы.
1. Исполнение конструкции тягово-транспортной машины по колесной схеме 4к4а.
2. Коэффициент распределения масс
где Iо — центральный момент инерции остова, М0 — масса остова, ^ —
продольная база, \, 1\ = ^ — /1 — горизонтальные координаты центра масс тягово-транспортной машины.
3. Парциальная частота вертикальных колебаний переднего моста
где Сх — радиальная жесткость шины передних колес или приведенная жесткость шины и упругого элемента системы подрессоривания, Мх — масса тягово-
транспортной машины, приходящаяся на передний мост + у* \ — ~ .
4. Парциальная частота вертикальных колебаний заднего моста
где C2 — радиальная жесткость шины задних колес или приведенная жесткость шины и упругого элемента системы подрессоривания, M2 — масса тягово-транспортной
машины, приходящаяся на задний мост Ml 2 —-.
Тем не менее не трудно заметить, что атрибуты 2-4 выражаются числовыми значениями. Следовательно, требуется их дальнейшая трансформация к логическому типу. Предлагается произвести эти действия с помощью специального модуля сопряжения, осуществляющего подготовку данных к вводу в экспертную систему. Опираясь на имеющиеся данные для второго атрибута (коэффициент распределения масс), применяем условие: если 0,9 -2,786/^ + 6,501/ - 0,409 или f2 Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Рис. 5. Листинг процедуры, обеспечивающей режим распознавания экспертной системы
В случае появления новых экспериментальных или фундаментальных теоретических знаний в рассматриваемой области экспертная система, включая модуль сопряжения, может быть переобучена и таким образом актуализирована.
Головицына М.В. Информационные технологии проектирования радиоэлектронных средств // БИНОМ. Лаборатория знаний, Интернет-университет информационных технологий. ИНТУИТ.ру, 2008.
Нейлор К. Как построить свою экспертную систему: пер. с англ. М.: Энергоатомиздат, 1991. 286 с.
Тарасюк В.Б. Математическая модель системы двигатель-трансмиссия-подвеска колесного трактора с учетом буксования движителей // Повышение надежности и тягово-сцепных качеств трактора. М.: МАМИ, 1985. С. 36-44.

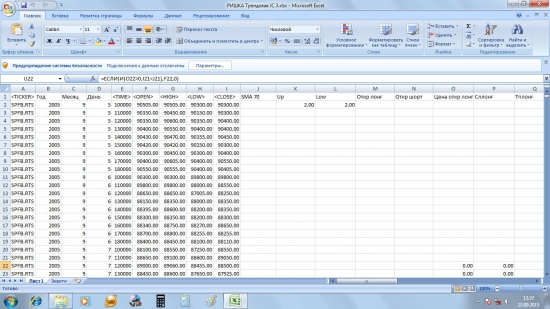
Теперь нам необходимо построить таблицу, которая будет иметь следующий вид: в первой её части будут сами котировки, будут заданы параметры Боллинджера, а также будут заданы условия открытия позиций;
во второй части будут определены цены открытия позиций, условия и цены закрытия позиций, объём открытых позиций в деньгах и по количеству контрактов, объём закрытых позиций в деньгах, а также возможные издержки (комиссионные+проскальзывание);
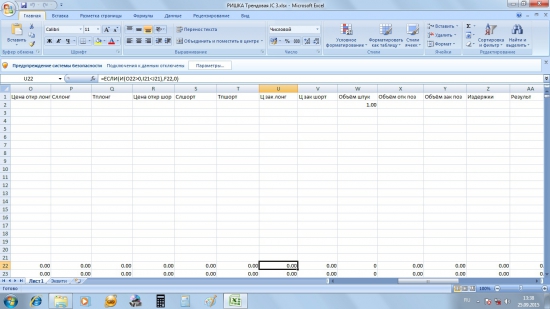
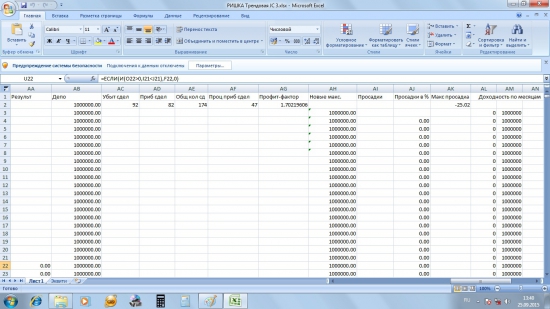
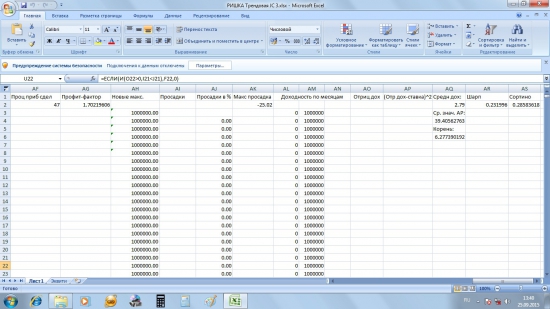
в третьей части таблицы будут показаны результаты системы, изменение депо и кроме того будут рассчитаны параметры, необходимые для оценки эффективности системы, такие как относительное количество прибыльных сделок, профит-фактор, максимальная просадка, плюс будут рассчитаны два коэффициента для оценки волатильности кривой капитала (коэффициенты Шарпа и Сортино).
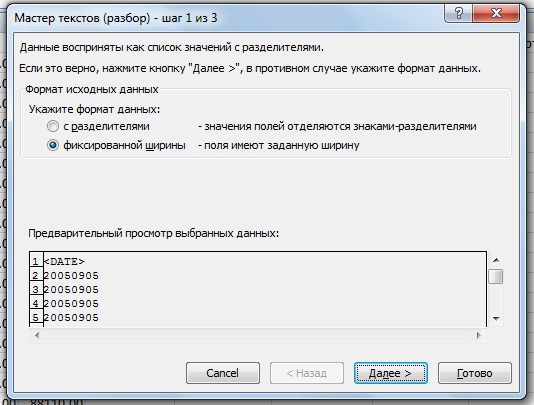
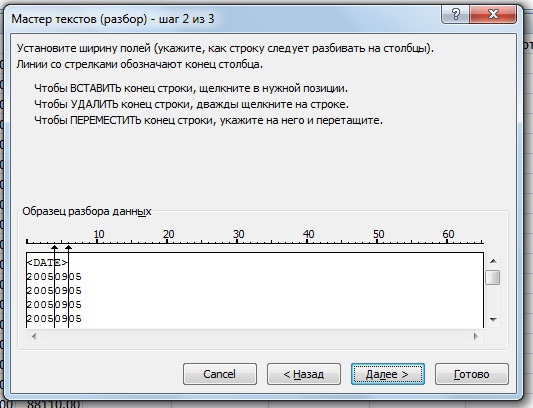
на втором шаге вручную расставляем разделители,
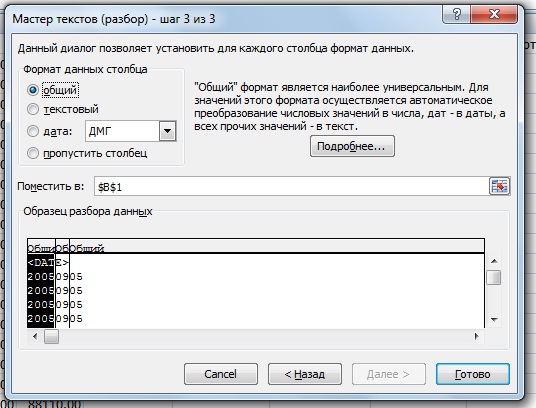
А теперь основные функции.
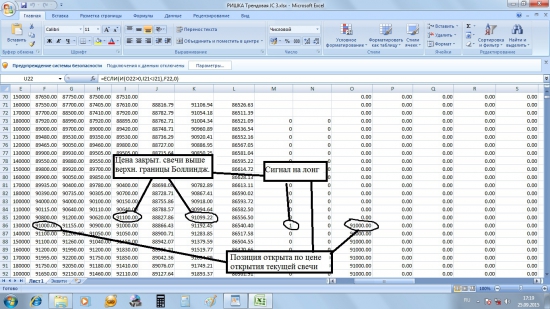
2.) Задаём условия для открытия позиций.
В ячейку M73 занесём формулу для открытия лонга.
Условие сформулировано так: если предыдущая свеча закрылась выше верхней полосы Боллинджера, на этой свече открывается лонг.
Используем функцию ЕСЛИ: В M73 пишем:
=ЕСЛИ(I72>K72;1;0)
(если цена закрытия (значение в ячейке I72) будет выше значения в ячейке K72, в столбце появится единица, которая будет сигналом на вход; в ином случае будет 0).
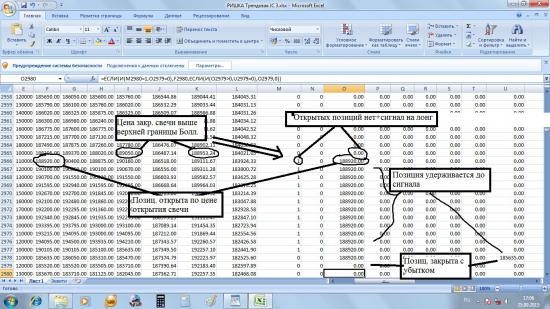
Аналогичную формулу пишем в столбец N73, но только значение I72 должно быть ниже значения в ячейке L72: =ЕСЛИ(I72 0;I21 0;U21=0);O21
И добавим эту функцию в имеющуюся формулу:
=ЕСЛИ(И(M22=1;O21=0);F22; ЕСЛИ(И(O21>0;U21=0);O21;0))
Формула читается так: Если открытой позиции нет (O21=0), но есть сигнал на открытие позиции (M22=1), позиция открывается на текущей свече (F22); в ином случае — если позиция была открыта (O21>0) и сигнала на её закрытие нет (U21=0), позиция удерживается (O21); и наконец если ни одно из условий не соответствует действительности (нет сигнала на лонг (M22=1) или поступил сигнал на закрытие лонга (U21>0)) — то значение в столбце O равно нулю — открытых позиций нет (вне рынка).
Аналогичным образом задаются условия на открытие, удержание и закрытие шорта в соответствующих столбцах (R и V).
Пока всё) Потом допишу. Сейчас нет времени. Да и многовато для одного поста)
Читайте также: