
Как сделать словарь
Добавил пользователь Евгений Кузнецов Обновлено: 05.10.2024
Совсем не давно я обратил свое внимание на Python, захотелось попробовать свои силы в программирование и если все получиться поменять сферу деятельности, но это еще только планы. В общем, в программирование на Python я не новичок, но до гуру мне еще очень далеко, поэтому если Вы найдете ошибки в моих статьях сообщите. Если Вы так же решили изучить Питон, то должны научиться работать со словарями и списками. Сегодня поговорим о том как создать словарь из списков.
Я уже написал несколько статей касаемых программирования на Python, рекомендую Вам с ними обязательно ознакомиться.
Как собрать словарь из двух списков
И так допустим есть какие то списки, например.
names = [‘Аня’, ‘Коля’, ‘Лёша’, ‘Лена’, ‘Миша’]
cities = [‘Владивосток’, ‘Красноярск’, ‘Москва’, ‘Обнинск’, ‘Чебоксары’]
Для того чтобы собрать словарь нужно воспользоваться функциями len и range в цикле for.
friends = <>
for i in range (len(friends_names)):
friends[names[i]] = cities [i]
То получим словарь.
Давайте немного разберем то что мы сделали, с помощью range мы задали последовательность чисел, с аргументом len(names). Функция len(names) посчитала и вернула нам количество элементов в списке
Мы увидим количество элементов в списке.
Далее мы просто сопоставили элементы двух списков friends[names[i]] = cities [i].
Самое главное чтобы элементы в списках соответствовал друг другу и их было одинаковое количество.
Этичный хакинг и тестирование на проникновение, информационная безопасность
Оглавление
В этой статье собраны возможные ситуации генерации словарей, с которыми можно столкнуться на практике, но которые ещё не описаны в других статьях. Некоторые примеры взяты из вопросов в комментариях или на форуме, с некоторыми задачами я сталкивался сам.
Будут рассмотрены не только уже знакомые нам инструменты, но и парочка новых. Для некоторых задач мы будем использовать не только специализированные инструменты - некоторые действия проще сделать с помощью стандартных утилит Linux или собственных скриптов.
Поскольку здесь не будут описываться основы генерации словарей, то начнём с перечня источников, где вы можете прочитать эти самые основы. Рекомендуется прочитать их, если вы ещё не сделали этого.
Азы генерации словарей
Атака на основе правил
Атака на основе правил - изменяет уже существующий словарь по указанному набору правил. Если с помощью атаки на основе правил вы хотите изменить поведение маски, то вначале нужно создать словарь по маске, а затем работать с ним.
Самый простой способ - использовать программу с графическим интерфейсом Mentalist, инструкция: Генерация и модификация словарей по заданным правилам.

Атака на основе правил в John the Ripper намного мощнее чем в hashcat, для данной атаки из этих двух программ рекомендую выбирать именно John: Полное руководство по John the Ripper. Ч.5: атака на основе правил
Генерация словарей на основе информации о человеке
Если пароль составлен на основе данных пользователя, например, комбинация имени, фамилии, даты рождения, именах детей, номера телефона, этих же данных ближайших родственников, то такой пароль можно считать слабым. Рассмотренные выше инструменты не очень подходят для составления подобных словарей, основанных на информации о пользователе - разве что, комбинаторная атака в Hashcat, но она за раз принимает только 2 словаря.
Именно эту проблему решает утилита CUPP.
Установка CUPP в Kali Linux
Установка CUPP в BlackArch
Запустите программу в интерактивном режиме и введите известные данные пользователя:

Пример сгенерированных паролей:

Если вам нужен перевод задаваемых вопросов, то вы найдёте его на странице карточки программы.
Составление списков слов и списков имён пользователей на основе содержимого веб-сайта
Познакомимся с ещё одним инструментом - CeWL. Эта программа обходит указанный сайт (можно указать глубину обхода) и все найденные на страницах сайта слова сортирует в порядке частоты их использования. Зачем нужен такой словарь? Автор предлагает использовать его для брут-форса. К тому же, программа умеет искать e-mail адреса, а также извлекать имена создателей офисных документов - поддерживаются файлы Word и PDF. Эти данные можно использовать для составления списка имён пользователей.
Ещё в комплекте с программой идёт утилита FAB, которая извлекает из уже скаченных документов Word и PDF имена авторов - их тоже можно использовать в качестве имён пользователей для брут-форса.
Установка CeWL в Kali Linux
Программа предустановлена в Kali Linux.
В минимальных версиях программа устанавливается следующим образом:
Установка в BlackArch
В карточке программы описаны дополнительные нюансы установки - рекомендуется ознакомиться.
Примеры запуска CeWL

Запуск FAB, при котором будут проверены все документы *.doc в директории /home/mial/Downloads/, из метаинформации этих документов будет извлечено поле, содержащее имя автора документа, данные будут выведены на экран:

Как создать словарь по маске с переменной длиной
Рассмотрим генерацию списков слов различной длины на примере Hashcat и maskprocessor.
Удлиняющиеся пароли в Hashcat
Для того, чтобы генерировались пароли различной длины, имеются следующие опции:
Опция -i является необязательной. Если она используется, то это означает, что длина кандидатов в пароли не должна быть фиксированной, она должна увеличиваться по количеству символов.
Опция --increment-min также является необязательной. Она определяет минимальную длину кандидатов в пароли. Если используется опция -i, то значением --increment-min по умолчанию является 1.
И опция --increment-max является необязательной. Она определяет максимальную длину кандидатов в пароли. Если указана опция -i, но пропущена опция --increment-max, то её значением по умолчанию является длина маски.
Правила использования опций приращения маски:
- перед использованием --increment-min и --increment-max необходимо указать опцию -i
- значение опции --increment-min может быть меньшим или равным значению опции --increment-max, но не может превышать его
- длина маски может быть большей по числу символов или равной числу символов, установленной опцией --increment-max, НО длина маски не может быть меньше длины символов, установленной --increment-max.
Итак, команда запуска для генерации паролей, которые имеют длину от шести до десяти символов:
hashcat -a 3 -i --increment-min=6 --increment-max=10 --stdout ?l?l?l?l?l?l?l?l?l?l
Удлиняющиеся пароли в maskprocessor
В maskprocessor имеется следующая опция приращения:
Следующая команда составит словарь из чисел от 1 до 9999:
Когда о пароле ничего не известно (все символы)
Про нюансы я уже писал, здесь только примеры команд.
Если нужно запустить полный перебор, когда в пароле могут быть большие и маленькие латинские буквы, а также цифры и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
Создание словарей, в которых обязательно используется определённые символы или строки
В комментариях к статьям о генерации паролей по маскам иногда спрашивают, а как создать словарь, содержащий определённые символы или слова, причём они могут быть в любом месте. На самом деле, именно маски для этого подходят плохо. Задачу можно решить с помощью Атаки на основе правил, особенно если речь идёт об отдельных символах или группах символов - выше уже даны ссылки на решение подобных случаев. Но если речь идёт о строках, то Атака на основе правил становится или слишком сложной и запутанной из-за необходимости создавать большое количество правил, или даже просто невозможной.
Рассмотрим несколько примеров.

На мой взгляд, это оптимальное решение. Оно также подходит, если вы не хотите создавать словарь, а хотите использовать атаку по маске - многие программы для брут-форса способны принимать кандидаты в пароли из стандартного ввода.
Ещё один вариант - искомое слово может быть в любом регистре, но точно расположено в начале пароля:
Кстати, последний пример не особенно удачный - поскольку нам известно, что вначале возможны только 2 символа - „A“ или „a“, то лучше использовать пользовательский набор символов, включающих эти два символа. Аналогично и для других - хотя бы четырёх известных символов (по количеству возможных пользовательских наборов).
В ней вы можете добавлять цепочку из grep и отфильтровывать пароли с любым количеством необходимых символов.
Количество искомых строк может быть любым:
Думаю, идея понятно - вместо того, чтобы пытаться создать невозможную маску, создаём всё возможное и отфильтровываем то, что нам нужно.
Как создавать комбинированные словари
Суть в том, что к каждому слову из первого словаря, добавляется каждое слово из второго словаря.
Словарь 1 (dict1.txt)
Словарь 2 (dict2.txt)
Запуск комбинаторной атаки (-a 1):
Мне почему-то казалось, что слова должны объединятся ещё и в обратном порядке (то есть первым идёт слово из второго словаря), но как вы можете убедиться, это не происходит. Поэтому для получения описанного эффекта, нужно запустить атаку ещё раз, поменяв словари местами:
Как комбинировать более двух словарей
Далее показан пример комбинации трёх словарей - суть в том, что каждое новое полученное слово состоит по одному слову из каждого из трёх словарей:
Как комбинировать подобным образом 4 и более словарей? Мне трудно представить, что это может пригодиться в реальной ситуации, но для этого скорее всего придётся писать свой скрипт для автоматизации показанного выше алгоритма. Если вы знаете программы, которые умеют это делать, то пишите в комментариях.
И… в этом месте я вспомнил о программе combinator3. Она поставляется в пакете hashcat-utils. Эта команда служит для комбинации трёх словарей (для комбинации двух словарей используйте combinator).
Эта программа умеет комбинировать по 3 указанных словаря, но опять же - если словарь идёт третьим, то слова из него всегда будут в конце.
Чтобы получить все возможные комбинации из трёх слов в любом порядке, то нужно использовать следующие команды:
Как создать все возможные комбинации для короткого списка строк
Утилита combipow создаёт все “уникальные комбинации” из короткого списка ввода. Эта программа также включена в hashcat-utils.
Пример содержимого словаря с именем wordlist:
Запуск combipow с этим словарём:
Даст следующие результаты:
Комбинирование по алгоритму PRINCE
Программа princeprocessor реализует алгоритм PRINCE. Подробнее об этом алгоритме вы можете узнать на странице карточки программы. Там же описана суть работы программы и её опции.
Примеры использования princeprocessor.
Чтобы создать все возможные цепи из содержимого файла dict1.txt:

Используя слова из указанного словаря (dict1.txt) составить цепи минимальной длиной 2 элемента (--elem-cnt-min=2) и максимальной длиной 2 элемента (--elem-cnt-max=2), то есть в каждой цепи будет только по 2 слова:

Гибридная атака - объединение комбинаторной атаки и атаки по маске
Эта атака совмещает атаку по словарю и атаку по маске - она принимает на входе словарь и маску и выдаёт гибридный пароль.
Если ваш example.dict содержит:
генерируют следующие кандидаты в пароли:
Это работает и в противоположную сторону!
генерируют следующие кандидаты в пароли:
Все возможности гибридной атаки можно реализовать с помощью Атаки на основе правил - поэтому если она вам нравится больше, то используйте её.
Как создать комбинированный словарь, содержащий имя пользователя и пароль, разделённые символом
Теперь возвращаемся к комбинированным словарям, содержащим одновременно имя пользователя и пароль.
В качестве примера посмотрите на фрагмент словаря (файл auth_basic.txt) программы Router Scan by Stas'M - в нём учётные данные разделены символом табуляции:
А это пример комбинированного словаря, в котором имя пользователя и пароль разделены двоеточием:
Чтобы создать комбинированный словарь, используйте команду вида:
- users.txt и passwords.txt - словари, из которых будут взяты имена пользователей и пароли и будут составлены все возможные комбинации.
- РАЗДЕЛИТЕЛЬ - символ, которым будут разделены логин и пароль
Например, в следующей команде разделителем является двоеточие:

Кстати, если в качестве разделителя нужно вставить символ табуляции, то нажмите Ctrl-v + Tab:

Кстати, если вы попытаетесь разобраться в приведённой выше команде hashcat, то выясните, что одновременно используется Комбинаторная атака и добавлено правило из Атаки на основе правил.
Рассмотрим частный случай: как создать файл парный словарь логинов и паролем такого типа: логин всегда постоянный, затем табуляция и пароль.
Конечно, в качестве первого словаря можно создать файл с одним текстовым полем - логином. Но есть и другой вариант с помощью мощнейшей команды sed:
- superadmin — строка, которую нужно вставить перед каждым паролем
- \t — символ табуляции, который будет разделять логин и пароль
- pass.txt — файл, откуда считывать пароли
- login_pass.txt — новый файл, куда будут сохранены пароли
Если не хотите создавать новый файл, а хотите изменить имеющийся, то уберите перенаправление и добавьте опцию -i:
Как извлечь имена пользователей и пароли из комбинированного словаря в обычные словари
Если из комбинированного словаря нам нужно извлечь только имена пользователей и/или только пароли. Для этого мы воспользуемся (тоже мощнейшей) программой awk.
Смотрите также: Уроки по Awk
Для извлечения имён пользователей:
Для извлечения паролей:
В этих командах:
В принципе, команды только различаются в $1 (первое поле до разделителя) и $2 (второе поле после разделителя).
Как при помощи Hashcat можно сгенерировать словарь хешей MD5 всех шестизначных чисел от 000000 до 999999
Hashcat может делать радужные таблицы, но только для Wi-Fi.
Зато с помощью PHP эту задачу можно решить несколько строк:
Время выполнение — 1-4 секунды. За это время будут сгенерированы все md5 хеши для строк 000000…999999.
Сохраните приведённый выше код в файл md5-rb-gen.php, запускать так:
Чтобы сохранить полученные хеши в файл:
Интересное наблюдение о скорости достижения задачи.
Следующие две команды делают ровно то же самое:
Но на среднем компьютере выполнение команд займёт до часа. PHP оказался быстрее, чем нативные Linux команды…
Удвоение слов
Как создать словарь 12 символьных слов, состоящих только из десятичных цифр (?d) формата abcdefabcdef, т.е шестизначное число написано два раза?
Можно использовать Атаку на основе правил, а можно написать небольшой скрипт Bash (все слова в из файла user.txt пишутся по 2 раза):
Применительно к нашему заданию — удвоение шестизначных чисел, можно использовать следующую команду, которая сгенерирует числа из шести цифр и дважды запишет каждое число:
Как создать словарь со списком дат
Как создать список дат по шаблону ДД-ММ-ГГГГ, то есть соответствущий маске ?d?d-?d?d-?d?d?d?d но чтобы перебор был не в диапазоне 00-99, а 01-31, 01-12 и 1900-2021 соответственно?
Такие словари умеет создавать программа pydictor.
Но ещё проще словарь сделать следующим образом (он будет сохранён в файл dates.txt):
Если хотите обойтись без создания словаря, то передавайте вывод предыдущие команды на стандартный ввод hashcat:
Как разбить генерируемые словари на части
Можно ли как-то в maskprocessor разделить выходящий генерируемый словарь на несколько частей? Например, частями по 1Гб.
Да, вы можете разделить вывод maskprocessor, а также готовые словари на части. В Linux для этого удобно воспользоваться утилитой split, например:
Заключение
Если я что-то пропустил или есть утилиты, которые делают показанные вещи проще или делают возможным то, о чём я написал что это невозможно, то пишите в комментариях - будет интересно узнать об этом и дополнить статью.
Также можете задавать ваши вопросы, связанные с генерацией словарей, учитывающих определённые условия.
Связанные статьи:
факультете информационной безопасности от GeekBrains? Комплексная годовая программа практического обучения с охватом всех основных тем, а также с дополнительными курсами в подарок. По итогам обучения выдаётся свидетельство установленного образца и сертификат. По этой ссылке специальная скидка на любые факультеты и курсы!
Я несколько раз создавала Словари Терминов в компаниях. Самый масштабный из них — Словарь Терминов Олимпийских Игр, мы разработали его в Оргкомитете Сочи 2014. Это компания-организатор Олимпийских и Паралимпийских Игр в Сочи в 2014 году. В Оргкомитете я руководила департаментом управления знаниями. Эту инструкцию буду иллюстрировать скриншотами того самого проекта.
Зачем и когда нужен?
Если суммировать уже сказанное выше, Словарь Терминов вам поможет в случае:
С чего начать?
Начинайте с определения цели и понимания результатов. Например, для этого можно использовать чек-лист из утверждений выше. Возможно, вы дополните его и своими причинами. Оцените каждую по пятибалльной шкале. Попросите коллег также заполнить этот чек-лист. Обсудите и проанализируйте результаты: какие утверждения набрали максимальные веса? Это и есть цель создания вашего словарика.
Внимание!
Не приступайте к созданию Словаря, пока не определили цели (и задачи). Они, в свою очередь, должны быть понятны и приняты конечными потребителями.
Теперь поговорим о результате. Оценить и измерить качество Словаря очень важно. Иначе — как вы поймёте, что он сделан наилучшим образом и действительно полезен? Результат можно измерить тремя способами. Самый простой — по его посещаемости. Например, по количеству посетителей в период времени, продолжительности использования одним посетителем, идей и предложений, словом — по вовлечённости его пользователей.
Начинайте с определения цели и понимания результатов
И третий — оцените результативность и влияние словаря на те бизнес-процессы или проекты, которые вы определили в своих целях. То есть оцените целевые результаты. Изменилась ли ситуация к лучшему? Спросите об этом пользователей и всех заинтересованных. Подробнее про измерения и оценки Словаря читайте дальше.
Для полноты картины используйте все три способа.
Внимание!
Планируйте оценку, анализ результатов и нужные метрики заранее, на самом начальном этапе.
10 простых шагов для создания отличного словаря
Перед нами дорожная карта создания Словаря, который будет очень полезен вашей компании. Следуйте по карте, и вы создадите удобный и ценный Словарь Терминов.

Рисунок 1. Маршрутная карта создания Словаря Терминов
Именно так мы и действовали в Оргкомитете. Прежде всего, мы описали алгоритм создания Словаря (примерно такой, как на Рисунке 1) и представили его вице-президентам и директорам, чтобы получить их поддержку. Теперь, когда мы вовлекли заинтересованные стороны, можно было приступать к сбору терминов.
Шаг 2. Собираем команду
Оцените результативность и влияние словаря на те бизнес-процессы или проекты, которые вы определили в своих целях
Поскольку о цели мы уже поговорили, переходим ко второму шагу. Очень частая ошибка — не привлекать будущих пользователей к созданию продукта. Обязательно советуйтесь с ними и по возможности максимально вовлеките их в процесс. Например, вы можете еженедельно проводить короткие встречи, покажите, что уже сделано, спросите совета и рекомендаций.
Но, даже если у вас нет возможности активно вовлечь бизнес-направления в создание Словаря, обязательно информируйте их о ваших намерениях и целях. Хорошо бы провести для этого kick-off проекта с участием будущих пользователей.
В Оргкомитете к тому времени уже сложилась группа сотрудников из всех бизнес-направлений, неравнодушное активное меньшинство, агенты изменений. Так началось формирование профессионального сообщества Координаторов Знаний. Сбор терминов и понятий своего бизнес-направления и создание Словаря Терминов стали одними из первых задач будущих Координаторов.
Внимание!
Вовлекайте будущих пользователей Словаря в его создание. Тогда вы избежите риска ошибок и неприятия ими конечного продукта.
Шаг 3. Собираем термины
Приступаем к созданию словаря. Для начала создадим простой шаблон для сбора и описания понятий. Это упростит задачу бизнес-направлениям и значительно сократит ваше время по обработке терминов.
Например, используйте вот такой. На этом скриншоте четыре термина бизнес-направления управление знаниями. Словарь Терминов в Оргкомитете был двуязычным.

Рисунок 2. Шаблон для Словаря Терминов, пример бизнес-направления управление знаниями
Внимание!
Обязательно создайте простой шаблон, чтобы бизнес-направления его заполнили. Это упростит задачу для всех участников, в том числе и для вас.
Даже если у вас нет возможности активно вовлечь бизнес-направления в создание Словаря, обязательно информируйте их о ваших намерениях и целях
Внимание!
Подумайте о мотивации ваших соучастников, как их поощрить и наградить. Возможно, спросите самих соучастников — что для них важно?
Если такого сообщества помощников у вас пока не сложилось, вероятнее всего, придется договариваться с руководителями бизнес-направлений. Они предложат кого-то из сотрудников.
Внимание!
Максимально сократите время, необходимое бизнес-направлениям для заполнения шаблона. Хорошо бы сразу привести примеры описаний.
Шаг 4. Анализируем термины и понятия
Тем или иным способом вы получили заполненные шаблоны с терминами. Проанализируйте их — есть ли повторения? Одинаковые толкования разных терминов? Одни и те же термины, но с разным толкованием? Именно все они и есть предмет следующего и очень важного этапа работы — согласования и поиска формулировок, принятых разными бизнес-направлениями. Выпишите все спорные термины. Назначьте время для обсуждения.
В Оргкомитете Сочи 2014 первоначально мы собрали 940 терминов и понятий. В конечную версию Словаря 700 из них. Около 200 понятий после анализа были объединены или исключены.
Внимание!
Проанализируйте список, выделите спорные термины, пригласите авторов на встречу.
Проведите короткую встречу, расскажите о сути проекта, объясните задачи, поставьте сроки
Шаг 5. Уточняем формулировки
Описания терминов должны быть максимально понятны и просты. Термины нужны для облегчения взаимодействий, а не для сложностей взаимопонимания. Поэтому спорные термины важно обсудить со всеми заинтересованными сторонами. И здесь вам потребуется мастерство модерации и немного фасилитации, чтобы создать условия для результативного обсуждения.
Со спорными терминами можно поступить двумя способами. Если это возможно — переформулировать термин, чтобы учесть все его характеристики и толкования. Это получится, когда речь идёт об одном и том же понятии, но его рассматривают с разных сторон. В этом процессе важно участие руководителей бизнес-направлений.
Иногда один и тот же термин означает разные понятия или процессы. Если не удаётся договориться, можно включить в Словарь два термина с аббревиатурами бизнес-направлений.
Внимание!
Обязательно обсудите и переформулируйте спорные термины с участием заинтересованных сторон.
Шаг 6. Пишем ТЗ
Сами термины и понятия можно расположить в алфавитном порядке, а можно разбить по бизнес-направлениям. В Оргкомитете Сочи 2014 мы применили второй способ.
Содержание вашего ТЗ может быть примерно таким.

Рисунок 3. Содержание ТЗ Словаря Терминов
Внимание!
Подумайте, как максимально упростить использование Словаря и сделать его доступным для всех, кому он важен. Учтите это при написании ТЗ.
Шаг 7. Определяем правила обновления
Словарь, как и язык, изменяется. Возникают новые понятия, некоторые термины не используются, а часть может со временем приобрести другой смысл. Чтобы Словарь оставался живым, его нужно актуализировать. Можно делать это регулярно, раз в полгода, или же по необходимости.
В Оргкомитете мы составили документ с описанием правил дополнения и обновления Словаря. И даже нарисовали схему бизнес-процесса его актуализации (Рисунок 4).

Рисунок 4. Описание бизнес-процесса обновления Словаря Терминов
Я очень рекомендую визуализировать бизнес-процессы. Это не займёт много времени, а результат очень наглядный, он понятен и хорошо воспринимается. Как пример — схема из Оргкомитета. Хотя, это и не лучший вариант. Самая главная цель описания процесса — понимание, простота и чёткость обновления. Поэтому и схема должна быть наглядной, простой, красивой.
В Оргкомитете за актуализацию Словаря отвечали Координаторы Знаний.
А вот так могут выглядеть поля для обновления Словаря:

Рисунок 5. Обновление Словаря Терминов
Внимание!
Обязательно определите правила, опишите процесс и назначьте ответственных за обновление.
Шаг 8. Разрабатываем и публикуем словарь в общедоступном пространстве
Этот шаг — как подведение итогов всех предыдущих действий. Вы собрали, проанализировали, обсудили термины и понятия компании. Описали порядок их обновления. Написали ТЗ и передали его в работу. И теперь нужно разместить Словарь на сетевом ресурсе, например, в Интранет. Для него не нужно специальных технологий, используйте те, что уже есть.
Затем вы регулярно смотрите версии Словаря, чтобы тестировать их и постепенно привести к вашей задумке. Например, как на Рисунке 6.
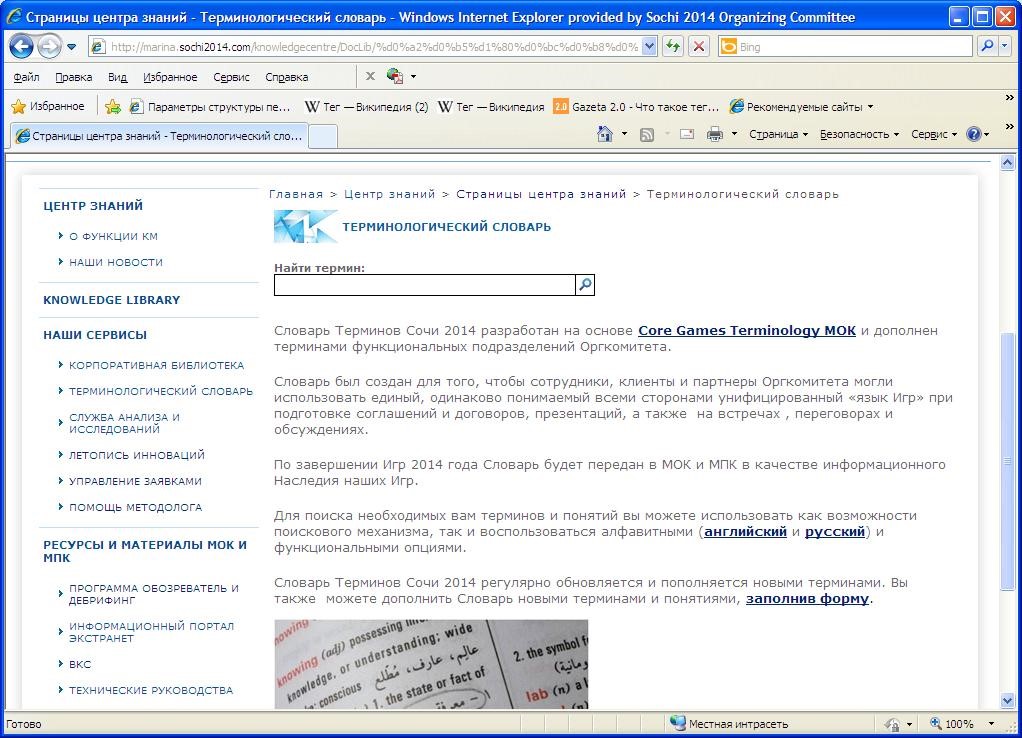
Рисунок 6. Словарь Терминов на Интранет портале
Спорные термины важно обсудить со всеми заинтересованными сторонами
Шаг 9. Информируем всех-всех-всех
Если вы думаете, что слава о Словаре разлетится по компании с помощью сарафанного радио, то я вас разочарую. Впоследствии так оно и будет, но не на первых порах. Только малый процент людей готов самостоятельно искать и применять новые инструменты, даже если они очень нужны. Чаще всего их не больше 10–12%.
Отнеситесь к этой задаче как к продвижению изменений.
Шаг 10. Анализируем и оцениваем результаты
Итак, мы создали Словарь Терминов, и теперь важно протестировать и оценить его результативность. Тогда будет понятно — нужен ли этот инструмент (вдруг мы переоценили его важность?), а также насколько хорошо мы его сделали. Можно попросить добровольцев, необязательно из числа вашей группы поддержки, тестировать Словарь и найти как можно больше возможностей для его улучшения. Для этого хорошо организовать конкурсы или викторины.
Только малый процент людей готов самостоятельно искать и применять новые инструменты, даже если они очень нужны
В Оргкомитете мы не проводили специальных тестов, а сразу запустили Словарь для общего использования. Это было из-за 100% уверенности в его нужности и срочности задачи. Словарь очень ждали все бизнес-направления. Не случайно он стал первым инструментом Интранет-портала. Результативность Словаря мы измеряли двумя способами. Во-первых, наблюдали за вовлечённостью посетителей. Мы заметили, что первые две-три недели на страницу Словаря Терминов заходили примерно 25% сотрудников. В основном, это были те, кто принимал участие в его создании. Стало понятно, что Словарь недостаточно хорошо известен. Тогда мы провели еще две–три акции — короткую презентацию Словаря для всех желающих (участвовали примерно 35% сотрудников), а также рассказали о нем на общем собрании. Посещаемость повысилась до 45%. Постепенно, с приходом новичков она росла и достигла 60%.
И тогда мы попросили этих посетителей ответить на три простых вопроса. с оценкой по шкале 5 баллов. Часто ли они используют Словарь? Удобно ли его использовать? Помогает ли Словарь Терминов в их работе? Мы также попросили рассказать короткие кейсы, когда Словарь сделал их работу более успешной. 90% участников опроса (а это были 60% сотрудников Оргкомитета) оценили Словарь на 8–9 баллов из 10, 15 человек прислали свои идеи и предложения. Мы также получили 5 историй, когда Словарь помог выполнить работу лучше.
Подводим итоги
В момент создания Словаря Терминов в Оргкомитете он включал 940 терминов и понятий. В конечную версию вошли 700 из них, из которых почти 400 были общими, широко распространенными терминами, обязательными для всех бизнес-направлений. Около 200 терминов мы объединили с другими или переформулировали. Координаторы Знаний в бизнес-направлениях регулярно дополняли Словарь, и он помогал коммуницировать, взаимодействовать, выполнять многофункциональные проекты вплоть до февраля 2014 — до самых Игр.

— Инструкции и документы
Раз вы начали читать эту инструкцию, ничего теперь уже не изменить. Вы уже встали на путь освоения русского языка, а это значит, что ваша грамотность будет медленно, но верно повышаться.
Первый шаг вы уже сделали. Вторым шагом будет создание собственного словаря. Для него подойдёт любая тетрадка 18 - 20 листов или небольшой блокнотик. Выглядеть он со временем будет примерно так:

3. Если ошибка допущена в третий, четвертый, пятый и более раз, слово подчеркивается другими цветами, обводится в овал. С таким словом начинается особая работа: его пишут крупно и вывешивают на стену, преподаватель включает его в словарные диктанты.
Сначала вы будете записывать в словарь очень много слов. Возможно, в какой-то момент вам покажется, что им нет конца и выучить их все невозможно. Не поддавайтесь панике! Это такой этап словарной работы. У всех бывает и легко проходит. Через несколько месяцев регулярных занятий вы заметите, что записываете в словарь все меньше и меньше, и главное - что вы уже запомнили из своего словарика почти все старые слова.

3. Вы не знаете, как правильно пишутся лишь некоторые слова (у кого-то их несколько десятков, а у кого-то - несколько сотен, но крайне редко человек не знает правописание тысячи слов родного языка).
4. Ваша задача вычислить, какие слова конкретно вы пишете неверно, и выучить их. Чем больше вы делаете ошибок в начале обучения, тем лучше, потому что вы быстро составите список своих словарных слов.
Читайте также: