
Как сделать логирование c
Добавил пользователь Алексей Ф. Обновлено: 20.09.2024
Людям свойственно ошибаться. Это относится не только к разработчикам, но и к пользователям. В ходе разработки мы контролируем процесс и можем разобраться в неправильном поведении программы простой отладкой. А вот расследовать случай, который произошёл в production-окружении, не всегда просто. В таких ситуациях на помощь приходят журналы. И чтобы от них действительно была польза, их нужно вести правильно.
Логирование — это процесс ведения таких журналов. Помогает обнаружить скрытые ошибки, разобраться в проблемах пользователей и просто понять, что произошло на самом деле. В простейшей реализации такие журналы пишутся в текстовом файле и содержат точное время и описание произошедшего события. В логировании есть множество подходов и давно определены лучшие практики — это хорошо для нас.
В этой статье разберёмся, как правильно организовать ведение журналов в PHP-приложении, как эффективно с ними взаимодействовать и какие библиотеки и инструменты могут быть полезны.
Стандарт PSR-3. Уровни логирования
PSR — это свод рекомендаций для PHP-разработчиков. Он содержит советы по оформлению кода, некоторые интерфейсы и другие рекомендации. Один из его документов (PSR-3) посвящён реализации логера.
Знакомство с этими рекомендациями предлагаю начать с уровней логирования, которые в них предлагаются.
- DEBUG — отладочная информация, подробно раскрывающая детали события;
- INFO — любые интересные события. Например, когда пользователь авторизовался;
- NOTICE — важные события в рамках ожидаемого поведения;
- WARNING — исключительные ситуации, не являющиеся ошибками. Например, использование устаревшего метода, неправильный запрос в API;
- ERROR — ошибки, которые следует отслеживать, но они не требуют срочного исправления;
- CRITICAL — критическое состояние или событие. Например, недоступность компонента, неожиданное исключение (Exception);
- ALERT — ошибка или событие, требующие срочных действий. Например, когда база данных недоступна;
- EMERGENCY — ситуация, когда программа или система полностью выведены из строя.
Чтобы использовать эти уровни, достаточно добавлять их название к строке каждой записи журнала. Например:
На уровни ALERT и EMERGENCY часто ставят дополнительное информирование, например по SMS. По INFO можно легко восстановить последовательность действий пользователя, по DEBUG — узнать точные значения переменных, результат работы функции в определённом месте и прочее.
PSR-3. Интерфейс для класса-логера
Помимо класса с уровнями, PSR-3 предлагает нам интерфейс для реализации собственных логеров — LoggerInterface. Соблюдать его очень полезно, так как большинство существующих библиотек его поддерживает. Если вы решите заменить свой логер на другой, просто подключите вместо него новый класс.
LoggerInterface требует реализации методов ведения журнала — и чтобы она учитывала уровни, которые мы разобрали выше. Создадим собственный класс-логер, который будет соответствовать этому интерфейсу и делать записи в файл.
Для начала загрузим код стандарта PSR-3 с помощью Composer.
В загруженном пакете содержится несколько классов, трейтов и интерфейсов. Среди них — LogLevel, который мы разобрали выше, и интересующий нас в данный момент LoggerInterface. Давайте создадим новый класс, реализующий этот интерфейс. Важно: убедитесь, что у вас подключён класс-автозагрузчик (vendor/autoload.php).
Класс мы создали. Но чтобы он удовлетворял требованиям стандарта, нужно написать все методы, описанные в интерфейсе. Самый важный из них — log. В нём будет указана основная логика записи в файл.
Для полного удовлетворения интерфейса LoggerInterface нам осталось написать реализацию для методов emergency, alert, critical, error, warning, notice, info и debug, которые соответствуют уровням (их мы разобрали выше). Их реализация сводится к очень простому принципу: мы вызываем метод log, передав в него необходимый уровень.
Использование логера
Теперь, когда наш класс реализует интерфейс, предложенный стандартом PSR-3, мы можем легко задействовать его в любом месте. Например, в файле index.php:
Или в любом другом классе.
Обратите внимание: в качестве типа аргумента конструктора мы указываем не конечную реализацию (FileLogger), а именно интерфейс стандарта PSR-3. Это удобно, потому что позволяет легко заменять применяемый логер на любой другой, поддерживающий этот интерфейс.
Контекст
Вы могли заметить, что все методы интерфейса LoggerInterface содержат аргумент $context. Зачем он нужен?
Контекст предназначен для передачи вспомогательной и зачастую динамичной информации. Например, если вы делаете отладочную запись (уровень debug), можно передать в контекст значение переменной.
Чтобы применять этот аргумент, нам нужно поддержать его в методе log. Давайте доработаем его, учитывая, что $context — массив.
Теперь в любом месте вызова логера мы можем передать вторым аргументом массив дополнительной информации.
В результате мы получим запись следующего вида:
Библиотека Monolog
Несмотря на всю простоту принципа ведения журналов, в этой области широкий простор для модификаций. Мы могли бы поддержать другие форматы записей, реализовать отправку SMS или элементарно дать возможность менять имя конечного файла логов.
Здорово, что всё это уже реализовано в большинстве библиотек. Одна из самых распространённых – monolog.
Среди весомых преимуществ этого пакета:
- полная поддержка PSR-3;
- поддержка разных принципов обработки логов в зависимости от уровня;
- поддержка имён каналов (имена логеров);
- очень широкая поддержка фреймворков.
Чтобы начать использовать этот прекрасный инструмент, установим его с помощью Composer.
Использование Monolog
Работа библиотеки monolog основывается на обработчиках. Они позволяют задавать конкретное поведение в ответ на события логирования. Например: запись в файл — это специальный обработчик, который называется StreamHandler. Давайте заменим использование нашего класса на загруженную библиотеку.
Если мы запустим этот код, в файле gb.log появится запись следующего вида:
Очень похоже на то, что было у нас ранее, кроме добавления имени канала (gb-demo).
Важная особенность обработчиков monolog: им можно задать уровень, на котором они работают. Например, чтобы писать все ошибки в отдельный файл.
Подключённый на уровень ERROR обработчик будет принимать на себя все записи уровня ERROR и выше. Поэтому вызов метода emergency попадает в оба файла: gb.log и errors.log
Такое простое разделение записей по уровням значительно упрощает для нас реагирование на ошибки. Ведь больше не нужно искать их среди всех записей в журнале. Это простая и полезная функция.
Все записи от одного запроса
Когда мы разрабатываем проект, журналы читаются очень просто, они последовательны и ясны. Но когда продуктом пользуются несколько человек, логи могут перемешиваться и больше запутывать, чем помогать. Для решения этой проблемы есть простой трюк. Вместо имени канала (логера) используйте уникальный идентификатор сессии. Получить его можно с помощью встроенной функции session_id(). При этом сессия должна быть обязательно запущена с помощью session_start()
Рассмотрим пример реализации такого приёма:
Что нам даёт такая простая доработка? Важную возможность — группировать все записи запросам пользователя.
Что дальше?
Monolog поддерживает множество полезных готовых обработчиков, на которые стоит обратить внимание:
- TelegramBotHandler — отправляет записи в Telegram от имени бота. Пригодится для высоких уровней логирования;
- SlackHandler — похож на предыдущий, но отправляет записи в Slack;
- SwiftMailerHandler — позволяет отправлять записи по email;
- ChromePHPHandler – даёт доступ к журналам прямо из браузера Chrome в режиме Live.
Заключение
Логирование поможет исправлять ошибки на ранних этапах разработки и быть уверенными, что ничего не сломалось в новой версии кода. А ещё расследовать случаи ваших пользователей и иметь общее видение проекта.
Главное — помнить простые правила:
- Следование PSR-3 позволит легче заменять классы-логеры в вашем коде и использовать внешние библиотеки.
- Разные уровни логирования помогут сосредоточиться на важном.
- Отделение динамической информации в контекст упростит поиск по журналам.
- Библиотека Monolog реализует практически все возможные хотелки. Обязательно изучите её.
- С помощью идентификатора сессии можно разделить записи в журналах по каждому запросу.
- Лучше писать много лишних логов, чем не дописать один важный.

Людям свойственно ошибаться. Это относится не только к разработчикам, но и к пользователям. В ходе разработки мы контролируем процесс и можем разобраться в неправильном поведении программы простой отладкой. А вот расследовать случай, который произошёл в production-окружении, не всегда просто. В таких ситуациях на помощь приходят журналы. И чтобы от них действительно была польза, их нужно вести правильно.
Логирование — это процесс ведения таких журналов. Помогает обнаружить скрытые ошибки, разобраться в проблемах пользователей и просто понять, что произошло на самом деле. В простейшей реализации такие журналы пишутся в текстовом файле и содержат точное время и описание произошедшего события. В логировании есть множество подходов и давно определены лучшие практики — это хорошо для нас.
В этой статье разберёмся, как правильно организовать ведение журналов в PHP-приложении, как эффективно с ними взаимодействовать и какие библиотеки и инструменты могут быть полезны.
Стандарт PSR-3. Уровни логирования
PSR — это свод рекомендаций для PHP-разработчиков. Он содержит советы по оформлению кода, некоторые интерфейсы и другие рекомендации. Один из его документов (PSR-3) посвящён реализации логера.
Знакомство с этими рекомендациями предлагаю начать с уровней логирования, которые в них предлагаются.
- DEBUG — отладочная информация, подробно раскрывающая детали события;
- INFO — любые интересные события. Например, когда пользователь авторизовался;
- NOTICE — важные события в рамках ожидаемого поведения;
- WARNING — исключительные ситуации, не являющиеся ошибками. Например, использование устаревшего метода, неправильный запрос в API;
- ERROR — ошибки, которые следует отслеживать, но они не требуют срочного исправления;
- CRITICAL — критическое состояние или событие. Например, недоступность компонента, неожиданное исключение (Exception);
- ALERT — ошибка или событие, требующие срочных действий. Например, когда база данных недоступна;
- EMERGENCY — ситуация, когда программа или система полностью выведены из строя.
Чтобы использовать эти уровни, достаточно добавлять их название к строке каждой записи журнала. Например:
На уровни ALERT и EMERGENCY часто ставят дополнительное информирование, например по SMS. По INFO можно легко восстановить последовательность действий пользователя, по DEBUG — узнать точные значения переменных, результат работы функции в определённом месте и прочее.
PSR-3. Интерфейс для класса-логера
Помимо класса с уровнями, PSR-3 предлагает нам интерфейс для реализации собственных логеров — LoggerInterface. Соблюдать его очень полезно, так как большинство существующих библиотек его поддерживает. Если вы решите заменить свой логер на другой, просто подключите вместо него новый класс.
LoggerInterface требует реализации методов ведения журнала — и чтобы она учитывала уровни, которые мы разобрали выше. Создадим собственный класс-логер, который будет соответствовать этому интерфейсу и делать записи в файл.
Для начала загрузим код стандарта PSR-3 с помощью Composer.
В загруженном пакете содержится несколько классов, трейтов и интерфейсов. Среди них — LogLevel, который мы разобрали выше, и интересующий нас в данный момент LoggerInterface. Давайте создадим новый класс, реализующий этот интерфейс. Важно: убедитесь, что у вас подключён класс-автозагрузчик (vendor/autoload.php).
Класс мы создали. Но чтобы он удовлетворял требованиям стандарта, нужно написать все методы, описанные в интерфейсе. Самый важный из них — log. В нём будет указана основная логика записи в файл.
Для полного удовлетворения интерфейса LoggerInterface нам осталось написать реализацию для методов emergency, alert, critical, error, warning, notice, info и debug, которые соответствуют уровням (их мы разобрали выше). Их реализация сводится к очень простому принципу: мы вызываем метод log, передав в него необходимый уровень.
Использование логера
Теперь, когда наш класс реализует интерфейс, предложенный стандартом PSR-3, мы можем легко задействовать его в любом месте. Например, в файле index.php:
Или в любом другом классе.
Обратите внимание: в качестве типа аргумента конструктора мы указываем не конечную реализацию (FileLogger), а именно интерфейс стандарта PSR-3. Это удобно, потому что позволяет легко заменять применяемый логер на любой другой, поддерживающий этот интерфейс.
Контекст
Вы могли заметить, что все методы интерфейса LoggerInterface содержат аргумент $context. Зачем он нужен?
Контекст предназначен для передачи вспомогательной и зачастую динамичной информации. Например, если вы делаете отладочную запись (уровень debug), можно передать в контекст значение переменной.
Чтобы применять этот аргумент, нам нужно поддержать его в методе log. Давайте доработаем его, учитывая, что $context — массив.
Теперь в любом месте вызова логера мы можем передать вторым аргументом массив дополнительной информации.
В результате мы получим запись следующего вида:
Библиотека Monolog
Несмотря на всю простоту принципа ведения журналов, в этой области широкий простор для модификаций. Мы могли бы поддержать другие форматы записей, реализовать отправку SMS или элементарно дать возможность менять имя конечного файла логов.
Здорово, что всё это уже реализовано в большинстве библиотек. Одна из самых распространённых – monolog.
Среди весомых преимуществ этого пакета:
- полная поддержка PSR-3;
- поддержка разных принципов обработки логов в зависимости от уровня;
- поддержка имён каналов (имена логеров);
- очень широкая поддержка фреймворков.
Чтобы начать использовать этот прекрасный инструмент, установим его с помощью Composer.
Использование Monolog
Работа библиотеки monolog основывается на обработчиках. Они позволяют задавать конкретное поведение в ответ на события логирования. Например: запись в файл — это специальный обработчик, который называется StreamHandler. Давайте заменим использование нашего класса на загруженную библиотеку.
Если мы запустим этот код, в файле gb.log появится запись следующего вида:
Очень похоже на то, что было у нас ранее, кроме добавления имени канала (gb-demo).
Важная особенность обработчиков monolog: им можно задать уровень, на котором они работают. Например, чтобы писать все ошибки в отдельный файл.
Подключённый на уровень ERROR обработчик будет принимать на себя все записи уровня ERROR и выше. Поэтому вызов метода emergency попадает в оба файла: gb.log и errors.log
Такое простое разделение записей по уровням значительно упрощает для нас реагирование на ошибки. Ведь больше не нужно искать их среди всех записей в журнале. Это простая и полезная функция.
Все записи от одного запроса
Когда мы разрабатываем проект, журналы читаются очень просто, они последовательны и ясны. Но когда продуктом пользуются несколько человек, логи могут перемешиваться и больше запутывать, чем помогать. Для решения этой проблемы есть простой трюк. Вместо имени канала (логера) используйте уникальный идентификатор сессии. Получить его можно с помощью встроенной функции session_id(). При этом сессия должна быть обязательно запущена с помощью session_start()
Рассмотрим пример реализации такого приёма:
Что нам даёт такая простая доработка? Важную возможность — группировать все записи запросам пользователя.
Что дальше?
Monolog поддерживает множество полезных готовых обработчиков, на которые стоит обратить внимание:
- TelegramBotHandler — отправляет записи в Telegram от имени бота. Пригодится для высоких уровней логирования;
- SlackHandler — похож на предыдущий, но отправляет записи в Slack;
- SwiftMailerHandler — позволяет отправлять записи по email;
- ChromePHPHandler – даёт доступ к журналам прямо из браузера Chrome в режиме Live.
Заключение
Логирование поможет исправлять ошибки на ранних этапах разработки и быть уверенными, что ничего не сломалось в новой версии кода. А ещё расследовать случаи ваших пользователей и иметь общее видение проекта.
Написали программу с применением нейросети, но она выдает кучу ошибок? Где потом искать эти ошибки? Как структурировать полученную информацию?
Помочь с поиском ошибок может логирование — группа методов для сбора и сохранения информации о работе программы. Всю интересующую нас информацию мы можем записывать в текстовые файлы и потом их обрабатывать. К примеру, вот таким образом в случае деления на 0:
Тогда консоль нам покажет следующее:
А в логе с файлом увидим:
Конечно, реализовать самостоятельно такой способ — просто, и многие этим пользуются. Но у него тоже есть минус: если проект большой, надо не забывать придерживаться определенного формата их заполнения.
Для работы с ней нам необходимо импортировать библиотеку logging и указать основные параметры. Всего параметров для настройки 6.
Так же существует 5 уровней логирования информации: от DEBUG (отладка) до critical (критичные ошибки).
На этом можно закончить с теорией, и перейдем к практике.
Теперь мы будем логировать нашу функцию деления уже с учетом модуля logging и попытаемся собрать максимум информации о ее работе. Давайте рассмотрим код нашего простенького скрипта, но уже с учетом использования логов.
Как мы видим он немного увеличился в размерах, но при этом, для записи также использует лишь одна строчка.
В начале мы создаем переменную, в которой указываем идентификатор лога. Это нужно для того, к примеру, чтобы мы не путались из какого скрипта записываем лог. Это делается строкой -
После – мы указываем уровень лога и имя файла, в который мы будем его записывать:
format_log = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') file_name.setFormatter(format_log) logger.addHandler(file_name)
Вот, на этом и все) В дальнейшем мы можем использовать наш логгер простым вызовом logger.info('Division') или в случае описания ошибки logger.error(error_text). По окончанию работы скрипта данные будут сохранены в файл 'data.log'.
А теперь посмотрим, что мы получили в логе:
Вот таким простым способом мы с вами научились делать понятную и удобную запись логов в нашем скрипте!
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
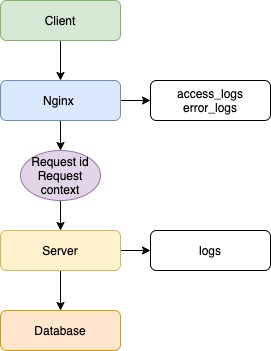
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.

Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.
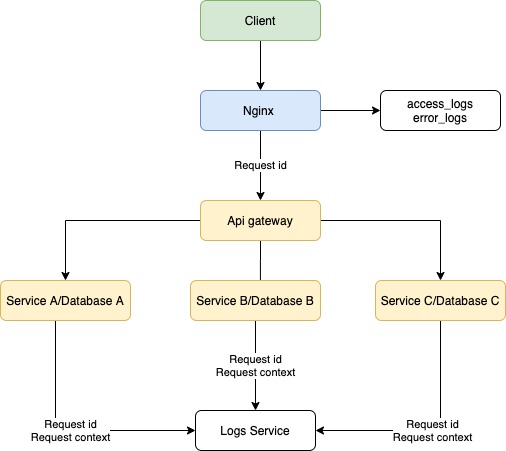
При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.
В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.
Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Давайте научимся следить за выполнением логики в нашей программе, для этого мы научимся использовать логирование, поймем зачем оно и где используется.
Шаг 0. Обзор
Логирование – не используя термины википедии, то это возможность следить за процесом выполнения бизнес-логики проекта.
Зачем нужно логирование и что оно даёт?
Вы, как человек который администрирует магазин начнет разбераться в чем же проблема. Неопытный человек будет долго искать проблему, а опытный сразу полезет в логи сервера, но там все логи сервера и найти то что нужно вам сложно.

В этом случае решение следующее, выводить нужные вам логи в отдельный файл. Но как понять, какие из всех логов, которые сыпятся в общий лог сервера нужны вам? Для этого нужно реализовать свою систему логирования, где вы сможите указать какие логи куда выводить, или же настроить уровни логирования.
В данном уроке мы рассмотрим как сконфигурировать и начать использовать Log4j.
Шаг 1. Создаем проект и добавляем завимости
Запускаем всеми любимую Intellij IDEA и тыкаем New Project выбираем Maven Module и называем его :

Теперь в pom.xml жлбавим зависимость:
Это все зависимости, которые надо было подключить.
Шаг 2. Создание примитивной логики для примера
Давайте создадим класс в котором была бы бизнес-логика, назовем его OrderLogic:
Хочу обратить ваше внимание на то, что логика данного проекта не важна, так как мы рассматриваем логирование, для этого я и подготовил примитивную логику класса OrderLogic.
И теперь создаем Main класс:
В результате выполнения данного кода, мы получим следующее:
Как видите пока ничего нового.
Шаг 3. Конфигурируем Log4j
Чтобы гибко управлять логированием стоит создать в resources/ файл log4j.properties:

Теперь в этот файл добавим пару строк конфигураций:
Теперь давайте более детальней разберем строку формирования шаблона:
%d – выводит дату в формате 2014-01-14 23:55:57
%-5p – выводит уровень лога (ERROR, DEBUG, INFO …), цифра 5 означает что всегда использовать 5 символов остальное дополнится пробелами, а минус (-), то что позиционирование по левой стороне.
%c – категория, в скобках указывается сколько уровней выдавать. Так как у нас 1 уровень то писаться будет только имя класса.
%L – номер строки в которой произошёл вызов записи в лог.
Читайте также: