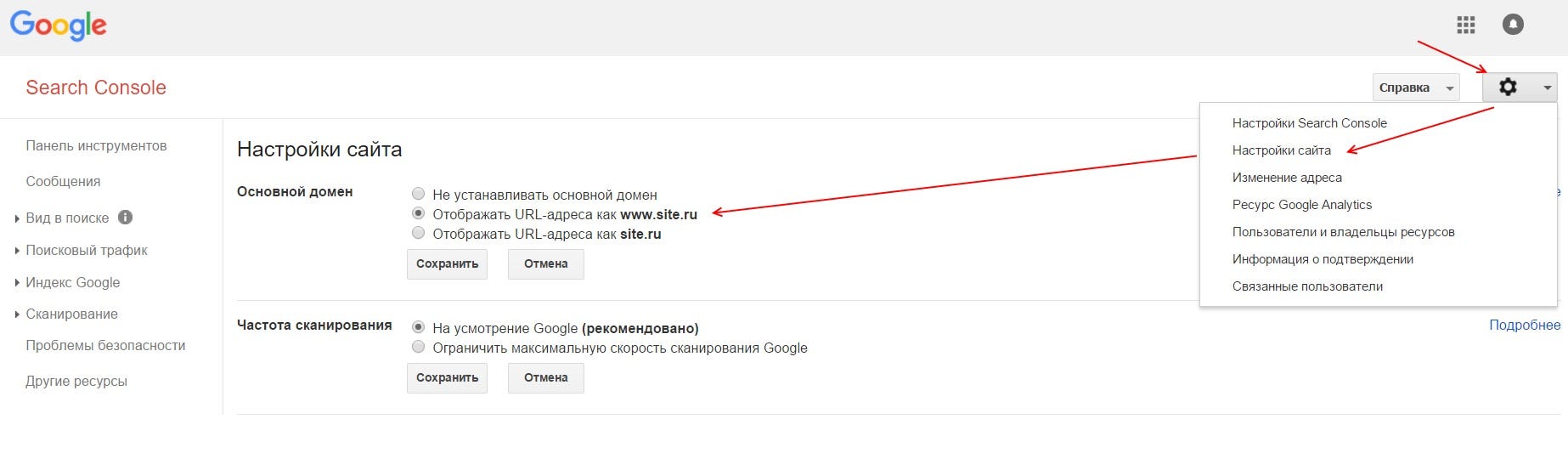
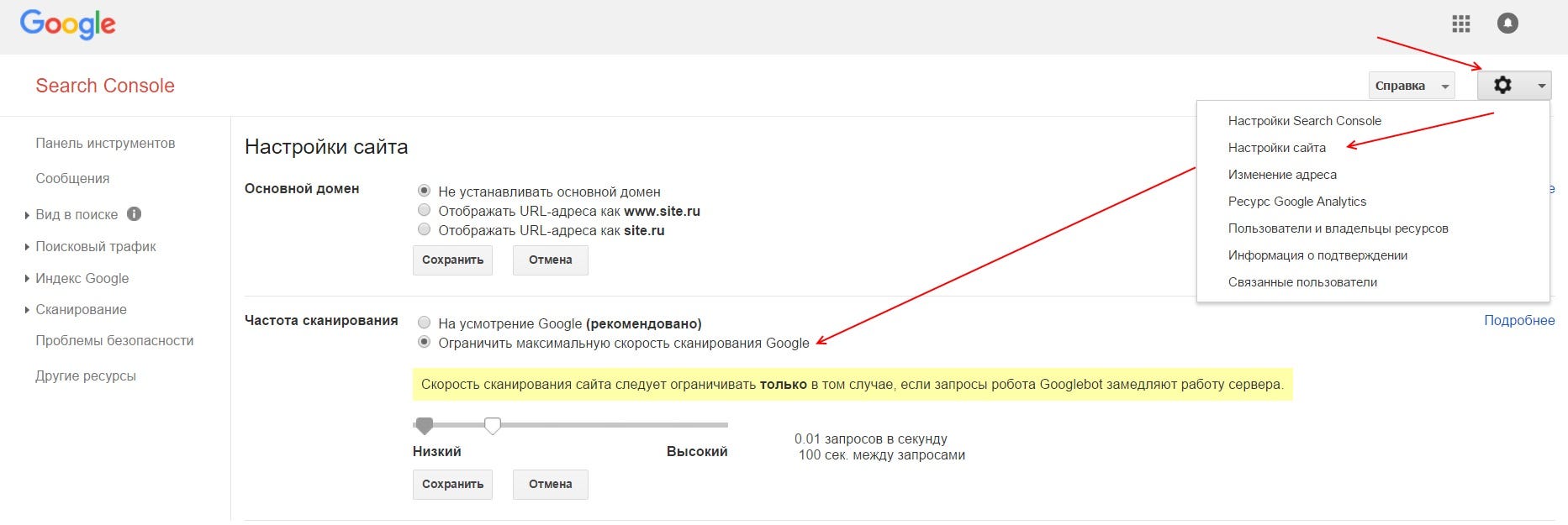
Как сделать робота поисковика
Добавил пользователь Дмитрий К. Обновлено: 04.10.2024
Создание личного поискового бота поможет вам найти лучшие сайты на основе ваших критериев поиска. Например, ограничьте личный поисковый бот, чтобы найти только фактические ссылки или конкретное местоположение.
Люди используют этот тип бота, чтобы найти сайты, которые содержат именно тот тип информации, которую они хотят. Поисковая система, такая как Google, показывает миллионы веб-сайтов на основе релевантности ключевых слов. В отличие от этого, личный поисковый бот найдет сайты, которые хорошо подойдут на основе личности и знаний человека.
Персональные поисковые роботы начались как исследовательский проект Марка Земана как часть магистра в области дизайна в университете Месси. Исследование проверило влияние, которое Интернет оказывает на сотрудничество между группами людей и информацией, которой они обмениваются.
Шаг 1
Шаг 2
Отрегулируйте цвета изображения вашего поискового бота. Переместите указатель мыши вокруг палитры и сразу же увидите изменения в изображении робота в левой части веб-страницы.
Шаг 3
Выберите личность для поискового бота, выбрав один из двух чипов данных (образы дискет), которые появляются на экране. Текст, который появляется с изображением чипа данных, отражает личность бота. Выберите один чип и перетащите его через веб-страницу на изображение робота и нажмите, чтобы активировать.
Подача поискового бота осуществляется через микросхемы данных - небольшие изображения гибких дисков, которые позволяют настроить поискового бота для выполнения поисковых запросов на основе тегов, местоположения, вопросов, цвета и других личных характеристик. Эти чипы отображаются в графическом интерфейсе, где вы просто перетаскиваете изображение чипа в созданный вами поисковый бот и опускаете его для активации.
Чем больше пользовательских данных, ключевых слов, тегов и информации вы предоставляете своему персональному поисковому роботу, тем более индивидуальными и релевантными становятся результаты поиска - в зависимости от ваших спецификаций. Когда бот обнаружит новые результаты поиска, вы получите оповещение по электронной почте.
Шаг 5
Как создать свой собственный бот онлайн

Вы можете не видеть роботов очень часто вокруг дома или на улице, но роботы (или боты) уже захватили мир онлайн. Онлайн бот - это автоматизированная компьютерная программа .
Как использовать поиск в Windows 7 и настроить поисковый индекс

Как использовать поиск в Windows 7 и найти то, что вы хотите, из любой точки мира. Как настроить поисковый индекс в Windows 7.
Не можете найти файлы? Вы можете перестроить, обновить или добавить диски в поисковый индекс Windows 10, чтобы он снова заработал.
Если вы пользуетесь сервисом веб-хостинга (например, Wix или Blogger), вероятнее всего, вам не потребуется редактировать файл robots.txt напрямую или у вас даже не будет такой возможности. Вместо этого ваш провайдер будет указывать поисковым системам, нужно ли сканировать ваш контент, с помощью страницы настроек поиска или другого инструмента.
Если же вы хотите самостоятельно запретить или разрешить поисковым системам обработку определенной страницы вашего сайта, попробуйте найти информацию об этом в сервисе управления хостингом. Пример запроса: "wix как скрыть страницу от поисковых систем".
Ниже приведен пример простого файла robots.txt с двумя правилами.
Более подробные сведения вы найдете в разделе Синтаксис.
Основные рекомендации по созданию файла robots.txt
Чтобы создать файл robots.txt и сделать его доступным, необходимо выполнить четыре действия:
Как создать файл robots.txt
Создать файл robots.txt можно в любом текстовом редакторе, таком как Блокнот, TextEdit, vi или Emacs. Не используйте офисные приложения, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них лишние символы, например фигурные кавычки, которые не распознаются поисковыми роботами. Обязательно сохраните файл в кодировке UTF-8, если вам будет предложено выбрать кодировку.
Правила в отношении формата и расположения файла
Как добавить правила в файл robots.txt
Правила – это инструкции для поисковых роботов, указывающие, какие разделы сайта можно сканировать. Добавляя правила в файл robots.txt, учитывайте следующее:
- Файл robots.txt состоит из одной или более групп.
- Каждая группа может включать несколько правил, по одному на строку. Эти правила также называются директивами или инструкциями. Каждая группа начинается со строки User-agent , определяющей, какому роботу адресованы правила в ней.
- Группа содержит следующую информацию:
- К какому агенту пользователя относятся директивы группы.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
Директивы в файлах robots.txt, поддерживаемые роботами Google
Все директивы, кроме sitemap , поддерживают подстановочный знак * для обозначения префикса или суффикса пути, а также всего пути.
Строки, не соответствующие ни одной из этих директив, игнорируются.
Ознакомьтесь со спецификацией Google для файлов robots.txt, где подробно описаны все директивы.
Как загрузить файл robots.txt
Сохраненный на компьютере файл robots.txt необходимо загрузить на сайт и сделать доступным для поисковых роботов. Специального инструмента для этого не существует, поскольку способ загрузки зависит от вашего сайта и серверной архитектуры. Обратитесь к своему хостинг-провайдеру или попробуйте самостоятельно найти его документацию (пример запроса: "загрузка файлов infomaniak").
После загрузки файла robots.txt проверьте, доступен ли он для роботов и может ли Google обработать его.
Как протестировать разметку файла robots.txt
Для этой цели Google предлагает два средства:
- Инструмент проверки файла robots.txt в Search Console. Этот инструмент можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
- Если вы разработчик, мы рекомендуем воспользоваться библиотекой с открытым исходным кодом, которая также применяется в Google Поиске. С помощью этого инструмента файлы robots.txt можно локально тестировать прямо на компьютере.
Когда вы загрузите и протестируете файл robots.txt, поисковые роботы Google автоматически найдут его и начнут применять. С вашей стороны никаких действий не требуется. Если вы внесли в файл robots.txt изменения и хотите как можно скорее обновить кешированную копию, следуйте инструкциям в этой статье.
Полезные правила
Вот несколько часто используемых в файлах robots.txt правил:
Следует учесть, что в некоторых случаях URL сайта могут индексироваться, даже если они не были просканированы.
Сканировать весь сайт может только робот googlebot-news .
Робот Unnecessarybot не может сканировать сайт, а все остальные могут.
Это правило запрещает сканирование отдельной страницы.
Например, можно запретить сканирование страницы useless_file.html .
Это правило скрывает определенное изображение от робота Google Картинок.
Например, вы можете запретить сканировать изображение dogs.jpg .
Это правило скрывает все изображения на сайте от робота Google Картинок.
Google не сможет индексировать изображения и видео, которые недоступны для сканирования.
Это правило запрещает сканировать все файлы определенного типа.
Например, вы можете запретить роботам доступ ко всем файлам .jpg .
Это правило запрещает сканировать весь сайт, но при этом он может обрабатываться роботом Mediapartners-Google
Робот Mediapartners-Google сможет получить доступ к удаленным вами из результатов поиска страницам, чтобы подобрать объявления для показа тому или иному пользователю.
Например, эта функция позволяет исключить все файлы .xls .
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Думаю, никто не будет в обиде, если я перенесу эту статью сюда.
Энциклопедия интернет-маркетинга: составляем корректный robots.txt своими руками
SEOnews запустил проект для специалистов и клиентов "Энциклопедия интернет-маркетинга", в рамках которого редакция пуб…
Если попросить SEO-специалиста оценить важность правильно составленного robots.txt для сайта, хороший SEOшник оценит ее на 5 баллов из 5.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенн а я директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индекса поисковых систем, а значит, потеряет весь поисковый трафик.
- Введение
- Что такое robots.txt
- Директивы и спецсимволы robots.txt
- Настройка Google Search Consloe (GSC)
- Как составить правильный robots.txt самостоятельно
- Распространенные ошибки при составлении robots.txt
- Заключение
- Полезные ссылки
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
То есть, другими словами, robots.txt — набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Порядок включения директив:
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent — указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
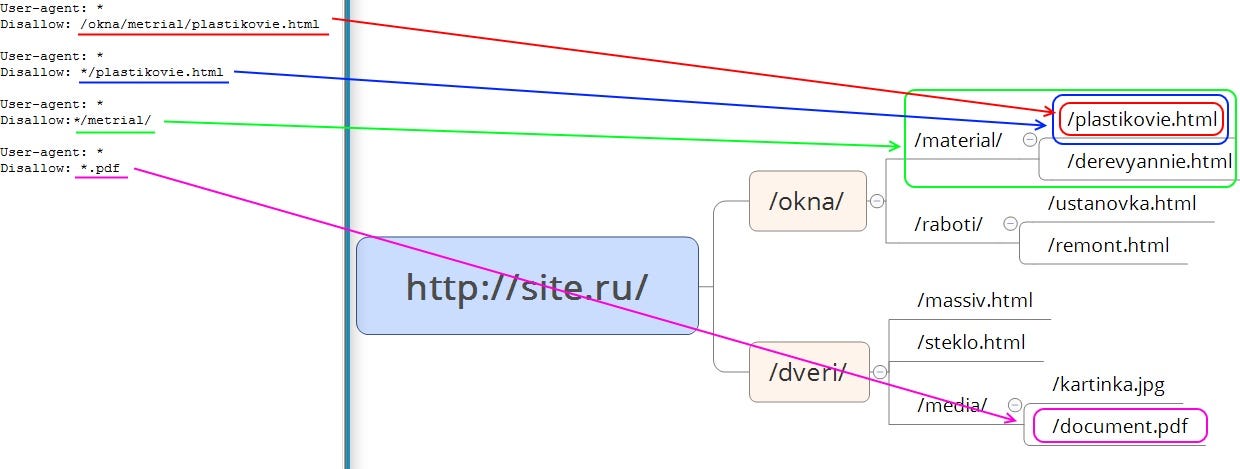
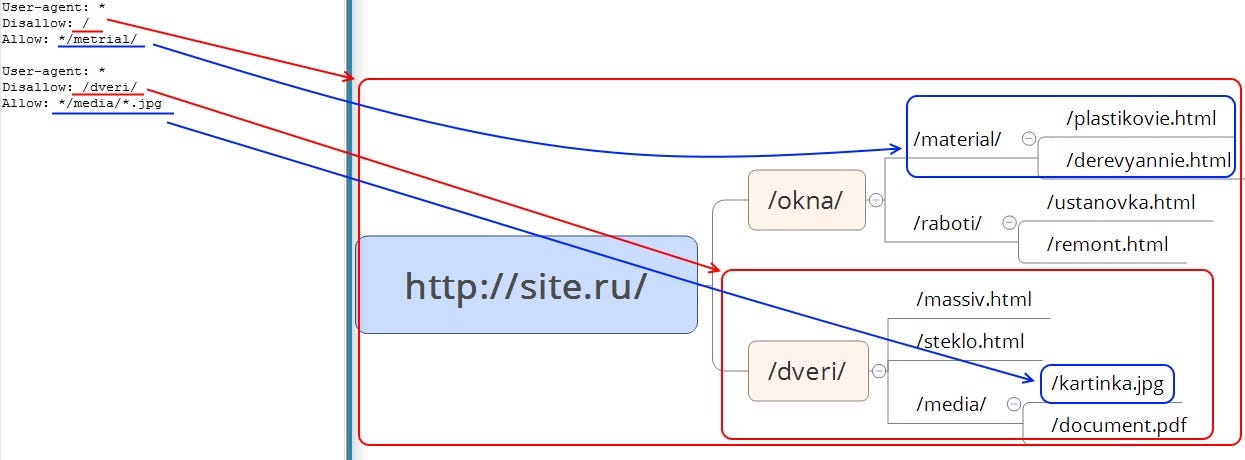
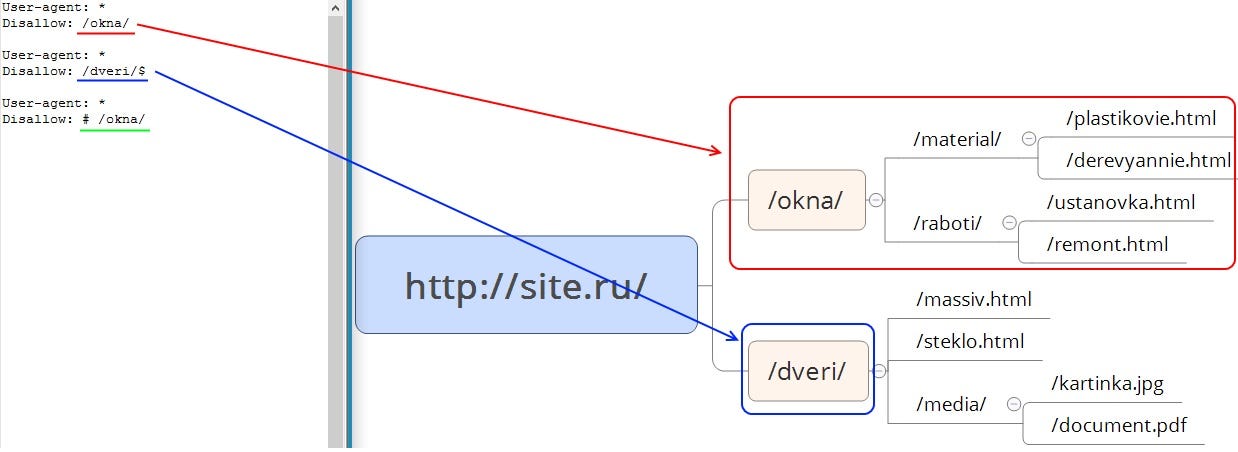
Disallow — директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
![]()
Allow — директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
![]()
Sitemap — директива для указания пути к файлу xml-карты сайта.
- Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
Спецсимволы
![]()
Host — директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay — директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
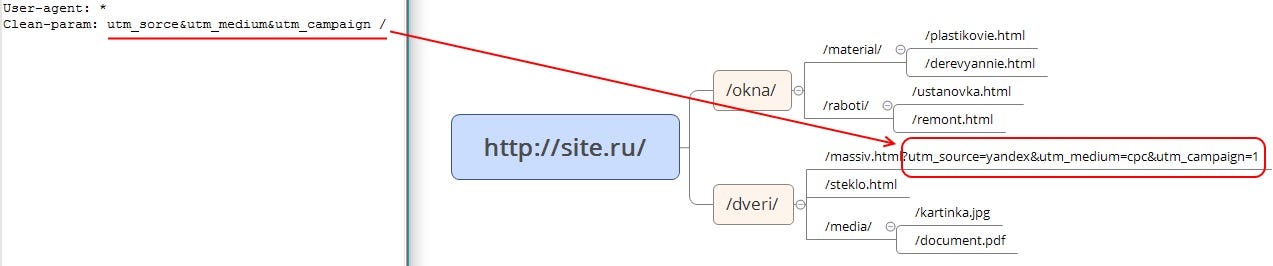
Clean-param — директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
![]()
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
![]()
![]()
![]()
Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
- Администраторская часть сайта
- Персональные разделы пользователей
- Корзины и этапы оформления
- Фильтры и сортировки в каталогах
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
- Между последней директивой одного User-agent’а и следующим User-agent’ом.
- Последней директивой последнего User-agent’а и директивой Sitemap.
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
Robots.txt является инструкцией, созданной веб-мастером, которая указывает поисковикам какие страницы и файлы сайта стоит сканировать, а какие нет.
Если правильно его составить, он может стать полезным инструментом для сеошника.
О том, как правильно это сделать читайте в нашей статье.
![Примеры создания и проверки файла robots.txt]()
СОДЕРЖАНИЕ
Нужен трафик?
Помогу найти точки роста в SEO.
Наладим стабильный трафик из поиска на Ваш сайт.
Напиши и получи бесплатный анализ.Файл robot.txt – необходим для большинства сайтов.
Каждый SEO-оптимизатор должен понимать смысл этого файла, а также уметь прописывать самые востребованные директивы.
Чтобы разобраться в том, что такое robot.txt и как он действует, вспомним, как работают поисковики.
Алгоритмы Google Яндекса и других систем выполняют два основных задания:
- обход интернета для поиска новой информации;
- индексирование контента, чтобы его могли находить пользователи.
Чтобы посетить все сайты, поисковые системы используют доменные имена, переходят с одного ресурса на другой, изучают миллиарды ссылок.
Такое поведение напоминает паука в паутине: он обходит территорию и смотрит, что нового попало в сеть.
После прибытия на веб-сайт, но перед его индексацией, алгоритм поисковика (робот, бот, сканнер) смотрит файл robots.txt.
Если он существует, бот сначала читает его, а потом, в соответствии с инструкциями, продолжает исследовать сайт.
Robots.txt содержит информацию о том, как поисковая система должна сканировать найденные страницы и что с ними делать.
Если файл не содержит директив, запрещающих действие агента (или его нет совсем), бот продолжит индексировать все данные на сайте.
![Nikolay]()
Что есть у конкурента, а у тебя – еще нет? Правильно – трафик. SEOquick в помощь!
Привлечем тебе на сайт массу трафика через SEO.
Сделаем это исключительно белыми методами, без фильтров и санкций от Google и Яндекс.
Проведем глубокую оптимизацию: усилим контент, нарастим ссылки и репутацию. И всё получиться!
Первое знакомство с Robots.Txt
Некоторые пользовательские агенты могут игнорировать robots.txt.
В какой кодировке создают Robots.txt?
Robots.txt — это текстовый файл, созданный веб-мастером для инструктирования поисковых роботов.
В нем прописаны рекомендации касательно того, как сканировать страницы на данном сайте.
Говоря простым языком – в этом файле указано, куда не надо заходить поисковому роботу, что индексировать для поиска, а что нет.
По сути, это простой текстовый файл, который создают в корневом каталоге сайта.
Всякий раз, когда поисковые агенты приходят на сайт, они ищут робота в одном конкретном месте: основной каталог (обычно корневой домен).
Некоторые пользовательские агенты могут игнорировать robots.txt.
Это особенно характерно для пиратских сканеров или парсеров адресов электронной почты.
Это общедоступный файл, его может увидеть любой пользователь, поэтому не используйте его, чтобы скрыть особо важную информацию.
В нижней части файла чаще всего указывают, где лежит карта сайта.
Если у Вас сайт (домен) с поддоменами, то в каждом из них в корне должны быть отдельные robots.txt.
Robots.txt создают в стандартной кодировке UTF-8.
Это важно, потому что другие кодировки поисковые системы могут воспринимать некорректно.
А если вдаваться в технические подробности, файл robots.txt – это документ в форме Бекса-Наура, которая востребована в различных языках программирования для описания синтаксиса.
Памятка: размер файла Robots.txt для Google ограничен 500Kb
В файле robots есть инструкции как поисковые системы должны обращаться со страницами сайта.
Зачем это нужно?
Для SEO, если на страницах есть ссылки на сторонние ресурсы, не уникальный контент или информация, которую не нужно индексировать.
Ответы на частые вопросы по ссылкам можно получить из нашего видео:
Также в robots.txt можно прописать отдельные правила для различных поисковиков, далее мы подробно рассмотрим, как это делается.
Вы хотите получать бесплатный трафик?
Вас интересует продвижение своего сайта?
Заполните форму ниже и я лично свяжусь с Вами и мы обсудим план по раскрутке вашего бизнеса!
Подробнее о Robots.Txt
Как проверить наличие файла robots.txt?
Файлы robots.txt контролируют доступ поисковых систем к определенным областям сайта.
Это полезно для оптимизации работы веб-ресурса, но может быть опасно, если Вы случайно запретили Googlebot (поисковику гугл) обходить весь сайт.
Вот распространенные случаи, когда используют robots.
- Чтобы в результатах выдачи не появлялось повторяющиеся или не уникальные тексты. Вообще, рекомендую использовать на сайтах только качественный контент, и ни в коем случае не копировать тексты с других сайтов, но иногда выкладывают инструкции, нормативные акты и другой материал, который нельзя уникализировать. Если система будет их индексировать, рейтинг сайта понизится. Имеет смысл закрывать такие страницы.
- При создании зеркальных сайтов необходимо сделать так, чтобы в ранжировании участвовал только один. В противном случае поисковик не будет понижать рейтинг (пессимизировать) дублированный контент.
- При закрытии сохраненных внутренних страниц сайта, результатов поисковой выдачи или иных материалов, используемых в процессе работы. Например, на сайте есть страничка или блок информации для сотрудников компании, совершенно не обязательно открывать ее поисковику.
- Чтобы скрыть от индексирования карты и географические данные.
- Изображения, файлы ПДФ и подобный графический контент.
- Для указания задержки при обходе – чтобы предотвратить перегрузку серверов, когда сканеры читают и индексируют сразу несколько частей сайта.
Если на сайте нет областей, где Вы хотите управлять доступом, файл robots.txt может и не понадобится, но это редкий случай.
Чаще всего он необходим хотя бы для того, чтобы закрыть админку.
Чтобы проверить его наличие, введите в адресную строку корневой домен, затем добавьте /robots.txt в конец URL-адреса.
3 типа инструкций для robots.txt.
Если обнаружили, что файл robots.txt отсутствует, создать его несложно.
Как уже было сказано в начале статьи – это обычный текстовый файл в корневом каталоге сайта.
Его можно сделать через админ-панель или файл-менеджер, с помощью которого программист работает с файлами на сайте.
В том, как и что там прописывать, мы разберемся по ходу статьи.
Поисковые системы получают из этого файла инструкции трех типов:
- сканировать все, то есть полный доступ (Allow);
- сканировать нельзя ничего – полный запрет (Disallow);
- сканировать отдельные элементы нельзя (указано какие) – частичный доступ.
На практике это имеет вот такой вид:
Обратите внимание, страница все равно может попасть в выдачу, если на нее установили ссылку на этом сайте или вне его.
Чтобы лучше в этом разобраться, давайте изучим синтаксис этого файла.
Синтаксис Robots.Txt
Важные моменты: что нужно всегда помнить о robots.
Семь общих терминов, которые часто встречаются на сайтах.
В самой простой форме робот имеет такой вид:
Вместе эти три строки считаются самым простым robots.txt.
Обратите внимание: в файле robots набор директив для одного пользовательского агента (поисковика) отделен от набора директив для другого разрывом строки.
В файле с несколькими директивами для поисковых систем каждый запрет или разрешение применяется только к поисковику, указанному в этом конкретном блоке строк.
Это важный момент и о нем нельзя забывать.
Если файл содержит правила, применимые к нескольким пользовательским агентам, система будет отдавать приоритет директивам, которые прописаны конкретно для указанного поисковика.
На иллюстрации выше – для MSNbot, discobot и Slurp прописаны индивидуальные правила, которые будут работать только для этих поисковиков.
Все остальные пользовательские агенты следуют общим директивам в группе user-agent: *.
Синтаксис robots.txt абсолютно не сложен.
Существуют семь общих терминов, которые часто встречаются на сайтах.
Обратите внимание – Googlebot не поддерживает эту команду, но скорость сканирования может быть вручную установлена в Google Search Console.
- Sitemap: Используется для вызова местоположения любых XML-карт, связанных с этим URL-адресом. Эта команда поддерживается только Google, Ask, Bing и Yahoo.
- Host: эта директива указывает на основное зеркало сайта, которое стоит учитывать при индексации. Его можно прописать только один раз.
- Clean-param: это команда используется для борьбы с дублированием контента при динамической адресации.
Регулярные выражения
Как разрешать и запрещать сканировать в robots.txt.
На практике файлы robots.txt могут разрастаться и становиться довольно сложными и громоздкими.
Система дает возможность использовать регулярные выражения, чтобы обеспечить требуемый функционал файла, то есть гибко работать со страницами и подпапками.
Мы только что запретили всем поисковикам сканировать и индексировать сайт целиком.
Как часто требуется такое действие?
Нечасто, но бывают случаи, когда нужно чтобы ресурс не участвовал в поисковой выдаче, а заходы производились по специальным ссылкам или через корпоративную авторизацию.
Так работают внутренние сайты некоторых фирм.
Кроме того, такая директива прописывается, если сайт находится на стадии разработки или модернизации.
Читайте также: