
Как сделать уголь из oak log stack
Обновлено: 04.07.2024
Если у вас есть топор, то возьмите его, если топора нет, то дерево можно рубить даже голыми руками, только на это уйдет гораздо больше времени. Подойдите к дереву вплотную и зажмите левую кнопку мыши на части дерева, которую нужно срубить, через несколько ударов блок дерева будет срублен. Собрать листву можно только с помощью ножниц, чтобы использовать листья как декорацию, нужно подложить под них блок дерева.
Сведения про листву тропического дерева
- из разрушенных блоков листвы тропического дерева иногда выпадают саженцы (этого же вида дерева);
- если уничтожить ствол тропического дерева, то рано или поздно листва исчезнет;
- листва, которую добыли при помощи ножниц, поставленная на землю, не исчезает.
Вся листва в Майнкрафте разная
До некоторых пор в Майнкрафте было 4 вида листвы, но с выходом Minecraft версии 1.7.2, когда появились листья темного дуба и акации, их стало шесть. То, что листва отличается внешне, видно на скриншоте, где листья березы отмечены белой рамкой.

На изображении вся листва из Майнкрафта, а для сравнения рядом: березовые доски → береза (древесина) → листва березы.
Видео
Как получить твердолист через админку?
Для тех, у кого нет никакого желания заниматься поисками твердолиста и его выращиванием, предлагаем использовать режим администратора, где можно прописать команду и получить данное растение в неограниченном количестве. Но перед тем как решите воспользоваться читами, следует убедиться, что они разрешены в мире. В ином случае придётся создать новый мир, где они будут разрешены. И как только решите эту проблему, можно уже будет воспользоваться инструкцией:
Кроме этого, любая команда прописывается без кавычек, но, если даже в таком случае не получается воспользоваться командой или даже режимом администратора, тогда предлагаем воспользоваться функциями командного блока. После того как поставите его, команду следует прописать внутри него. В конце она активируется автоматическим образом после того, как до командного блока дойдёт сигнал от красного камня.
Команда получения дубовых листьев
Здесь указана команда, которая позволяет получить дубовые листья в Майнкрафте, то есть как в Minecraft создать дубовые листья.
Разберём основы логирования в Docker и Kubernetes, а затем рассмотрим два инструмента, которые можно смело использовать на продакшене: Grafana Loki и стек EFK: Elasticsearch + Fluent Bit + Kibana.
Логирование в Docker
На уровне Kubernetes приложения запущены в Pod'ах, но на уровне ниже они всё-таки работают обычно в Docker. Поэтому нужно настроить логирование таким образом, чтобы собирать логи с контейнеров. Контейнеры запускает Docker, значит надо разобраться, как логирование устроено на уровне Docker.
Надеюсь, каждый читатель знает: логи приложения надо писать в stdout/stderr, а не внутрь контейнера. Логи агрегирует Docker Daemon, и он работает именно с теми логами, которые отправляются на stdout/stderr. К тому же запись логов внутрь контейнера чревата проблемами: контейнер пухнет от растущего лога (так как никакого Logrotate в контейнере скорее всего нет), а Docker Daemon и не в курсе про этот лог.
У Docker есть несколько лог-драйверов или плагинов для сбора логов контейнеров. В бесплатной версии Docker Community Edition (CE) лог-драйверов меньше, чем в коммерческой Docker Enterprise Edition (EE).
Лог-драйверы в Docker CE:
local — запись логов во внутренние файлы Docker Daemon;
json-file — создание json-log в папке каждого контейнера;
journald — отправка логов в journald.

Настройки логирования в Docker находятся в файле daemon.json.
В поле “log-driver” указывают плагин, а в поле “log-opts” — его настройки. В примере выше указан плагин “json-file”, ограничение по размеру лога — “max-size”: “10m”; ограничение по количеству файлов (настройки ротации) — “max-file”: “3”; а также значения, которые будут прикручены к логам.
Некоторые настройки лог-драйвера можно задать через командную утилиту; это удобно, если отдельный контейнер нужно запустить с другим лог-драйвером.
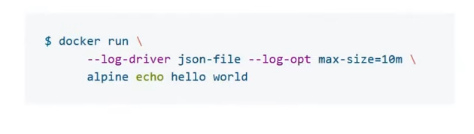
Вот как выглядит схема логирования в Docker:
Как схема работает: лог-драйвер, например json-file, создаёт файлы. Сборщики логов (Rsyslog, Fluentd, Logagent и другие) эти файлы собирают и передают на хранение в Elastic, Sematext или другие хранилища.
Особенности логирования в Kubernetes
Упрощённо схема логирования в Kubernetes выглядит так: есть pod, в нём запущен контейнер, контейнер отправляет логи в stdout/stderr. Затем Docker создаёт файл и записывает логи, которые затем может ротировать.
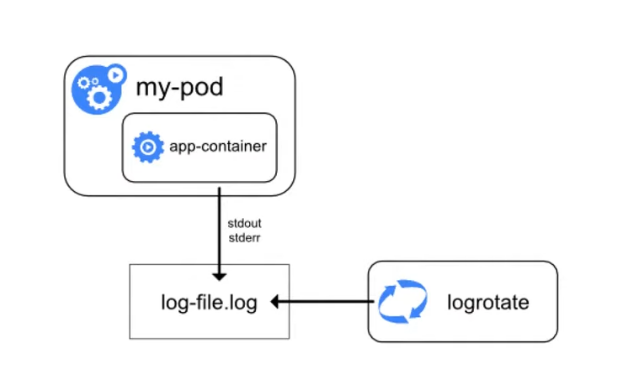
Рассмотрим особенности логирования в Kubernetes.
Сохранять логи между деплоями. Это обязательное условие для корректной настройки логирования. Если не сохранять логи между деплоями, то при выходе новой версии приложения логи предыдущей будут затираться, перезагрузка контейнера также будет чревата потерей логов. У Kubernetes есть ключик --previous, он позволяет посмотреть логи приложения до последнего рестарта Pod’а, но не глубже.
Агрегировать логи со всех инстансов. Если микросервисы хостятся в облаках, то за контроль системы отвечает облачный провайдер. Если микросервисы на своём железе, то помимо логов с контейнеров нужно собирать и логи системы.
Эксперименты продолжались, и нашёлся другой способ. В CentOS 7 основные системные логи (messages, audit, secure) дублируются в var-лог в виде файлов. В Docker тоже можно настроить сохранение логов в файлы json. Соответственно, эти файлы из CentOS 7 и Docker можно собирать вместе.
Со временем стало популярно решение ELK Stack. Это комбинация нескольких инструментов: Elasticsearch, Logstash и Kibana.
Elasticsearch хранит логи с контейнеров, Logstash собирает логи с инстансов, Kibana позволяет обрабатывать полученные логи, строить по ним графики. Некоторое время ELK Stack активно использовали, но, на мой взгляд, его время проходит. Позже расскажу, почему.
Добавлять метаданные. Pod’ы, приложения, контейнеры могут быть запущены где угодно. Более того, у одного приложения может быть несколько инстансов. Логи записаны в одном формате, а нам надо понять, какая именно это реплика, какой Pod это пишет, в каком namespace он находится. Именно поэтому логам нужно добавлять метаданные.
Парсить логи. Забавно, но расходы на поддержку системы логирования и мониторинга могут превысить затраты на основное приложение. Когда у вас летят десятки и сотни тысяч логов в секунду, это кажется закономерным, но всё же надо знать грань. Один из способов эту грань найти — парсинг логов.
Бездумно фильтровать логи не рекомендуют, потому что отфильтрованных данных может не хватить для нормальной аналитики. С другой стороны, возможно аналитику стоит проводить не на уровне логирования, а на уровне сбора метрик. Тогда не придётся хранить сотни тысяч строк с кодом 200. Один из подходов — получать информацию о трафике и ошибках из метрик ingress-контроллеров.
В общем, здесь надо хорошо подумать: что вы хотите хранить и как долго, потому что иначе возникнет ситуация, когда система логирования будет отнимать ресурсов больше, чем основной проект.
Пока нет стандартного решения для логирования. В отличие от мониторинга, где есть одно, наиболее распространенное решение Prometheus, в логировании стандарта нет. В рамках этой лекции мы рассмотрим два инструмента: один популярный, а второй — набирающий популярность. Помимо них есть и другие, но в этой статье мы их не коснёмся.
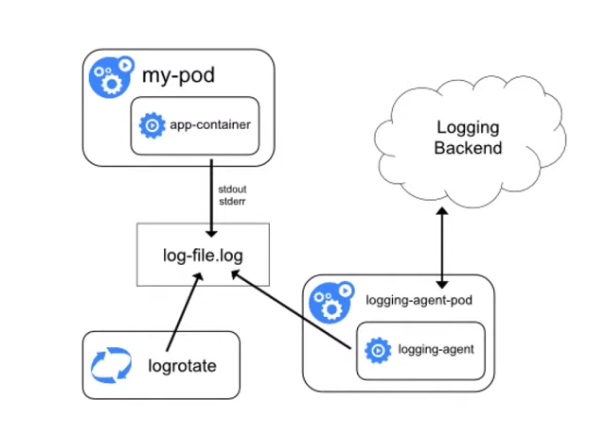
Учитывая все рассмотренные выше особенности, логирование в Kubernetes теперь можно представить на такой схеме:
Остаётся лог контейнера, ротирование, но появляется агент-сборщик, который подбирает логи и отправляет на хранение (на схеме — в Logging Backend). Агент работает на каждой ноде и, как правило, запущен в Kubernetes.
Теперь рассмотрим инструменты для логирования.
Grafana Loki
Небольшое отступление про TSDB для тех, кто не читал предыдущую статью: TSDB отлично справляется с задачей хранения большого количества данных, временных рядов, но не предназначена для долгого хранения. Если по какой-то причине вам нужно хранить логи дольше двух недель, то лучше настроить их передачу в другую БД.
Ещё одно преимущество Loki — для визуализации данных используется Grafana. Очень удобно: в Grafana мы смотрим данные по мониторингу и там же, подключив Loki, смотрим логи. По логам можно строить графики.
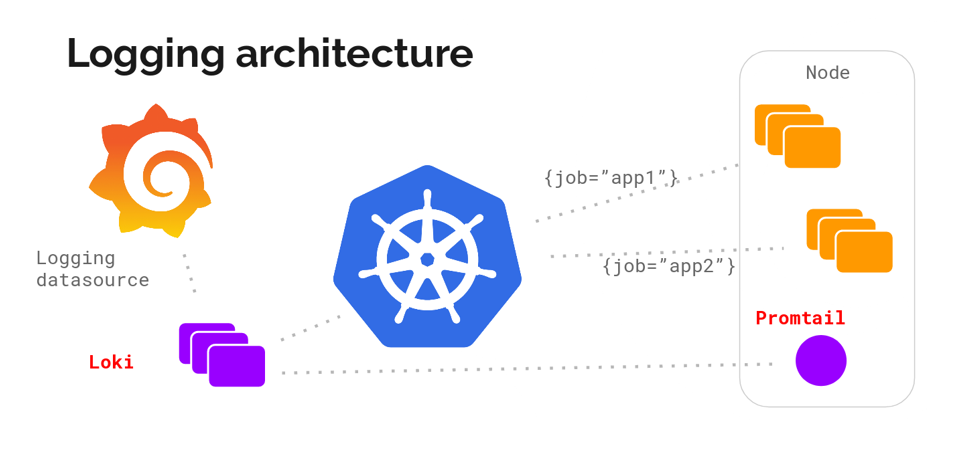
Архитектура Loki выглядит примерно так: '
С помощью DaemonSet на всех серверах кластера разворачивается агент — Promtail или Fluent Bit. Агент собирает логи. Loki их забирает и хранит у себя в TSDB. К логам сразу добавляются метаданные, что удобно: можно фильтровать по Pod’ам, namespaces, именам контейнеров и даже лейблам.
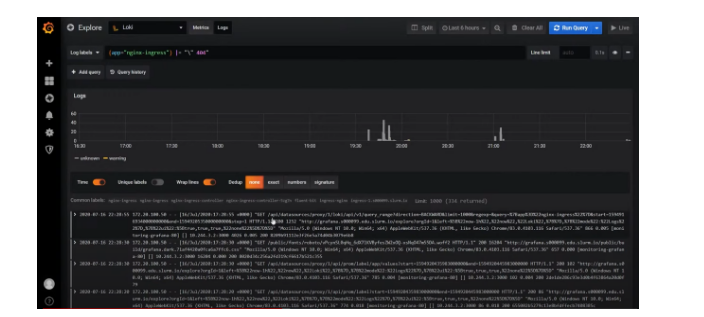
Loki работает в знакомом интерфейсе Grafana. У Loki даже есть собственный язык запросов, он называется LogQL — по названию и по синтаксису напоминает PromQL в Prometheus. В интерфейсе Loki есть подсказки с запросами, поэтому не обязательно их знать наизусть.
Документация к языку LogQL
Loki в интерфейсе Grafana
Используя фильтры, в Loki можно найти коды (“400”, “404” и любой другой); посмотреть логи со всей ноды; отфильтровать все логи, где есть слово “error”. Если нажать на лог, раскроется карточка со всей информацией по событию.
В Loki достаточно инструментов, которые позволяют вытаскивать нужные логи, (хотя честно говоря, технически их могло быть и больше). Сейчас Loki активно развивается и набирает популярность.
Elastic + Fluent Bit + Kibana (EFK Stack)
Стек EFK — это более классический, и при этом не менее популярный инструмент логирования.
В начале статьи упоминался ELK (Elasticsearch + Logstash + Kibana), но этот стек устарел из-за не очень производительного и при этом ресурсоёмкого Logstash. Вместо него стали использовать более легковесный и производительный Fluentd, а спустя некоторое время ему в помощь пришёл Fluent Bit — ещё более легковесный, и ещё более производительный агент-сборщик.
У Fluent Bit меньше возможностей, чем у Fluentd, но основные потребности он закрывает, поэтому мы в основном пользуемся Fluent Bit.
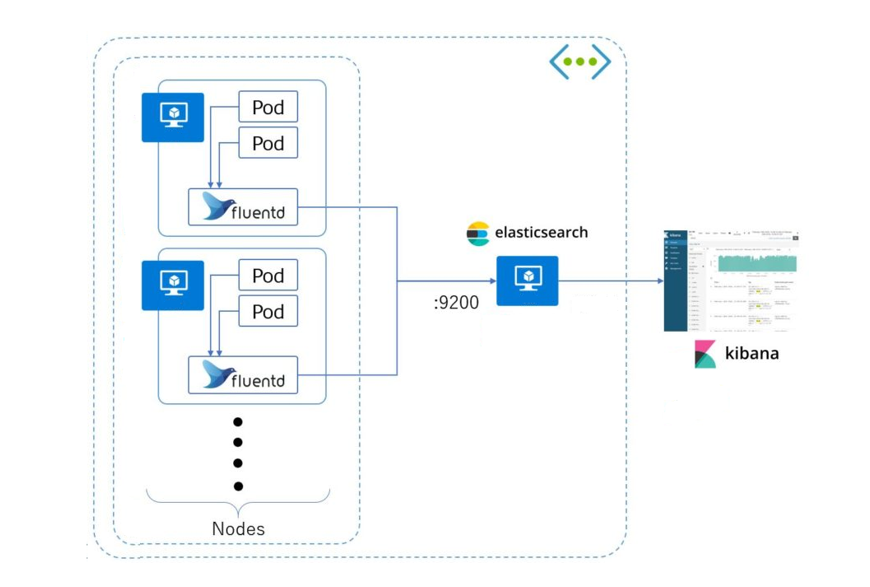
Схема работы стека EFK: агент собирает логи со всех Pod’ов (как правило, это DaemonSet, запущенный на всех серверах кластера) и отправляет в хранилище (Elasticsearch, PostgreSQL или Kafka). Kibana подключается к хранилищу и достаёт оттуда всю необходимую информацию.
Kibana представляет информацию в удобном веб-интерфейсе. Есть графики, фильтры и многое другое.
По логам можно создавать целые дашборды.
Вариант настройки дашборда в Kibana
Возможности Fluent Bit
Так как о Fluent Bit, как правило, слышали меньше, чем о Logstash, рассмотрим его чуть подробнее. Fluent Bit логически можно поделить на 6 модулей, на часть модулей можно навесить плагины, которые расширяют возможности Fluent Bit.
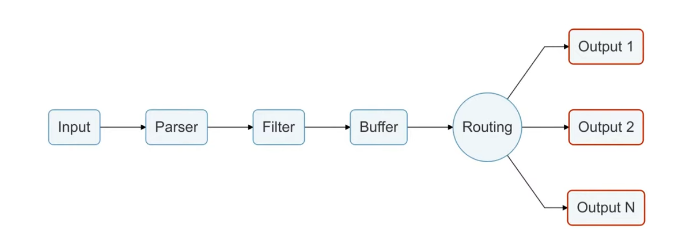
Модуль Input собирает логи из файлов, служб systemd и даже из tcp-socket (надо только указать endpoint, и Fluent Bit начнёт туда ходить). Этих возможностей достаточно, чтобы собирать логи и с системы, и с контейнеров.
В продакшене мы чаще всего используем плагины tail (его можно натравить на папку с логами) и systemd (ему можно сказать, из каких служб собирать логи).
Модуль Parser приводит логи к общему виду. По умолчанию логи Nginx представляют собой строку. С помощью плагина эту строку можно преобразовать в JSON: задать поля и их значения. С JSON намного проще работать, чем со строковым логом, потому что есть более гибкие возможности сортировки.
Модуль Filter. На этом уровне отсеиваются ненужные логи. Например, на хранение отправляются логи только со значением “warning” или с определёнными лейблами. Отобранные логи попадают в буфер.
Модуль Buffer. У Fluent Bit есть два вида буфера: буфер памяти и буфер на диске. Буфер — это временное хранилище логов, нужное на случай ошибок или сбоев. Всем хочется сэкономить на ОЗУ, поэтому обычно выбирают дисковый буфер, но нужно учитывать, что перед уходом на диск логи всё равно выгружаются в память.
Модуль Routing/Output содержит правила и адреса отправки логов. Как уже было сказано, логи можно отправлять в Elasticsearch, PostgreSQL или, например, Kafka.
Интересно, что из Fluent Bit логи можно отправлять во Fluentd. Так как первый более легковесный и менее функциональный, через него можно собирать логи и отправлять во Fluentd, и уже там, с помощью дополнительных плагинов, их дообрабатывать и отправлять в хранилища.
Если вы используете стек Elastic (ELK) и заинтересованы в сопоставлении пользовательских журналов Logstash с Elasticsearch, то этот пост для вас.

Стек ELK – это аббревиатура для трех проектов с открытым исходным кодом: Elasticsearch, Logstash и Kibana. Вместе они образуют платформу управления журналами.
- Elasticsearch – это поисковая и аналитическая система.
- Logstash – это серверный конвейер обработки данных, который принимает данные из нескольких источников одновременно, преобразует их и затем отправляет в “тайник”, например Elasticsearch.
- Kibana позволяет пользователям визуализировать данные с помощью диаграмм и графиков в Elasticsearch.
Beats появился позже и является легким грузоотправителем данных. Введение Beats преобразовало Elk Stack в Elastic Stack, но это не главное.
Эта статья посвящена Grok, которая является функцией в Logstash, которая может преобразовать ваши журналы, прежде чем они будут отправлены в тайник. Для наших целей я буду говорить только об обработке данных из Logstash в Elasticsearch.

Grok-это фильтр внутри Logstash, который используется для разбора неструктурированных данных на что-то структурированное и подлежащее запросу. Он находится поверх регулярного выражения (regex) и использует текстовые шаблоны для сопоставления строк в файлах журналов.
Как мы увидим в следующих разделах, использование Grok имеет большое значение, когда речь заходит об эффективном управлении журналами.
Без Grok ваши данные журнала Неструктурированы
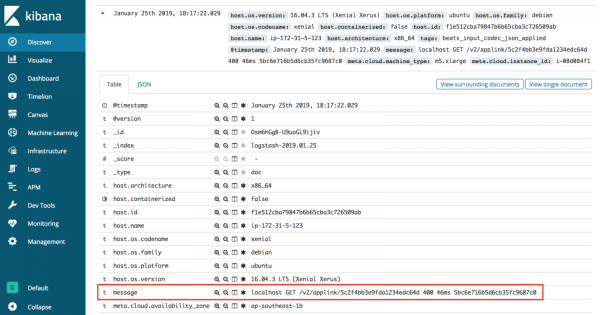
Неструктурированные данные из логов
Если вы внимательно посмотрите на необработанные данные, то увидите, что они на самом деле состоят из разных частей, каждая из которых разделена пробелом.
Структурированный вид наших данных
- localhost == environment
- GET == method
- /v2/applink/5c2f4bb3e9fda1234edc64d == url
- 400 == response_status
- 46ms == response_time
- 5bc6e716b5d6cb35fc9687c0 == user_id
Как мы видим в структурированных данных, существует порядок для неструктурированных журналов. Следующий шаг – это программная обработка необработанных данных. Вот где Грок сияет.
Шаблоны Grok
Встроенные шаблоны Grok
Logstash поставляется с более чем 100 встроенными шаблонами для структурирования неструктурированных данных. Вы определенно должны воспользоваться этим преимуществом, когда это возможно для общих системных журналов, таких как apache, linux, haproxy, aws и так далее.
Однако что происходит, когда у вас есть пользовательские журналы, как в приведенном выше примере? Вы должны построить свой собственный шаблон Grok.
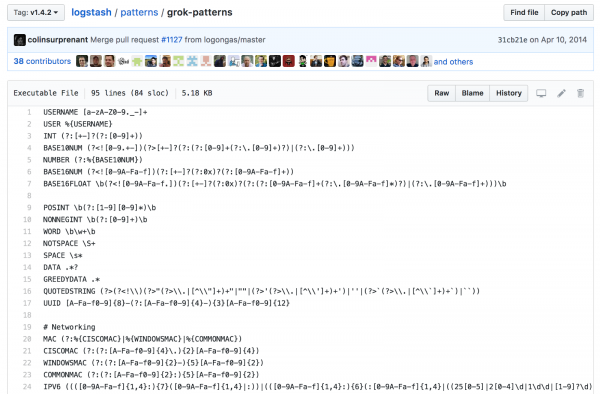
Кастомные шаблоны Grok
Нужно пробовать, чтобы построить свой собственный шаблон Grok. Я использовал Grok Debugger и Grok Patterns .
Обратите внимание, что синтаксис шаблонов Grok выглядит следующим образом: %
Первое, что я попытался сделать, это перейти на вкладку Discover в отладчике Grok. Я подумал, что было бы здорово, если бы этот инструмент мог автоматически генерировать шаблон Grok, но это было не слишком полезно, так как он нашел только два совпадения.
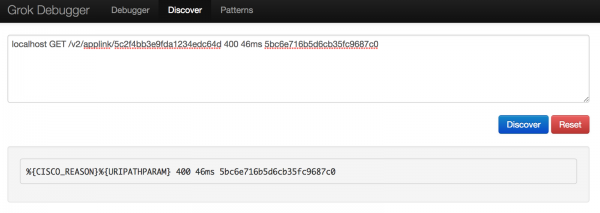
Используя это открытие, я начал создавать свой собственный шаблон на отладчике Grok, используя синтаксис, найденный на странице Github Elastic.
Поиграв с разными синтаксисами, я наконец-то смог структурировать данные журнала так, как мне хотелось.
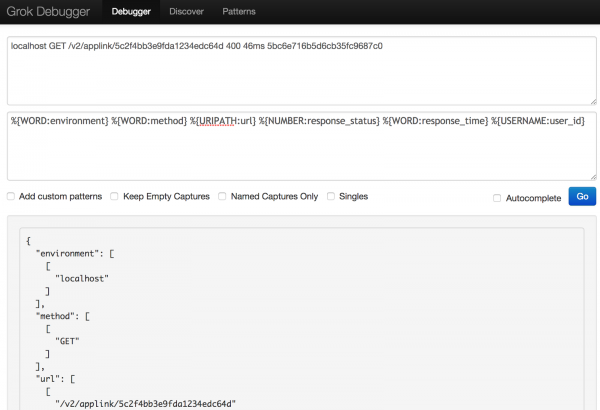
То что получилось в итоге
Имея в руках шаблон Grok и сопоставленные данные, последний шаг — добавить его в Logstash.
Обновление файла конфигурации Logstash.conf
На сервере, на котором вы установили стек ELK, перейдите к конфигурации Logstash:
После сохранения изменений перезапустите Logstash и проверьте его состояние, чтобы убедиться, что он все еще работает.
Наконец, чтобы убедиться, что изменения вступили в силу, обязательно обновите индекс Elasticsearch для Logstash в Kibana!
С Grok ваши данные из логов структурированы!
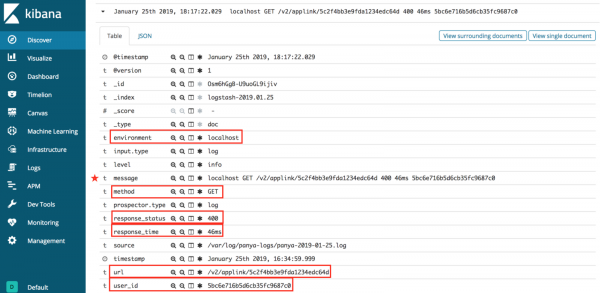
Как мы видим, на изображении выше, Grok способен автоматически сопоставлять данные журнала с Elasticsearch. Это облегчает управление журналами и быстрый запрос информации. Вместо того чтобы рыться в файлах журналов для отладки, вы можете просто отфильтровать то, что вы ищете, например среду или url-адрес.
Попробуйте дать Grok expressions шанс! Если у вас есть другой способ сделать это или у вас есть какие-либо проблемы с примерами выше, просто напишите комментарий ниже, чтобы сообщить мне об этом.
Спасибо за чтение — и, пожалуйста, следуйте за мной здесь, на Medium, для получения более интересных статей по программной инженерии!


Logstash

ElasticSearch
Пример документа в базе:
Вся работа с базой данных строится на JSON запросах с помощью REST API, которые либо выдают документы по индексу, либо некую статистику в формате: вопрос — ответ. Для того чтобы все ответы на запросы визуализировать была написана Kibana, которая представляет из себя веб сервис.
Kibana
Пример дашбоарда для Check Point, картинка кликабельна:

Пример дашбоарда по OpenVas, картинка кликабельна:

Заключение
Мы рассмотрели из чего состоит ELK stack, немного познакомились с основными продуктами, далее в курсе отдельно будем рассматривать написание конфигурационного файла Logstash, настройку дашбоардов на Kibana, познакомимся с API запросами, автоматизацией и много чего еще!
В нашем телеграм канале мы рассказываем о главных новостях из мира IT, актуальных угрозах и событиях, которые оказывают влияние на обороноспособность стран, бизнес глобальных корпораций и безопасность пользователей по всему миру. Узнай первым как выжить в цифровом кошмаре!
Читайте также: