
Как сделать нейросеть в термукс
Добавил пользователь Алексей Ф. Обновлено: 05.10.2024
Если вы хотите разработать нейронную сеть на Python, вы находитесь в правильном месте. Прежде чем углубиться в обсуждение о том, как использовать Excel для создания обучающих данных для вашей нейросети, для получения дополнительной информации посмотрите остальные статьи серии выше, в меню с содержанием.
Что такое обучающие данные?
Например, предположим, что вы хотите, чтобы ваша нейронная сеть предсказывала вкусовые качества помидора на основе цвета, формы и плотности. Вы не представляете, как именно цвет, форма и плотность связаны с вкусностью, но вы можете измерить цвет, форму и плотность, и у вас есть вкусовые рецепторы. Таким образом, всё, что вам нужно сделать, это собрать тысячи и тысячи помидоров, записать их физические характеристики, попробовать каждый (лучшая часть), а затем поместить всю эту информацию в таблицу.
Каждая строка – это то, что я называю одной обучающей выборкой, и в ней четыре столбца: три из них (цвет, форма и плотность) являются столбцами входных данных, а четвертый – целевым выходным значением.

Рисунок 1 – Связь между данными в Excel и параметрами нейросети
Во время обучения нейронная сеть найдет связь (если когерентная связь существует) между тремя входными значениями и выходным значением.
Оценка обучающих данных
Следующая диаграмма показывает, как этот тип кодирования используется для классификации выходных значений нейронной сети.

Рисунок 2 – Унитарный код для выходных значений нейросети
Выходная схема, использующая унитарный код, позволяет нам определить недвоичные классификации таким образом, чтобы это было совместимо с логистической сигмоидной функцией активации. Выходные данные логистической функции являются, по сути, двоичными, поскольку область перехода на графике является узкой по сравнению с бесконечным диапазоном входных значений, для которых выходное значение очень близко к минимальному или максимальному значению:

Рисунок 3 – График логистической функции
Таким образом, мы не хотим создавать эту нейросеть с одним выходным узлом, а затем предоставлять обучающие выборки, которые имеют выходные значения 0, 1, 2, 3 или 4 (или, если вы хотите оставаться в диапазоне от 0 до 1, это будут 0, 0,2, 0,4, 0,6 или 0,8), поскольку логистическая функция активации выходного узла будет устойчиво придерживаться минимального и максимального выходных значений.
Нейронная сеть просто не понимает, насколько нелепым было бы сделать вывод, что все помидоры либо несъедобны, либо восхитительны.
Создание набора обучающих данных
Нейронная сеть на Python, о которой мы говорили в части 12, импортирует обучающие выборки из файла Excel. Обучающие данные, которые я буду использовать для этого примера, организованы следующим образом:

Рисунок 4 – Обучающие данные в таблице Excel
Как показано на скриншоте, результат рассчитывается следующим образом:
Таким образом, выходное значение равно true , только если input_0 больше нуля, input_1 больше нуля, а input_2 меньше нуля. В противном случае выходное значение равно false .
Это математическая связь вход-выход, которую перцептрон должен извлечь из обучающих данных. Вы можете создать столько выборок, сколько захотите. Для такой простой задачи, как эта, вы можете достичь очень высокой точности классификации с 5000 выборками и одной эпохой.
Обучение нейросети
Вам нужно установить входную размерность на три ( I_dim = 3, если вы используете мои имена переменных). Я настроил нейросеть так, чтобы в ней было четыре скрытых узла ( H_dim = 4), и выбрал скорость обучения 0,1 ( LR = 0,1).
Валидация нейросети
Чтобы проверить эффективность нейросети, я создаю вторую электронную таблицу и генерирую входные и выходные значения, используя точно такие же формулы, а затем импортирую эти проверочные данные так же, как импортировал обучающие данные:
В следующем фрагменте кода показано, как выполнить базовую валидацию:
Я использую стандартную процедуру прямого распространения для вычисления сигнала постактивации выходного узла, а затем использую оператор if / else для применения порогового значения, который преобразует значение постактивации в классификационное значение true / false .
Точность классификации вычисляется путем сравнения значения классификации с целевым значением для текущей выборки валидации, подсчета количества правильных классификаций и деления на количество выборок валидации.
Помните, что если вы закомментировали инструкцию np.random.seed(1) , при каждом запуске программы веса будут инициализироваться различными случайными значениями, и, следовательно, точность классификации будет меняться от одного запуска к следующему. Я выполнил 15 отдельных запусков с параметрами, указанными выше, 5000 обучающих выборок и 1000 проверочных выборок.
Самая низкая точность классификации составила 88,5%, самая высокая – 98,1%, а средняя – 94,4%.
Заключение
Мы рассмотрели важную теоретическую информацию, относящуюся к обучающим данным нейронной сети, и провели первый эксперимент по обучению и валидации нашего многослойного перцептрона на языке Python. Я надеюсь, вам интересна эта серия статей о нейронных сетях – мы добились большого прогресса со времени первой статьи, и есть еще много, что нам нужно обсудить!
К 2019 году искусственные нейронные сети стали чем-то большим, чем просто забавная технология, о которой слышали только гики. Да, среди обычных людей мало кто понимает что из себя представляют нейросети и как они работают, но проверить действие подобных систем на практике может каждый – и для этого не нужно становиться сотрудником Google или Facebook. Сегодня в Интернете существуют десятки бесплатных проектов, иллюстрирующих те или иные возможности современных ИНС, о самых интересных из них мы и поговорим.
Из 2D в 3D
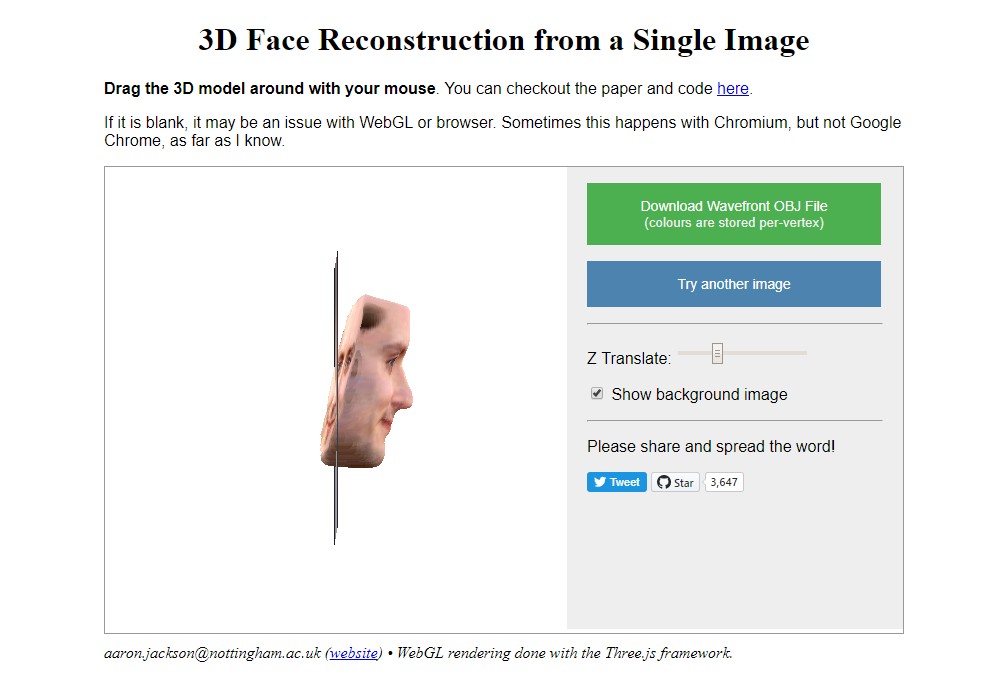
На этом сервисе вы сможете вдохнуть новую жизнь в свои старые фотографии, сделав их объемными. Весь процесс занимает меньше минуты, необходимо загрузить изображение и через несколько секунд получить 3D-модель, которую можно покрутить и рассмотреть во всех деталях. Впрочем, есть два нюанса — во-первых, фотография, должна быть портретной (для лучшего понимания требований на главной странице сайта представлены наиболее удачные образцы снимков, которые ранее загружали другие пользователи; во-вторых, детализация получаемой модельки зачастую оставляет желать лучшего, особенно, если фотография в низком разрешении. Однако авторы разрешают не только ознакомиться с результатом в окне браузера, но и скачать получившийся файл в формате obj к себе на компьютер, чтобы затем самостоятельно его доработать.
Нейминг брендов
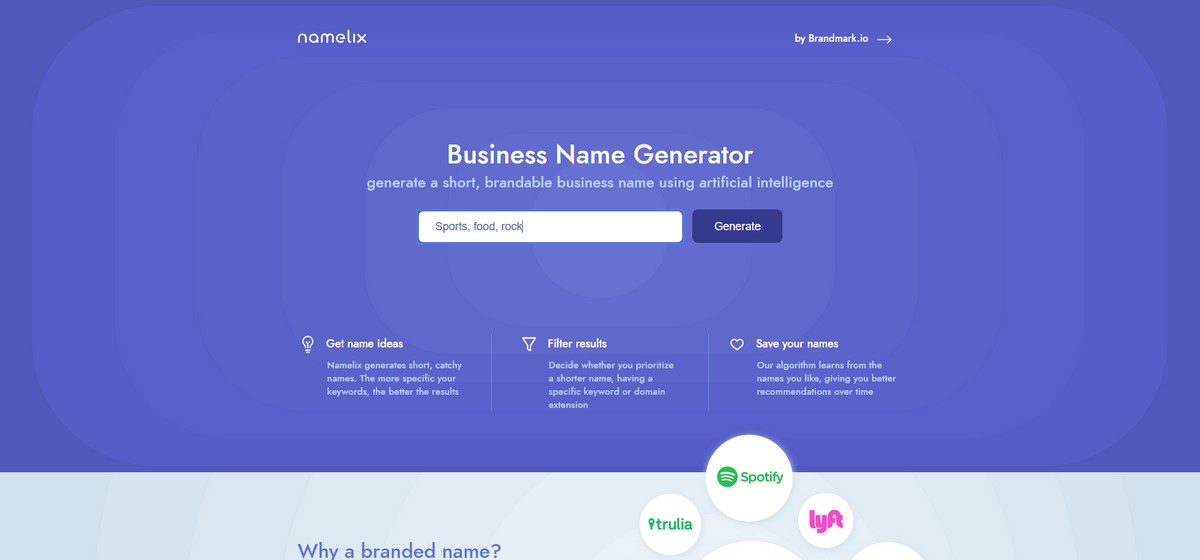
Придумали крутую идею для стартапа, но не можете определиться с именем для будущей компании? Достаточно вбить несколько ключевых слов, задать длину названия в символах и готово! В общем, больше не нужно искать на фрилансе людей, которые будут решать такой личный вопрос, как наименование дела всей вашей жизни.
Выбор досуга

Пересмотрели все интересные вам фильмы, прочли все достойные книги и не знаете чем занять вечер? Система рекомендаций от специалиста по искусственному интеллекту Марека Грибни расскажет как увлекательно и с пользой провести свободное время. Для корректной работы сервиса вас сперва попросят указать ваши любимые произведения в кинематографе, литературе, музыке или живописи.
Рай для искусствоведа
Google специально для поклонников современного (и не только) искусства запустила проект Google Arts & Culture, в котором можно подобрать произведения по вашему вкусу как от малоизвестных, так и от малоизвестных авторов. Большая часть контента здесь на английском, но если вы не дружите с языками, можно воспользоваться встроенным переводчиком.
Озвучивание картинок

Японская студия Qosmo разработала очень необычную нейросеть Imaginary Soundscape, которая воспроизводит звук, соответствующий тому или иному изображению. В качестве источника информации вы можете указать ссылку на любую картинку в Интернете, загрузить свой файл либо выбрать случайную локацию на Google Maps.
Не умеешь рисовать – тогда тебе к нам!

Если вы пробовали использовать рукописный ввод на своем смартфоне, эта нейросеть покажется вам до боли знакомой: она превращает любые каракули в аккуратные 2D-рисунки.
Генерация людей

Thispersondoesnotexist – это один самых известных AI-проектов. Нейросеть, созданная сотрудником Uber Филиппом Ваном, выдает случайное изображение несуществующего человека при каждом обновлении страницы.
Генерация… котов

Тот же автор разработал аналогичный сайт, генерирующий изображения несуществующих котов.
Быстрое удаление фона
Часто ли вам приходится тратить драгоценное время на удаление бэкграунда с фотографий? Даже если регулярно такой необходимости не возникает, следует на всякий случай знать о возможности быстрого удаления фона с помощью удобного онлайн-инструмента.
Написать стихотворение

Компания ‘Яндекс’, известная своей любовью к запуску необычных русскоязычных сервисов, имеет в своем портфолио сайт, где искусственный интеллект составляет рандомные стихотворения из заголовков новостей и поисковых запросов.
Окрашивание черно-белых фотографий

Colorize – это также российская нейросеть, возвращающая цвета старым черно-белым снимкам. В бесплатной версии доступно 50 фотографий, если вам нужно больше, можете приобрести платный аккаунт с лимитом в десять тысяч изображений.
Апскейлинг фото
Чтение текста голосом знаменитостей

Благодаря высоким технологиям, сегодня у вас есть возможность озвучить любую фразу голосом самых известных в мире людей. Все просто: пишите текст и выбираете человека (среди последних — Дональд Трамп, Тейлор Свифт, Марк Цукерберг, Канье Уэст, Морган Фриман, Сэмюель Л Джексон и другие).
Описание фотографий
Музыкальная шкатулка
Напоследок расскажем о целой пачке нейросетей от Google, первая из них – Infinite Drum Machine. Открыв страницу приложения, вы увидите своеобразную карту, на которой находятся самые разнообразные звуки. С помощью круглых манипуляторов можно изменять сочетание элементов, если получившийся набор покажется вам бессмысленным, нажмите кнопку Play в нижней части экрана и звуковая картина сложится сама собой.
Птичий хор
Если предыдущий сервис может оказаться полезным для, например, диджеев или обычных музыкантов, то польза от управления голосами десятков тысяч певчих птиц довольно сомнительна. Кстати, коллекция звуков для Bird Sounds собиралась орнитологами со всего мира на протяжении нескольких десятилетий.
Виртуальный пианист
В A. I. Duet пользователю предлагается сыграть какую-нибудь мелодию на пианино, а искусственный интеллект попробует самостоятельно закончить композицию, подобрав наиболее логичное и гармоничное продолжение.
Распознавание рисунков
Объяснение логики машинного обучения
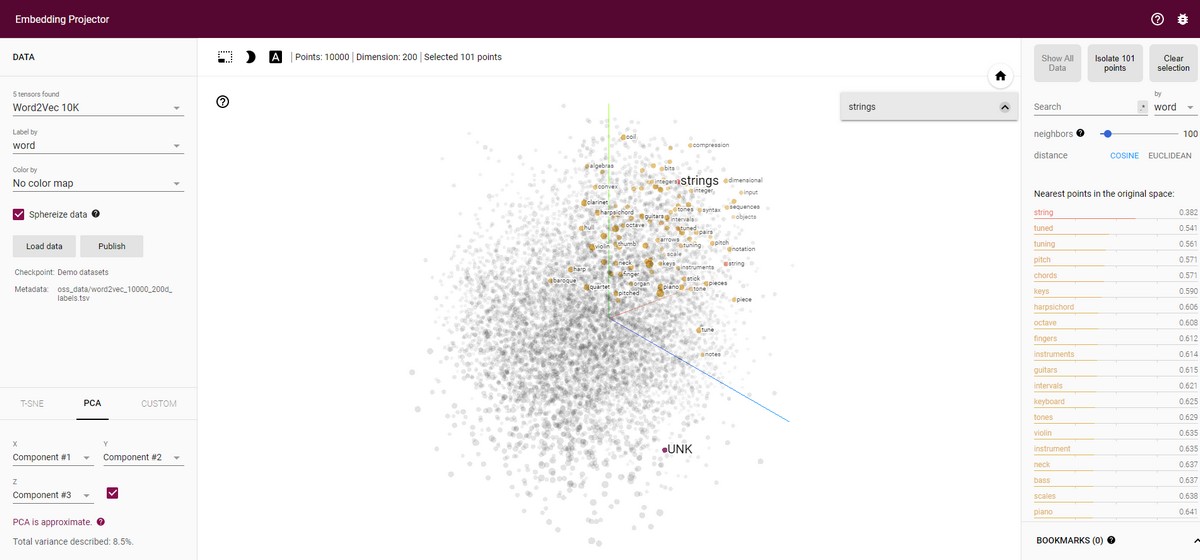
Проект Visualizing High-Dimensional Space (“Визуализация многомерного пространства”) создавался для того, чтобы объяснить простым людям и начинающим разработчикам, как работают нейросети. Когда ИИ, оперируя большими базами данных, получает информацию (например, вашу фотографию, введенную фразу или только что нарисованное изображение), он сравнивает входящие данные с теми, что у него уже есть. VHDS наглядно демонстрирует корреляцию одного лишь выбранного вами слова с миллионами аналогичных понятий.

Наличие программного пакета X-CUBE-AI, расширяющего функционал STM32CubeMX, поможет разработчику построить искусственную нейросеть на базе микроконтроллера из линейки STM32G4 производства STMicroelectronics. Статья включает пошаговое описание реализации такой нейросети.
Идея построения искусственных нейронных сетей появилась в 50-х годах прошлого века. До недавних пор практическое применение таких сетей было крайне ограничено из-за недостаточной мощности вычислительной техники. Однако успехи современной микроэлектроники позволили существенно нарастить производительность электронных устройств, благодаря чему практическое использование нейронных сетей стало возможным даже на базе компактных микроконтроллеров. В данной статье рассматривается теория и практика применения искусственных нейронных сетей с использованием микроконтроллеров семейства STM32G4 производства компании STMicroelectronics.
Немного истории
Процесс создания приложения на базе нейронной сети в микроконтроллерах STMicroelectronics состоит из пяти базовых этапов, изображенных на рисунке 1.

Рис. 1. Этапы создания нейросети
Как видно из рисунка 1, первые три этапа относятся к созданию нейросети, а четвертый и пятый – к эксплуатации.
На первом этапе происходит сбор данных для анализа. Обычно для этого используются датчики и сенсоры, которые располагаются рядом с объектом анализа и регистрируют изменения его состояния в пространстве и времени. Примерами физических величин для регистрации являются скорость, ускорение, температура, звуковые и видеохарактеристики объекта в зависимости от приложения нейросети. Компания STMicroelectronics предлагает устройства, облегчающие сбор данных, такие как платформа SensorTile, которая работает в автономном режиме и поддерживает дистанционное управление через приложение для смартфона ST BLE Sensor. SensorTile содержит датчики движения и состояния окружающей среды, микроконтроллер, разъем для подключения SD-карты и модуль Bluetooth.
Данные, полученные от сенсоров, необходимо промаркировать. Для контролируемого обучения (обучения с учителем) необходима классификация полученных данных по определенным признакам — маркерам. Например, можно классифицировать изображения по наличию или отсутствию на них человека. Такие промаркированные данные являются эталоном для обучения и проверки нейросети. Разработчики должны определить оптимальную топологию нейросети для лучшего обучения и обеспечения корректных полезных данных конечному приложению. Обычно такие задачи решаются с помощью готовых интегрированных сред программирования для глубокого обучения. У компании ST есть ряд партнеров, которые предоставляют готовые инженерные решения в области нейросетей, а также оказывают поддержку со стороны архитекторов нейронных сетей и специалистов в данной области.
Тренировка нейросети представляет собой итерационный процесс обработки эталонных наборов данных с целью минимизации критерия ошибки. Эта задача обычно выполняется с помощью готовых интегрированных сред от сторонних разработчиков. Обучение, как правило, выполняется на мощных вычислительных машинах с практически неограниченными вычислительными ресурсами и объемами памяти, что позволяет выполнить большое число итераций за короткий промежуток времени. Результатом такого процесса является предварительно обученная нейросеть. Пакет STM32Cube.AI предоставляет простой и эффективный интерфейс с наиболее популярными средами для глубокого машинного обучения, такими как Keras, Caffe, TensorFlow Lite, ONNX, PyTorch, Matlab и другими. Эти среды представляют собой открытые программные библиотеки для машинного обучения, разработанные различными компаниями с целью решения задач построения и тренировки нейронных сетей для автоматического нахождения и классификации образов, сравнимых по качеству с человеческим восприятием. Выходные данные этих сред могут быть напрямую импортированы в пакет STM32Cube.AI.
Следующий, четвертый шаг построения нейросети – преобразование предварительно обученной нейросети, сгенерированной сторонней интегрированной средой, в программный код, оптимизированный для исполнения на микроконтроллере STM32. Оптимизация подразумевает минимизацию числа вычислений и объема используемой памяти. Этот шаг очень легко выполняется с помощью пакета STM32Cube.AI, интегрированного в экосистему разработки STM32 в качестве расширения известного инструмента STM32CubeMX. Пакет STM32Cube.AI позволяет выбрать необходимый микроконтроллер для конкретной задачи, предоставляет обратную связь по производительности нейросети на базе выбранного микроконтроллера, обеспечивает проверку сети как на компьютере, так и на целевом устройстве.
Финальный, пятый шаг – это внедрение созданной нейросети в пользовательское приложение. Для решения данной задачи компания STMicroelectronics предлагает широкий набор низкоуровневых драйверов, библиотек и пользовательских приложений, собранных в один пакет программного обеспечения. Для ускорения процесса проектирования разработчики могут использовать эти шаблоны, внося в них необходимые изменения.
Метод, в котором для обучения требуются эталонные данные, называется машинным обучением. Однако существует также метод, не требующий эталонных данных для обучения, он называется глубоким обучением. В случае глубокого обучения структура искусственных нейронных сетей состоит из нескольких входных, выходных и скрытых слоев. Каждый слой содержит единицы, преобразующие входные данные в сведения, которые следующий слой может использовать для определенной прогнозируемой задачи. Благодаря этой структуре вычислительное устройство может изучать собственную обработку данных. На рисунке 2 показаны семейства микроконтроллеров STM32, поддерживающие машинное и глубокое обучение.

Рис. 2. Поддержка машинного и глубокого видов обучения
Пакет X-CUBE-AI
Пакет X-CUBE-AI, расширяющий функционал STM32CubeMX, используется на четвертом шаге построения нейронной сети (рисунок 1) и служит для преобразования предварительно обученной нейронной сети в формат, оптимизированный для выполнения на микроконтроллере.
X-CUBE-AI также позволяет на этапе создания проекта выбрать микроконтроллеры, подходящие для выбранной нейросети по определенным ресурсам, таким как размер памяти RAM или Flash. Этот пакет позволяет сгенерировать три типа проектов:
- проект оценки системной производительности выполняется на микроконтроллере семейства STM32 и позволяет точно оценить объем используемой памяти и нагрузку вычислительного модуля;
- проверочный проект позволяет оценить результаты, полученные от нейросети с использованием в качестве входных данных набора случайных чисел и пользовательского набора тестовых данных. Проект может исполняться как на компьютере, так и на микроконтроллере;
- шаблон приложения позволяет быстро создавать приложения с элементами искусственного интеллекта (далее по тексту – ИИ).
На рисунке 3 показано ядро системы X-CUBE-AI.

Рис. 3. Ядро системы X-CUBE-AI
Это ядро обеспечивает конвертацию нейросети в модель на языке С для использования во встроенных приложениях с ограниченными ресурсами аппаратного обеспечения. Сгенерированная библиотека нейросети (общая и специализированная части) может быть напрямую встроена в среду разработки. Для создания пользовательских приложений также экспортируется интерфейс API. Все функции ядра X-CUBE-AI доступны через интерфейс командной строки на уровне консоли. Упрощенный интерфейс конфигурации, доступный через графическую оболочку, содержит несколько параметров:
- имя сгенерированной модели на С;
- коэффициент сжатия для уменьшения размера модели;
- возможность для семейства STM32 выбрать оптимальную библиотеку.
На рисунке 4 показан основной функционал, который поддерживается импортируемой моделью нейросети и целевой платформой.

Рис. 4. Обзор X-CUBE-AI
Поддерживаются только простые массивы входных и выходных данных:
Сгенерированные модели на С полностью оптимизированы для ядер STM32 Arm Cortex–M4/M7 c FPU и DSP.
Ниже – в практической части статьи – будет описан пример с использованием модели Keras. Keras – это библиотека глубокого обучения, представляющая собой высокоуровневый API, написанный на Python. Она позволяет легко и быстро создавать прототипы благодаря удобству в работе, модульности и масштабированию. Keras поддерживает сверточные, рекуррентные сети и их комбинации, может работать как на процессоре общего назначения (CPU), так и на графическом процессоре (GPU).

Рис. 5. Процесс квантования
X-CUBE-AI является частью пакета STM32CubeMX, который используется для быстрой конфигурации микроконтроллеров STM32. STM32CubeMX позволяет с помощью графического пользовательского интерфейса создать полноценный проект для среды разработки, например, STM32CubeIDE, включая возможность генерации инициализационного кода на С для периферии, выводов, тактовых сигналов и других устройств. Структура STM32CubeMX показана на рисунке 6.

Рис. 6. Структура STM32CubeMX
Пример использования экосистемы X-CUBE-AI
В данном разделе рассмотрен практический пример проектирования нейронной сети на базе отладочной платы NUCLEO-G474RE.
Внешний вид платы показан на рисунке 7.

Рис. 7. Внешний вид платы NUCLEO-G474RE
Эта плата содержит микроконтроллер STM32G474RET6 в корпусе с 64 выводами. Максимальная частота ядра процессора – 170 МГц, объем Flash-памяти – 512 кбайт, объем статической памяти – 128 кбайт. Также плата содержит встроенный высокоскоростной отладчик/программатор ST-LINK/V3, что позволяет производить программирование и отладку платы без использования каких-либо внешних отладочных средств.
Микроконтроллеры семейства STM32G4 обладают высокой производительностью и богатым набором периферийных устройств. Также производитель предлагает широкий набор программных и отладочных средств для разработки, в том числе решений в области нейронных сетей, поэтому представитель именно этого семейства был выбран для практического рассмотрения.
Для загрузки модели нейросети переходим по ссылке, указанной выше, и в окне проекта кликаем мышкой на файл model.h5, как это показано на рисунке 8.

Рис. 8. Выбор модели нейросети

Рис. 9. Загрузка файла модели
Для программирования отладочной платы необходимо установить программное обеспечение. Для начала нужно установить STM32CubeMX версии 5.1.0 или новее. На момент написания статьи самой свежей является версия программы 6.0.0. STM32CubeMX доступен как для операционной системы Windows, так и для Linux. Заодно можно скачать пакет расширения X-CUBE-AI и среду STM32CubeIDE, которая будет необходима для компиляции сгенерированного кода.
После установки STM32CubeMX пакет X-CUBE-AI устанавливается следующим образом.

Рис. 10. Выбор встроенных пакетов в STM32CubeMX

Рис. 11. Установка X-CUBE-AI в STM32CubeMX
Если X-CUBE-AI уже был установлен, желательно удалить его перед новой установкой.

Рис. 12. X-CUBE-AI в STM32CubeMX

Рис. 13. Выбор отладочной платы NUCLEO-G474RE в STM32CubeMX

Рис. 14. Инициализация проекта

Рис. 15. Запуск проекта
Выводы контроллера также автоматически сконфигурированы согласно трассировке отладочной платы NUCLEO-G474RE.

Рис. 16. Настройка тактовой частоты

Рис. 17. Настройки порта UART
Рис. 18. Выбор модуля X-CUBE-AI
Существует несколько типов приложений, которые можно выбрать:
- System performance – для проверки производительности реализаций различных нейросетей на целевой платформе;
- Validation – для проверки производительности нейросетей и сравнения результатов вычислений;
- Application template – шаблон, позволяющий создавать пользовательские приложения. Этот тип приложения используется в данном примере и также позволяет оценить производительность и сравнить результаты вычислений.

Рис. 19. Расчет вычислительных ресурсов
Коэффициент сжатия 8 был выбран из-за ограниченного объема памяти, так как модель с коэффициентом 4 уже не вместилась бы во Flash-память выбранного микроконтроллера.
Далее необходимо проверить, насколько точно код, сгенерированный для микроконтроллера, соответствует оригинальной модели нейросети. Для этого существует два вида тестов: на компьютере и на устройстве STM32 (рисунок 20).

Рис. 20. Виды проверки нейросети
Модель нейросети, сгенерированная на языке С, запускается на выполнение на процессоре х86 или STM32, и результат выполнения сравнивается с оригинальной моделью. При ошибке L2 меньше 0,01 результат построения С-модели считается успешным. Большое влияние на ошибку оказывает степень сжатия.

Рис. 21. Результат проверки модели на компьютере
Ошибка L2 = 5,01e-07, что значительно меньше допустимой погрешности 0,01. Также виден процент использования вычислительных ресурсов разными слоями нейросети.

Рис. 22. Настройка проверки модели в STM32
Имя порта зависит от операционной системы. В данном примере использовалась система Ubuntu18.04, где порт для связи с отладочной платой получил автоматическое название /dev/ttyACM0. В операционной системе Windows это будут названия типа COM1, COM2 и так далее. Скорость 115200 соответствует настройкам проекта. Для проверки модели в микроконтроллере необходима среда (Toolchain/IDE) для компиляции исходных кодов, сгенерированных с помощью STM32CubeMX. В данном случае для компиляции используется среда STM32CubeIDE, которая была предварительно установлена на компьютер.

Рис. 23. Результат выполнения теста в STM32
Ошибка L2 в этом случае также значительно меньше 0,01, а значит модель, сгенерированная для микроконтроллера STM32, соответствует оригинальной.
Подведем итог
Искусственные нейронные сети достаточно сложны в реализации. Для их практического применения очень важны инструменты, облегчающие и ускоряющие процесс создания прикладных приложений с их использованием. Компания STMicroelectronics предлагает широкий набор программных инструментов, значительно облегчающих процесс создания приложений на базе искусственных нейросетей. В совокупности с аппаратными отладочными средствами это позволяет значительно сократить цикл разработки устройств и в кратчайшие сроки получить конкурентоспособный продукт. Специалисты компании КОМПЭЛ всегда рады помочь в выборе правильных ресурсов и инструментов для решения задач построения нейросетей на базе микроконтроллеров семейства STM32G4.
Сервис предназначен для создания уникальных обоев для смартфона, но в соцсетях его применяют для иллюстраций к книгам, комиксам и диссертациям.
В 2021 году набрали популярность десятки разных программ и приложений, позволяющих при помощи нейросетей генерировать картинки с нуля по текстовому описанию или заданной тематике. В начале декабря в твиттере обратили внимание на очередной похожий сервис — нейросеть Dream.
В отличие от других программ, результат генерации Dream кажется более абстрактным, зато выделяется за счёт доступного интерфейса, скорости обработки запроса и набора из 11 стилей: пастель, фэнтези, мистика, стимпанк и другие. Эти опции позволяют получить визуально красивый образ, даже если искусственный интеллект не смог точно воспроизвести запрос.
Формат изображения выбрать нельзя — генерируется только вертикальный прямоугольник, подходящий под экраны смартфонов. Сервис доступен не только в браузере, но и в виде приложения на Android и iOS, что позволяет быстро создавать уникальные обои прямо на устройстве.
Из-за доступности сервиса в твиттере не только стали тестировать его работу на собственных запросах, но и устроили полноценные флешмобы, в которых визуализировали ники, описания профилей, мемы или темы своих докторских диссертаций.

ИИ уже успел достаточно нашуметь — о нейросетях сейчас знают и в научной среде, и в бизнесе. Вам наверняка случалось читать, что совсем скоро ваши рабочие процессы уже не будут прежними из-за какой-нибудь формы ИИ или нейросети. И вы, я уверен, слышали (пусть и не всё) о глубоких нейронных сетях и глубоком обучении.
В этой статье я приведу самые короткие, но эффективные способы понять, что такое глубокие нейронные сети, а также расскажу о том, как внедрить их с помощью библиотеки PyTorch.
Определение глубоких нейросетей (глубокого обучения) для новичков
Попытка 1
Глубокое обучение — это подраздел машинного обучения в искусственном интеллекте (ИИ), алгоритмы которого основаны на биологической структуре и функционировании мозга и призваны наделить машины интеллектом.
Сложно звучит? Дава й те разобьём это определение на отдельные слова и составим более простое объяснение. Начнём с искусственного интеллекта, или ИИ.

Искусственный интеллект (ИИ) в наиболее широком смысле — это разум, встроенный в машину. Обычно машины глупые, поэтому, чтобы сделать их умнее, мы внедряем в них интеллект — в результате машина может самостоятельно принимать решения. К примеру, стиральная машина определяет необходимый объём воды, а также требуемое время для замачивания, стирки и отжима. Таким образом, она принимает решение, основываясь на конкретных вводных условиях, а значит делает свою работу разумнее. Или, например, банкомат, который выдаёт нужную вам сумму, составляя правильную комбинацию из имеющихся в нём банкнот. Такой интеллект внедряется в машины искусственным путём — отсюда и название “искусственный интеллект”.
Важно отметить, что интеллект здесь запрограммирован явно, то есть создан на основе подробного списка правил вида “если…, то…”. Инженер-проектировщик тщательно продумал все возможные комбинации и создал систему, которая принимает решения, проходясь по цепочке правил. А что если нам нужно внедрить интеллект в машину без явного программирования, то есть, чтобы машина училась сама? Здесь-то мы и подходим к теме машинного обучения.
Машинное обучение — это процесс внедрения интеллекта в систему или машину без явного программирования.
- Эндрю Ын, адъюнкт-профессор Стэнфордского университета
Примером машинного обучения могла бы стать система, предсказывающая результат экзамена на основе предыдущих результатов и характеристик студента. В этом случае решение о том, сдаст студент экзамен или нет, основывалось бы не на подробном списке всех возможных правил — напротив, система обучалась бы сама, отслеживая паттерны в предыдущих наборах данных.
Теперь давайте вновь взглянем на определение глубокого обучения.
Попытка 2
Глубокое обучение — это раздел машинного обучения и искусственного интеллекта с алгоритмами, основанными на деятельности человеческого мозга и призванными внедрить интеллект в машину без явного программирования.
Стало гораздо понятнее, правда? :)
Там, где машинное обучение не справлялось, глубокое обучение применялось успешно. С течением времени проводились дополнительные исследования и эксперименты, позволившие понять, для каких ещё задач мы можем задействовать глубокое обучение и получать качественные результаты при достаточном объёме данных. Глубокое обучение стали широко использовать для решения прогностических задач, не ограничивая его применение машинным распознаванием образов, речи и т. п.
Какие задачи глубокое обучение решает сегодня?
С появлением экономически эффективных вычислительных мощностей и накопителей данных глубокое обучение проникло во все цифровые аспекты нашей повседневной жизни. Вот несколько примеров цифровых продуктов из обычной жизни, в основе которых лежит глубокое обучение:
- популярные виртуальные помощники Siri/Alexa/Google Assistant;
- предложение отметить друга на только что загруженной фотографии в Facebook;
- автономное вождение в автомобилях Tesla;
- фильтр с кошачьими мордами в Snapchat;
- рекомендации в Amazon и Netflix;
- недавно выпущенные, но получившие вирусную популярность приложения для обработки фото — FaceApp и Prisma.
Возможно, вы уже пользовались приложениями с применением глубокого обучения и просто не знали об этом.
Глубокое обучение проникло буквально во все отрасли. К примеру, в здравоохранении с его помощью диагностируют онкологию и диабет, в авиации — оптимизируют парки воздушных судов, в нефтегазовой индустрии— проводят профилактическое техобслуживание оборудования, в банковской и финансовой сферах — отслеживают мошеннические действия, в розничной торговле и телекоммуникациях — прогнозируют отток клиентов и т. д. Эндрю Ын верно назвал ИИ новым электричеством: подобно тому, как электричество в своё время изменило мир, ИИ также изменит практически всё в ближайшем будущем.
Из чего состоит глубокая нейронная сеть?
Упрощённая версия глубокой нейросети может быть представлена как иерархическая (слоистая) структура из нейронов (подобно нейронам в мозге), связанных с другими нейронами. На основе входных данных одни нейроны передают команду (сигнал) другим и таким образом формируют сложную сеть, которая обучается с помощью определённого механизма обратной связи. На диаграмме ниже изображена глубокая нейронная сеть с количеством слоёв N.

Как видно на рисунке выше, входные данные передаются нейронам на первом (не скрытом) слое, они в свою очередь передают выходные данные нейронам на следующем слое и так далее до финального выхода. Выход может представлять собой прогноз (вроде “Да”/“Нет”), представленный через вероятность. На каждом слое может быть один или множество нейронов, каждый из которых вычисляет небольшую функцию, функцию активации. Эта функция имитирует передачу сигнала последующим, связанным с предыдущими, нейронам. Если результат входных нейронов превышает порог, выходное значение просто игнорируется и передаётся дальше. Связь между двумя нейронами соседних слоёв имеет вес. Вес определяет влияние входных данных на выход для следующего нейрона и последующий финальный выход. Начальные веса нейросети случайные, однако в процессе обучения модели они постоянно обновляются и обучаются предсказывать верное выходное значение. В процессе анализа нейросети можно обнаружить несколько логических структурных элементов (нейрон, слой, вес, вход, выход, функция активации и наконец механизм обучения, или оптимизатор), которые помогают ей постепенно заменять веса (изначально со случайными значениями) на более подходящие для точного прогноза выхода.
Для более ясного понимания давайте рассмотрим, как человеческий мозг учится различать людей. Когда вы встречаете человека во второй раз, то узнаёте его. Как так получается? У всех людей схожее строение: два глаза, два уха, нос, губы и т. д. Все одинаково устроены, и, тем не менее, различать людей нам довольно легко, не так ли?
Природа процесса обучения человеческого мозга довольно очевидна. Вместо того чтобы для узнавания людей изучать структуру лица, мы изучаем отклонения от типичного лица, то есть то, насколько сильно отличаются глаза конкретного человека от типичного глаза. Далее эта информация преобразуется в электрический сигнал определённой силы. Подобным же образом изучаются отклонения всех остальных частей лица от типичных. Все эти отклонения в итоге собираются в новые признаки и дают выходное значение. Всё описанное происходит за доли секунды, и мы просто не успеваем понять, что произошло в нашем подсознании.
Теперь, когда структура нейросетей понятна, давайте разберёмся, как происходит обучение. Из входных данных, которые мы предоставляем сети, на выходе получается прогноз (с серией матричных умножений), который может быть верным или неверным. В зависимости от выхода мы можем потребовать от сети более точных прогнозов, и система будет обучаться, меняя значения весов для нейронных связей. Чтобы правильно дать сети обратную связь и определить следующий шаг для внесения изменений, мы используем элегантный математический алгоритм “обратного распространения ошибок”. Повторение процесса шаг за шагом несколько раз с нарастающим объёмом данных позволяет нейросети обновлять веса соответствующим образом и создаёт систему, в которой сеть может делать прогноз на основе созданных ею через веса и связи правил.
Название “глубокие нейронные сети” пошло от использования множества скрытых слоёв, которые и делают нейросеть “глубокой”, способной обучаться более сложным паттернам. Истории успешного применения глубокого обучения только-только начали появляться в последние годы, ведь процесс обучения нейронной сети сложный по части вычислений и требует больших объёмов данных. Эксперименты наконец увидели свет, только когда возможности вычисления и хранения данных стали более доступными.
Какие есть популярные фреймворки для глубокого обучения?
Учитывая то, что внедрение глубокого обучения прошло быстрыми темпами, прогресс экосистемы для него также стал феноменальным. Благодаря множеству крупных технологических компаний и проектов с открытым исходным кодом вариантов для выбора более чем достаточно. Эти фреймворки глубокого обучения предоставляют блоки кода для многократного использования, из которых можно составить описанные выше логические блоки, а также несколько удобных дополнительных модулей для создания модели глубокого обучения.
Все доступные варианты фреймворков глубокого обучения можно разделить на низкоуровневые и высокоуровневые. Пусть такая терминология и не принята в этой области, но мы можем использовать это разделение, чтобы облегчить себе понимание фреймворков. Низкоуровневые фреймворки предлагают более базовый функционал для абстракции, который в то же время даёт массу возможностей для кастомизации и трансформации. Высокоуровневые фреймворки упрощают нам работу своей более продвинутой абстракцией, но ограничивают нас во внесении изменений. Высокоуровневые фреймворки используют низкоуровневые на бэкенде и в процессе работы конвертируют источник в желаемый низкоуровневый фреймворк для выполнения. Ниже приведены несколько вариантов популярных фреймворков для глубокого обучения.
Низкоуровневые фреймворки:
Высокоуровневые фреймворки:
- Keras (использует TensorFlow на бэкенде)
- Gluon (использует MxNet на бэкенде)
Самый популярный сейчас фреймворк — TensorFlow от Google. Keras также довольно популярен благодаря быстрому прототипированию моделей глубокого обучения и, следовательно, упрощению работы. PyTorch от Facebook — ещё один фреймворк, который стремительно догоняет конкурентов. PyTorch может стать прекрасным выбором для многих специалистов по ИИ: он затрачивает меньше времени на обучение, чем TensorFlow, и может легко применяться на всех этапах создания модели глубокого обучения — от прототипирования до внедрения.
В этом руководстве для внедрения небольшой нейросети мы предпочтём именно PyTorch. Но прежде чем сделать свой выбор фреймворка изучите и другие варианты. В этой статье (eng) приводится отличное сравнение и детальное описание разных фреймворков — это поможет вам в выборе. Однако в ней нет введения в PyTorch — для этого я рекомендую ознакомиться с официальной документацией.
Создание небольшой нейронной сети с PyTorch
Вкратце изучив тему, мы можем приступить к созданию простой нейронной сети с помощью PyTorch. В этом примере мы генерируем набор фиктивных данных, которые имитируют сценарий классификации с 32 признаками (колонки) и 6000 образцов (строки). Набор данных обрабатывается с помощью функции randn в PyTorch.
Этот код вы также можете найти на Github.
Заключение
Целью этой статьи было вкратце познакомить новичков с глубокими нейросетями, объяснив тему простым языком. Упрощение математических расчётов и полное сосредоточение на функциональности позволит максимально эффективно использовать глубокое обучение для современных бизнес-проектов.
Читайте также: