
Как сделать линейное распределение в spss
Обновлено: 04.07.2024
При изучении линейного регрессионного анализа снова будут проведено различие между простым анализом (одна независимая переменная) и множественным анализом (несколько независимых переменных). Никаких принципиальных отличий между этими видами регрессии нет, однако простая линейная регрессия является простейшей и применяется чаще всех остальных видов.
Этот вид регрессии лучше всего подходит для того, чтобы продемонстрировать основополагающие принципы регрессионного анализа. Рассмотрим пример из раздела корреляционный анализ с зависимостью показателя холестерина спустя один месяц после начала лечения от исходного показателя. Можно легко заметить очевидную связь: обе переменные развиваются в одном направлении и множество точек, соответствующих наблюдаемым значениям показателей, явно концентрируется (за некоторыми исключениями) вблизи прямой (прямой регрессии). В таком случае говорят о линейной связи.
у = b • х + а,
где b — регрессионные коэффициенты, a — смещение по оси ординат (OY).
Смещение по оси ординат соответствует точке на оси Y (вертикальной оси), где прямая регрессии пересекает эту ось. Коэффициент регрессии b через соотношение:
b = tg(a) - указывает на угол наклона прямой.
При проведении простой линейной регрессии основной задачей является определение параметров b и а. Оптимальным решением этой задачи является такая прямая, для которой сумма квадратов вертикальных расстояний до отдельных точек данных является минимальной.
Если мы рассмотрим показатель холестерина через один месяц (переменная chol1) как зависимую переменную (у), а исходную величину как независимую переменную (х), то тогда для проведения регрессионного анализа нужно будет определить параметры соотношения:
chol1 = b • chol0 + a
После определения этих параметров, зная исходный показатель холестерина, можно спрогнозировать показатель, который будет через один месяц.
Расчёт уравнения регрессии
Рис.16.2: Диалоговое окно Линейная регрессия
Вывод основных результатов выглядит следующим образом:
Model Summary (Сводная таблица по модели)
| Model (Модель) | R | R Square (R-квадрат) | Adjusted R Square (Скорректир. R-квадрат) | Std. Error of the Estimate (Стандартная ошибка оценки) |
| 1 | ,861 а | ,741 | ,740 | 25,26 |
а. Predictors: (Constant), Cholesterin, Ausgangswert (Влияющие переменные: (константы), холестерин, исходная величина)
| Model (Модель) | Sum of Squares (Сумма Квадратов) | df | Mean Square (Среднее значение квадрата) | F | Sig. (Значимость) | |
| 1 | Regression (Регрессия) | 314337,948 | 1 | 314337,9 | 492,722 | ,000 a |
| Residual (Остатки) | 109729,408 | 172 | 637,962 | |||
| Total (Сумма) | 424067,356 | 173 |
a. Predictors: (Constant), Cholesterin, Ausgangswert (Влияющие переменные: (константа), холестерин, исходная величина).
b. Dependent Variable: Cholesterin, nach 1 Monat (Зависимая переменная холестерин через 1 месяц)
Coefficients (Коэффициенты) а
(Не стандартизированные коэффициенты)
(Станд. ошибка)
a. Dependent Variable (Зависимая переменная)
Рассмотрим сначала нижнюю часть результатов расчётов. Здесь выводятся коэффициент регрессии b и смещение по оси ординат а под именем "константа". То есть, уравнение регрессии выглядит следующим образом:
chol1 = 0,863 • chol0 + 34,546
Если значение исходного показателя холестерина составляет, к примеру, 280, то через один месяц можно ожидать показатель равный 276.
Частные рассчитанных коэффициентов и их стандартная ошибка дают контрольную величину Т; соответственный уровень значимости относится к существованию ненулевых коэффициентов регрессии. Значение коэффициента ß будет рассмотрено при изучении многомерного анализа.
Средняя часть расчётов отражает два источника дисперсии: дисперсию, которая описывается уравнением регрессии (сумма квадратов, обусловленная регрессией) и дисперсию, которая не учитывается при записи уравнения (остаточная сумма квадратов). Частное от суммы квадратов, обусловленных регрессией и остаточной суммы квадратов называется "коэфициентом детерминации". В таблице результатов это частное выводится под именем "R-квадрат". В нашем примере мера определённости равна:
314337,948 / 424067,356 = 0,741
Эта величина характеризует качество регрессионной прямой, то есть степень соответствия между регрессионной моделью и исходными данными. Мера определённости всегда лежит в диапазоне от 0 до 1. Существование ненулевых коэффициентов регрессии проверяется посредством вычисления контрольной величины F, к которой относится соответствующий уровень значимости.
В простом линейном регрессионном анализе квадратный корень из коэфициента детерминации, обозначаемый "R", равен корреляционному коэффициенту Пирсона. При множественном анализе эта величина менее наглядна, нежели сам коэфициент детерминации. Величина "Cмещенный R-квадрат" всегда меньше, чем несмещенный. При наличии большого количества независимых переменных, мера определённости корректируется в сторону уменьшения. Принципиальный вопрос о том, может ли вообще имеющаяся связь между переменными рассматриваться как линейная, проще и нагляднее всего решать, глядя на соответствующую диаграмму рассеяния. Кроме того, в пользу гипотезы о линейной связи говорит также высокий уровень дисперсии, описываемой уравнением регрессии.
И, наконец, стандартизированные прогнозируемые значения и стандартизированные остатки можно предоставить в виде графика. Вы получите этот график, если через кнопку Plots. (Графики) зайдёте в соответствующее диалоговое окно и зададите в нём параметры *ZRESID и *ZPRED в качестве переменных, отображаемых по осям у и х соответственно. В случае линейной регрессии остатки распределяются случайно по обе стороны от горизонтальной нулевой линии.
Сохранение новых переменных
Многочисленные вспомогательные значения, рассчитываемые в ходе построения уравнения регрессии, можно сохранить как переменные и использовать в дальнейших расчётах.
Рис. 16.3: Диалоговое окно Линейная регрессия: Сохранение
Интересными здесь представляются опции Standardized (Стандартизированные значения) и Unstandardized (Нестандартизированные значения), которые находятся под рубрикой Predicted values (Прогнозируемые величины опции). При выборе опции Не стандартизированные значения будут рассчитывается значения у, которое соответствуют уравнению регрессии. При выборе опции Стандартизированные значения прогнозируемая величина нормализуется. SPSS автоматически присваивает новое имя каждой новообразованной переменной, независимо от того, рассчитываете ли Вы прогнозируемые значения, расстояния, прогнозируемые интервалы, остатки или какие-либо другие важные статистические характеристики. Нестандартизированным значениям SPSS присваивает имена pre_1 (predicted value), pre_2 и т.д., а стандартизированным zpr_l.
В редакторе данных будет образована новая переменная под именем рrе_1 и добавлена в конец списка переменных в файле. Для объяснения значений, находящихся в переменной рrе_1, возьмём случай 5. Для случая 5 переменная рrе_1 содержит нестандартизированное прогнозируемое значение 263,11289. Это прогнозируемое значение слегка отличается в сторону увеличения от реального показателя содержания холестерина, взятого через один месяц (chol1) и равного 260. Нестандартизированное прогнозируемое значение для переменной chol1, так же как и другие значения переменной рге_1, было вычислено исходя из соответствующего уравнения регрессии.
Если мы в уравнение регрессии:
chol1 = 0,863 • chol0 + 34,546
подставим исходное значение для chol0 (265), то получим: chol1 = 0,863 • 265 + 34,546 = 263,241
Небольшое отклонение от значения, хранящегося в переменной рге_1 объясняется тем, что SPSS использует в расчётах более точные значения, чем те, которые выводятся в окне просмотра результатов.
Мы исходим из того, что нам не известны значения показателя холестерина через месяц после начала лечения, и мы хотим спрогнозировать значение переменной chol1.
В конце списка переменных добавится переменная рге_2. Для нового добавленного случая (№175) для переменной chol1 будет предсказано значение 277,77567, а для случая №176 — значение 305,37620.
Построение регрессионной прямой
Чтобы на диаграмме рассеяния изобразить регрессионную прямую, поступите следующим образом:
Рис. 16.4: Диалоговое окно Scatter plots. (Диаграмма рассеяния)
Рис. 16.5: Диалоговое окно Simple Scatterplot (Простая диаграмма рассеяния).
Рис. 16.6: Диаграмма рассеяния в окне просмотра
Рис. 16.7: Диалоговое окно Scatterplot Options (Опции для диаграммы рассеяния)
Рис. 16.8: Диалоговое окно Scatterplot Options: Fit Line (Опции для диаграммы рассеяния:
Рис. 16.9: Диаграмма рассеяния с регрессионной прямой
Для диаграмм рассеяния часто оказывается необходимой дополнительная корректировка осей. Продемонстрируем такую коррекцию при помощи одного примера. В файле raucher.sav находятся десять фиктивных наборов данных. Переменная konsum указывает на количество сигарет, которые выкуривает один человек в день, а переменная puls на количество времени, необходимое каждому испытуемому для восстановления пульса до нормальной частоты после двадцати приседаний. Как было показано ранее, постройте диаграмму рассеяния с внедрённой регрессионной прямой.
Рис. 16.10: Диаграмма рассеяния с регрессионной прямой до коррекции осей
Так как никто не выкуривает минус 10 сигарет в день, точка начала отсчёта оси X является не совсем корректной. Поэтому эту ось необходимо откорректировать.
Рис. 16.11: Диалоговое окно Axis Selection (Выбор оси)
Рис. 16.12: Диалоговое окно X-Scale Axis (Ось X)
В окне просмотра Вы увидите откорректированную диаграмму рассеяния (см. рис. 16.13).
Рис. 16.13: Диаграмма рассеяния с регрессионной прямой после корректировки осей
На откорректированной диаграмме рассеяния теперь стало проще распознать начальную точку на оси Y, которая образуется при пересечении с регрессионной прямой. Значение этой точки примерно равно 2,9. Сравним это значение с уравнением регрессии для переменных puls (зависимая переменная) и konsum (независимая переменная). В результате расчёта уравнения регрессии в окне отображения результатов появятся следующие значения:
Coefficients (Коэффициенты) а
| Model (Модель) | Unstandardized Coefficients (Не стандартизированные коэффициенты) | Standardized Coefficients (Стандартизированные коэффициенты) | t | Sig. (Значимость) | |
| B | Std: Error (Станд. ошибка) | ß (Beta) | |||
| 1 | (Constant) (Константа) | 2,871 | ,639 | 4,492 | ,002 |
| tgl. Zigarettenkonsum | ,145 | ,038 | ,804 | 3,829 | ,005 |
a. Dependent Variable: Pulsfrequenz unter 80 (Зависимая переменная: частота пульса ниже 80)
Что дает следующее уравнение регрессии:
puls = 0,145 • konsum + 2,871
Константа в вышеприведенном уравнении регрессии (2,871) соответствует точке на оси Y, которая образуется в точке пересечения с регрессионной прямой.
SPSS (пятнадцать) SPSS кластерный анализ (графика + набор данных)
Введение в кластерный анализ
Индивидуумы (записи) классифицируются в соответствии с их характеристиками, поэтому индивидуумы в одной и той же категории имеют максимально возможную однородность, а между категориями - максимально возможную неоднородность.
Чтобы получить более разумную классификацию, мы должны сначала использовать соответствующие показатели, чтобы количественно описать близость отношений между объектами исследования.
- До кластерного анализа категория, к которой принадлежат все люди, неизвестна, а количество категорий, как правило, неизвестно. Основой анализа являются исходные данные, и информация о категории заранее может отсутствовать.
- Строго говоря, кластерный анализ не является чисто статистическим методом, он не похож на другие методы многомерного анализа, которые должны выводить население из выборки. Как правило, распределение соответствующих статистических данных не участвует, и тест значимости не требуется.
- Кластерный анализ больше похож на метод установления гипотез, а проверка связанных гипотез требует других статистических методов.
Примечание:Кластерный анализ больше похож на метод установления гипотез, а для проверки связанных гипотез также необходимы другие статистические методы, такие как дискриминантный анализ, T-критерий, дисперсионный анализ и т. Д.
Цель кластеризации
- Проектный план отбора проб (стратифицированная выборка)
- Процесс предварительного анализа (кластерный анализ сначала используется для упрощения данных, и многие люди объединяются в несколько категорий или подмножеств, которые легче обрабатывать, а затем последующий многомерный анализ)
- Сегментация рынка и поведение отдельных потребителей (сначала кластеризация, а затем использование дискриминантного анализа для дальнейшего изучения различий между группами)
Краткое изложение основных этапов кластерного анализа


Метод кластеризации

К-средний кластер
Принцип метода
- Выберите (или искусственно укажите) определенные записи в качестве точки сцепления
- Объедините оставшиеся записи в точку конденсации в соответствии с ближайшим принципом
- Рассчитайте центральное положение (среднее) каждой начальной классификации
- Повторная кластеризация с рассчитанным центральным положением
- Повторяйте этот цикл, пока положение точки конденсации не сойдет
Характеристики метода
- Количество известных категорий
- Начальная позиция может быть указана вручную
- Экономьте вычислительное время
- Необходимо учитывать, когда размер выборки слишком велик
- Можно использовать только непрерывные переменные
Кейс: Сегментация клиентов мобильной связи


Видя, что результат не может сходиться, поэтому сбросьте количество итераций и дайте ему сходиться


Но в итоге результаты странные

Шкала измерения каждой переменной отличается, и размер больше при кластеризации для расчета расстояния.




Стандартизированные переменные, как правило, в пределах плюс или минус 3, где 0 представляет средний уровень

Но мы хотим видеть исходный уровень исходной переменной, не смотря на эту стандартизированную
Классификация сохраненных случаев





Мы просто хотим увидеть среднее

Получить нестандартные результаты кластерного центра

- Первая категория: коммерческие клиенты высокого класса с длительным общим временем разговора и высоким процентом звонков в рабочие дни.
- Вторая категория: меньше пользователей с низким уровнем дохода, общее время разговора короткое, а время разговора в каждом периоде короткое
- Третья категория: коммерческие клиенты среднего уровня, общее время разговора среднее, а доля звонков в рабочие дни высока
- Четвертая категория: среднесуточные клиенты, общее время разговора среднее, а скорость вызовов высокая в течение рабочего дня.
- Пятая категория: долгий разговор с клиентами, длительное время разговора.
Иерархический кластер
Принадлежащий к определенному методу систематической кластеризации, процесс кластеризации может быть описан древовидной структурой (древовидная структура)
Принцип метода
- Сначала обработайте все n переменных / наблюдений как разные n типов
- Затем объедините две категории с самой близкой природой (ближайшее расстояние) в одну категорию
- Затем найдите две ближайшие категории из n-1 категорий и объедините их
- И так до тех пор, пока все переменные / наблюдения не будут сгруппированы
- Затем пользователь решает, что его следует разделить на несколько категорий на основе конкретных вопросов и результатов кластеризации.
особенность
- Как только записи / переменные классифицированы, их результаты классификации не будут изменены
- Может кластеризовать переменные или записи
- Переменные могут быть непрерывными или категориальными переменными (хотя переменные могут быть непрерывными или подтипами, но их нельзя смешивать, или они используются для полной классификации или кластеризации непрерывных переменных)
- Предоставляет множество методов измерения расстояния
- Более медленная скорость расчета
Случай: Гимнастическая кластеризация тенденций оценки рефери (в данном случае это кластерные переменные)
SPSS поставляется с набором данных судей.сав, который представляет собой оценку судей и судей в семи странах, таких как Китай, Соединенные Штаты и Франция. Пожалуйста, классифицируйте их по соответствующим категориям на основе различий в рейтингах.

Почему вы не можете использовать кластеризацию K-средних?
Поскольку кластеризация K-средних может выполнять только кластеризацию, это относится к кластерным переменным
А для K-средних необходимо определить количество категорий, которое в настоящее время неизвестно

Мы группируем переменные, диаграмма сосульки выглядит слишком хлопотно, просто посмотрите на дендрограмму

Процесс кластеризации, коэффициент представляет собой расстояние, что означает расстояние, зависит от того, какой индекс расстояния мы используем

Дендрограмма 233.297 преобразована в следующие 25

Я обнаружил некоторые проблемы с кластеризацией итальянской и восточной группы (Китай, Россия, Румыния)
Переменная кластеризация обычно по умолчанию коррелирует (по умолчанию используется квадратное евклидово расстояние)


Результаты намного лучше

Этот пример также может быть решен с использованием факторного анализа
Общий метод кластеризации - лучшая связь между группами, метод Уорда будет более средним при кластеризации.

Метрика: случай - лучшее евклидово расстояние
Переменная - Пирсон имеет лучшую корреляцию

K-означает кластеризацию требует ручного
Система сгруппирована следующим образом

Два упомянутых выше метода являются классическими методами кластеризации анализа, и существуют интеллектуальные методы кластеризации анализа.
Двухступенчатый алгоритм кластеризации ( TwoStep Cluster)
Особенности:
- Обрабатываемые объекты: категориальные переменные и непрерывные переменные
- Автоматически определять лучшее количество категорий
- Быстрая обработка больших наборов данных
Предположения:
- Переменные не зависят друг от друга
- Категориальные переменные следуют за полиномиальным распределением, непрерывные переменные следуют за нормальным распределением
На самом деле, это не имеет значения, если вы слегка нарушите эти предположения.

SPSS использует модель для автоматической нормализации непрерывных переменных

Установите максимальное количество кластеров

Очки для внимания в кластеризации
Используйте значение по умолчанию
Нерелевантные переменные иногда приводят к серьезной ошибочной классификации
должен вводить только те переменные, которые значительно различаются между разными классами
Старайтесь использовать для анализа только переменные одного типа (используйте непрерывные переменные, используйте категориальные переменные для интерпретации результатов; новые методы кластеризации, такие как двухэтапный алгоритм кластеризации, могут использовать эти переменные одновременно)
Это оказывает большее влияние на запись результатов кластеризации, что эквивалентно весу переменной в кластеризации больше, чем другим переменным
Предварительную обработку лучше
Это необходимо сделать, когда переменная размерность / степень вариации сильно отличается
Математические статистические алгоритмы требуют стандартизации
Стандартизация ослабит роль полезных переменных
Большее влияние
Нет лучшего решения
Старайтесь избегать
С практической точки зрения категории от 2 до 8 являются более подходящими
Должен сочетаться с профессиональными знаниями для анализа
Кластерный анализ в основном используется в поисковых исследованиях. Результаты анализа могут дать несколько возможных решений. Выбор окончательного решения требует субъективного суждения исследователя и последующего анализа.
Решение кластерного анализа полностью зависит от кластерных переменных, выбранных исследователем. Добавление или удаление некоторых переменных может оказать существенное влияние на окончательное решение
Независимо от того, существуют ли фактически разные категории в фактических данных, кластерный анализ можно использовать для получения решений, разделенных на несколько категорий
Основным инструментом анализа и визуализации статистических данных для меня всегда был Excel. Я работаю с ним ежедневно. По нему написал больше всего заметок и прочитал наибольшее число книг. Пожалуй, лучшее сочетание статистики и Excel я нашел в книге Левин. Статистика для менеджеров с использованием Microsoft Excel. Вторым инструментом, к которому я только прикоснулся, был R (см., например, Алексей Шипунов. Наглядная статистика. Используем R!). А недавно прочитал любопытную книгу Нил Дж. Салкинд. Статистика для тех, кто (думает, что) ненавидит статистику. В ней автор все примеры иллюстрирует в программе SPSS. Так что я решил попробовать и этот продукт.
На сайте IBM доступна пробная версия, которая будет работать на вашем ПК 14 дней. Регистрируетесь и скачиваете программу SPSS Statistics. При регистрации запомните пароль. Он вам пригодится для входа в программу. После запуска появляется приветственное окно:
Рис. 1. Приветственное окно SPSS; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Если вы не хотите видеть этот экран каждый раз при запуске SPSS, то в левом нижнем углу окна кликните Не показывать это диалоговое окно в будущем.
Кликните Закрыть в правом нижнем углу экрана. Появится окно Редактор данных. По виду и функционалу Редактор похож на электронную таблицу, как лист Excel.
Рис. 2. Редактор данных
Хотя этого и не видно, когда SPSS открывается в первый раз, но есть еще одно открытое (хотя и неактивное) окно. Это Окно вывода (Viewer). Оно показывает создаваемые вами статистические результаты и графики. Набор данных создается при помощи Редактора данных, а после анализа или построения графиков вы изучаете результаты анализа в Окне вывода.
Рис. 3. Окно вывода
Панель инструментов и строка состояния
Если вы хотите узнать, что делает иконка на панели инструментов, просто наведите на нее указатель мыши. Некоторые кнопки на панели инструментов затенены. Это означает, что они не активны.

Рис. 4. Панель инструментов

Рис. 5. Строка состояния
Использование справки
Справка настолько подробна, что может указать вам путь, даже если вы новичок в работе с программой. Меню Справка содержит 10 разделов.
Рис. 6. Меню справки
Нажмите Темы, и перейдете в браузер на страницу центра знаний IBM на русском языке. Здесь представлена собственно справка, а также Учебное пособие, Разбор конкретных случаев, Инструктор по статистике, Разделы для подключаемых модулей Python и R.
Открытие файла
Вы можете импортировать данные из Excel, или ввести значения в таблицу, после чего сохранить в новом файле SPSS, или открыть готовый файл. В этой заметке мы используем файл Sample Data Set.sav. Пройдите по меню Файл –> Открыть –> Данные. Выберите файл. Данные загрузятся в окно редактора:
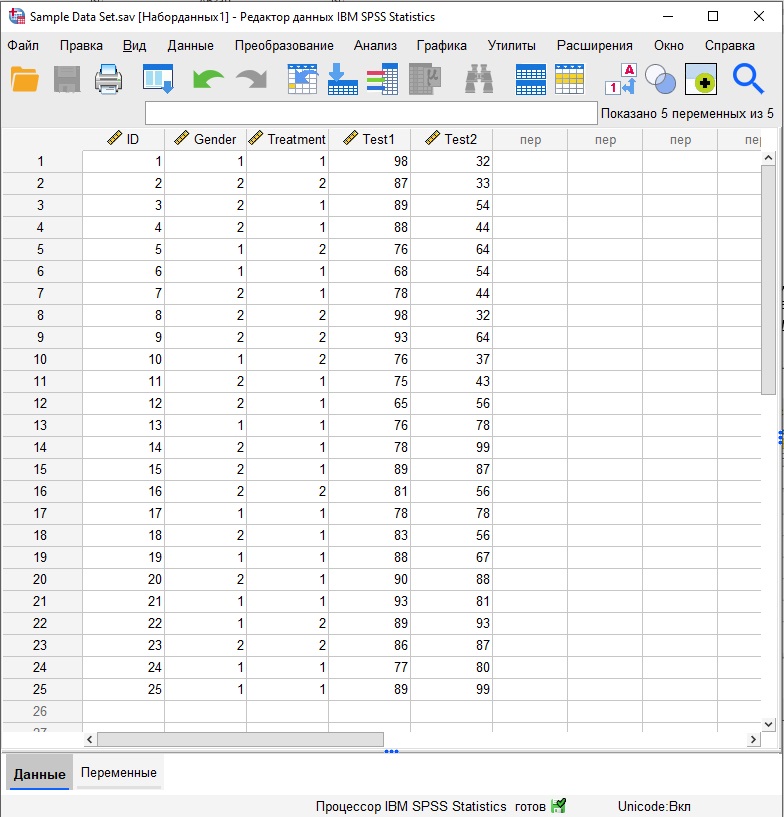
Рис. 7. Данные загружены из файла в окно редактора
Таблица и диаграмма
Допустим, мы хотим посчитать, сколько мужчин и женщин находится в нашей выборке, и вывести результат в виде столбчатой диаграммы. В окне Редактора данных пройдите по меню Анализ –> Описательные статистики –> Частоты. В открывшемся окне Частоты, выберите Gender, нажмите кнопку для переноса переменной в правое окно (или дважды кликните на Gender). Нажмите копку Диаграммы. Выберите Столбчатые. Нажмите Продолжить. Нажмите Ok.
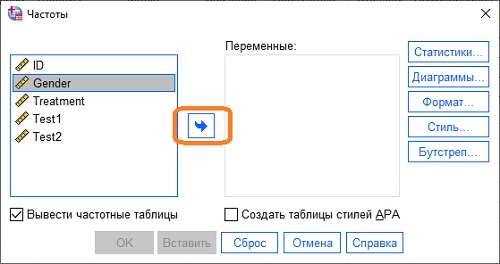
Рис. 8. Выбор переменной для анализа частоты
В окне вывода появится таблица и диаграмма:
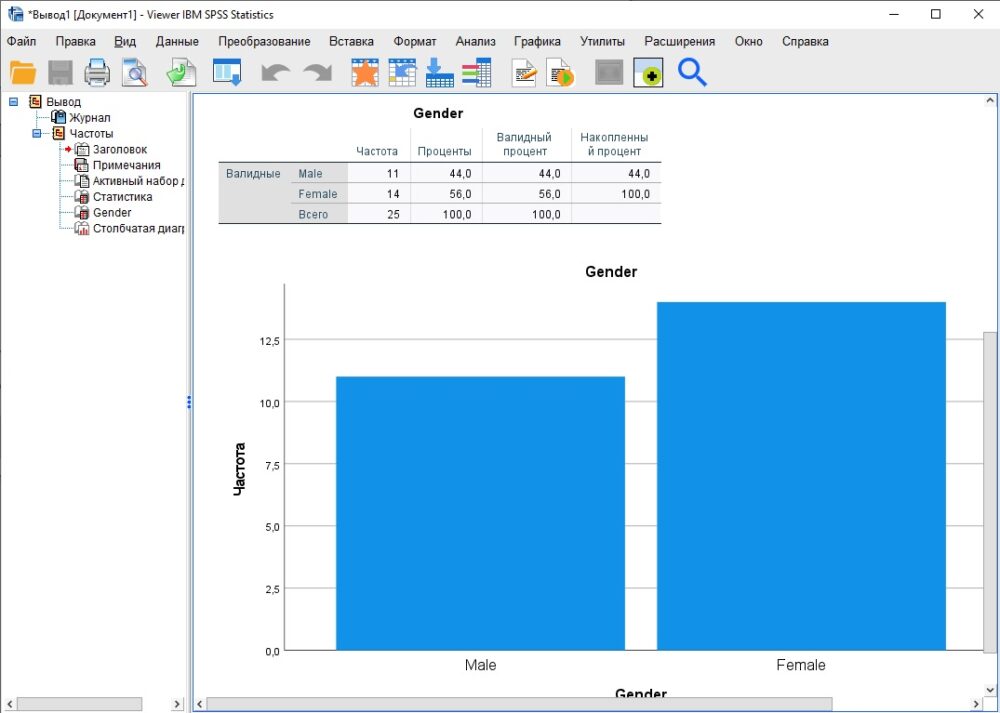
Рис. 9. Таблица и диаграмма в окне вывода
Оценка t-критерия
Давайте проверим, отличаются ли средние значения результатов Test 1 у мужчин и женщин. Этот анализ основан на t-критерии для независимых выборок. В редакторе данных пройдите по меню Анализ –> Сравнение средних –> Т-критерий для независимых выборок. В открывшемся окне переместите переменную Test1 в область Проверяемые параметры, а переменную Gender – в область Группировать по:
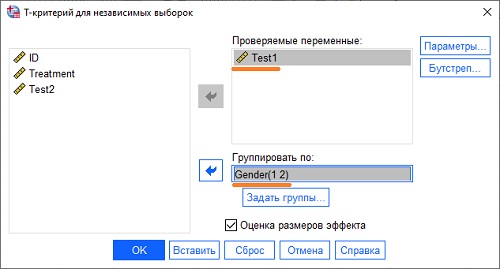
Рис. 10. Настройка расчета t-критерия для независимых выборок
Нажмите Ok. Программа сформирует таблицы проверки по t-критерию, и покажет их в окне вывода:
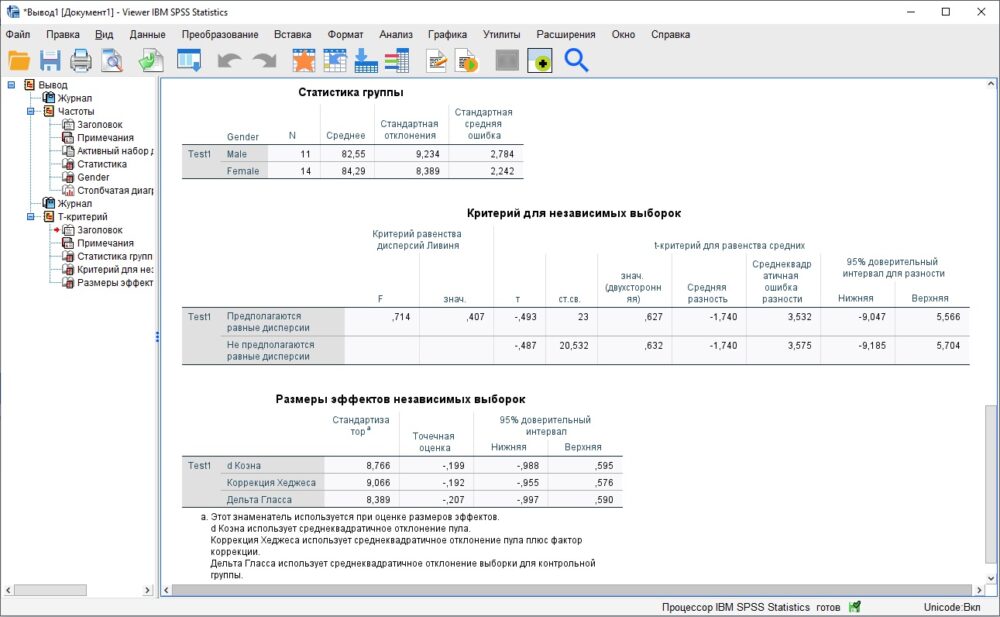
Рис. 11. Результаты проверки t-критерия для независимых выборок
T-тест показал, что различие между мужчинами и женщинами при прохождении Test1 незначимо.
Создание и редактирование файла данных
Давайте создадим набор данных, который только что загрузили из файла Sample Data Set.sav. Сначала определим переменные, а затем введем данные. В окне Редактора данных пройдите по меню Файл –> Создать –> Данные. Откроется новое окно Редактора данных. Обратите внимание, что окно открылось на вкладке Переменные (SPSS подсказывает, что сначала надо заняться ими).
Если вы поместите курсор в первую ячейку в колонке Имя, введёте любое имя и нажмёте Enter, SPSS для всех характеристик переменной автоматически проставит значения по умолчанию (см. строку 1 на рис. ниже).
Рис. 12. Параметры по умолчанию
Подробнее о параметрах переменной:
- Имя переменной должно начинаться с буквы, иметь длину не более 64 символов, не содержать пробелы, подробнее см. здесь;
- Тип:
Рис. 13. Типы переменных
- Ширина задает количество символов в столбце, содержащем данную переменную;
- Десятичные определяет количество десятичных знаков;
- Метка задает метку переменной длиной до 256 символов;
- Значения устанавливает соответствие числовых значений и категорий; например, 1 для мужчин и 2 для женщин;
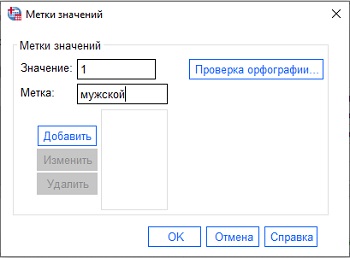
Рис. 14. Введение значений для категорийных переменных
Категорийные переменные в SPSS можно вводить в виде текстовых строк, например, Male и Female, а можно назначить им значения. Когда дело дойдет до анализа, окажется, что очень трудно работать с нечисловыми записями. Но при визуальном просмотре файла, наоборот, имена (метки) нагляднее. Окно Метки значений позволяет вводить в SPSS числа, а выводить на экран метки: и волки сыты, и овцы целы. Чтобы это работало, находясь в Редакторе данных на закладке Данные, перейдите в меню Вид, и поставьте галочку напротив Метки значений.
- Пропущенные – указывает, как обращаться с пропущенными значениями;
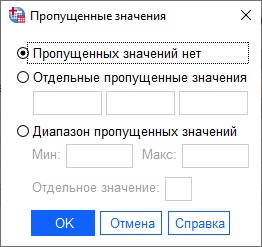
Рис. 15. Управление пропущенными значениями
- Ширина столбца определяет количество символов, выделенное для переменной в окне представления данных;
- Выравнивание – определяет, как будут выровнены данные в ячейке (влево, вправо, по центру);
- Мера – определяет шкалу измерения, которая лучше всего описывает переменную (номинальная, порядковая или интервальная);
- Роль – определяет роль, которую играет переменная в анализе (входная, целевая и т.д.).
Определите следующие переменные:
Рис. 16. Пять переменных в окне Редактора данных на закладке Переменные
Теперь вы можете переключиться на вкладку Данные и просто ввести все данные, которые представлены на рис. 7.
Печать из SPSS
Чтобы распечатать весь файл данных или его часть:
- убедитесь, что файл, который вы хотите напечатать, находится в активном окне;
- кликните Файл –>Печать;
- откроется диалоговое окно печати (рис. 17);
- выберите, что вы хотите распечатать: файл целиком или выделенный фрагмент (если предварительно фрагмент не был выбран, эта опция неактивна); нажмите Ok.
Рис. 17. Диалоговое окно печати
Вместо выбора принтера можно задать создание файл *.pdf.
Создание диаграммы в SPSS
Воспользуемся данными из файла Sample Data Set.sav. Откройте файл, на вкладке Данные, кликните меню Графика. Выберите одну из опций: Мастер диаграмм, Панель выбора диаграмм, Устаревшие диалоговые окна. Последняя опция позволяет выбрать один из стандартных типов диаграмм. Первые две опции проведут вас по пути создания диаграммы, наиболее подходящей к выбранным данным.
Рис. 18. Типы диаграмм
Выберите Столбцы, откроется диалоговое окно, предлагающее несколько вариантов оформления:

Рис. 19. Виды столбчатой диаграммы
Выберите Простая и Итоги по группам наблюдений. Нажмите Задать. Откроется окно Простые столбцы. Задайте, что будет анализировать диаграмма:
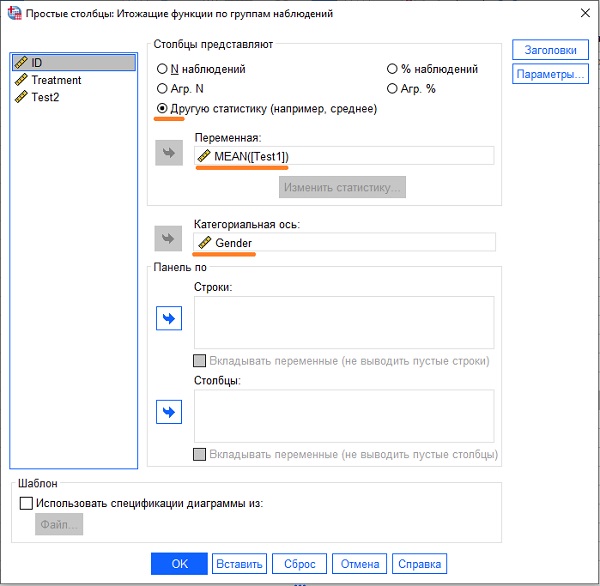
Рис. 20. Параметры аналитики диаграммы
Нажмите Ok. В окне вывода появится диаграмма: среднее значение Test1 раздельно по полу:
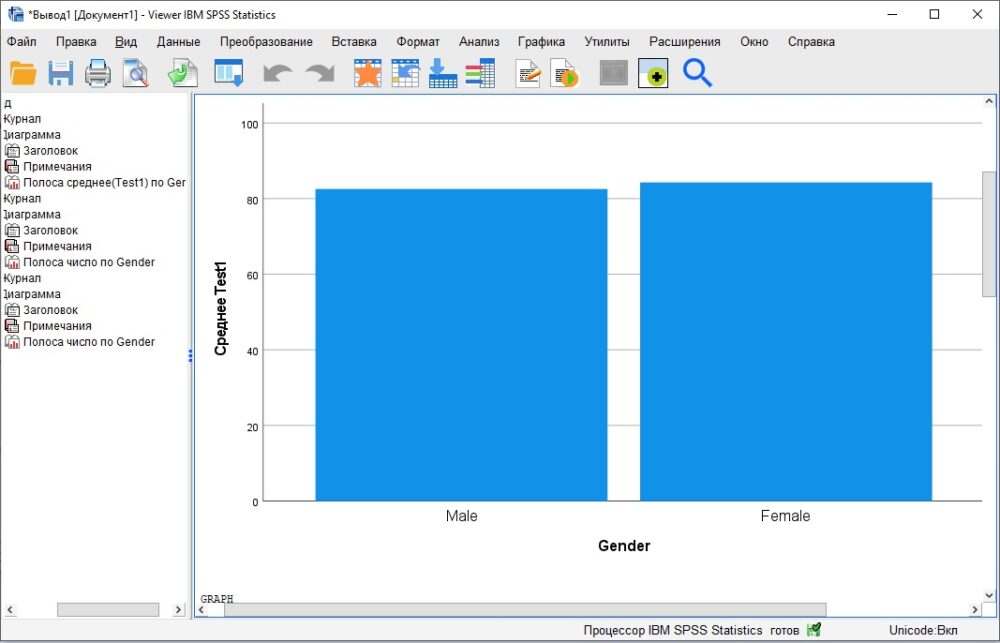
Рис. 21. Средние результаты Теста 1
Сохранение диаграммы
Диаграмма является частью окна вывода. В этом окне сохраняется любой выполняемый вами анализ. Диаграмма не является самостоятельной сущностью, и ее нельзя сохранить в качестве таковой. Для того чтобы сохранить диаграмму, вам нужно сохранить содержимое всего окна вывода. Для этого:
- кликните Файл –>Сохранить;
- задайте имя для окна вывода и папку;
- нажмите Ok; вывод сохранится в файле с расширением *.spo.
Редактирование диаграммы
Для изменения диаграммы используйте Редактор диаграмм. Чтобы вызвать его дважды кликните на диаграмме в окне вывода.
Чтобы добавить заголовок кликните на соответствующей иконке на панели инструментов Редактора диаграмм:
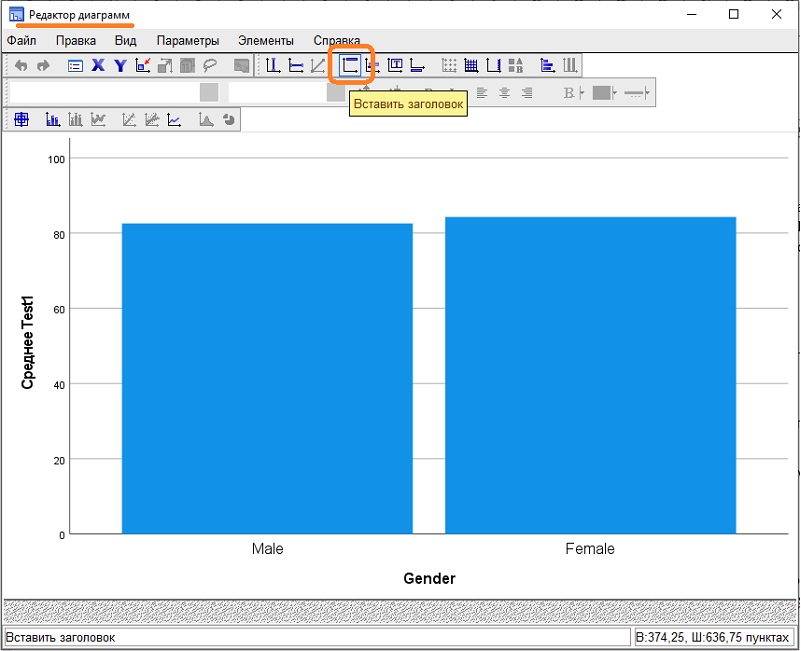
Рис. 22. Кнопка Редактор диаграмм
На диаграмме появится область для ввода заголовка и окно Свойства, где можно выбрать шрифты, границы и заливку. Для добавления подзаголовка (или даже нескольких) кликните на иконке Вставить заголовок повторно.
Для изменения любого элемента дважды щелкните на нем. Можно отдельно щелкнуть на названии оси, подписях и самой оси. В первых двух случаях можно будет отредактировать шрифты и стили оформления, а в последнем – масштаб.
Чтобы выйти из Редактора диаграмм просто кликните на крестике окна или пройдите Файл –> Закрыть.
Описание данных
Частоты и сопряженные таблицы. Частоты подсчитывают количество случаев возникновения определенного значения. Сопряженные таблицы позволяют подсчитать количество случаев возникновения определенного значения с разбивкой по одной или более категориям, например, по полу и возрасту. Для вычисления частот перейдите в окно Редактора данных, кликните Анализ –> Описательные статистики –> Частоты. Откроется диалоговое окно Частоты (см. выше рис. 8). Дважды щелкните мышью по переменным, для которых вы хотите посчитать частоты. В нашем случае это Test 1 и Test 2:
Рис. 23. Диалоговое окно Частоты
Щелкните по кнопке Статистики. Откроется диалоговое окно Частоты: статистики. В разделе Разброс отметьте Стандартное отклонение. В разделе Положение центра распределения отметьте Среднее:
Рис. 24. Диалоговое окно Частоты: Статистики
Нажмите Продолжить, а затем Ok.
В окне вывода появится три таблицы: обобщенная, и подробная для каждой переменной – Test 1 и Test 2:
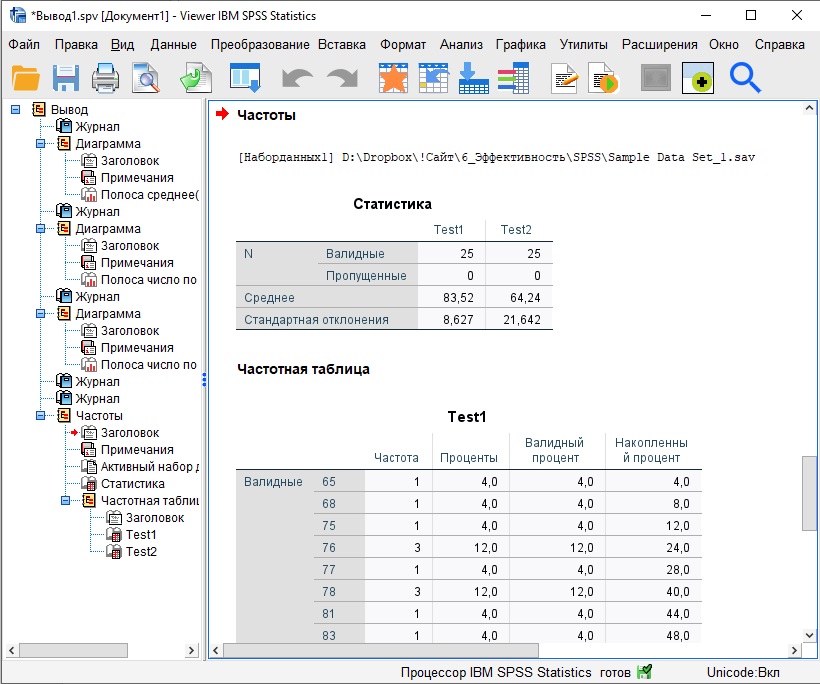
Рис. 25. Обобщенная статистика частот и фрагмент подробной таблицы частот Test 1
Выход из SPSS
Кликните Файл –> Выход. SPSS позаботится о том, чтобы сохранить все не сохраненные ранее или отредактированные окна, а затем закроется.
Только что вы кратко познакомились с SPSS. Однако эти навыки ничего не значат, если вы не понимаете смысла того, что делаете. Так что не восхищайтесь своими или чужими навыками пользования такими программами, как SPSS. Восхищайтесь, когда люди могут рассказать, что означает тот или иной вывод и какой ответ он дает на поставленный вопрос. И особенно восхищайтесь, если вы сами можете это сделать!
1 комментарий для “SPSS Statistics быстрый старт”
отдельно хочу отметить книгу — Салкинд очень просто и доходчиво дает инфу, позволяя с нуля освоить методы статистики вывода.
Множественная линейная регрессия (multiple linear regression) – подход к моделированию связи между одной зависимой переменной и несколькими независимыми.
Случай, когда линейная регрессия имеет только одну зависимую переменную и одну независимую, называется простой линейной регрессией (simple linear regression) или парной линейной регрессией (bivariate regression).
Начнём рассмотрение с простого варианта. Парная линейная регрессия, содержащая только одну зависимую переменную и одну независимую, имеет уравнение вида:

, где:

– предсказанные значения зависимой переменной;

– интерсепт (константа или свободный член);

– угловой коэффициент;

– значения независимой переменной;

– случайная ошибка модели.
Графически указанные величины будут представлены следующим образом. Предсказанные значения зависимой переменной – это те точки, через которые пройдёт линия регрессии. Интерсепт показывает, чему будет равно y при x = 0. Угловой коэффициент показывает, насколько прирастёт y, если x изменится на 1 единицу. Наконец, случайные ошибки модели, возникающие вследствие влияния неучтённых моделью факторов, увидеть нельзя. Но мы можем увидеть наблюдаемую ошибку, которая называется остатками модели (residuals) – это разность между тем, где находятся наблюдения, и тем, где проходит линия регрессии.
Вычисление величин, отличных от наблюдаемых, производится методом наименьших квадратов (least-squares method). Этот метод позволяет построить зависимость величин таким образом, чтобы линия проходила наиболее близко ко всем наблюдаемым случаям. К тому же метод наименьших квадратов гарантирует, что существует только один-единственный способ, как именно можно провести эту линию при заданных условиях.
Рассмотрим на графике рассеяния указанные в уравнении величины:

В формулу интерсепта входит коэффициент корреляции r-Пирсона, что приводит к прямому соответствию между знаком коэффициента корреляции и направлением линии относительно диагоналей графика рассеяния. При положительной корреляции линия регрессии будет проходить так, как указано на рисунке; в случае отрицательной корреляции интерсепт также будет отрицательным, а линия регрессии пойдёт по другой диагонали графика. В случае приближения корреляции к нулю, линия регрессии будет более-менее параллельна оси X.
Простая линейная регрессия, отражённая на рисунке, представляет собой попытку найти зависимость, связывающую X и Y. К искомой зависимости предъявляется ряд требований, среди которых самыми важными на первоначальном этапе понимания являются два: 1) зависимость должна иметь вид линии, что мы можем видеть как графически, так и в самом уравнении; 2) результат нашего моделирования необходимо проверить, ведь построенная линия сама по себе не означает, что зависимость есть. Отличие успешной модели от неуспешной состоит не в том, что у неуспешной модели нет линии. Отличие состоит в том, что линия неуспешной модели параллельна оси Х или, если говорить более точными формулировками, угловой коэффициент такой линии не отличается от ноля. Поэтому при расчёте в SPSS мы должны понять, какими способами оценивается успешность построения модели. В общем смысле для оценки успешности построения модели нам необходимо, чтобы наблюдаемые значения оказались как можно ближе к линии регрессии (лучше, чтобы они находились на ней). Не стоит путать это высказывание со способом построения линии – методом наименьших квадратов. Ведь если зависимости нет, линия наименьших квадратов, хотя и пройдёт ближе всего к точкам, будет фактически очень далеко от каждой из них. К тому же для оценки успешности построения модели нам важно, чтобы угол линии был достаточно большой, ведь в обратном случае изменение X не приводит к изменению Y.
При увеличении количества независимых переменных простая линейная регрессия становится множественной. Уравнение сохраняет общую логику, хотя и приобретает расширенный вид:

В этом уравнении мы также встречаем интерсепт и угловой коэффициент, а отличие состоит лишь в том, что происходит введение нескольких независимых переменных, каждая из которых имеет свой угловой коэффициент. К сожалению, на двухмерном графике нельзя увидеть трёхмерную картину линейной регрессии, а при добавлении факторов наше физическое пространство и мироощущение вовсе оказываются неподготовленными к графическому восприятию обсуждаемого вопроса. Однако это никак не мешает вычислять требуемые величины аналитически.
Перед тем, как начать конкретный расчёт множественной линейной регрессии в SPSS, стоит сделать ещё одно общее замечание. В модели присутствует сразу несколько независимых переменных, но исследователь не может быть уверен, что каждая из них действительно должна быть включена в модель. С одной стороны, расчёт позволит ответить на этот вопрос. С другой, из-за того, как именно происходит вычисление, неправильно введённая в модель переменная может кардинальным образом повлиять на вывод относительно всех переменных. Поэтому были разработаны различные способы включения переменных в модель:
К сожалению, однозначного ответа на вопрос, какой из указанных методов лучше, нет. На мой взгляд, имеет смысл начинать с одновременного включения всех переменных в модель (enter), чтобы оценить общую картину. А итоговый расчёт можно проводить каким-либо из методов 2, 3, 4. Основной интерес при сравнении указанных методов будет представлять наличие или отсутствие различия в выводах. Если применение различных методов приводит к различным выводам, необходимо более пристальное внимание к тем переменным, которые начинают появляться и пропадать в разных моделях. Это связано с критериями включения и исключения, отличающимися от метода к методу. Исследователю стоит самостоятельно принять решение, какую модель выбрать. Но, с моей точки зрения, имеет смысл исключить из модели все переменные, которые попадают в промежуток между уровнями значимости от 0,05 до 0,10.
Исходные данные для расчёта множественной регрессии в SPSS, а также гипотезы и базовые предположения представлены в документе: исходные данные — множественная линейная регрессия
На видео 1 представлен расчёт множественной линейной регрессии в SPSS методом одновременного включения всех переменных в модель:
На видео 2 представлен расчёт множественной линейной регрессии различными методами включения переменных в модель:
На видео 3 рассмотрена проверка базовых предположений множественной линейной регрессии:
На видео 4 представлена проверка многомерной нормальности в SPSS:
Синтаксисы , полезные при расчёте множественной линейной регрессии:
проверка многомерной нормальности: макрос и синтаксис многомерной нормальности, а также пояснение, как запустить эту проверку.
Читайте также: