
Как сделать ипс
Обновлено: 07.07.2024
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. - без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче - все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos. Архитектура современных ИПС для WWW Информационные ресурсы и их представление в ИПС Индекс поиска Информационно-поисковый язык системы Интерфейс системы Заключение Литература Пользователям Internet уже хорошо известны названия таких сервисов
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. - без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче - все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено множество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник "Научно-техническая информация. Серия 2", который выходит до сих пор. На русском языке издана так же и "библия" по разработке ИПС - "Динамические библиотечно-информационные системы" Ж. Солтона [1], в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом, нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения появилось нечто принципиально новое, чего не было раньше. Если быть точным, то ИПС в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web еще не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться, и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти и в сети не будет каталога, отражающего конкретную предметную область. Именно по этой причине для множества серверов Gopher, называемого GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий наблюдается и в World Wide Web. Собственно еще в 1988 году в специальном выпуске журнала "Communication of the ACM" [2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал в качестве первоочередной задачи для следующего поколения систем этого типа назвал проблему организации поиска информации в больших гипертекстовых сетях. До сих пор многие идеи, высказанные в той статье, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли [3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена отнюдь не чудесным программам талантливых одиночек, а средствам, являющимся результатом планового и последовательного движения научных и производственных коллективов к поставленной цели. Рано или поздно этап исследований заканчивается, и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital [4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Архитектура современных ИПС для WWW
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например [5,6], приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы [6] (рис.).
Рис. Типовая схема информационно-поисковой системы.
Client (клиент) на этой схеме - это программа просмотра конкретного информационного ресурса. Наиболее популярны сегодня мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
Search engine (поисковая машина) - служит для трансляции запроса на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) - индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
Queries (запросы пользователя) - сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот-индексировщик) - служит для сканирования Internet и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
WWW sites - это весь Internet или точнее - информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принципу построения каждого из этих компонентов более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
Информационные ресурсы и их представление в ИПС
В традиционных системах используется понятие поискового образа документа - ПОД. Обычно, этим термином обозначают нечто, заменяющее собой документ и использующееся при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель [7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОД. В более сложных моделях термины взвешиваются - элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной в ИПС Internet [4,6,7].
Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска и модель поиска в нечетких множествах [7]. Не вдаваясь в подробности, имеет смысл обратить внимание на то, что пока только линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText и AliWeb. Однако ведутся исследования по применению и других моделей, результаты которых отражены в работах [4,6]. Таким образом, первая задача, которую должна решить ИПС, - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС. Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Индекс поиска
Page-ID отображает идентификаторы страниц в их URL, Keyword-ID - каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков - идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок - идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову документа список пар - идентификатор страницы, позиция слова в странице. Прямой список - это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле - это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным - хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу" с помощью таблицы модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса - его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText [11].
Информационно-поисковый язык системы
Индекс - это только часть поискового аппарата, скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык (ИПЯ), позволяющий сформулировать запрос к системе в простой и наглядной форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка, - именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это еще не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: "Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно".
Возможны и варианты. Так, в большинстве систем фраза "Unix Platform" будет опознана как ключевая фраза и не будет разделяться на отдельные слова. Другой подход заключается в вычислении степени близости между запросом и документом. Именно этот подход используется в Lycos. В этом случае в соответствии с векторной моделью представления документов и запросов вычисляется их мера близости. Сегодня известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее развитым языком запросов из современных ИПС Internet обладает Alta Vista. Кроме обычного набора AND, OR, NOT эта система позволяет использовать еще и NEAR, позволяющий организовать контекстный поиск. Все документ в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь надеется увидеть ключевое слово: ссылка, заглавие, аннотация и т.п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. Различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню - ориентированный подход, либо командную строку. Первый позволяет ввести список терминов, обычно разделяемых пробелом, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя - в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска - список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Итак, результат поиска в базе данных ИПС - это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых выдается только список ссылок, а в таких, как Lycos, Alta Vista и Yahoo, дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности [7]. Релевантность - это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Первую вычисляет система, и на основании чего ранжируется выборка найденных документов. Вторая - это оценка самим пользователем найденных документов. Некоторые системы имеют для этого специальное поле [6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, а результат снова ранжируется. Так происходит до тех пор, пока не наступит стабилизация, означающая, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Заключение
В обзорной статье были рассмотрены основные элементы информационно-поисковых систем и принципы их построения. Сегодня ИПС являются наиболее мощным механизмом поиска сетевых информационных ресурсов Internet. К сожалению, в российском секторе Internet пока не наблюдается активного изучения этой проблемы за исключением, может быть, проекта LIBWEB, финансируемого РФФИ и системы "Паук", которая работает недостаточно надежно. Наибольшим опытом разработки такого сорта систем безусловно обладает ВИНИТИ, но здесь работа сосредоточена пока на размещении своих собственных ресурсов в Сети, что принципиально отличается от информационно-поисковых систем Internet типа Lycos, OpenText, Alta Vista, Yahoo, InfoSeek и т.п. Казалось бы, что такая работа могла быть сосредоточена в рамках таких проектов, как Россия On-line компании SovamTeleport, но здесь мы пока наблюдаются ссылки на чужие поисковые машины. Развитие ИПС для Internet в США началось два года назад, учитывая отечественные реалии и темпы развития технологий Сети в России, можно надеяться, что у нас еще все впереди.
• навыками составления поисковой фразы, выбора раздела и области поиска на поисковом сайте и в каталоге.
Массивы информации, необходимые для развития современного общества, огромны и имеют принципиальное отличие от той информации, что была доступна несколько десятилетий назад. Сегодня не существует ярко выраженных центров сосредоточения знаний. Традиционные источники информации: библиотеки, базы данных, архивы воспринимаются не как отдельные информационные узлы, а как совокупность множества источников информации. Наиболее четко тенденция рассредоточения информации просматривается в новых информационных средах, таких как глобальные компьютерные сети.
Рассредоточение источников информации – это не только возможность получать необходимую информацию, но и серьезные проблемы, связанные с поиском и классификацией необходимых информационных ресурсов. Глобальная информационная среда Интернет представляет собой миллионы источников информации общего пользования, практически по всем возможным темам. Сложность ориентирования в этом массиве информации заключается даже не в его огромных размерах и наличии множества разнообразных форматов данных, а в динамической природе информации, требующей постоянного обновления "информации о наличии и месте расположения информации".
Невозможно эффективно использовать новые информационные среды, в частности Интернета, без применения развитых поисковых механизмов – информационных поисковых систем (ИПС).
Общие принципы построения информационно-поисковых систем
Основные принципы информационного поиска. Проблема поиска документа возникает в любом хранилище данных. При создании систем хранения применяются две модели: иерархическая и гипертекстовая. Иерархическая модель хранения подразумевает многоуровневую рубрикацию системных ресурсов. Для определения пути к необходимому ресурсу используются описания, составленные при отправке документа на хранение. Гипертекстовая модель позволяет связывать документы ссылками, расположенными непосредственно в тексте документа.
При больших объемах информации, высокой скорости их обновления и разнородности запросов очевидны недостатки этих моделей. Многоуровневая рубрикация и простановка ссылок выполняется высококвалифицированными специалистами, поэтому объем обработанных ими документов становится ограниченным. Связанные документы ограничиваются определенной предметной областью, которая может разным образом трактоваться составителем и пользователем. При поиске документа целесообразно просматривать множество документов, содержащих лишь ссылки на другие ресурсы.
Этих недостатков лишены информационно-поисковые системы; будучи однажды созданными, они работают автономно. Принцип взаимодействия ИПС с пользователем заключается в том, что пользователь вводит в этой системе запрос, обрабатываемый системой, и получает список указателей на документы, удовлетворяющие запросу. Список может быть отсортирован по релевантности – степени соответствия документа запросу.
Основные принципы информационного поиска заключаются в том, что создается массив указателей на информационные ресурсы. Указатель (индекс) содержит некое свойство документа и ссылки на документы, обладающие этим свойством. Например, авторский указатель позволяет получить ссылки на работы определенного автора, предметный указатель – выбрать документы, затрагивающие определенные понятия (предметы). Процесс создания указателей называется индексированием, а термины, использующиеся для индексирования, называют терминами индексирования. В авторском указателе роль терминов индексирования выполняют фамилии авторов, работы которых хранятся в фонде. Совокупность используемых терминов индексирования называется словарем. Массив указателей, составленный после индексации информационных ресурсов, именуется индексной базой.
К индексной базе обращаются посредством запросов. Так, запрос пользователя должен быть переведен на язык индексирования. При поиске происходит сопоставление запроса с имеющимися данными и пользователю выдается список ссылок на подходящие ресурсы. Для повышения эффективности работы системы словарь и индекс должны быть упорядочены по системе, наиболее отвечающей задачам поиска в конкретной предметной области.
Первые информационно-поисковые системы были созданы в 1970– 1980-х гг. и продолжают развиваться сегодня.
Любая информационно-поисковая система использует предметный указатель, позволяющий отыскивать документы, касающиеся некоего "предмета". Для составления предметного указателя анализируется содержание документа и определяется "предмет" или "предметы", о которых в документе идет речь. Названия этих предметов переводятся на информационно-поисковый язык (ИПЯ), в результате получают поисковый образ документа (ПОД). Проиндексировав (создав поисковые образы) все информационные ресурсы, получают индексную базу – основной массив данных ИПС.
Процесс поиска заключается в сопоставлении запроса пользователя с имеющимися данными, полученный запрос также переводится на информационно-поисковый язык. После сопоставления переведенного па ИПЯ запроса и поисковых образов документов пользователь получает список ссылок на документы, соответствующие по мнению системы его запросу. Поиск происходит не по тексту документов, а по их поисковым образам, составленным на ИПЯ. Поэтому качество поисковой системы зависит в первую очередь от ее информационно-поискового языка. В состав информационно- поискового языка входят:
- 1) словарь индексационных терминов – множество терминов индексирования;
- 2) кодовый словарь – множество кодовых терминов;
- 3) словарь входов – множество входных терминов;
- 4) вспомогательные средства языка индексирования – используемые совместно с индексационными терминами для расширения или сужения определенных понятий;
- 5) правила использования языка индексирования.
Для повышения эффективности поиска словарь должен быть контролируемым, т.е. должен быть организован таким образом, чтобы полнота и точность поиска были оптимальными. Очевидно, что организация словаря зависит от многих факторов – предметной области, в которой будет функционировать ИПС, характера интересов пользователей, степени их подготовки и т.д.
Для улучшения результатов поиска необходимо определить степень специфичности терминов при индексации. Как правило, применяют два принципа – использование наиболее специфического термина, соответствующего объему и содержанию отражаемого понятия, и избыточное индексирование. В избыточном индексировании поисковый образ дополняется терминами, связанными с основным. Могут использоваться термины, связанные как с основным отношением обобщения или спецификации, так и ассоциативной связью. Дополнение поискового образа терминами с ассоциативной связью увеличивает полноту поиска, но неизбежно снижает его точность. К недостаткам избыточного индексирования относятся также увеличение объема поисковых образов. Для устранения этой проблемы во многих ИПС используется избыточное индексирование не документов, а запросов.
Предметное индексирование не исключает использование при создании поискового образа атрибутов документа. Это могут быть такие атрибуты, как данные об авторе, дата публикации, язык публикации и т.д.
Точность и полнота поиска зависят не только от характеристик самой ИПС, но и от того, как создается запрос. Идеальный запрос может быть составлен пользователем, в полном объеме знакомым с интересующей его предметной областью, а также с применяемой ИПС. Однако такому пользователю ИПС, очевидно, не требуется. Остальные пользователи вынуждены довольствоваться или низкой точностью поиска, или низкой полнотой.
Для повышения качества поиска существуют различные методы. Наиболее употребляемый из них – использование
логических операторов И, ИЛИ, НЕ. Это довольно простой способ повысить релевантность выдаваемых документов. Недостатком считается плохая масштабируемость. Оператор И может сильно сузить поиск, а оператор ИЛИ – сильно расширить. Степень точности и полноты поиска зависит от того, насколько общие термины участвовали в формулировке запроса. Может быть неверным использование как наиболее общих терминов (возрастает уровень информационного шума), так и слишком специфичных терминов (снижается полнота поиска). Применение слишком специфичных терминов чревато еще и тем, что в словаре ИПС данного термина может не оказаться. В общем виде процедура поиска – процедура итеративная, т.е. за этапом выдачи результатов поиска следует коррекция запроса, поиск по этому запросу и т.д. Схематично процедура показана на рис. 9.1. Коррекция запроса происходит в зависимости от количества полученных документов и их релевантности и может выполняться как пользователем, так и самой информационно-поисковой системой.
В зависимости от соотношения полноты и точности найденных документов пользователь может сузить или расширить область поиска, перейдя к более общим или, наоборот, более специфичным терминам, а также использовав родственные понятия. В случае поиска по нескольким терминам такая коррекция области поиска может происходить по одному из нескольких терминов, что позволяет изменять эту область достаточно плавно. Может оказаться полезным знание пользователя о наличии определенно релевантных документов. Не обнаружив их в списке найденных документов, область поиска следует расширить. Запрос корректируется системой информационного поиска па основании анализа документов, отмеченных пользователем как наиболее точно отвечающих его потребностям. В таком случае при следующем поиске система ищет те документы, где помимо заданных в первоначальном запросе содержатся термины, встречающиеся в документах, отмеченных пользователем. Улучшить результаты поиска можно различными способами, если функции для этого предоставляются интерфейсом информационно-поисковой системы.

Рис. 9.1. Процедура поиска
В последнее время во многих ИПС появилась функция подсказки при вводе текста поискового запроса, учитывающая ранее введенные этим пользователем запросы по сходной тематике за некоторый период времени.
Интерфейс системы. Важным фактором, во многом определяющим эффективность поиска, может быть вид представления информации в программе, т.е. ее интерфейс. По форме диалога, способу задания условия отбора и механизму поиска программные средства можно разделить на системы рубрикационного типа и структурно-логические системы.
Первые реализуются интерфейсом в виде иерархических последовательно раскрывающихся списков, через которые обеспечивается доступ к тематически связанным группам документов. Раскрывая очередную рубрику и перемещаясь таким образом по тематической иерархии, пользователь уточняет предметную область и увеличивает (усрсдненно) степень точности соответствия выдаваемых документов и информационной потребности. Предопределенность соотнесения документов с отдельными рубриками компенсируется логичностью естественно-научной классификационной схемы, заменяющей пользователю путеводитель.
Структурно-логические методы формирования запроса используются для работы с базами данных структурированной информации, когда каждый документ состоит из многих информационных полей, возможно, разного типа. Критерий отбора строится как логическая комбинация простых, сводящихся к проверке условия присутствия или отсутствия в документе слов (имен собственных или имен понятий, определяющих предмет поиска).
При составлении запроса к системе используют либо "меню-ориентированный" подход, либо командную строку. Первый позволяет ввести список терминов, как правило, разделяемых пробелом, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. Многие ИПС позволяют сохранять запросы пользователя – в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением, или уточнением, запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска – список идентификаторов документов, который объединяется или пересекается со списком, полученным при поиске документов по новым терминам.
Для решения некоторых навигационных задач, например, для определения МС, необходимо проложить на карте ЛРПС. Для этого необходимо сначала определить пеленг самолета. Поскольку на любой карте нанесены обычные географические меридианы, называемые в навигации истинными, и именно к ним будет прикладываться транспортир, то речь идет о расчете истинного пеленга самолета (ИПС).
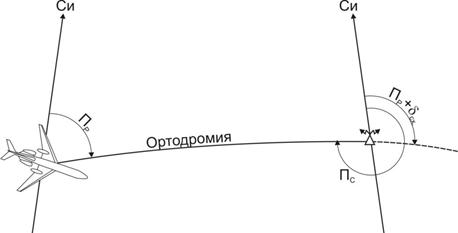
Рис. 3.35. Связь между пеленгом самолета и пеленгом радиостанции Очевидно, что магнитный пеленг самолета можно определить как
Как было показано ранее, этот МПС – это направление от РНТ на самолет, измеренное от магнитного меридиана места самолета (поскольку именно от него измерен МК, используемый для расчета МПС). Но ведь на карте нужно проложить ЛРПС на карте от истинного меридиана радиостанции. Следовательно, вновь возникает задача перехода от одного меридиана (магнитного меридиана МС) к другому (истинному меридиану РНТ).
Переход можно выполнить в соответствии с мнемоническим правилом. Для этого к МПС нужно прибавить магнитное склонение в точке расположения ВС (поскольку именно от меридиана МС известен МПС) и учесть угол схождения меридианов, чтобы перейти от истинного меридиана МС к истинному меридиану РНТ.
Расчет с помощью мнемонического правила более удобен и надежен на практике. Если же записать именно формулу для расчета ИПС, она будет выглядеть следующим образом:
где ΔМ – магнитное склонение в районе нахождения МС;
λр - долгота радиостанции;
φср – средняя широта (РНТ и МС).
В этой формуле первые три слагаемые – это и есть МПС, отсчитанный от меридиана МС (поскольку от него отсчитан МК). Последние два слагаемые обеспечивают переход от магнитного меридиана МС к истинному меридиану РНТ. И еще раз подчеркнем: долгота места самолета λ присутствует в формуле вовсе не потому, что именно там находится ВС, а потому что от этого меридиана измеряется МК!
Из данной формулы следует, что для расчета по ней ИПС необходимо иметь информацию о местонахождении МС (его широту и долготу, магнитное склонение). Но ведь ИПС для того и рассчитывают, чтобы определить МС и, следовательно, оно пока неизвестно. А оказывается, что для расчета ИПС уже нужно знать место самолета! Получается замкнутый круг.
Это является платой за то, что мы пытаемся проложить линию положения не для того навигационного параметра, который непосредственно измерили. Ведь суммированием курса и курсового угла радиостанции мы определяем пеленг радиостанции, который и является измеренным навигационным параметром. Но проложить на карте соответствующую ему линию положения (ЛРПР) трудно, поскольку она имеет сложную форму. Поэтому на практике мы с помощью Пр рассчитываем другой параметр – пеленг самолета (Пс), для которого построить линию положения легче. И для перехода от Пр к Пс как раз и нужна информация о МС, поскольку Пр отсчитан от меридиана МС.
А если для расчета пеленга использован не магнитный, а ортодромический курс? Очевидно, что ортодромический пеленг радиостанции
отсчитывается от выбранного опорного меридиана. Но прокладывать ЛРПС нужно все равно от истинного меридиана РНТ! Следовательно, в этом случае нужно перейти от опорного меридиана к истинному меридиану радиостанции. Это также удобно сделать с помощью мнемонической схемы. Порядок перехода будет зависеть от того, какой меридиан выбран опорным (истинный или магнитный) и какого именно пункта. Интересно, что в этом случае информация о местоположении самолета для расчета ИПС вообще не понадобится. Ведь переход будет выполняться от опорного меридиана к меридиану РНТ, а где находится самолет - не имеет значения.
Например, если в качестве опорного меридиана выбран магнитный меридиан точки с долготой λ0,например, аэродрома вылета, то
ИПС=ОК+КУР±180 +ΔМ0 +(λр-λ0)sinφср .
Предпоследнее слагаемое этой формулы обеспечивает переход от магнитного меридиана аэродрома вылета (он является опорным) к истинному меридиану этого аэродрома. А с помощью последнего слагаемого выполняется переход от истинного меридиана аэродрома к истинному меридиану РНТ.
Существующие в настоящие время средства информационного поиска могут рассматриваться как связь индивидуальных или коллективных потребителей (пользователей) информации . Средства поиска - это контакт конкретного потребителя с поставщиками информации, объединяемых общностью информации по отношению к поставленному вопросу (рис. 2).
Рис. 2 Схема взаимодействия средства информационного поиска с потребителями и поставщиками информации
На схеме поставщик информации вырабатывает информацию, которая аккумулируется (накапливается) средством информационного поиска. Потребитель информации формулирует запрос и после поиска в массиве получает от средства поиска необходимые сведения. Поставщики информации могут быть разобщены территориально и ведомственно, а средство поиска представляет способ преодоления этой разобщенности.
Средства информационного поиска решают проблемы отыскания конкретных сведений среди множества документов (информационных ресурсов). В их работе с документальной информацией можно выделить два основных этапа:
1-й этап - сбор и хранение информации;
2-й этап - поиск и выдача информационных ресурсов потребителям.
Службы поиска (средства, предназначенные для поиска информации) Интернета разделяются на каталоги (directories), поисковые системы (search engines) и метапоисковые системы (metasearch engines).
2. Информационно0поисковые каталоги
Каталог - это система, обеспечивающая классификацию информации. Его отличительная особенность - наличие иерархии (схемы упорядочения) ресурсов, в которой каждый из них (ресурсов)
относится к одному или более разделам. Каталоги (например, Yahoo!
казаться более осмысленными, так как информационные ресурсы налогах подготовлены людьми.
Рассмотрим структуру типовой схемы каталога (рис. 3):
Рис. 3. Типовая схема каталога
Клиент - это программа просмотра конкретного информационного
ресурса. Наиболее популярными программами просмотра Интернет-
документов являются Microsoft Internet Explorer и Netscape Navigator. В
свою очередь, все эти информационные ресурсы являются объектами
Пользовательский интерфейс - это группа Web-страниц (форм) средства поиска, при помощи которых пользователь взаимодействует с данным средством.
Поисковая машина - компонент системы, основное назначение которого - поиск известных данной системе документов, соответствующих сформулированному запросу во внутреннем массиве данных системы, и формирование ответа (результата проведенного поиска) пользователю в виде набора ссылок на найденные документы.
Технический персонал - люди, в обязанности которых входит формирование перечня информационных ресурсов каталога, их описаний и иерархии этих ресурсов.
Запросы пользователя - массив данных системы, служащий для временного хранения сформулированных запросов пользователя.
Иерархия информационных ресурсов и их описания – внутренний массив данных каталога, в котором содержатся сведения об информационных ресурсах сети Интернет (адреса URLи краткое описание ресурсов). Данный массив организован таким образом, что каждый информационный ресурс соответствует какой-либо теме, а перечень тем упорядочен по признаку подчинения.
Информационные ресурсы - ресурсы, просмотр которых обеспечивается программами просмотра, такими как Microsoft Internet Explorer, Netscape Navigator и др., т.е. это Интернет-документы.
При решении стандартной поисковой задачи (при поиске общедоступной информации) именно каталог, а не поисковая система оказывается наиболее лучшей точкой отсчета для начала поиска.
Типичным примером использования каталога является необходимость нахождения в сети Интернет группы информационных ресурсов на определенную недостаточно узкую тематику, например сайтов, предоставляющих контактную информацию организаций Москвы или сайтов электронных СМИ.
Информационно-поисковые системы
Другая, принципиально отличная от каталога, служба поиска информации - информационно-поисковая система (ИПС). ИПС - это система, обеспечивающая накопление и поиск информации
ИПС, решая задачи сбора, хранения, обработки и выдачи информации, выполняют следующие операции:
- поиск документов;
- анализ содержимого документов;
- построение поисковых образов документов (извлечение из
документов информации, используемой системой как знания
о документе); - хранение поисковых образов документов (сведений о
документах); - анализ запросов пользователей (потребителей информации);
- поиск релевантных (соответствующих) запросу документов;
- выдача ссылок на документы потребителям.
Это представляет возможным составить общую схему ИПС. Примером может служить типовая схема ИПС (рис. 4).
Рис. 4. Типовая схема информационно-поисковой системы
Индекс базы данных - это основной массив данных ИПС. Он служит для хранения сведений обо всех известных системе Интернет-документах. Данные сведения необходимы для того, чтобы поисковая система сумела найти документы на запрос пользователя.
Робот-индексировщик (crawler, spiderили паук) - программный модуль поисковой системы, служащий для поиска (отбора) информационных ресурсов в Сети и их индексирования (индексировать информацию означает приписать каждому документу ключевые слова, отражающие содержание документа и управляющие поиском, приводя к тем документам, слова которых оказываются более сходными со словами сделанного запроса), т.е. поддержания базы данных индекса в актуальном (по отношению к Интернету) состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов. Просмотр документов Интернета данным модулем системы делается регулярно. Для крупных систем период просмотра документов, как правило, составляет 1-2 недели.
Общий алгоритм функционирования ИПС (принцип работы; со сюит в следующем. Робот-индексировщик автоматических просматривает (переходя от одного ресурса к другому, используя ссылки, расположенные на нем) различные информационные ресурсы Интернета (Интернет-документы). Создает индекс базы данных, помещая туда информацию о ресурсах Сети. При этом он также периодически возвращается к информационным ресурсам и проверяет их на наличие изменений. Когда пользователь делает поисковой системе; запрос, ее программное обеспечение (поисковая машина) просматривает созданный индекс базы данных в поиске ресурсов с заданными ключевыми словами и ранжирует (упорядочивает) эти ресурсы по степени близости к предмету поиска.
Относительно алгоритма функционирования ИПС следует сделать ряд замечаний. В каждой конкретной поисковой системе хранятся (сведения не о всех документах Интернета, а только о тех документах которые известны данной системе (для различных систем процент проиндексированных документов различен, но, как правило, не превышает 30%). В поисковых системах хранятся не сами документы, а только сведения о них, достаточные для их нахождения пользователем и, как следствие этого, поисковая система в результатах поиска может и не выдавать некоторые соответствующие запросу документы. В результате поиска (отклике на запрос) системой сортируются документы по степени соответствия сделанному пользователем запросу с точки зрения алгоритма поисковой системы, а не с точки зрения их фактического соответствия запросу. Данная особенность систем значительно экономит время, затрачиваемое на поиск требуемой информации, особенно когда комбинация слов запроса встречается в нескольких тысячах или миллионах документов, однако нередки и случаи, когда наиболее соответствующие запросу документы не являются первыми в выданном списке. В данном случае следует соблюдать компромисс между количеством просматриваемых документов и общим числом найденных документов (как правило, требуемая информация содержится в первых нескольких десятках найденных документов), но наиболее типичным действием является уточнение запроса с помощью средств уточнения запроса, предоставляемых данной системой (т.е. обычно при помощи языка запросов и (или) средств расширенного интерфейса формулировки запросов). К формированию более детального запроса также следует обратиться, если в результатах поиска много информационного шума (т.е. не соответствующей запросу информации), что, как правило, свидетельствует о неудачно подобранных терминах запроса (например, они подвержены полисемии (т.е. имеют несколько значений)). В промежутках между работой робота-индексировщика системы документы изменяются пользователями, но эти изменения часто учитываются поисковой системой не мгновенно, а спустя некоторый промежуток времени, определяемый периодом индексирования Интернета, поэтому некоторая информация может быть в системе потенциально недоступной в конкретный момент времени.
Поисковые системы следует применять, если требуется найти информацию по специфичным вопросам или для обеспечения полноты охвата ресурсов.
Метапоисиовые системы
Отличия в стратегии и широте охвата материала различных поисковых систем часто приводят к тому, что разные средства поиска дают разноречивые ответы на один и тот же запрос. Этим воспользовались разработчики метапомсковых систем, которые в своей работе используют потенциал других средств информационного поиска (рис. 5.). Метапоисковые системы - это надстройки над поисковыми системами и электронным каталогами, которые не имеют собственной базы данных (индекса) и при поиске по поисковому предписанию пользователя самостоятельно формируют запросы для нескольких внешних средств
Рис. 5. Типовая схема метапоисковой системы
поиска, а затем анализируют полученные результаты и выдают список ссылок в порядке, определяемом соотношением рейтингов ответа сразу по нескольким средствам поиска. Иначе, такая система ведет опрос нескольких поисковых систем, а затем отбирает ссылки, следуя собственному алгоритму.
Метапоисковые системы позволяют сократить время, затраченное на поиск информации, так как при обработке запроса пользователя эти системы одновременно обращаются к нескольким различным средствам поиска.
Метапоисковые системы наиболее эффективны на начальных чпапах поиска информации. Они помогают локализовать средства юиска, в которых присутствуют сведения об искомой пользователем информации.
Дополнительные средства и способы поиска

Данная дисциплина знакомит с основными проблемами информационного поиска, раскрывает основные этапы становления средств навигации для текстовой информации и информационного поиска, дает представление о локальных и глобальных сетях и о принципах работы в них.
Кроме того, курс о поисковых системах позволяет ознакомиться с основами информационного поиска в справочно-правовых системах и информационным поиском в глобальной сети Интернет – проводится краткий исторический обзор становления информационно-поисковых систем сети Интернет (как в целом, так и в России), рассматриваются основные задачи и компоненты ИПС глобальной сети.
Читайте также: