
Как сделать схему базу данных
Обновлено: 05.07.2024
Сегодняшний материал, как я уже сказал, ориентирован на начинающих программистов, которые хотят научиться работать с Microsoft SQL Server. Поэтому я и буду исходить из того, что Вам нужно создать базу данных для обучения, т.е. основной посыл этой статьи направлен на то, чтобы тот, кто хочет создать базу данных в Microsoft SQL Server, после прочтения статьи четко знал, что ему для этого нужно сделать.
Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
В данном разделе я представлю своего рода этапы создания базы данных в Microsoft SQL Server, т.е. это как раз то, что Вы должны знать и что у Вас должно быть, для того чтобы создать базу данных:
- У Вас должна быть установлена СУБД Microsoft SQL Server. Для обучения идеально подходит бесплатная редакция Microsoft SQL Server Express. Если Вы еще не установили SQL сервер, то вот подробная видео-инструкция, там я показываю, как установить Microsoft SQL Server 2017 в редакции Express;
- У Вас должна быть установлена среда SQL Server Management Studio (SSMS). SSMS – это основной инструмент, с помощью которого осуществляется разработка баз данных в Microsoft SQL Server. Эта среда бесплатная, если ее у Вас нет, то в вышеупомянутой видео-инструкции я также показываю и установку этой среды;
- Спроектировать базу данных. Перед тем как переходить к созданию базы данных, Вы должны ее спроектировать, т.е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
- Создать пустую базу данных. В среде SQL Server Management Studio создать базу данных можно двумя способами: первый — с помощью графического интерфейса, второй — с помощью языка T-SQL;
- Создать таблицы в базе данных. К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
- Наполнить БД данными. В базе данных уже есть таблицы, но они пусты, поэтому сейчас уже можно переходить к добавлению данных в таблицы;
- Создать другие объекты базы данных. У Вас уже есть и база данных, и таблицы, и данные, поэтому можно разрабатывать другие объекты БД, такие как: представления, функции, процедуры, триггеры, с помощью которых реализуется бизнес-правила и логика приложения.
Вот это общий план создания базы данных, который Вы должны знать, перед тем как начинать свое знакомство с Microsoft SQL Server и языком T-SQL.
В этой статье мы рассмотрим этап 4, это создание пустой базы данных, будут рассмотрены оба способа создания базы данных: и с помощью графического интерфейса, и с помощью языка T-SQL. Первые три этапа Вы должны уже сделать, т.е. у Вас уже есть установленный SQL Server и среда Management Studio, и примерная структура базы данных, которую Вы хотите реализовать, как я уже сказал, на этапе обучения этот пункт можно пропустить, а в следующих материалах я покажу, как создавать таблицы в Microsoft SQL Server пусть с простой, но с более-менее реальной структурой.
Создание базы данных в SQL Server Management Studio
Первое, что Вам нужно сделать, это запустить среду SQL Server Management Studio и подключиться к SQL серверу.
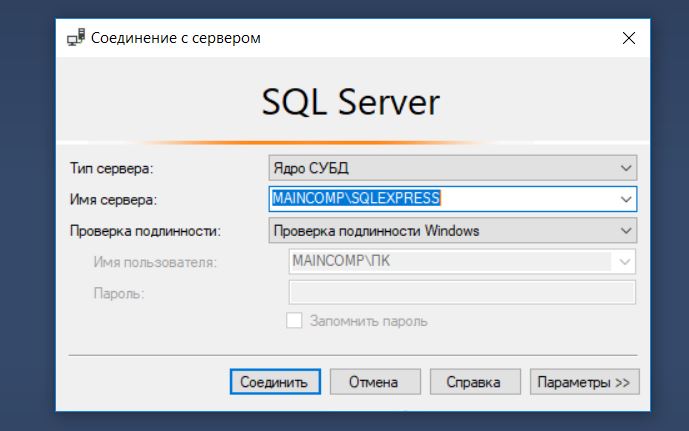
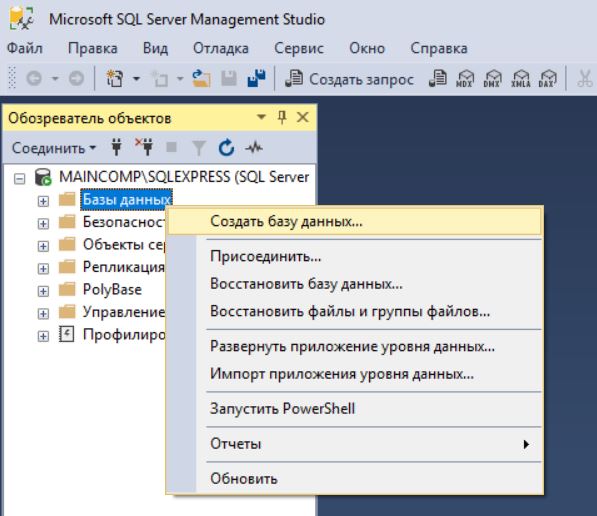
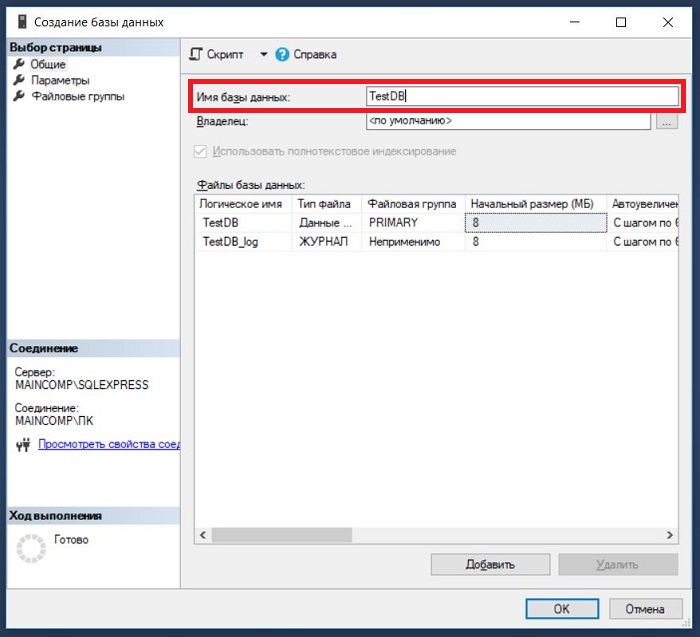
Если БД с таким именем на сервере еще нет, то она будет создана, в обозревателе объектов она сразу отобразится.
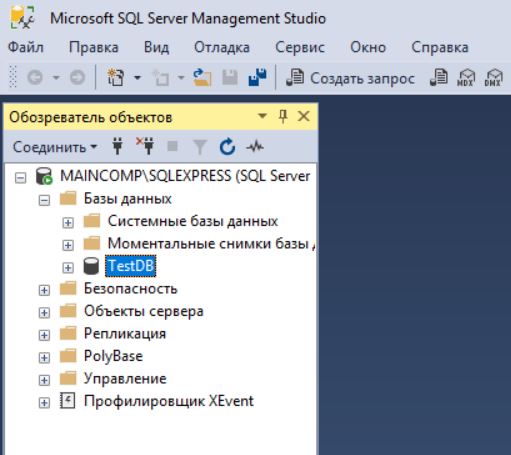
Как видите, база данных создана, и в этом нет ничего сложного.
Создание базы данных на T-SQL (CREATE DATABASE)
Процесс создания базы данных на языке T-SQL, наверное, еще проще, так как для того чтобы создать БД с настройками по умолчанию (как мы это сделали чуть выше), необходимо написать всего три слова в редакторе SQL запросов – инструкцию CREATE DATABASE и название БД.
Где CREATE – это команда языка T-SQL для создания объектов на SQL сервере, командой DATABASE мы указываем, что хотим создать базу данных, а TestDB — это имя новой базы данных.
С помощью инструкции CREATE DATABASE можно задать абсолютно все параметры, которые отображались у нас в графическом интерфейсе SSMS. Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.

Удаление базы данных в Microsoft SQL Server
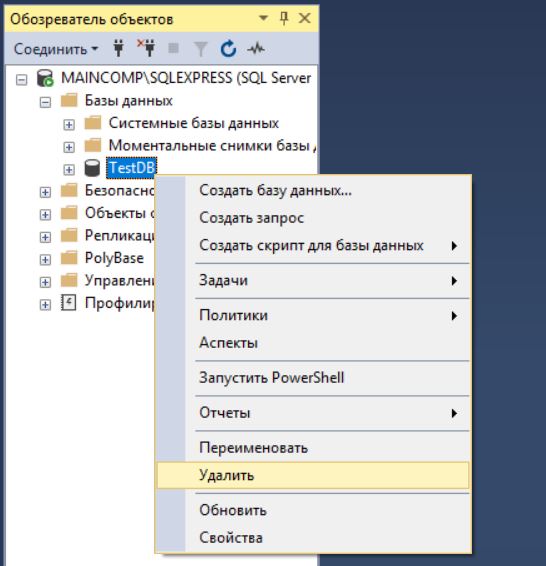
В случае необходимости можно удалить базу данных. В реальности, конечно же, такое редко будет требоваться, но в процессе обучения, может быть, и часто. Это можно сделать также, как с помощью графического интерфейса, так и с помощью языка T-SQL.
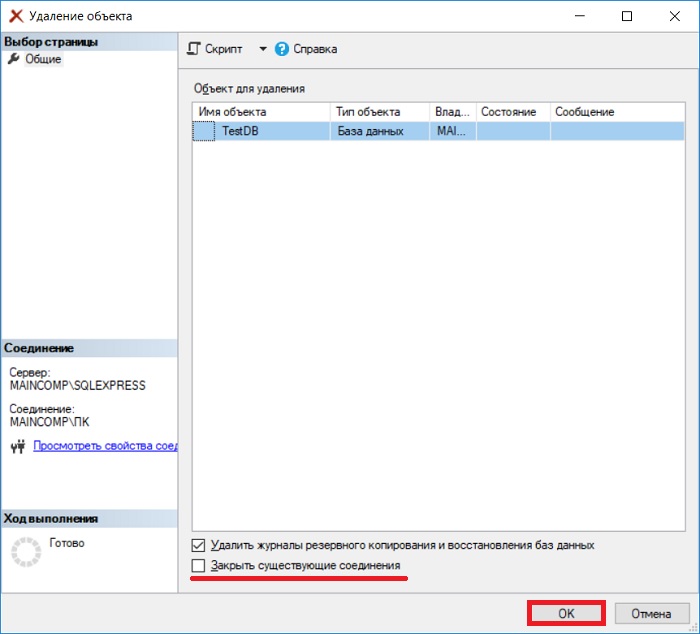
Примечание! Удалить базу данных возможно, только если к ней нет никаких подключений, т.е. в ней никто не работает, даже Ваш собственный контекст подключения в SSMS должен быть настроен на другую БД (например, с помощью команды USE). Поэтому предварительно перед удалением необходимо попросить всех завершить сеансы работы с БД, или в случае с тестовыми базами данных принудительно закрыть все соединения.
В случае с T-SQL, для удаления базы данных достаточно написать следующую инструкцию (в БД также никто не должен работать).
Где DROP DATABASE — это инструкция для удаления базы данных, TestDB – имя базы данных. Иными словами, командой DROP объекты на SQL сервере удаляются.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Видео-урок по созданию базы данных в Microsoft SQL Server
На этом наш сегодняшний урок закончен, надеюсь, материал был Вам интересен и полезен, в следующем материале я расскажу про то, как создавать таблицы в Microsoft SQL Server, удачи Вам, пока!
Внимание, поскольку WorkBench обновился, то я написал новую статью, которая состоит из теории и практики построения БД из WorkBench.
Итак, в прошлом посте, мы создали физическую базу данных и первую таблицу в базе данных, при помощи программы MySQL Workbench (в дословном переводе “Рабочая скамья” )))).
В этом посте мы узнаем, что такое модели в программе WorkBench и как с их помощью создавать взаимосвязанные таблицы (с внешними ключами), а заодно – усовершенствуем нашу базу данных для последующих экспериментов. Предыдущим методом мы могли из Workbench создавать только базу данных и какие-то отдельные таблицы.
Итак, в программе MySQL WorkBench жмем File New Model (Ctrl + N) и перед нами открывается такая картина…
Итак, все, что мы создадим сейчас будет называться моделью, программа поможет нам сформировать скрипт, который и создаст реальную базу данных.
1 Создание базы данных (схемы) в модели
Итак, начнем, с редакции имени базы данных. Терминологическое отступление. Вообще база данных ещё называется “Schema”, это синонимы, насколько я помню из книги Д. Осипова, “Базы данных и Delphi”, это произошло не сразу, а после очередного собрания “стандартизаторов” баз данных. Чтобы отредактировать название “Схемы”, нужно проделать следующее…
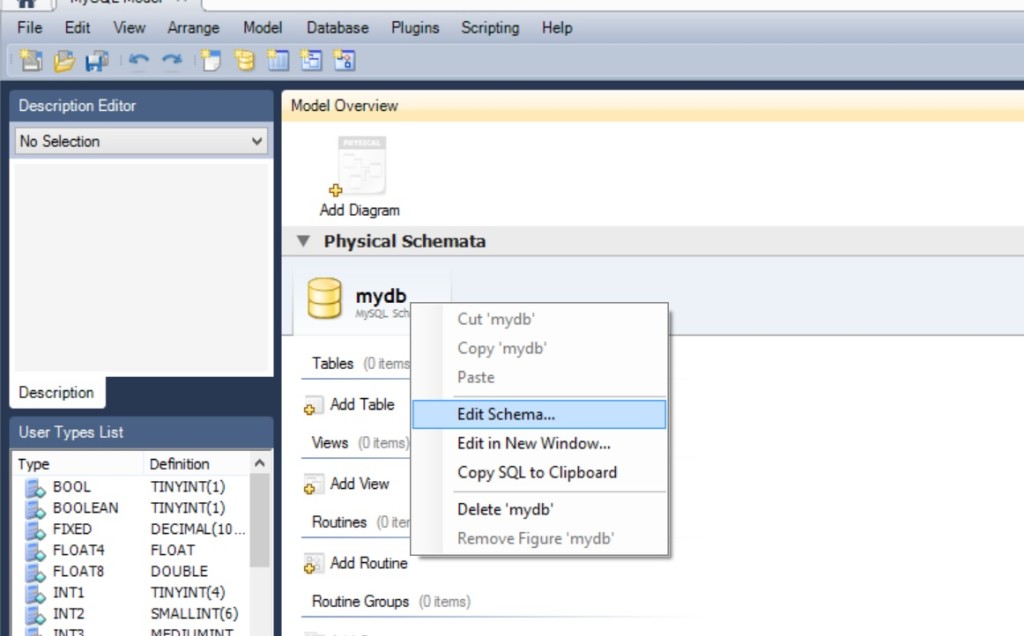
Перед нами открывается такое окно…
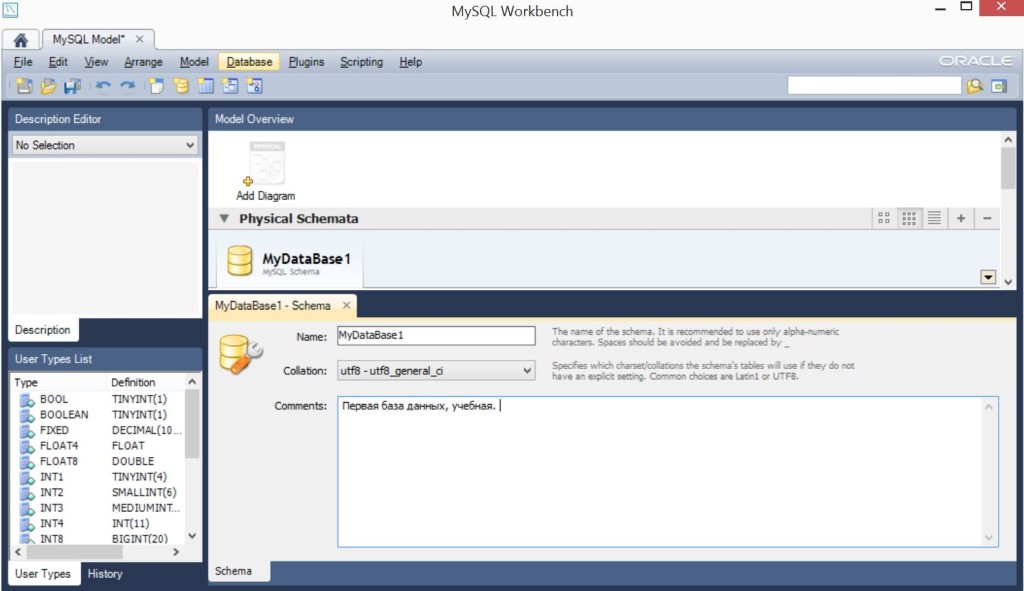
Я назвал базу данных, схему – MyDataBase1, кодировку не менял, в комментарии указал – “Первая база данных, учебная”;
После этого – жмём на крестик, на вкладке возле названия “MyDataBase1” и возвращаемся к предыдущему окну.
2 Создание таблиц в базе данных (схеме)
Итак, для того, чтобы создать таблицы – нам нужно определиться какую ситуацию будет отражать база данных. Я предлагаю сделать всё на примере студентов – все учились, всем будет понятно.
Каждый студент учится на каком-то одном факультете, поэтому, для начала предлагаю создать таблицу “Students” и таблицу “Departments”…
2 раза кликаем на AddTable и видим такую картину… Заполняем поле Table Name…
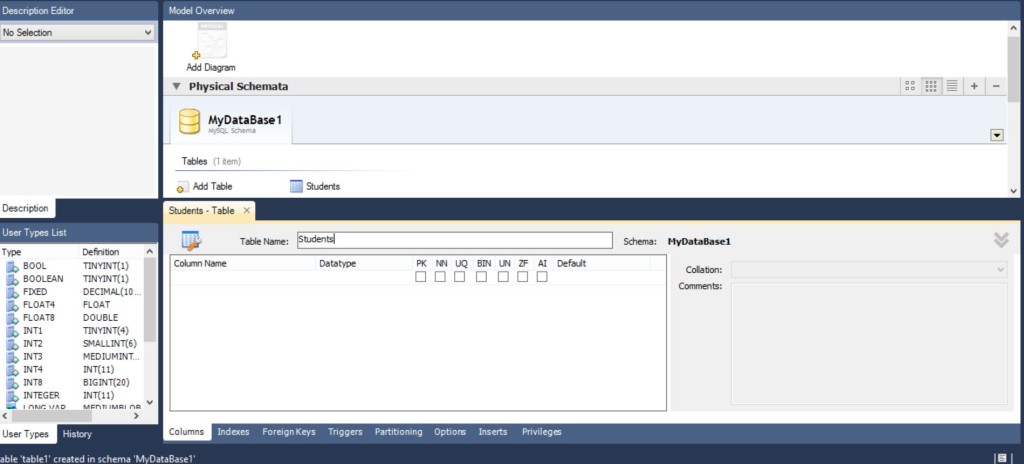
Заполняем имя таблицы. Обратите внимание на вкладки внизу, сейчас мы находимся на “Coloumns”. Для таблицы студентов разработаем несколько полей…
-Primary_key (уникальный ключ записей данной таблицы)
-Department_id (Внешний ключ, каждый студент учится на каком-то факультете, соответственно будем отмечать это в данном поле);
И сразу же введём их, на вкладке Students -Table – Coloumns, результат получился такой…
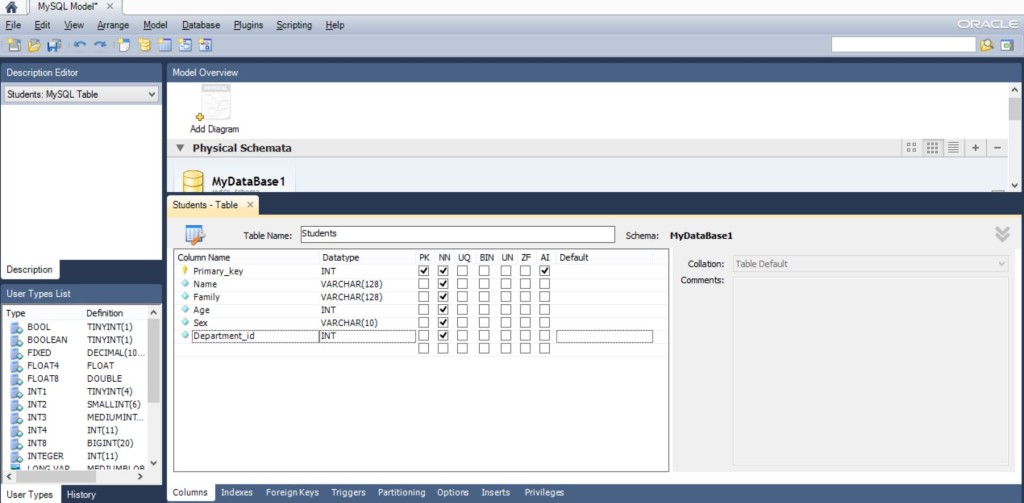
Итак, “PK” – поставил только у главного ключа, это поле является частью формирования уникального ключа таблицы (насколько я понял, в формировании такого ключа может участвовать несколько полей, но это в дальнейших исследованиях).
NN – Not Nulled – отсутствие нулевых полей, так как у всех студентов есть Имя, Фамилия, Возраст, Пол…
AI – автоинкрементное поле – с добавлением новой записи значение в этом поле будет увеличиваться как минимум на единицу.
Аналогично создадим и настроим таблицу Departments. В ней я создал 2 поля Primary_key и Department_name, в терминологии баз данных, получилось так..
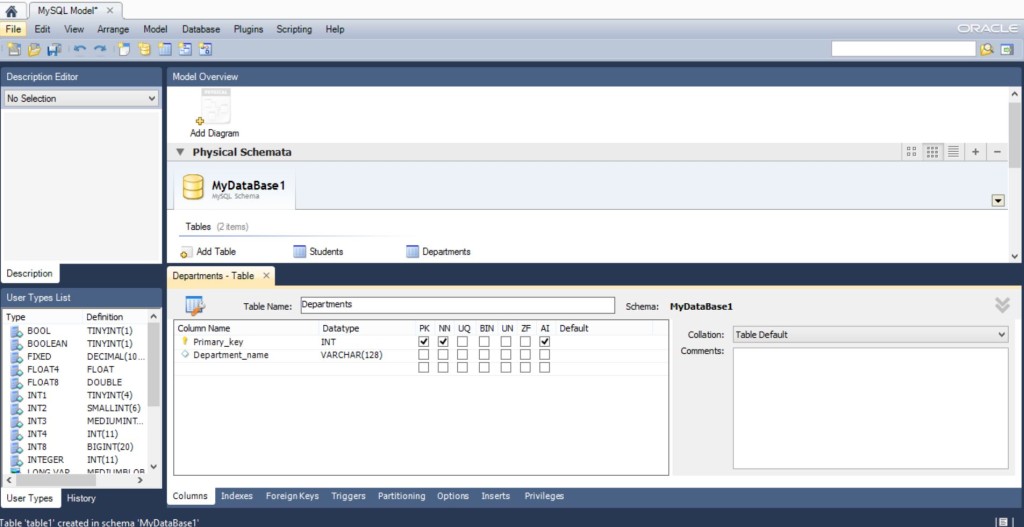
Здесь сделаю небольшое пояснение, Deparment_id в таблице students и Primary_key, в таблице departments это практически одно и тоже, разница лишь в том, что значения внешнего ключа Deparment_id разбросаны по таблице, а Primary_key автоинкрементен в своей таблице.
3 Стартовое заполнение созданных таблиц
Для того, чтобы нам с Вами делать какие-то дальнейшие эксперименты с IDE Delphi, языком SQL и др. вещами – нужно сделать стартовое заполнение, то есть, внести хоть какие-то записи. Для этого, на каждой из таблиц переходим во вкладку Inserts. Она внизу….
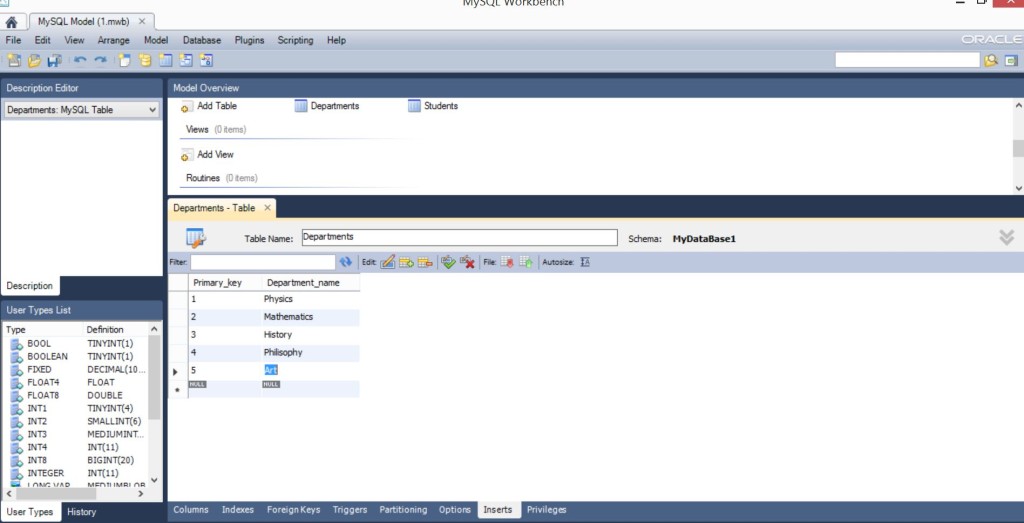
Для таблицы Departments – я сделал 5 факультетов – Physics, Mathematics, History, Philosophy, Art.
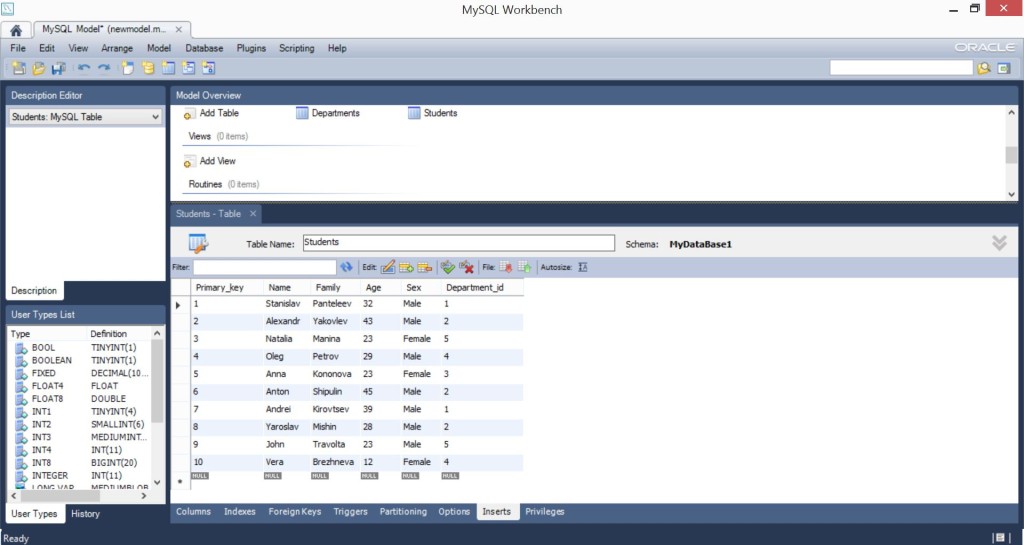
Для таблицы Students 10 произвольных записей. Если будете повторять пример – можете написать, что угодно, главное, соблюдать тип данных и в автоинкрементных полях писать по порядку.
После ввода записей, не забывайте нажать “Apply Updates”
Создание связи между таблицами
Для создания связи между таблицами, сначала разберемся в типе связи. В нашей ситуации на одном факультете может учиться несколько студентов, значит связь – один ко многим. Открываем вкладку Foreign Keys, дописываем “ручками” имя ключа, я написал “MyForeignKey1”, в Referenced table выбрал Departments, а в правой части таблицы – выбрал в колонке Coloumn Department_id, поскольку это было имя внешнего ключа для таблицы Students и соответствующее поле в другой таблице Primary Key
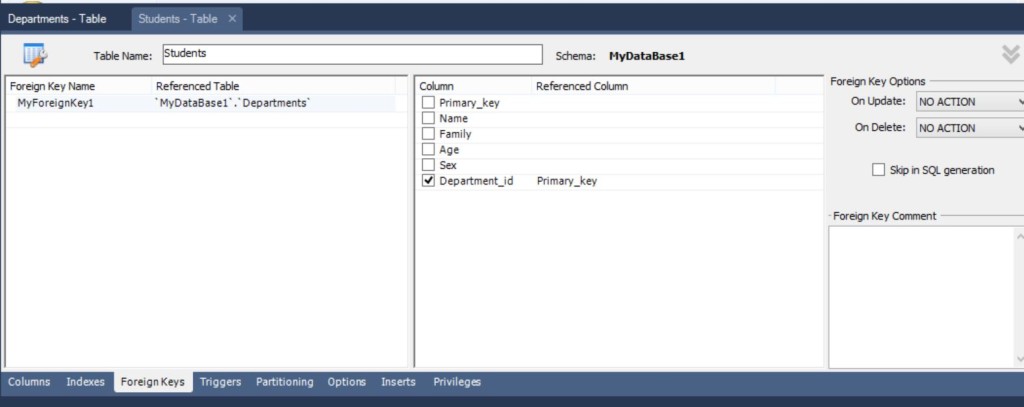
Можно также ещё заполнить Foreign Key Options. По описанию из блога Mithandrir
В разделе “Foreign Key Options” настраиваем поведение внешнего ключа при изменении соответствующего поля (ON UPDATE) и удалении (ON DELETE) родительской записи:
- RESTRICT – выдавать ошибку при изменении / удалении родительской записи
- CASCADE – обновлять внешний ключ при изменении родительской записи, удалять дочернюю запись при удалении родителя
- SET NULL – устанавливать значение внешнего ключа NULL при изменении / удалении родителя (неприемлемо для полей, у которых установлен флаг NOT NULL!)
- NO ACTION – не делать ничего, однако по факту эффект аналогичен RESTRICT
Сохранение из модели в реальную / физическую базу данных
“File → Export→ Forward Engineer MySQL Create Script…”
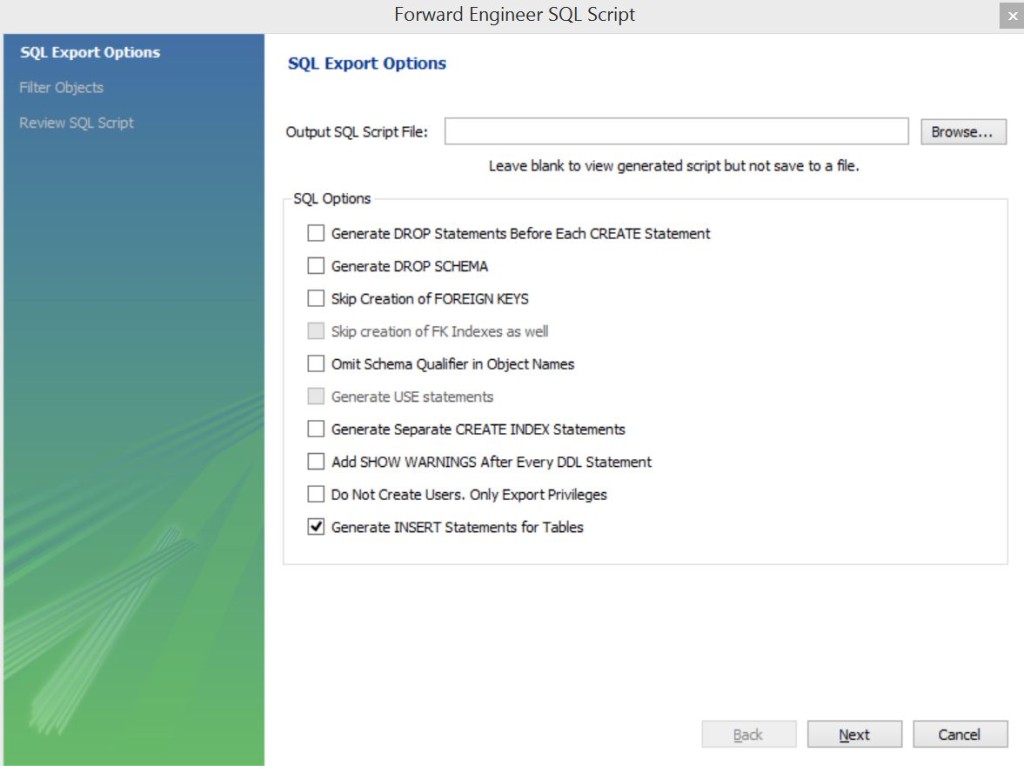
Отмечаем необходимые галочки, мне нужна была только одна Generate INSERT Statements for Tables. Если нужно сохранить скрипт в файл – пропишите директорию в поле сверху.
В следующем окне можно настроить – какие объекты мы будем экспортировать. Если внимательно присмотреться, то у нас создано всего 2 таблицы.
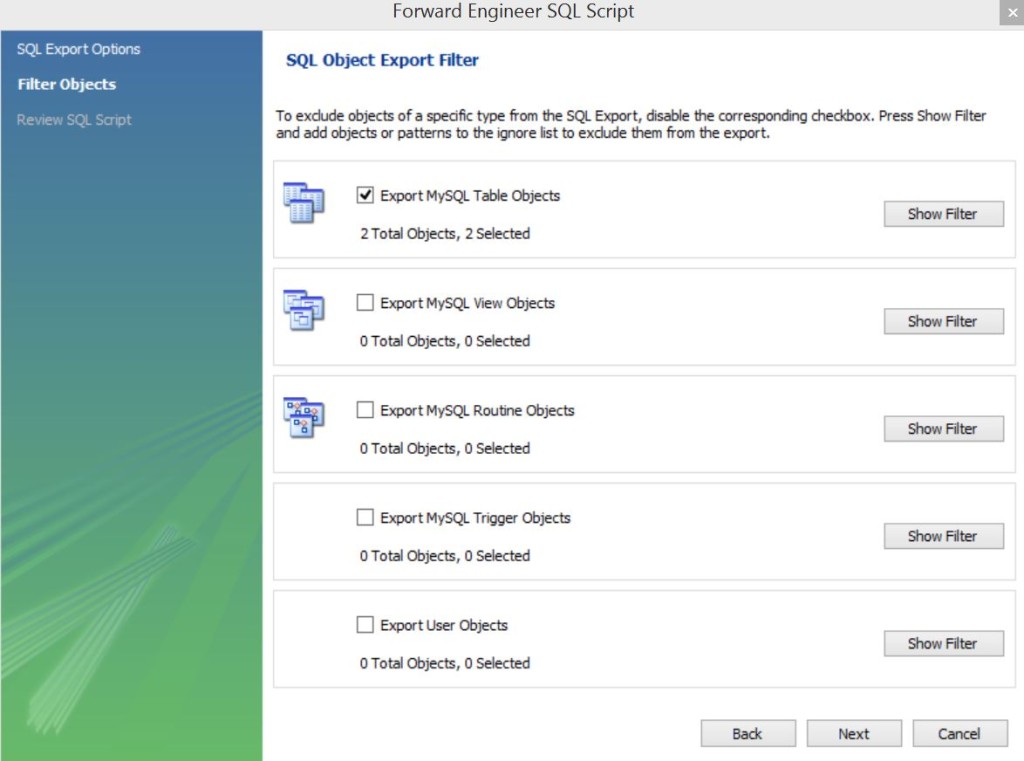
Жмем далее… и получаем такой вот скрипт…
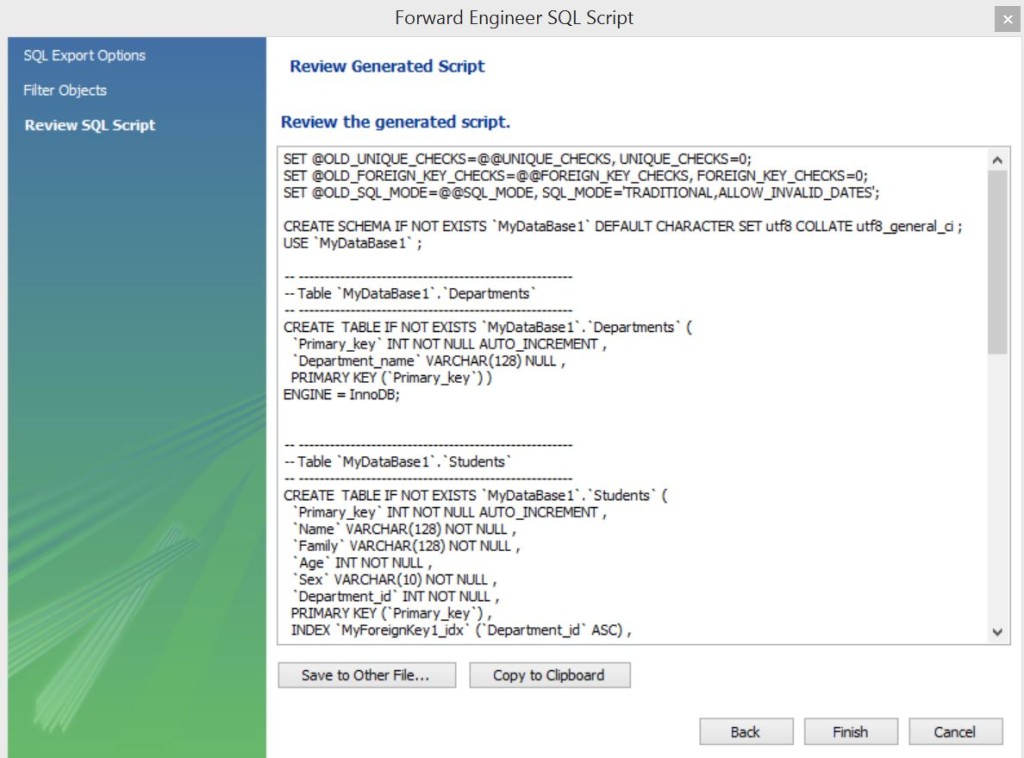
Копируем в буфер, но что дальше? Нужно этот скрипт где-то выполнить…
Выполнение скрипта – создания базы данных и таблиц
Жмем на “домик” в верхнем левом углу программы…
Потом 2 раза кликаем на MyConnection….
Перед нами открывается такая вкладка…
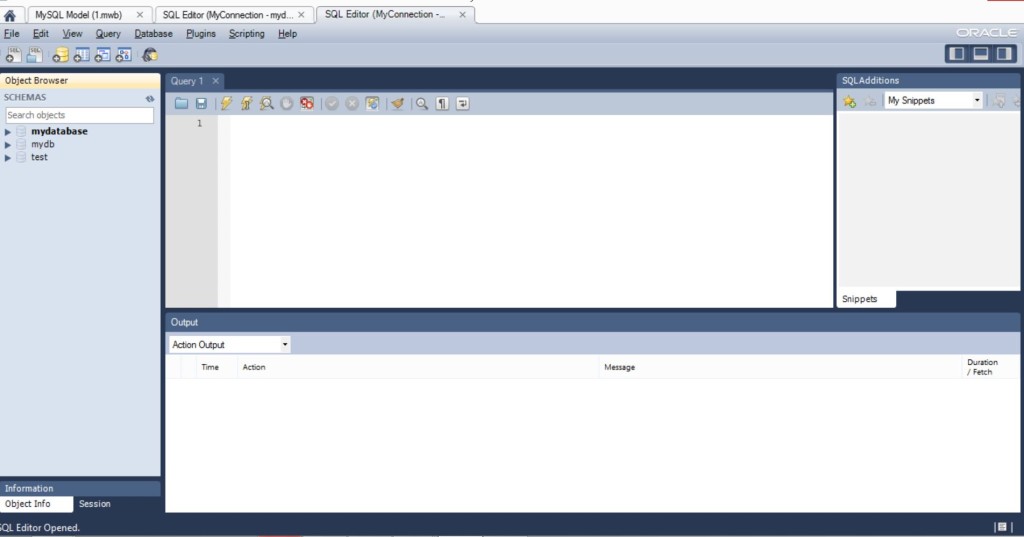
Это наше соединение с сервером, здесь мы и будем выполнять наш скрипт. Обратите внимание, слева базы данных, которые были созданы в программе WorkBench….
Далее, File New Query Tab… Вставляем скрипт в полученный Tab…
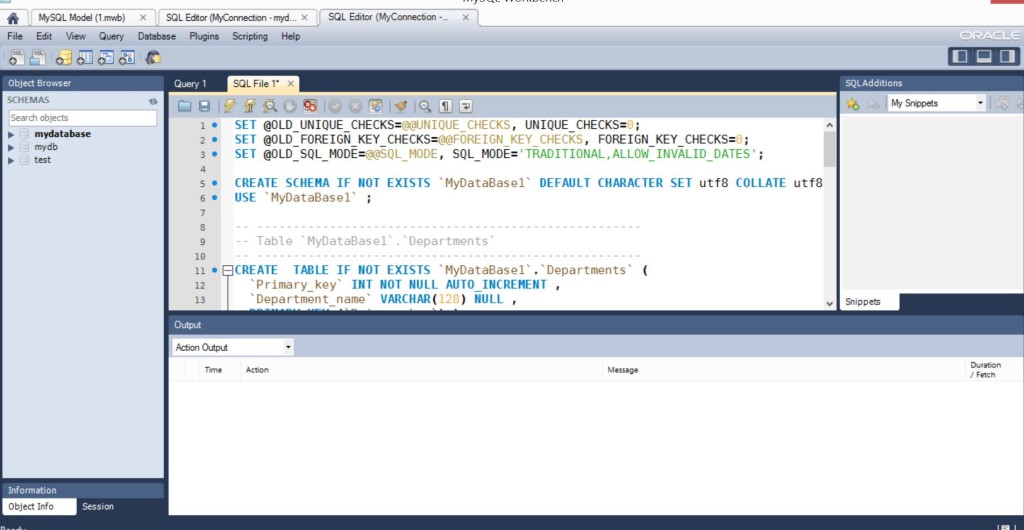
Теперь, нужно дать команду этот скрипт исполнить, для этого жмем в верхнем меню, Query Execute (All or Selection)
Итак, если все нормально, то в нижнем окне output, вы увидите все “зеленые галочки”. А когда нажмете Refresh в контекстном меню в списке баз данных, то увидите, вновь созданную базу mydatabase1.
Напоследок, построим ER диаграмму. ER расшифровывается как Entity Relation – удачная модель “Сущность – связь”, которая, в частности разрабатывалась Питером Ченом. Итак, возвращаемся на вкладку модели и жмем на Add Diagramm…
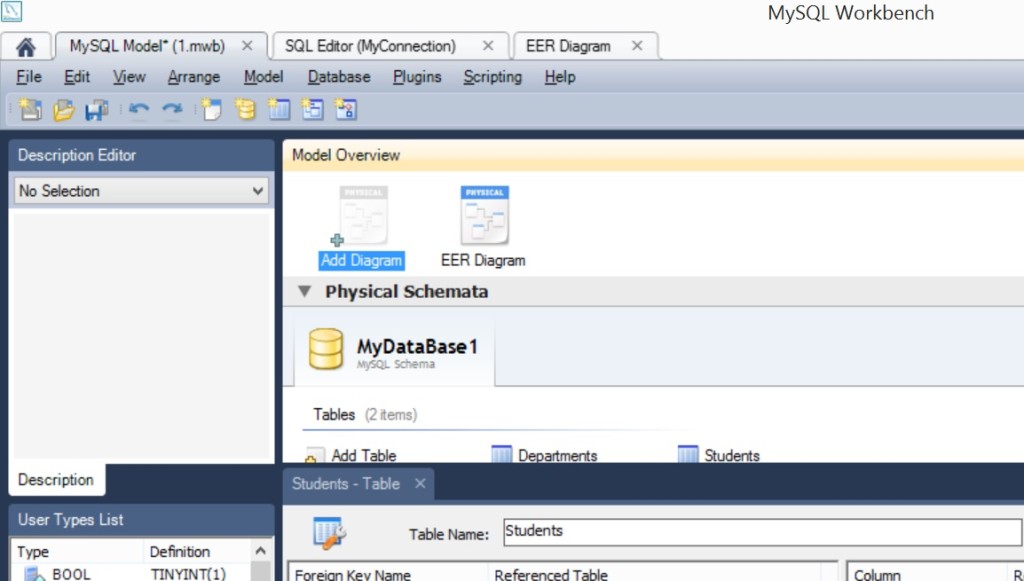
Далее, переносим таблицы в область диаграммы…
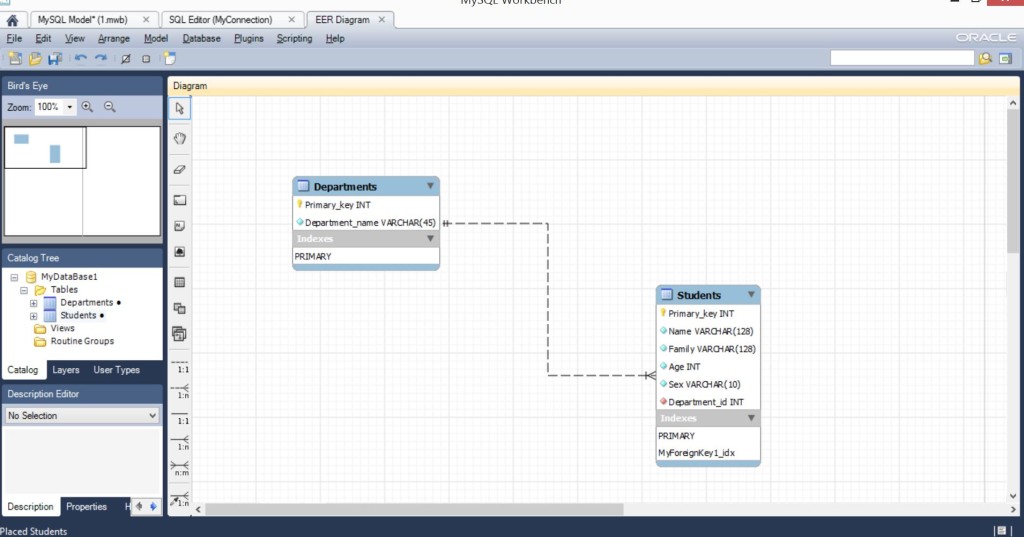
Мы создали связь один ко многим. На одном факультете могут учиться несколько студентов. Обратите внимание, связь возле таблицы Students расщепляется – это означает “ко многим”.
Итак, мы создали модель, из неё через выполнение скрипта – реальную базу с таблицами. А также создали диаграмму ER.
Схемы используются в модели безопасности компонента Database Engine для упрощения взаимоотношений между пользователями и объектами, и, следовательно, схемы имеют очень большое влияние на взаимодействие пользователя с компонентом Database Engine. В этом разделе рассматривается роль схем в безопасности компонента Database Engine. В первом подразделе описывается взаимодействие между схемами и пользователями, а во втором обсуждаются все три инструкции языка Transact-SQL, применяемые для создания и модификации схем.
Разделение пользователей и схем
- это коллекция объектов базы данных, имеющая одного владельца и формирующая одно пространство имен. (Две таблицы в одной и той же схеме не могут иметь одно и то же имя.) Компонент Database Engine поддерживает именованные схемы с использованием понятия принципала (principal). Как уже упоминалось, принципалом может быть индивидуальный принципал и групповой принципал.
Индивидуальный принципал представляет одного пользователя, например, в виде регистрационного имени или учетной записи пользователя Windows. Групповым принципалом может быть группа пользователей, например, роль или группа Windows. Принципалы владеют схемами, но владение схемой может быть с легкостью передано другому принципалу без изменения имени схемы.
Отделение пользователей базы данных от схем дает значительные преимущества, такие как:
один принципал может быть владельцем нескольких схем;
несколько индивидуальных принципалов могут владеть одной схемой посредством членства в ролях или группах Windows;
удаление пользователя базы данных не требует переименования объектов, содержащихся в схеме этого пользователя.
Каждая база данных имеет схему по умолчанию, которая используется для определения имен объектов, ссылки на которые делаются без указания их полных уточненных имен. В схеме по умолчанию указывается первая схема, в которой сервер базы данных будет выполнять поиск для разрешения имен объектов. Для настройки и изменения схемы по умолчанию применяется параметр DEFAULT_SCHEMA инструкции CREATE USER или ALTER USER. Если схема по умолчанию DEFAULT_SCHEMA не определена, в качестве схемы по умолчанию пользователю базы данных назначается схема dbo.
Инструкция CREATE SCHEMA
В примере ниже показано создание схемы и ее использование для управления безопасностью базы данных. Прежде чем выполнять этот пример, необходимо создать пользователей базы данных Alex и Vasya, как будет описано в следующей статье (вы можете вернуться к этим примерам позже).
В этом примере создается схема poco, содержащая таблицу Product и представление view_Product. Пользователь базы данных Vasya является принципалом уровня базы данных, а также владельцем схемы. (Владелец схемы указывается посредством параметра AUTHORIZATION. Принципал может быть владельцем других схем и не может использовать текущую схему в качестве схемы по умолчанию.)
Две другие инструкции, применяемые для работы с разрешениями для объектов базы данных, GRANT и DENY, подробно рассматриваются позже. В этом примере инструкция GRANT предоставляет инструкции SELECT разрешения для всех создаваемых в схеме объектов, тогда как инструкция DENY запрещает инструкции UPDATE разрешения для всех объектов схемы.
С помощью инструкции CREATE SCHEMA можно создать схему, сформировать содержащиеся в этой схеме таблицы и представления, а также предоставить, запретить или удалить разрешения на защищаемый объект. Как упоминалось ранее, защищаемые объекты - это ресурсы, доступ к которым регулируется системой авторизации SQL Server. Существует три основные области защищаемых объектов: сервер, база данных и схема, которые содержат другие защищаемые объекты, такие как регистрационные имена, пользователи базы данных, таблицы и хранимые процедуры.
Инструкция CREATE SCHEMA является атомарной. Иными словами, если в процессе выполнения этой инструкции происходит ошибка, не выполняется ни одна из содержащихся в ней подынструкций.
Порядок указания создаваемых в инструкции CREATE SCHEMA объектов базы данных может быть произвольным, с одним исключением: представление, которое ссылается на другое представление, должно быть указано после представления, на которое оно ссылается.
Принципалом уровня базы данных может быть пользователь базы данных, роль или роль приложения. (Роли и роли приложения рассматриваются в одной из следующих статей.) Принципал, указанный в предложении AUTHORIZATION инструкции CREATE SCHEMA, является владельцем всех объектов, созданных в этой схеме. Владение содержащихся в схеме объектов можно передавать любому принципалу уровня базы данных посредством инструкции ALTER AUTHORIZATION.
Для исполнения инструкции CREATE SCHEMA пользователь должен обладать правами базы данных CREATE SCHEMA. Кроме этого, для создания объектов, указанных в инструкции CREATE SCHEMA, пользователь должен иметь соответствующие разрешения CREATE.
Инструкция ALTER SCHEMA
Инструкция ALTER SCHEMA перемещает объекты между разными схемами одной и той же базы данных. Инструкция ALTER SCHEMA имеет следующий синтаксис:
Использование инструкции ALTER SCHEMA показано в примере ниже:
Здесь изменяется схема HumanResources базы данных AdventureWorks2012, перемещая в нее таблицу ContactType из схемы Person этой же базы данных. Инструкцию ALTER SCHEMA можно использовать для перемещения объектов между разными схемами только одной и той же базы данных. (Отдельные объекты в схеме можно изменить посредством инструкции ALTER TABLE или ALTER VIEW.)
Инструкция DROP SCHEMA
Для удаления схемы из базы данных применяется инструкция DROP SCHEMA. Схему можно удалить только при условии, что она не содержит никаких объектов. Если схема содержит объекты, попытка выполнить инструкцию DROP SCHEMA будет неуспешной.
Как указывалось ранее, владельца схемы можно изменить посредством инструкции ALTER AUTHORIZATION, которая изменяет владение сущностью. Язык Transact-SOL не поддерживает инструкции CREATE AUTHORIZATION и DROP AUTHORIZATION. Владелец схемы указывается с помощью инструкции CREATE SCHEMA.
Кластер баз данных PostgreSQL содержит один или несколько именованных экземпляров баз. На уровне кластера создаются роли и некоторые другие объекты. При этом в рамках одного подключения к серверу можно обращаться к данным только одной базы — той, что была выбрана при установлении соединения.
Примечание
Пользователи кластера не обязательно будут иметь доступ ко всем базам данных этого кластера. Тот факт, что роли создаются на уровне кластера, означает только то, что в кластере не может быть двух ролей joe в разных базах данных, хотя система позволяет ограничить доступ joe только некоторыми базами данных.
База данных содержит одну или несколько именованных схем, которые в свою очередь содержат таблицы. Схемы также содержат именованные объекты других видов, включая типы данных, функции и операторы. Одно и то же имя объекта можно свободно использовать в разных схемах, например и schema1 , и myschema могут содержать таблицы с именем mytable . В отличие от баз данных, схемы не ограничивают доступ к данным: пользователи могут обращаться к объектам в любой схеме текущей базы данных, если им назначены соответствующие права.
Есть несколько возможных объяснений, для чего стоит применять схемы:
Чтобы одну базу данных могли использовать несколько пользователей, независимо друг от друга.
Чтобы объединить объекты базы данных в логические группы для облегчения управления ими.
Схемы в некоторым смысле подобны каталогам в операционной системе, но они не могут быть вложенными.
5.8.1. Создание схемы
Для создания схемы используется команда CREATE SCHEMA . При этом вы определяете имя схемы по своему выбору, например так:
Чтобы создать объекты в схеме или обратиться к ним, указывайте полное имя, состоящее из имён схемы и объекта, разделённых точкой:
Этот синтаксис работает везде, где ожидается имя таблицы, включая команды модификации таблицы и команды обработки данных, обсуждаемые в следующих главах. (Для краткости мы будем говорить только о таблицах, но всё это распространяется и на другие типы именованных объектов, например, типы и функции.)
Есть ещё более общий синтаксис
но в настоящее время он поддерживается только для формального соответствия стандарту SQL. Если вы указываете базу данных, это может быть только база данных, к которой вы подключены.
Таким образом, создать таблицу в новой схеме можно так:
Чтобы удалить пустую схему (не содержащую объектов), выполните:
Удалить схему со всеми содержащимися в ней объектами можно так:
Стоящий за этим общий механизм описан в Разделе 5.13.
Часто бывает нужно создать схему, владельцем которой будет другой пользователь (это один из способов ограничения пользователей пространствами имён). Сделать это можно так:
Вы даже можете опустить имя схемы, в этом случае именем схемы станет имя пользователя. Как это можно применять, описано в Подразделе 5.8.6.
Схемы с именами, начинающимися с pg_ , являются системными; пользователям не разрешено использовать такие имена.
5.8.2. Схема public
5.8.3. Путь поиска схемы
Везде писать полные имена утомительно, и часто всё равно лучше не привязывать приложения к конкретной схеме. Поэтому к таблицам обычно обращаются по неполному имени, состоящему просто из имени таблицы. Система определяет, какая именно таблица подразумевается, используя путь поиска, который представляет собой список просматриваемых схем. Подразумеваемой таблицей считается первая подходящая таблица, найденная в схемах пути. Если подходящая таблица не найдена, возникает ошибка, даже если таблица с таким именем есть в других схемах базы данных.
Возможность создавать одноимённые объекты в разных схемах усложняет написание запросов, которые должны всегда обращаться к конкретным объектам. Это также потенциально позволяет пользователям влиять на поведение запросов других пользователей, злонамеренно или случайно. Ввиду преобладания неполных имён в запросах и их использования внутри PostgreSQL , добавить схему в search_path — по сути значит доверять всем пользователям, имеющим право CREATE в этой схеме. Когда вы выполняете обычный запрос, злонамеренный пользователь может создать объекты в схеме, включённой в ваш путь поиска, и таким образом перехватывать управление и выполнять произвольные функции SQL как если бы их выполняли вы.
Первая схема в пути поиска называется текущей. Эта схема будет использоваться не только при поиске, но и при создании объектов — она будет включать таблицы, созданные командой CREATE TABLE без указания схемы.
Чтобы узнать текущий тип поиска, выполните следующую команду:
В конфигурации по умолчанию она возвращает:
Первый элемент ссылается на схему с именем текущего пользователя. Если такой схемы не существует, ссылка на неё игнорируется. Второй элемент ссылается на схему public, которую мы уже видели.
Первая существующая схема в пути поиска также считается схемой по умолчанию для новых объектов. Именно поэтому по умолчанию объекты создаются в схеме public. При указании неполной ссылки на объект в любом контексте (при модификации таблиц, изменении данных или в запросах) система просматривает путь поиска, пока не найдёт соответствующий объект. Таким образом, в конфигурации по умолчанию неполные имена могут относиться только к объектам в схеме public.
Чтобы добавить в путь нашу новую схему, мы выполняем:
(Мы опускаем компонент $user , так как здесь в нём нет необходимости.) Теперь мы можем обращаться к таблице без указания схемы:
И так как myschema — первый элемент в пути, новые объекты будут по умолчанию создаваться в этой схеме.
Мы можем также написать:
Тогда мы больше не сможем обращаться к схеме public, не написав полное имя объекта. Единственное, что отличает схему public от других, это то, что она существует по умолчанию, хотя её так же можно удалить.
В Разделе 9.25 вы узнаете, как ещё можно манипулировать путём поиска схем.
Как и для имён таблиц, путь поиска аналогично работает для имён типов данных, имён функций и имён операторов. Имена типов данных и функций можно записать в полном виде так же, как и имена таблиц. Если же вам нужно использовать в выражении полное имя оператора, для этого есть специальный способ — вы должны написать:
Такая запись необходима для избежания синтаксической неоднозначности. Пример такого выражения:
На практике пользователи часто полагаются на путь поиска, чтобы не приходилось писать такие замысловатые конструкции.
5.8.4. Схемы и права
По умолчанию пользователь не может обращаться к объектам в чужих схемах. Чтобы изменить это, владелец схемы должен дать пользователю право USAGE для данной схемы. Чтобы пользователи могли использовать объекты схемы, может понадобиться назначить дополнительные права на уровне объектов.
Пользователю также можно разрешить создавать объекты в схеме, не принадлежащей ему. Для этого ему нужно дать право CREATE в требуемой схеме. Заметьте, что по умолчанию все имеют права CREATE и USAGE в схеме public . Благодаря этому все пользователи могут подключаться к заданной базе данных и создавать объекты в её схеме public . Некоторые шаблоны использования требуют запретить это:
5.8.5. Схема системного каталога
В дополнение к схеме public и схемам, создаваемым пользователями, любая база данных содержит схему pg_catalog , в которой находятся системные таблицы и все встроенные типы данных, функции и операторы. pg_catalog фактически всегда является частью пути поиска. Если даже эта схема не добавлена в путь явно, она неявно просматривается до всех схем, указанных в пути. Так обеспечивается доступность встроенных имён при любых условиях. Однако вы можете явным образом поместить pg_catalog в конец пути поиска, если вам нужно, чтобы пользовательские имена переопределяли встроенные.
Так как имена системных таблиц начинаются с pg_ , такие имена лучше не использовать во избежание конфликта имён, возможного при появлении в будущем системной таблицы с тем же именем, что и ваша. (С путём поиска по умолчанию неполная ссылка будет воспринята как обращение к системной таблице.) Системные таблицы будут и дальше содержать в имени приставку pg_ , так что они не будут конфликтовать с неполными именами пользовательских таблиц, если пользователи со своей стороны не будут использовать приставку pg_ .
5.8.6. Шаблоны использования
Схемам можно найти множество применений. Для защиты от влияния недоверенных пользователей на поведение запросов других пользователей предлагается шаблон безопасного использования схем, но если этот шаблон не применяется в базе данных, пользователи, желающие безопасно выполнять в ней запросы, должны будут принимать защитные меры в начале каждого сеанса. В частности, они должны начинать каждый сеанс с присвоения пустого значения переменной search_path или каким-либо другим образом удалять из search_path схемы, доступные для записи обычным пользователям. С конфигурацией по умолчанию легко реализуются следующие шаблоны использования:
Ограничить обычных пользователей личными схемами. Для реализации этого подхода выполните REVOKE CREATE ON SCHEMA public FROM PUBLIC и создайте для каждого пользователя схему с его именем. Как вы знаете, путь поиска по умолчанию начинается с имени $user , вместо которого подставляется имя пользователя. Таким образом, если у всех пользователей будет отдельная схема, они по умолчанию будут обращаться к собственным схемам. Применяя этот шаблон в базе, к которой уже могли подключаться недоверенные пользователи, проверьте, нет ли в схеме public объектов с такими же именами, как у объектов в схеме pg_catalog . Этот шаблон является шаблоном безопасного использования схем, только если никакой недоверенный пользователь не является владельцем базы данных и не имеет права CREATEROLE . В противном случае безопасное использование схем невозможно.
Удалить схему public из пути поиска по умолчанию, изменив postgresql.conf или выполнив команду ALTER ROLE ALL SET search_path = "$user" . При этом все по-прежнему смогут создавать объекты в общей схеме, но выбираться эти объекты будут только по полному имени, со схемой. Тогда как обращаться к таблицам по полному имени вполне допустимо, обращения к функциям в общей схеме всё же будут небезопасными или ненадёжными. Поэтому если вы создаёте функции или расширения в схеме public, применяйте первый шаблон. Если же нет, этот шаблон, как и первый, безопасен при условии, что никакой недоверенный пользователь не является владельцем базы данных и не имеет права CREATEROLE .
При любом подходе, устанавливая совместно используемые приложения (таблицы, которые нужны всем, дополнительные функции сторонних разработчиков и т. д.), помещайте их в отдельные схемы. Не забудьте дать другим пользователям права для доступа к этим схемам. Тогда пользователи смогут обращаться к этим дополнительным объектам по полному имени или при желании добавят эти схемы в свои пути поиска.
5.8.7. Переносимость
Стандарт SQL не поддерживает обращение в одной схеме к разным объектам, принадлежащим разным пользователям. Более того, в ряде реализаций СУБД нельзя создавать схемы с именем, отличным от имени владельца. На практике, в СУБД, реализующих только базовую поддержку схем согласно стандарту, концепции пользователя и схемы очень близки. Таким образом, многие пользователи полагают, что полное имя на самом деле образуется как имя_пользователя . имя_таблицы . И именно так будет вести себя PostgreSQL , если вы создадите схемы для каждого пользователя.
В стандарте SQL нет и понятия схемы public . Для максимального соответствия стандарту использовать схему public не следует.
Конечно, есть СУБД, в которых вообще не реализованы схемы или пространства имён поддерживают (возможно, с ограничениями) обращения к другим базам данных. Если вам потребуется работать с этими системами, максимальной переносимости вы достигнете, вообще не используя схемы.
Читайте также: