
Как сделать один ко многим вместо один к одному
Добавил пользователь Владимир З. Обновлено: 04.10.2024
Базы данных могут содержать таблицы, которые связаны между собой различными связями. Связь (relationship) представляет ассоциацию между сущностями разных типов.
При выделении связи выделяют главную или родительскую таблицу (primary key table / master table) и зависимую, дочернюю таблицу (foreign key table / child table). Дочерняя таблица зависит от родительской.
Для организации связи используются внешние ключи. Внешний ключ представляет один или несколько столбцов из одной таблицы, который одновременно является потенциальным ключом из другой таблицы. Внешний ключ необязательно должен соответствовать первичному ключу из главной таблицы. Хотя, как правило, внешний ключ из зависимой таблицы указывает на первичный ключ из главной таблицы.
Связи между таблицами бывают следующих типов:
Один к одному (One to one)
Один к многим (One to many)
Многие ко многим (Many to many)
Связь один к одному
Данный тип связей встречает не часто. В этом случае объекту одной сущности можно сопоставить только один объект другой сущности. Например, на некоторых сайтах пользователь может иметь только один блог. То есть возникает отношение один пользователь - один блог.
Нередко этот тип связей предполагает разбиение одной большой таблицы на несколько маленьких. Основная родительская таблица в этом случае продолжает содержать часто используемые данные, а дочерняя зависимая таблица обычно хранит данные, которые используются реже.
В этом отношении первичный ключ зависимой таблицы в то же время является внешним ключом, который ссылается на первичный ключ из главной таблицы.
Например, таблица Users представляет пользователей и имеет следующие столбцы:
UserId (идентификатор, первичный ключ)
Name (имя пользователя)
И таблица Blogs представляет блоги пользователей и имеет следующие столбцы:
BlogId (идентификатор, первичный и внешний ключ)
Name (название блога)
В этом случае столбец BlogId будет хранить значение из столбца UserId из таблицы пользователей. То есть столбец BlogId будет выступать одновременно первичным и внешним ключом.

Связь один ко многим
Это наиболее часто встречаемый тип связей. В этом типе связей несколько строк из дочерний таблицы зависят от одной строки в родительской таблице. Например, в одном блоге может быть несколько статей. В этом случае таблица блогов является родительской, а таблица статей - дочерней. То есть один блог - много статей. Или другой пример, в футбольной команде может играть несколько футболистов. И в то же время один футболист одновременно может играть только в одной команде. То есть одна команда - много футболистов.
К примеру, пусть будет таблица Articles, которая представляет статьи блога и которая имеет следующие столбцы:
ArticleId (идентификатор, первичный ключ)
BlogId (внешний ключ)
Title (название статьи)
Text (текст статьи)
В этом случае столбец BlogId из таблицы статей будет хранить значение из столбца BlogId из таблицы блогов.

Связь многие ко многим
При этом типе связей одна строка из таблицы А может быть связана с множеством строк из таблицы В. В свою очередь одна строка из таблицы В может быть связана с множеством строк из таблицы А. Типичный пример - студенты и курсы: один студент может посещать несколько курсов, и соответственно на один курс могут записаться несколько студентов.
Другой пример - статьи и теги: для одной статьи можно определить несколько тегов, а один тег может быть определен для нескольких статей.
Но в SQL Server на уровне базы данных мы не можем установить прямую связь многие ко многим между двумя таблицами. Это делается посредством вспомогательной промежуточной таблицы. Иногда данные из этой промежуточной таблицы представляют отдельную сущность.
Например, в случае со статьями и тегами пусть будет таблица Tags, которая имеет два столбца:
TagId (идентификатор, первичный ключ)
Text (текст тега)
Также пусть будет промежуточная таблица ArticleTags со следующими полями:
TagId (идентификатор, первичный и внешний ключ)
ArticleIdId (идентификатор, первичный и внешний ключ)
Технически мы получим две связи один-ко-многим. Столбец TagId из таблицы ArticleTags будет ссылаться на столбец TagId из таблицы Tags. А столбец ArticleId из таблицы ArticleTags будет ссылаться на столбец ArticleId из таблицы Articles. То есть столбцы TagId и ArticleId в таблице ArticleTags представляют составной первичный ключ и одновременно являются внешними ключами для связи с таблицами Articles и Tags.
Ссылочная целостность данных
При изменении первичных и внешних ключей следует соблюдать такой аспект как ссылочная целостность данных (referential integrity). Ее основная идея состоит в том, чтобы две таблице в базе данных, которые хранят одни и те же данные, поддерживали их согласованность. Целостность данных представляет правильно выстроенные отношения между таблицами с корректной установкой ссылок между ними. В каких случаях целостность данных может нарушаться:
Аномалия удаления (deletion anomaly). Возникает при удалении строки из главной таблицы. В этом случае внешний ключ из зависимой таблицы продолжает ссылаться на удаленную строку из главной таблицы
Аномалия вставки (insertion anomaly). Возникает при вставке строки в зависимую таблицу. В этом случае внешний ключ из зависимой таблицы не соответствует первичному ключу ни одной из строк из главной таблицы.
Аномалии обновления (update anomaly). При подобной аномалии несколько строк одной таблицы могут содержать данные, которые принадлежат одному и тому же объекту. При изменении данных в одной строке они могу прийти в противоречие с данными из другой строки.
Аномалия удаления
Для решения аномалии удаления для внешнего ключа следует устанавливать одно из двух ограничений:
Если строка из зависимой таблицы обязательно требует наличия строки из главной таблицы, то для внешнего ключа устанавливается каскадное удаление. То есть при удалении строки из главной таблицы происходит удаление связанной строки (строк) из зависимой таблицы.
Если строка из зависимой таблицы допускает отсутствие связи со строкой из главной таблицы (то есть такая связь необязательна), то для внешнего ключа при удалении связанной строки из главной таблицы задается установка значения NULL. При этом столбец внешнего ключа должен допускать значение NULL.
Аномалия вставки
Для решения аномалии вставки при добавлении в зависимую таблицу данных столбец, который представляет внешний ключ, должен допускать значение NULL. И таким образом, если добавляемый объект не имеет связи с главной таблицей, то в столбце внешнего ключа будет стоять значение NULL.
Аномалии обновления
Для решения проблемы аномалии обновления применяется нормализация, которая будет рассмотрена далее.

Если говорить о программировании ряляционных баз данных (типа MySQL), ниже для всех трех типов связи рассматривается один вопрос -- "как связать данные из двух таблиц, имеющих отношение друг другу?"
-- рассматриваются разные варианты, даются пояснения.
Связь "Один к одному"
Один к одному -- у каждой двух сущностей есть лишь один спутник и больше никто.
Ситуация из жизни:
В базе данных университета есть таблица с информацией о студентах (напр. паспортные данные) и таблицы профилей этих студентов на университетском сайте (где тоже есть несколько колонок, заполняемых по желанию).
Если один студент может завести только один аккаунт -- то мы имеем классический пример связи один к одному.
Проектирование БД:
Если для работы приложения вам требуется получать для данного студента данные его профиле на сайте университета (см. ситуацию выше) -- просто добавьте внешний ключ в таблицу "Студент" -- т.е. столбец, который будет хранить id (копию какого-нибудь уникального в рамках таблицы "Профиль" поля одного из кортежей, но обычно это копия первичного ключа таблицы) профиля для каждой записи о студенте в таблице студент.
Связь "Один ко многим"
"Один ко многим" -- это "иерархическая связь", т.е. по отношению одной сущности к другой есть множественность, а в обратную строну -- нет.
По сути является "расширением" связи типа "один к одному" (проектируется фактически так же -- см. о проектировании ниже).
Примеры из жизни:
Напр. взаимоотношения командиров в армии - -это серия таблиц, где "соседние" звания связаны как "один ко многим". Например "у одного генерала под командованием несколько полковников".
Или -- одна большая группа учеников ходит в одну школу, другая в другую -- тут "у одной школы много учеников".
Ученик не может ходить сразу в две школы (в обычной ситуации) -- а значит, в обратную сторону "от ученика к школе" множественности нет (иначе имели бы связь "многие ко многим") -- значит это "один ко многим".
Проектирование БД:
В одну из таблицы (для каждой сущности, которых "много") добавляется внешний ключ на связанную сущность, которая ("одна")
Связь "Многие ко многим"
Ситуация из жизни:
Таблица предметов и таблица студентов университета. Рассуждаем: ясно что один студент может ходить на много предметов, при этом один предмет может слушаться многими студентами -- значит, это "многие ко многим"
Проектирование БД:
Вводится дополнительная таблицы, в каждый кортеж которой входят два ключа, каждый из этих ключей указывает на одни из двух таблиц сущностей (между которыми таким образом и прокладывается связь "многие ко многим") -- см. пример SQL для связи "Многие ко многим"
Схема данных является графическим образом БД. Она используется различными объектами Access для определения связей между несколькими таблицами. Например, при создании формы, содержащей данные из нескольких взаимосвязанных таблиц, схема данных обеспечивает автоматический согласованный доступ к полям этих таблиц. Она же обеспечивает целостность взаимосвязанных данных при корректировке таблиц.
Связь между таблицами устанавливает отношения между совпадающими значениями в ключевых полях, обычно между полями, имеющими одинаковые имена в обеих таблицах. В большинстве случаев с ключевым полем одной таблицы, являющимся уникальным идентификатором каждой записи, связывается внешний ключ другой таблицы.
Обязательным условием при установлении связи является совпадение связываемых полей по типу и формату.
Типы связей
Тип отношения в создаваемой Microsoft Access связи зависит от способа определения связываемых полей.
Определение связей между таблицами

В результате в окно схемы данных будут добавлены графические образы двух таблиц:




Если перетащить поле, не являющееся ключевым и не имеющее уникального индекса, на другое поле, которое также не является ключевым и не имеет уникального индекса, создается неопределенное отношение. В запросах, содержащих таблицы с неопределенным отношением, Microsoft Access по умолчанию отображает линию объединения между таблицами, но условия целостности данных при этом не накладываются и нет гарантии уникальности записей в любой из таблиц.
Как сделать связь один ко многим в access 2010?
Статья написана в учебных целях, хотя в ней есть и пара интересных неучебных нюансов.
Сама по себе реализация такого редактора в Access несложна, вот весь процесс.
1. Создаем новую базу данных и сохраняем ее.
Обратите внимание, что оба поля я сделал ключевыми — это поможет избежать дублирования связей — например, объект 1 не должен иметь две одинаковых связи с категорией 1. Чтобы сделать оба поля ключевыми, нужно при нажатой клавише Ctrl выделить их, щелкая по области ключа, а затем вызвать правой кнопкой пункт меню.
10. В принципе, все готово. Наша форма работает, в чем можно убедиться, открыв ее кнопкой Вид
12. При выбранной кнопке в окне свойств перейдем на вкладку События и обратимся к коду сгенерированного нами обработчика:
В Интернете можно встретить советы предварительно обработать все параметры процедурой вида
Однако, для работы этого кода нужно, во-первых, иметь подключенную DAO (в окне редактора Visual Basic при остановленной программе вызвать Tools, References (или Сервис, Ссылки), найти и включить в списке библиотеку Microsoft DAO 3.6 Object Library), во-вторых, работа кода все-таки не гарантируется и в этом случае.
Мы хотим обойтись стандартным кодом
Вся проблема состоит в том, что объект RecordSet есть и в библиотеке DAO, и в используемой Access по умолчанию библиотеке ADODb! Таким образом, наличие прямой ссылки на DAO, как в показанной выше процедуре, не гарантирует работоспособность кода — может возникать куча заморочек, связанных с тем, какая библиотека подключена в данный момент и у какой выше приоритет.
Поискав (и не найдя) ответ по всему Интернету я догадался, наконец, описать RecordSet как Variant, то есть, без указания типа:
Ok так что это, вероятно, тривиальный вопрос, но у меня возникли проблемы с визуализацией и пониманием различий и когда использовать каждый. Я также немного не понимаю, как концепции, такие как однонаправленные и двунаправленные отображения, влияют на отношения "один ко многим" / "много ко многим". Я использую Hibernate прямо сейчас, поэтому любое объяснение, связанное с ORM, будет полезно.
в качестве примера предположим, что у меня есть следующая настройка:
Итак, в этом случае какой картографирования бы я? Ответы на этот конкретный пример определенно оценены, но мне также очень хотелось бы получить обзор того, когда использовать либо один ко многим и многие ко многим, и когда использовать таблицу объединения против столбца объединения и однонаправленный против двунаправленного.
один-ко-многим: один человек имеет много навыков, навык не используется повторно между людьми
- однонаправленный: человек может напрямую ссылаться на навыки через свой набор
- двунаправленный: каждый навык" ребенок " имеет один указатель на Person (который не отображается в вашем коде)
многие-ко-многим: один человек имеет много навыков, умения используют Персона(ы)
- однонаправленный: человек может напрямую ссылаться на навыки через свой набор
- двунаправленный: навык имеет набор людей, которые относятся к нему.
в отношениях "один ко многим" один объект является "родителем", а другой - "ребенком". Родитель контролирует существование ребенка. Во многих-ко-многим существование любого типа зависит от чего-то вне их обоих (в более крупном контекст приложения.)
ваш предмет (домен) должен диктовать, является ли отношение "один ко многим" или "много ко многим", однако я считаю, что однонаправленное или двунаправленное отношение-это инженерное решение, которое торгует памятью, обработкой, производительностью и т. д.
Что может быть запутанным, так это то, что двунаправленное отношение "многие ко многим" не должно быть симметричным! То есть куча людей могла бы указать на какой-то навык, но навык нужен не относиться только к этим людям. Как правило, это так, но такая симметрия не является требованием. Возьмем, к примеру, любовь-она двунаправленная ("я-люблю", "любит-меня"), но часто асимметричная ("я люблю ее, но она меня не любит")!
все они хорошо поддерживаются Hibernate и JPA. Просто помните, что Hibernate или любой другой ORM не дает ухо о поддержании симметрии при управлении двунаправленными отношениями "многие ко многим". это все зависит от приложения.
похоже, все отвечает One-to-many vs Many-to-many :
разницу между One-to-many , Many-to-one и Many-to-Many - это:
One-to-many vs Many-to-one - это вопрос перспективы. Unidirectional vs Bidirectional не повлияет на отображение, но будет иметь значение о том, как вы можете получить доступ к данным.
- на One-to-many на many сторона будет держать ссылку one стороне. Хороший пример- "у человека много навыков". В этом дело Person является одной стороной и Skill это много сторон. Будет колонка person_id в таблице skills .
на однонаправленный Person класса List skills но Skill не будет Person person . В двунаправленный как свойства добавляются, и это позволяет получить доступ к Person дали умение (то есть skill.person ).
- на Many-to-one много сторона будет нашей точкой зрения ссылка. Например, "у пользователя есть адрес". В нашей системе многие пользователи могут иметь общий адрес (например, несколько человек могут иметь один и тот же номер блока). В этом случае на users таблица будет разделена более чем одним users строк. В этом случае мы говорим, что users и addresses есть Many-to-one отношения.
на однонаправленный a User будет Address address . двунаправленный будет иметь дополнительный List users на Address класса.
- на Many-to-Many члены каждой стороны могут содержать ссылку на произвольное количество членов другой стороны. Для достижения этой таблица это. Примером тому могут служить отношения между врачами и пациентами. У врача может быть много пациентов И наоборот.
1) круги являются сущностями / POJOs / Beans
2) deg-это аббревиатура степени, как на графиках (количество ребер)
PK=первичный ключ, FK = внешний ключ
обратите внимание на противоречие между степенью и название стороны. Много соответствует степени=1, а соответствует степени >1.
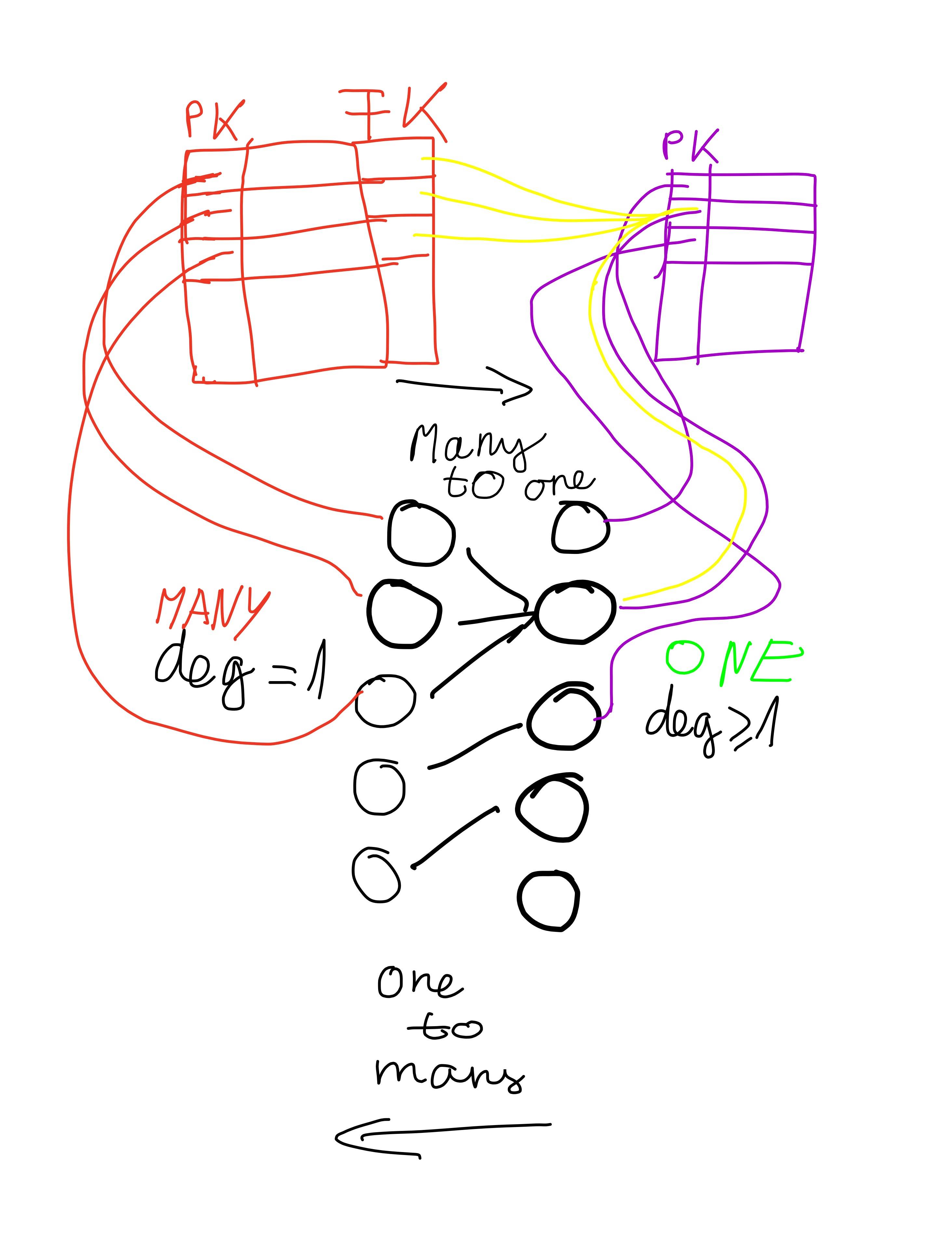
существует две категории отношений объектов,которые необходимо учитывать при сопоставлении. Первая категория основана на множественности и включает в себя три типа:
вторая категория основана на направленность и она содержит два типы, однонаправленные отношения и двухнаправленный отношения.
Это, вероятно, вызовет корабль отношений "многие ко многим" следующим образом
вам может потребоваться определить joinTable + JoinColumn, но это будет возможно также без.
прежде всего, прочитайте все мелким шрифтом. Обратите внимание, что NHibernate (таким образом, я предполагаю, Hibernate) реляционное отображение имеет забавное соответствие с отображением графов БД и объектов. Например, отношения "один к одному" часто реализуются как отношения "много к одному".
во-вторых, прежде чем мы сможем сказать вам, как вы должны написать свою карту O/R, мы также должны увидеть вашу БД. В частности, может ли один навык принадлежать нескольким людям? Если это так, у вас есть много-ко-многим отношения; в противном случае, это много-к-одному.
в-третьих, я предпочитаю не реализовывать отношения "многие ко многим" напрямую, а вместо этого моделировать "таблицу соединений" в вашей модели домена, т. е. рассматривать ее как сущность, например:
затем вы видите, что у вас есть? У вас два отношения "один ко многим". (В этом случае человек может иметь коллекцию PersonSkills, но не будет иметь коллекцию навыков.) Тем не менее, некоторые предпочтут использовать отношения "многие ко многим" (между личностью и умением); это спорно.
В-четвертых, если у вас есть двунаправленные отношения (например, не только у человека есть коллекция навыков, но и у навыка есть коллекция людей), NHibernate делает не принудительно двунаправленность в вашем BL для вас; он понимает только двунаправленность отношений для целей сохранения.
В-пятых, многие-к-одному намного проще правильно использовать в NHibernate (и я предполагаю, что Hibernate) чем один-ко-многим (сопоставление коллекция).
В предыдущей статье были изложены основы отношений (связей). Вы узнали, зачем нам нужны отношения, и как они влияют на фильтрацию нескольких таблиц. В этой статье вы узнаете об одном из наиболее важных свойств отношений, которое называется кардинальностью или мощностью связей. Целью данной статьи является понимание смысла отношений “один-к-одному”, “один-ко-многим”, “многие-к-одному” и “многие-ко-многим”.
Необходимое условие
Загрузите набор данных Pubs.xlsx для примеров этой статьи здесь .
Отношения в Power BI
Отношения Power BI дают нам возможность получать поля из нескольких таблиц и возможность фильтрации по нескольким таблицам в модели данных. Отношения основаны на поле, которое соединит две таблицы и отфильтрует одну на основе другой (или наоборот, зависит от направления). Например, мы можем отфильтровать данные по количеству таблицы Sales по состоянию в таблице Store, если между таблицами Sales и Store существует связь на основе stor_id:

И отношения между таблицами будут следующими:

Что такое мощность отношений?
Когда вы создаете отношение между двумя таблицами, вы получаете два значения, которые могут быть 1 или * на двух концах отношения между двумя таблицами, называемые кардинальностью или мощностью отношений.

Два значения 1 или * говорят о том, что поле в этой взаимосвязи имеет определенное число значения на строку в этой таблице. Давайте проверим это на примере.
В таблице Stores у нас есть одно уникальное значение для stor_id на строку.

Таким образом, если это поле участвует в одной стороне отношения, то эта сторона примет 1 в качестве показателя кардинальности, который называется ОДНОЙ стороной отношения.
Однако stor_id в таблице Sales не уникален для каждой строки данных в этой таблице. У нас есть несколько строк для каждого stor_id. Или скажем так; в каждом магазине происходит несколько торговых транзакций (что, конечно, нормально):

Итак, основываясь на том, что мы знаем в данный момент, если мы создадим отношение на основе stor_id между двумя таблицами Sales и Stores, то получим вывод:

Эти отношения могут быть прочитаны двумя способами;
Они оба, конечно, одинаковы, и они будут выглядеть точно так же, как каждое из них в представлении схемы. Теперь, когда вы знаете, что такое мощность отношений, давайте изучим все виды мощности.
Типы мощности
Есть четыре типа кардинальности, как показано ниже:
- 1-1: “один-к одному”
- 1- *: “один-ко-многим”
- * -1: “многие-к-одному”
- * - *: “многие-ко-многим”
Давайте поочередно рассмотрим каждый из этих типов.

Один-ко-многим или многие-к-одному

Есть два способа назвать эти отношения: один-ко-многим или многие-к-одному. Зависит от того, что является исходной и целевой таблицей.


Эти две таблицы заканчиваются созданием таких отношений:

В остальной части статьи мы будем использовать термины таблиц FACT и DIMENSION, которые мы объясним отдельно в другой статье. А пока вот краткое объяснение терминов:
- Таблица фактов (FACT): таблица с числовыми значениями, которые нам нужны либо в агрегированном уровне, либо в подробном выводе. Поля из этой таблицы обычно используются в качестве раздела VALUE визуальных элементов в Power BI.
- Таблица измерений (DIMENSION): таблица, содержащая описательную информацию, которая используется для нарезки данных таблицы фактов. Поля из этой таблицы часто используются в качестве слайсеров, фильтров или осей визуалов в Power BI.

Этот тип отношений, хотя часто используется во многих моделях, всегда может быть предметом исследования для лучшего моделирования. В идеальной модели данных вы НЕ должны иметь отношения между двумя таблицами измерений напрямую. Давайте проверим это на примере.
Допустим, модель отличается от того, что вы видели в этом примере: таблица Sales, таблица Product и две таблицы для информации о категории и подкатегории продукта:

Как вы можете видеть на приведенной выше диаграмме отношений, все отношения - “многие-к-одному”. Что хорошо. Однако, если вы хотите нарезать данные таблицы фактов (например, SalesAmount) по полю из таблицы DimProductCategory (например, по имени ProductCategory), для обработки потребуется три отношения:


Отношения “один-к-одному”
Отношение “один-к-одному” происходит только в одном сценарии, когда у вас есть уникальные значения в обеих таблицах на столбец. Примером такого сценария является случай, когда у вас есть таблицы Titles и Titles Details! У них обоих есть один ряд на заголовок. Так что, если мы создадим отношения, это будет выглядеть так:

Если между двумя таблицами существует взаимно-однозначное отношение, они являются хорошим кандидатом для объединения друг с другом с помощью слияния в Power Query. Поскольку обе таблицы в большинстве случаев имеют одинаковое количество строк, или даже если в одной из них меньше строк, все еще учитывающих метод сжатия механизма Power BI xVelocity, потребление памяти будет одинаковым, если вы поместите его в одну таблицу. Так что если у вас отношения “один-к-одному”, подумайте о том, чтобы серьезно объединить эти таблицы.
Было бы лучше, если бы мы объединили обе таблицы выше в одну таблицу, в которой есть все о заголовке.
Отношения “многие ко многим”: слабые отношения

Что делать, если у вас есть более одной таблицы с этим сценарием?


Лучшая модель для вышеупомянутого образца будет использовать общие размеры, как показано на этой диаграмме:

Резюме
Читайте также: